基于参数不确定性的洪水概率预报研究
2018-09-10赵信峰徐鹏刘开磊赵丽霞徐十锋郏建
赵信峰 徐鹏 刘开磊 赵丽霞 徐十锋 郏建
摘要:水文模型参数的选取通常依靠经验判断或者依赖历史库中的不完备数据集进行自动优选,所选参数并不一定能够准确反映流域降雨径流特点,更不足以反映不同洪水涨落阶段洪水特征的变化。基于水文模型的参数存在显著不确定性的客观事实,以随机参数驱动水文模型,并结合数值模型实现概率预报。通过东湾流域36场洪水模拟试验,揭示了水文参数不确定性对洪水预报结果的显著影响,验证了概率预报算法能够给出精确、可靠的预报结果,说明该算法能够降低水文模型参数所带来的洪水预报不确定性。
关键词:新安江模型;参数不确定性;概率分布;概率预报
中图分类号:P338
文献标志码:A
doi: 10.3969/j.issn.1000-1379.2018.04.009
受参数不确定性影响,洪水预报模型的预报结果往往难以达到足够的精度。在实际洪水预报中基于传统的洪水预报模型得到的预报结果,其不确定性程度较高,难以据此作出适合的防汛调度决策,在实际应用中往往通过校正或概率预报的方式来降低洪水预报不确定性。本研究从模型参数存在不确定性的客观事实出发,分析参数的概率分布特征以生成随机参数簇,驅动洪水预报模型产生初始预报解集,采用适合的方法进行预报结果综合,得到概率预报结果。
1 模型介绍
1.1 新安江模型及其参数介绍
新安江模型是1983年由河海大学赵人俊教授等研制并逐步完善起来的流域产汇流模型。该模型在国内水文预报中获得广泛应用,并在国际水文学研究中取得有价值的成果。
新安江模型是典型的概念性模型,由蒸散发、产流、分水源和汇流4个模块组成。模型参数较多,根据优化目标函数对参数的敏感性,将参数分为敏感、不敏感、区域敏感三类。对不敏感参数一般取经验值,不参与优选:对于敏感或区域敏感参数,则需要充分考虑参数水文特性,采用客观优选或SCE-UA等自动优化方法确定参数值。
河网蓄水消退系数CS常被归类为敏感参数,对洪水预报结果的影响较大,目前针对其水文特性及统计规律的研究较多,成果也较丰富。根据李致家在沙埠流域对CS参数的研究成果可知,CS是时段长度和线性水库蓄泄系数的函数,反映流域汇流特性及线性水库的时间尺度变化。陆曼皎尝试通过蓄泄系数参数来间接推求CS值,其模拟试验在皖南山区面积在100~3000km2之间的13个流域进行,结果表明地理因子公式推求得到CS的方法具备一定程度的可操作性,同时验证了计算步长、时段内人流分布可能带来的参数不确定性。
1.2 BMA模型介绍
BMA(Bayesian Model Averaging)是基于多预报序列的先验信息进行模型综合的数值模型。段青云等在美国3个水文站进行模拟试验,研究BMA方法的集合预报性能,其研究表明BMA对高、低水部位的模拟精度较高,对于降低洪水预报结果的不确定性程度效果显著。BMA模型依赖较长序列预报结果进行模型训练,进而根据各个时刻的初始(先验)预报结果估计预报变量的后验概率,生成概率预报以及均值、中位数形式的确定性预报结果。
在采用BMA模型进行集合预报时,不需要关注各模型中哪个是最优模型,也不要求各模型均能够提供高精确度的预报结果,只需要提供给模型足够长度的资料以进行BMA模型训练。因此,在实际应用中,BMA模型能够避免因对最优模型的判断不准确而带来的不确定性,避免产生较差的预报结果,同时能够提供较为可靠的预报变量概率分布描述。
1.3 基于参数不确定性的概率预报
实际上,BMA模型的先验信息并不局限于多模型预报结果,只要给出多个时间序列的原始预报数据及相应的实测序列,BMA就可以正常执行运算。考虑到在执行实时洪水预报时最优参数并不能够提前预知,可以依据参数的先验概率分布特征,随机给出某参数的多个可能的值,以驱动水文模型产生多个预报结果。在BMA框架下,随机参数所产生的多个预报结果视作BMA的集合预报成员:以基于以上各参数模拟历史场次洪水的计算结果作为先验信息,进行BMA模型训练:进而,以BMA模型综合当前洪水的多个预报结果,得到在考虑参数不确定性的情境下预报变量的概率分布。其中,随机生成的该参数的多个可能值被统一称为参数簇。
根据以上方法,以新安江模型为例,考虑其参数CS的不确定性,采用如下步骤构建基于参数不确定性的概率预报算法(PROP)。
(1)获取参数的先验概率分布:根据经验,选择以新安江模型的参数CS为例,考察该参数在历史各场洪水中的数值变化特征,考察各常见分布类型在描述CS的概率分布中的适用性。选出合适的分布类型之后,计算分布函数的参数,获取CS的先验概率分布。
(2)随机生成参数簇:根据CS的先验概率分布特征,随机生成维度为N的参数簇。
(3)构建预报信息库:基于以上N个参数,分别驱动新安江模型模拟所有场次的历史洪水,计算得到各场洪水的次模模拟结果。
在实时洪水预报中,步骤(2)中的参数簇可以在洪水预报之前生成,以降低运算量,保证实时性:步骤(3)中所提到的“历史洪水”为“当前场次以前的历史洪水”。
(4)训练BMA模型:根据成员数为Ⅳ的历史洪水预报结果的集合,训练BMA模型参数。受限于篇幅,此处不对相关技术细节作详细描述,可查阅文献。
(5)生成预报变量后验概率分布:设定后验分布的采样数目为L,然后将当前的Ⅳ个预报结果代人训练好的BMA模型中,基于蒙特卡罗采样方法生成成员数为L的预报变量的解集。当L值足够大时,该解集与预报变量的后验概率分布相似,可以认为该解集的分布情况反映了预报变量的后验概率分布特征,解集的均值可以视作预报变量的期望值。
在PROP算法中,模型参数的最优值无须提前预知,因此该算法能够避免洪水预报中不合理的参数取值对预报结果的负面影响;该算法仅依靠比较成熟、单一的新安江模型即可实现集合预报,无须引进其他模型,算法的实现简便:该算法能够提供变量的后验概率分布及期望等信息,比传统水文模型的信息更丰富,能够为防汛决策提供更多有价值的支撑信息。
2 试验流域及数据介绍
2.1 流域概况
本研究所选试验流域为东湾流域,位于东经lll°-112°、北纬33.0°-34.5°的伊河河源地区,流域面积为2856km2。流域地形西高东低,上游林地面积大,属大陆性季风气候区。降水量的年内分布极不均匀,每年7-9月降水量占年降水总量的一半以上。年降水量随高程增大而递增,因而山地为多雨区,河谷及附近丘陵为少雨区。降水年际变化较大,最大年降水量是最小年降水量的2倍左右。
2.2 流域数据
本研究共选择东湾流域1962-2011年的36场洪水用于数值模拟试验。模型参数率定中,采用先优化日模参数,再模拟各场次洪水初始时刻的流域土壤饱和程度,然后挑选出敏感次模参数的顺序。由于本研究所关注的是参数的不确定性程度及基于参数不确定性的相关理论方法,每场洪水的最优参数值不同,这就需要知道各场洪水中的最优参数值,因此每场洪水都需要优化,得到一个最优参数值。
根据《水文情报预报规范》(GB/T 22482-2008),本研究涉及洪水预报精度评定的地方,均统一采用NSE(Nash-SutCliffe EffiCiemcy coefficient)指标作为评价依据。以每场洪水的最优参数为依据分别执行预报并计算NSE指标值。统计结果显示,所选各场洪水均达到丙级以上精度,其中乙级以上32场,甲级以上11场,说明新安江模型在东湾流域适用性好,本研究的成果对于推进新安江模型在该流域及相似流域的应用具有一定的参考价值。
3 参数CS的先验概率分布
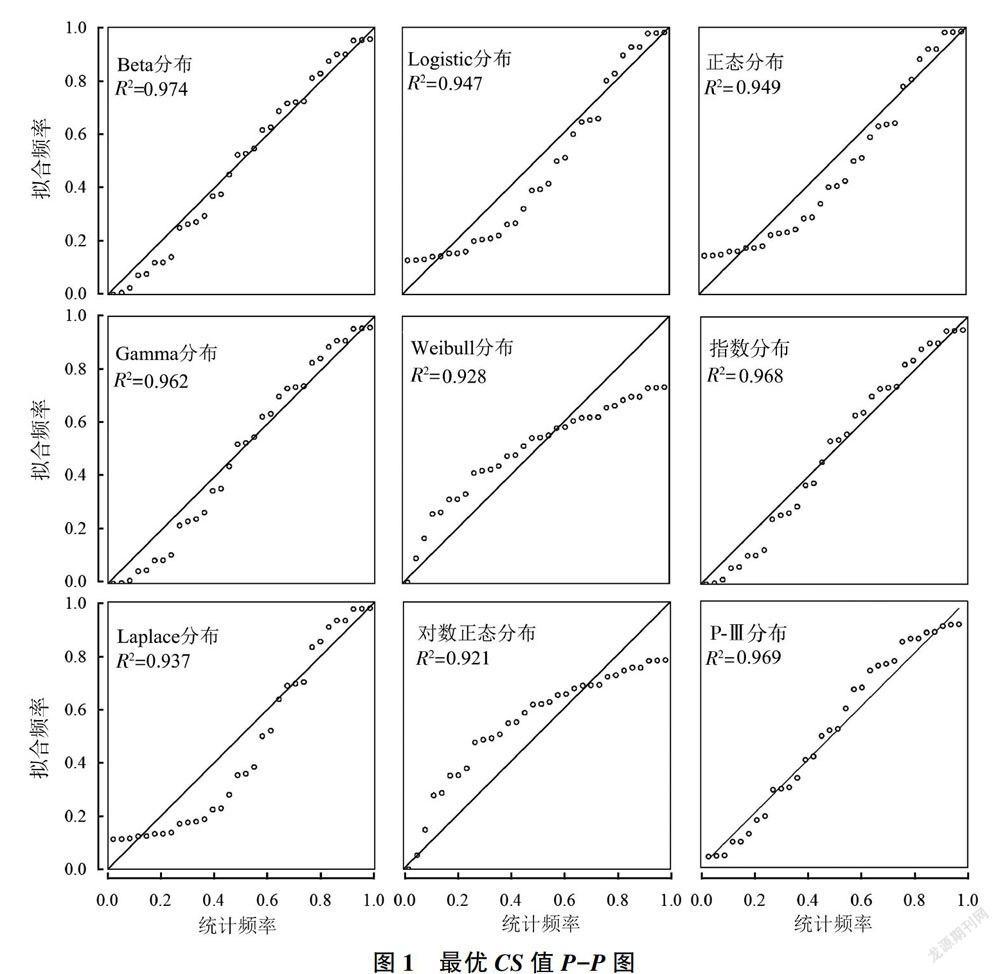
本研究利用SCE-UA算法,分别对每场洪水进行参数率定,以获取CS在每场洪水的最优值。计算所率定得到的36个CS参数值的累计概率值,并应用常见的Beta、Gamma、Laplace、Logistic、P-Ⅲ、Weibull(两参数)、对数正态、正态、指数分布共9种分布函数对CS值的统计概率分布点进行拟合。拟合情况见图1,横坐标表示直接统计最优CS值的频率,纵坐标表示相应CS值在不同分布类型中的频率估计值。
从图1可知,所选9个分布函数的确定性系数值均在0.9以上,各分布函数对最优CS值的拟合度均较高。Beta、P-Ⅲ相对于其他分布函数的表现更优,然而P-Ⅲ分布对较大CS值的拟合效果相对较差,因而可以认为Beta分布是这9个分布函数中最好的,适合描述不同场次洪水中最优CS值的概率分布。在确定参数CS所服从分布类型之后,记录其分布函数的各项参数值,随机生成L=50组不同的CS值。
4 原始预报集合获得
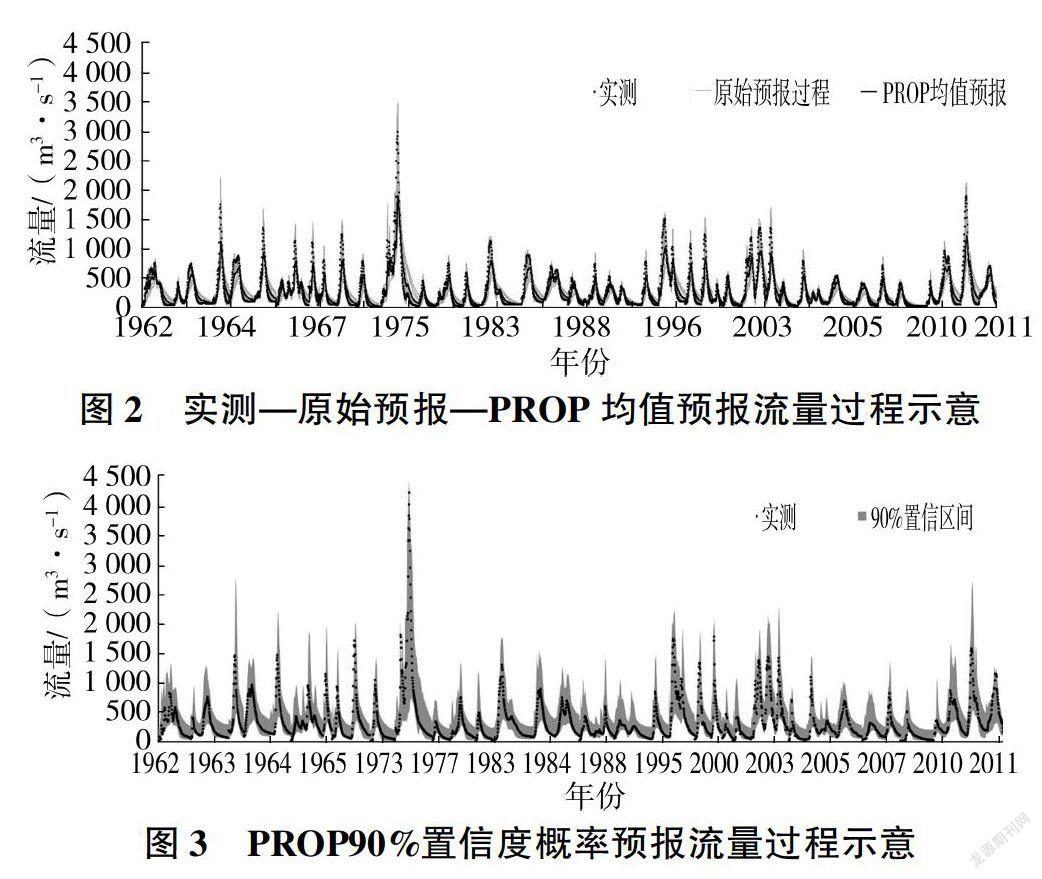
将随机生成的参数分别代人新安江模型,独立地对所选历史洪水进行模拟计算,获得集合预报成员数为50的预报值序列,并结合对应的实测数据对BMA模型进行训练。针对每场洪水,利用训练好的BMA模型综合50个原始预报结果进行集合预报运算。图2、图3分别展示了实测-原始预报-PROP均值预报流量过程比较、PROP概率预报流量过程。限于篇幅,将36场洪水彼此首尾相连,绘制在同一张图上,由于图示相邻两时刻的时间跨度可能比较大,因此图中洪水过程并不代表1962-2011年完整的流量过程,仅用于说明各集合预报成员及PROP在这36场洪水中的表现。
由图2可知,基于随机参数所构建的各集合预报成员,模拟得到流量过程的总体趋势与实测结果相差不大,但是仍然可见大量的原始预报结果偏离实测值。各集合预报成员所选CS参数值不同,是各自预报结果之间产生显著差异的唯一原因,这进一步印证了参数不确定性会导致预报结果显著发散现象,也强调了参数不确定性应作为水文预报中必须考虑的一个重要因素。PROP算法均值预报结果与实测流量的总体变化趋势一致,这说明基于PROP算法进行洪水预报时,其确定性预报结果更为稳定、可靠,且无须事先进行参数率定,可以避免参数不确定性导致的计算精度降低。
5 概率预报结果的获得与分析
常采用90%置信区间来表征预报变量的概率分布情况,置信区间中的实测点占全部实测点的比例(CR,覆盖率)被认为能够反映概率预报结果的可靠性。CR的取值范围为[0,1],CR越大,实测点落在置信区间内的比例越大,依据概率预报结果发生漏报的可能性越小。
由图3可知,PROP所提供的90%置信区间基本上能够将实测的低、中、高水部位包含在内,CR达到93.0%。PROP算法在洪峰部位的预报结果可靠性高,所选36场洪水中有31场的实测洪峰流量落在概率预报的置信区间之内,例如在1975年大洪水中,实测洪峰流量为4200m3/S,对应的PROP预报90%上、下限分别为4430m3/s与490m3/S。综合PROP的概率预报结果对整体及洪峰附近洪水过程的匹配程度,可以认为该模型所获得概率预报结果较为可靠。
6 结论
本研究基于水文模型的参数存在显著不确定性的客观事实,以随机生成的参数驱动水文模型,并结合数值模型构建PROP算法实现集合预报。通过东湾流域36场洪水模拟试验,揭示了水文参数不确定性对洪水预报结果的显著影响,并验证了PROP所提供的确定性及概率预报结果的精确性、可靠性,证明PROP能夠降低水文模型参数所带来的洪水预报不确定性。
在实际洪水预报中,参数的优选往往依靠经验判断或者依赖于历史库中的不完备数据集数据进行自动优化,由于洪水特征无法准确预知,甚至在一场洪水中不同的阶段所要求的参数值也存在较大差异,因此所选参数并不一定适合当前洪水的预报。PROP算法的提出,针对在考虑参数不确定性的条件下实现准确的洪水预报的问题,提出了一个可靠的解决方案。该算法强化了对参数概率分布特征的描述,弱化了对求解最优参数值的要求,降低了参数不确定性导致产生较差预报结果的可能性:依赖现有较为成熟的BMA模型,为洪水预报工作提供更为丰富、可靠的预报信息,对于完善并提高现有的洪水预报技术具有参考价值。
本研究所采用的参数仅仅针对单一的参数CS,实际洪水预报中往往有多个参数存在明显不确定性,如何准确描述多参数的联合概率分布,以及如何在洪水预报中同时考虑多参数不确定性的影响,是一个有价值的研究方向。
