稀疏链式多标记分类器*
2018-09-12王灿,黄俊,秦锋
王 灿,黄 俊,秦 锋
(安徽工业大学 计算机科学与技术学院 ,安徽 马鞍山 243000)
0 引 言
多标记学习的研究最早起源于文档分类中遇到的歧义性问题[1],近年来多标记学习已经引起了学者的广泛关注,是当前机器学习领域的一个研究热点。在多标记学习中,每个对象用一个特征向量表示,即一个示例(Instance),它可以属于一个或同时属于多个类别标记。例如一部电影可能同时属于多个类型的电影,电影“荒野猎人(The Revenant)” 同时属于“冒险” 、“戏剧” 和“西方电影” 等3个电影类型。在场景分类中,一张图像可能同时属于多个类别,例如 “大海” 、“沙滩” 和“天空” 等类别。多标记学习已在现实生活中得到了广泛应用,例如文档分类[1-2]、图像标注[3]、视频标注[4]、社交网络[5]、音乐情感分类[6]、生物信息学[7]等。
传统的分类任务主要解决的是单标记学习问题,即一个对象只属于一个类别,并且类别标记间是互斥的,而在多标记学习中,标记之间存在相互依赖性。研究者已经发现,建模类别之间的相关性可以有效提升多标记分类器的泛化性能[8]。利用这些关系能够使得相关标记上的有用信息互相帮助,有效降低学习任务的难度。例如,标记之间的共存和互斥关系能够避免冗余的训练和测试任务,而样本严重缺失,难以区分的标记则有可能利用其他具有更丰富样本的相关标记上的信息来帮助自身的学习任务。多标记学习的挑战就是如何有效地利用标记相关性学习高效地分类模型,为新样本预测一个或多个可能的类别标记。
研究人员对多标记学习问题已经进行相关的研究,目前建模标记相关性的方法可以分为二阶和高阶算法[8]。 二阶多标记学习算法将两两标记对(Label Pair)类别之间的相关性信息建模到分类器模型中,以提升分类器的泛化性能。建模类别相关性的算法复杂度是O(q2),对于类别数较大的数据复杂度较高。
高阶多标记学习算法挖掘所有类别标记之间的关系或标记子集的关系,以提升分类器的泛化性能,代表性的算法有链式分类器(Classifier Chain,CC)[9],堆叠式分类器(Stacking)[10]以及问题转换策略算法RAkEL[11]和EPS[12]。RAkEL和EPS的复杂度较高,很难适用于大规模多标记数据。CC和Stacking的复杂度为O(q),效率较高。很多算法在它们基础上进行改进,如文献[13-16]。但仍然有两个问题没有得到很好的解决:错误传播(Error Propagation)和冗余或错误的类别依赖关系(Unnecessary Dependent Relationships)[17-18]。精确的学习类别之间依赖关系的贝叶斯网络结构,可以减轻这两个问题带来的影响,但精准地学习一个贝叶斯网络(或者DAG图)的复杂度是标记个数的指数次,即O(q2q)[19],难以适用于大规模多标记数据。
对此,本文在链式分类器的基础上进行改进,学习一个稀疏的链式多标记分类器SCC (Sparse Classifier Chain)。通过引入稀疏学习机制,学习稀疏的类别依赖结构,去除冗余或者无关类别依赖关系,从而提升分类器的性能。
1 相关工作
根据建模标记相关性的不同方式,现有多标记学习算法可以分为一、二、三阶算法[8]。
1.1 一阶算法
一阶多标记学习算法主要基于BR[20]框架,为每个类别独立学习一个二类分类器(one-vs-rest)。例如MLkNN[21]和SWIM[7],该类方法效率较高且实现简单,但由于其完全忽略标记之间可能存在的相关性,其系统的泛化性能较低。因此,研究者提出建模二阶和高阶类别相关性。
1.2 二阶算法
二阶多标记学习算法将两两标记对类别之间的相关性信息建模到分类器模型中,以提升分类器的泛化性能。这种两两标记对的类别相关性信息关系也称为pairwise类别相关性。当前多标记学习算法建模pairwise类别相关性的方式主要有两种:一种是建模任意两个标记对之间的相关关系,以此来约束和指导它们对应的两个二类分类器之间的关系,例如 CLR[23]和LLSF[24]等算法;另一种是将Ranking Loss[8]损失函数融入到分类模型中进行优化,使得在对每个样本所有可能的类别标记排序时,隶属于该样本的类别标记应位于不属于该样本的类别标记之前。例如BP-MLL[2]和RankSVM[25]等算法。这些算法都建模两两标记对之间的依赖关系,而在实际应用中,一个类别标记可能同时依赖于多个类别标记。
1.3 高阶算法
高阶多标记学习算法挖掘所有类别标记之间的关系或标记子集的关系,以提升分类器的泛化性能。
CC[9]是建模高阶类别相关性的链式多标记学习算法,它将训练集中的类别标记进行随机排列,得到标记序列,然后据此给每个类别训练一个二类分类器(one-vs-rest)。CC的分类性能受限于标记序列顺序和错误传播,原作者提出使用集成学习(Ensemble Classifier Chain,ECC)的方法可以降低标记序列对分类性能的影响。PCC[26]是CC的一种概率模型和解释,PCC算法预测推理的计算复杂度较高,同时PCC的性能也对标记序列比较敏感。当前很多的多标记学习算法主要针对标记序列、类别结构和计算复杂度方面进行改进,例如LEAD[13]、PCC-beam[15]、DBR[10]、MCC[16]和PruDent[17]等算法。
目前,多标记算法建模大多都是全局标记相关性,而在实际应用中,不同的数据可能会共享不同的标记依赖关系。已有若干建模局部相关性算法,例如ML-LOC[27]、GCC[28]和LPLC[29]等算法。
2 稀疏链式多标记学习算法

2.1 链式分类器
链式多标记学习算法CC[9]建模高阶类别相关性,它将训练集中的q个类别标记随机排列,得到序列y1,y2,…,yq,然后依次训练q个二类分类器,图1给出了链式分类的结构。
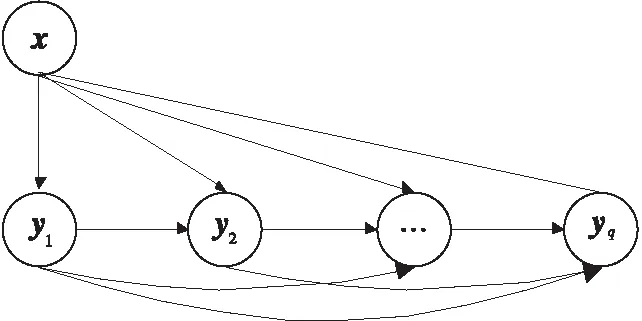
图1 链式分类器Fig.1 Classifier chain
当训练第l个分类器hl时,它将训练样本在类别y1,y2,…,yl-1上的标记值作为增广特征,与原始d维特征表示拼接在一起作为输入。在测试阶段,当预测第l个类别标记时,需要使用测试样本在前i-1个分类器h1,h2,…,hl-1的输出作为增广特征。
CC算法简单有效,但存在以下缺点:
CC假定第l个类别依赖于序列之前的l-1个类别标记。在实际应用中,这种假设经常不能满足,例如第l个类别可能只依赖于序列之前的l-1个类别标记中的部分标记。
CC的分类性能受限于标记序列的顺序和错误传播(Error Propagation)[30]。

2.2 稀疏链式多标记分类器
针对以上3个问题,提出稀疏链式多标记分类器。不是一般性,假定标记序列为y1,y2,…,yq,对于第l个类别标记,构建一个线性分类器:
(1)
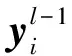
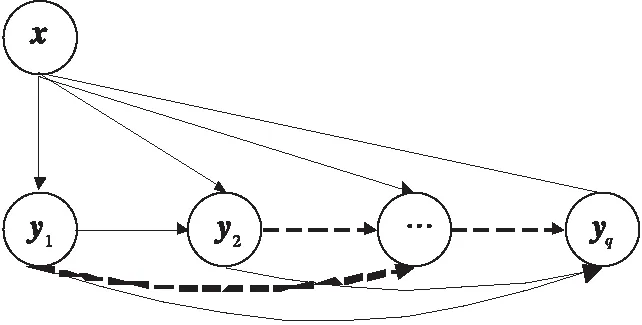
图2 SCC结构Fig.2 Sparse classifier chain
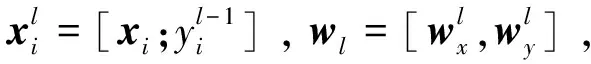

(2)
对于测试数据和训练数据分布不一致问题,借鉴多目标回归任务(Multi-target Regression)的思想[33],即在训练阶段不使用样本真实标记值,而是使用分类器预测值作为增广特征,可以降低数据的分布差异。算法1归纳了本文所提SCC算法的所有学习步骤。
算法1 SCC训练算法
输出:SCC算法分类器model_SCC
1.predictTarget=zeros(n,q);
2.forl=1 toq
3.D′={};
4.fori=1 ton
5.y_aug=predictTarget(i,1:l-1);
6.D′=D′∪{[xi,y_aug],yil};
7.end
8.wl=BR-Train(D’,C,LRL1);
9.predictTarget(:,l)=BR-Predict(D′,wl);
10.end
3 实 验
3.1 实验设置
本文将所提算法SCC和ESCC与下列相关的多标记学习算法进行对比:
(1) BR[20]:为每个类别独立学习一个二类分类器,一阶多标记学习算法。
(2) DBR[10]:将所有类别与特征空间结合在一起作为特征一起输入,然后给每个类学习一个二类分类器,高阶多标记学习算法。
(3) ECC[9]:链式分类器CC的集成学习版本,其中集成分类器个数m设为10,且随机产生每个链式分类器的类别序列,高阶多标记学习算法。
(4) MLkNN[21]:一种基于懒惰学习(Lazy Learning)技术的多标记学习算法,该算法通过扩展k近邻算法得到,近邻参数k搜索范围为{3,5,…,21},一阶多标记学习算法。
(5) SCC和ESCC:本文所提SCC以及它的集成学习版本ESCC (Ensemble Sparse Classifier Chain),其中集成分类器个数m设为10,且随机产生每个链式分类器的类别序列,高阶多标记学习算法。
本文使用LibLinear[32]中带l1和l2正则的Logistic回归模型分别作为BR、DBR、ECC、SCC和ESCC算法中的每个二类分类问题的分类器,例如BR-L2表示使用l2正则的Logistic回归模型作为二类分类器,而BR-L1则表示使用l1正则的Logistic回归模型作为二类分类器。Logistic回归模型的正则化系数C根据5折交叉验证确定,搜索值域为{10-4,10-3,…,104}。
3.2 评价指标
为了充分验证所提算法的有效性,选取8个评价指标来评估算法的性能,如Hamming Loss、Accuracy、Exact-Match、F1、Macro F1、Micro F1,Average Precision和One-Error,其中Hamming Loss和One-Error的值越小,表示分类器性能越好,其余6个指标则相反,各指标的具体意义和计算公式可参考文献[8]。
3.3 实验数据集
在12个标准数据集上进行了实验验证。表1总结了所有数据集的信息,它们可以从Mulan1、和Meka2下载。
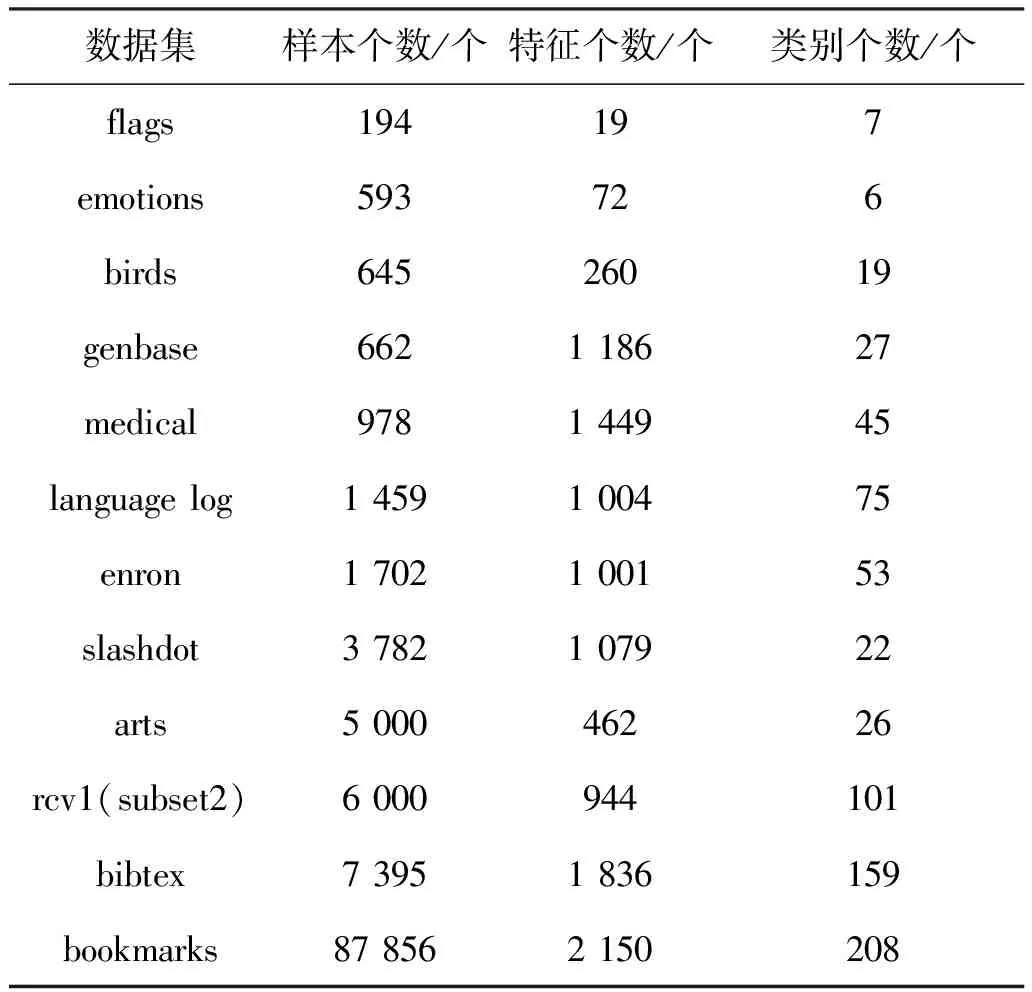
表1 实验数据集信息Table 1 Experimental data set information
3.4 实验结果
对于每个数据集,将其随机分成训练集(80%) 和测试集(20%),重复30次。表2—表9中记录了所有实验的平均结果(均值±标准差),黑体表示每个数据上的最优结果。符号↑(↓)表示值越大(小),分类器性能越好。
本文利用秩和检验(Nemenyi Test)[34]方法来分析所有对比算法之间的相对性能,以检验提出的方法SCC以及ESCC是否显著或者统计上优于其他对比算法。在某一给定评估指标下,如果两个分类器在所有数据上实验结果的平均排序值的差值大于一个临界差异(Critical Difference)值:
说明两者的性能有显著差异,否则没有显著差异。对于秩和检验,在显著性水平α=0.05 下,qα=3.031,则临界差异值PCD=3.031 (k=8,N=12)。图3展示了所有对比算法在不同评估指标下的相对性能。图3的每个子图中,横轴表示每个对比算法在给定评价指标下的平均Rank值,值越小表示算法性能越好。用红线连接的算法之间在统计上性能无显著差异(平均Rank 值之差小于等于一个临界差异值3.031),未连接的算法之间性能有显著差异(Rank 之差大于3.031)。从图中可以看出,在大多数评价指标下,提出的方法SCC和ESCC统计上优于所有对比算法,显著优于部分算法。根据以上实验结果,可以得出以下结论:
(1) 在大多数情况下,BR-L1的结果优于BR-L2,说明学习对每个类别具有判别力的类属特征学习的有效性。
(2) 在部分数据集上,例如flags、emotion、enron、slashdot数据,BR-L1的性能与BR-L2持平,但ESCC-L1依然取得了较ECC-L2更优的分类性能。这说明学习稀疏的类别依赖关系的有效性。通过稀疏约束,可以去除冗余和错误类别依赖关系,进而提升分类器性能。
(3) 在所有8个评价指标下,ESCC-L1性能均优于其他对比算法,在部分指标下显著优于部分对比算法,且在Hamming Loss上的结果优于BR。
(4) 除Macro F1指标外,SCC-L1在其余7个指标的性能均优于DBR-L1,说明稀疏链式分类器比稀疏堆叠式多标记分类器能更好地建模高阶标记相关性。SCC-L1在4个指标下的性能仅次于ESCC-L1。通过以上实验和分析可以发现,所提算法SCC和ESCC取得较有竞争力的分类性能。

(a) Hamming Loss (b) Accuracy (c) Exact-Match (d) F1

(e) Macro F1 (f) Micro F1 (g) Average Precision (h) One-Error图3 各对比算法在每个评估指标下实验结果的Nemenyi检验分析(显著性水平α=0.05)Fig.3 Nemenyi test analysis of the experimental results of each comparison algorithm under each evaluation index(Significance level α=0.05)

表2 各对比算法的Hamming Loss (↓)实验结果Table 2 Hamming Loss (↓) experimental results of each comparison algorithm
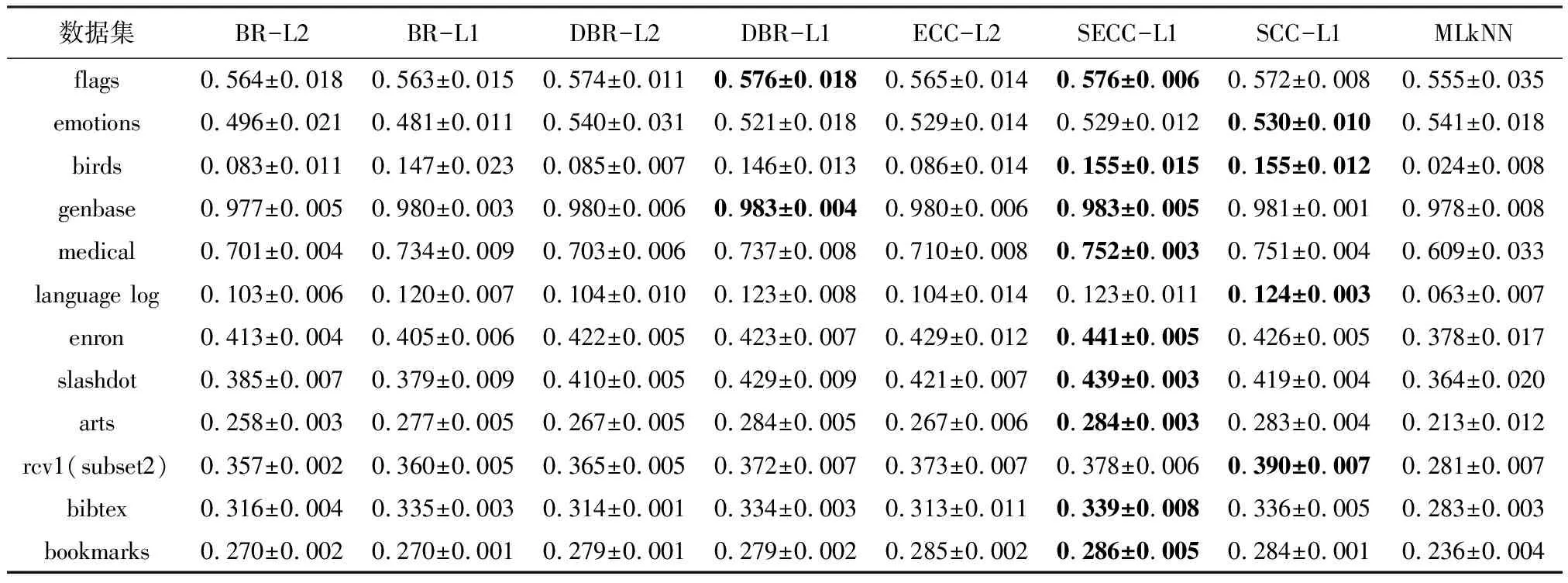
表3 各对比算法的Accuracy (↑)实验结果Table 3 Accuracy (↑) experimental results of each comparison algorithm

表4 各对比算法的Exact-Match (↑)实验结果Table 4 Exact-Match (↑) experimental results of each comparison algorithm
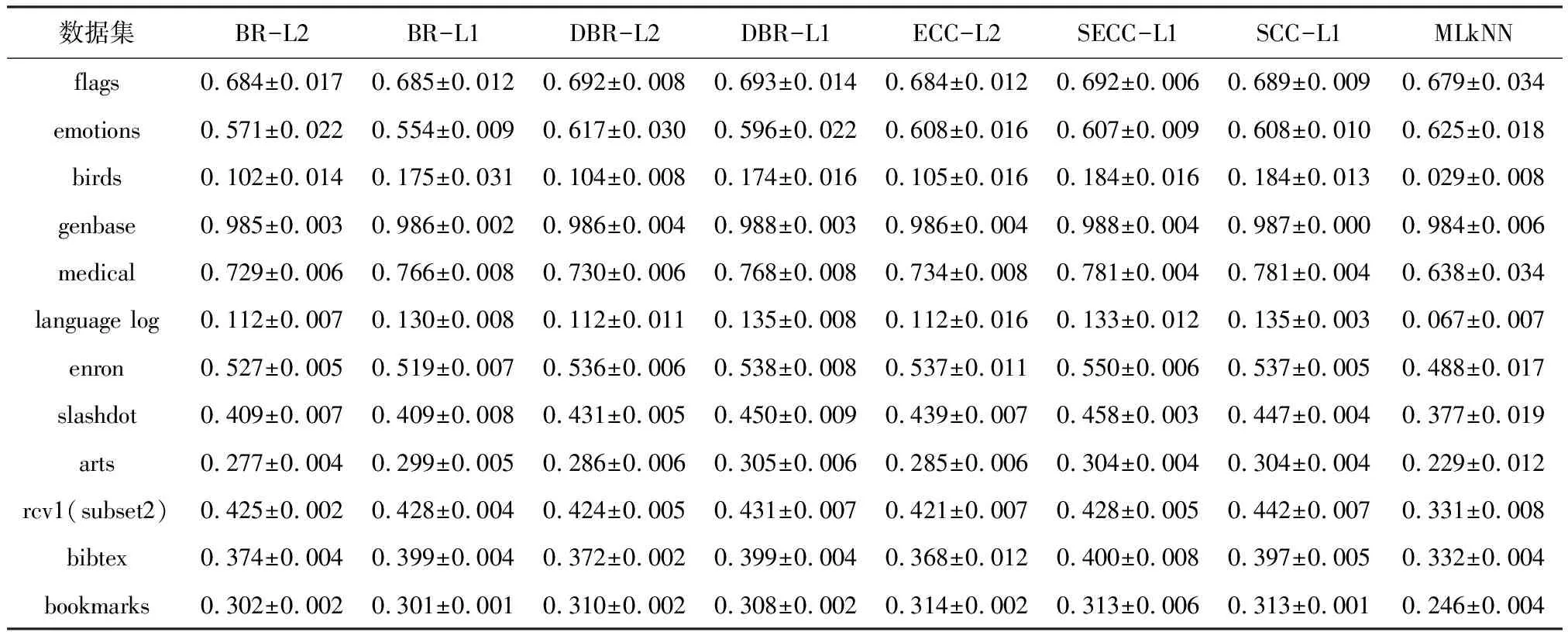
表5 各对比算法的F1 (↑)实验结果Table 5 F1 (↑) experimental results of each comparison algorithm
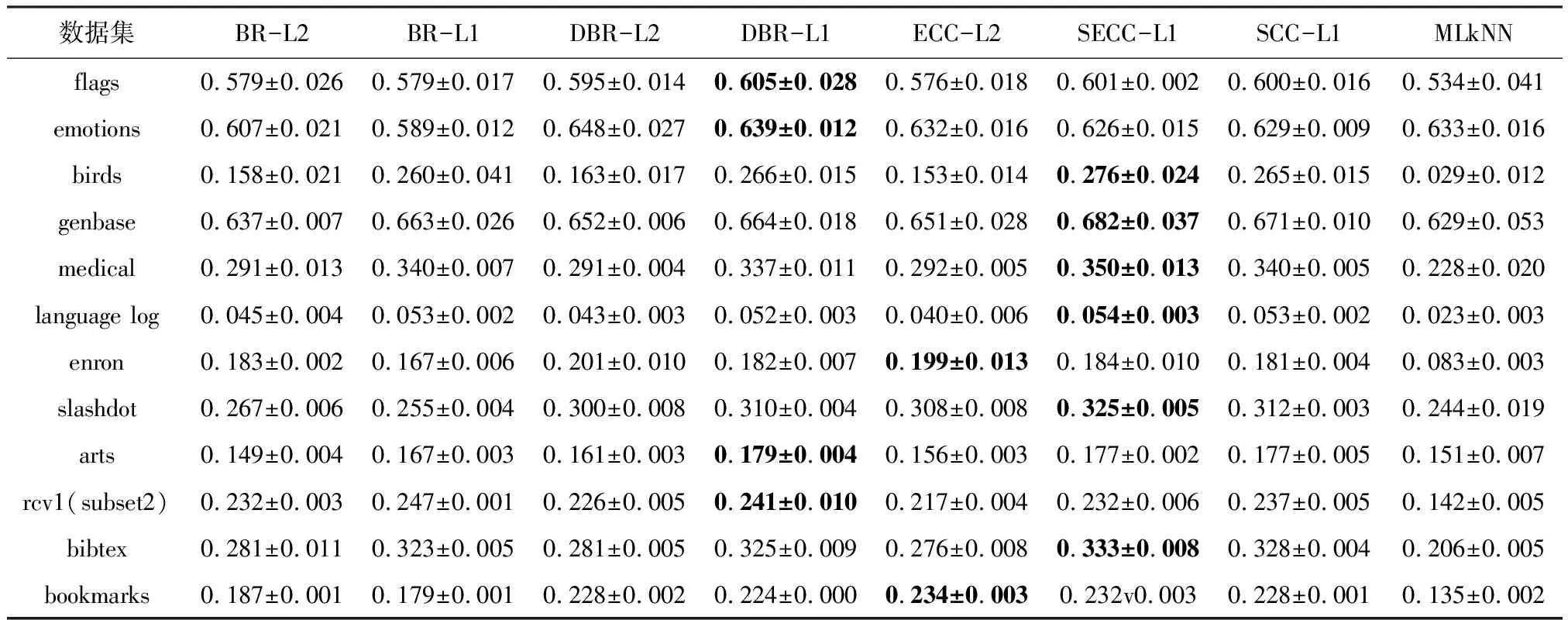
表6 各对比算法的Macro F1 (↑)实验结果Table 6 Macro F1 (↑) experimental results of each comparison algorithm

表7 各对比算法的Micro F1 (↑)实验结果Table 7 Micro F1 (↑) experimental results of each comparison algorithm

表8 各对比算法的Average Precision (↑)实验结果Table 8 Average Precision (↑) experimental results of each comparison algorithm

表9 各对比算法的 One-Error (↓)实验结果Table 9 One-Error (↓) experimental results of each comparison algorithm
3.5 参数分析
本文所提算法ESCC只有一个参数C,其搜索值域为{10-4,10-3,…,104}。在4个数据集上进行试验分析,即flags、medical、slashdot和bibtex。随机将其分成训练集(80%)和测试集(20%),重复30次,图4给出了ESCC在3个评价指标(Exact-Match,Macro F1和Micro F1)下的平均实验结果。从图中可以看出,参数C在不同的取值下,算法性能变化较小,说明所提算法对参数C不敏感,具有较好的稳定性。

(a) flags (b) medical (c) slashdot (d) bibte
图4ESCC算法参数C对预测性能的影响,纵轴表示各评价指标的结果值
Fig.4ESCCalgorithmparameterConthepredictionperformance,theverticalaxisrepresentstheresultsoftheevaluationindex
4 结束语
提出了稀疏链式多标记学习算法。不仅可以处理大规模多标记数据,同时可以降低冗余类别依赖关系带来的错误传播问题。算法在多个标准多标记数据集进行实验,实验结果表明所提算法具有较强的适用性和泛化性能。
