基于改进Dijkstra算法的配用电通信网流量调度策略
2018-08-28向敏,陈诚
向 敏,陈 诚
(重庆邮电大学自动化学院,重庆400065)(*通信作者电子邮箱804652105@qq.com)
0 引言
随着智能电网的发展,允许用户积极参与到用电管理和故障报告中,以提高电网的自愈能力、即插即用能力和互操作性[1]。配用电通信网包含多层体系结构,为了确保电网的安全可靠运行,建立一个高效、可靠、安全的实时电力数据采集双向通信系统将成为支撑智能电网快速发展的关键技术之一[2-3]。
有线和无线相结合是现有电力数据采集使用最广泛的通信方式,由于现有业务量的大量增加,已无法满足配用电通信网的发展要求[4]。无线通信技术的发展使配用电通信网具备了灵活、易接入、低成本等优势,已逐渐成为配用电网通信基础设施的首选。为了实现配用电通信网对用户区域无缝覆盖,无线多跳通信具有网络自组织、自愈性以及可靠性等性能,相较于单跳长距离传输更能满足智能电网通信需求[5-6]。
基于无线mesh网络的智能电网数据采集网络,安装集成无线通信模块且具有路由和一定缓存功能的中继节点,可以视为一个mesh节点[7]。对于居民区按照一定数据采集规模分为多个子网区域,每个子网区域存在一个子网网关,最后所有数据汇聚到主网关并与远程数据管理中心通信。该网络架构下不仅要考虑物理层、多路访问控制(Multi-Access Protocol,MAC)协议等满足智能电网通信网络需求,还应考虑应用层时变的数据流量对网络性能的影响[4]。例如,电力故障情况下,大量故障信息的产生和传输导致网络数据流量负载迅速增大,这样就可能造成某些中继节点数据量增大,极有可能产生拥塞,导致网络吞吐量下降,影响数据通信的实时性和可靠性。
由于智能电网的数据均与电网业务相关,是电网决策和数据分析的基础,因而智能电网通信网需要具有良好的实时性、准确性和可靠性。文献[7]对多网关联合网络进行了分析,以节点队列长度为主要指标,采用队列加权的方法提出了流量调度算法。文献[8]提出了一种多网关mesh结构,将多个局域mesh子网联合成为一个有主网关进行管理的多网关网络,任意智能电表既是数据源节点也是中继节点,且所有电表可以向任一子网关传输数据。文献[9]提出了用于智能电网认知无线电通信基础设施基于优先级的流量调度方法,考虑了智能电网业务流量的异构性,将数据流量分为了三个优先类别。文献[10]分析了传统背压算法在数据流量负载较大的情况下不能有效减少端到端时延的缺点,提出与最短路径相结合的背压算法,通过最小化源节点和目的节点的间路径长度以减少时延。文献[11]综合考虑跳数和mesh节点队列长度,提出了多网关单级背压调度算法。文献[12]提出了随机切换流量调度算法,以缓解紧急状况数据流量增大时某些处于关键位置智能电表的数据拥塞。文献[13]提出了一种贪婪背压路由算法,通过节点到达最近网关的跳数和流量负载计算获得贪婪背压度量值,根据最陡梯度方向路由数据包。文献[14]提出一种确定性路由和机会性路由相结合的路由协议,各节点从其邻居节点中选择出候选节点集传输数据,以避免瓶颈节点的产生。
随着智能电网业务的不断增加,配用电通信网数据采集网络将面临极大的数据流量压力,为缓解智能电网数据流量突增造成拥塞并均衡网络流量分布,本文提出一种基于改进Dijkstra的路由算法——DDTA(Data-balance and improved Dijkstra Traffic-scheduling Algorithm),以跳数、流量负载率和链路利用率作为路径选择的综合指标,优化配用电通信网络中的下一跳节点选择。构建业务调度模型,对重度拥塞节点进行业务调度,以保证高优先级业务的服务质量。
1 配用电通信网络流量调度模型
考虑到对用户区域的无缝覆盖,基于无线多跳网络的配用电数据采集网络能够有效提高用户电力数据采集和传输的实时性、完整性和可靠性。每个邻域网(Neighborhood Area Network,NAN)由多个mesh子网组成,每个mesh节点表示每个子网中可以接入本地网关的数据采集点。数据聚合点即为通过有线或无线链路与主网关进行通信的子网关。为了简化配用电通信网络的网络拓扑图以及便于节点管理,依据源节点到达目的节点的最少跳数对节点进行分层。由于越靠近网关的节点其负载越重,根据节点当前状态划分节点拥塞程度,对于重度拥塞节点进行业务调度尽可能避免高优先级业务的丢失。
1.1 配用电数据采集网络节点分层模型
采用有向图模型G(N,L)来表示整个配用电通信网的网络拓扑,N表示网络中所有节点集,L则表示网络中节点间链路集合。lij表示从节点i到节点j的有向边,由于网络中的链路均可双向传输数据,则lij∈L,lji∈L。eij表示节点i到节点j的有向链路边权值。设定最大跳数阈值为H,则可将所有数据采集节点分为H层,以到达网关的最少跳数对mesh子网中的数据采集节点进行分层。
以图1中mesh网络为例,将配用电数据采集网络中与主网关直接通信的子网关0作为第0层节点;只需单跳便可把数据传输到网关的节点1、2、3和4作为第1层节点;到达网关最少跳数为2的节点5、6和7作为第2层节点;到达网关最少跳数为3的节点8作为第3层节点。

图1 数据采集网络节点分层结构Fig.1 Node hierarchical structure for data acquisition network
1.2 配用电通信网业务调度模型
配用电通信业务的QoS需求主要包含时延、丢包率和数据速率等指标。参照《电力系统通信设计技术规定》将智能电网通信业务分为3类,分别用P1、P2、和P3标识业务等级;P1表示智能电网用于控制、保护和管理的紧急型业务,如纵联网络保护;P2表示智能电网中对实时性要求较高的关键型业务,如高级量测体系(Advanced Metering Infrastructure,AMI);P3表示智能电网中允许一定时延的常规型业务,如用电信息采集。等级标识越低业务优先级越高。三类配用电业务特性如表1所示。

表1 三类配用电业务特性Tab.1 Characteristics of three types of power distribution and utilization service
本文通过预先设置数据包IP报文中差分服务代码点(Differentiated Service Code Point,DSCP)值以辨识所划分的业务类型以及优先级,IP包头中区分服务字段中的TOS字段中DSCP值设置如表2所示,DSCP值的前四位表示配用电业务的优先等级,后四位用以表示配电点业务类别。

表2 DSCP值的二进制编码Tab.2 Binary encoding for DSCP
设节点i中的缓存队列长度为Qi,节点i数据到达率为vi,节点i数据生成数据为v0i,数据转发率为ui,一个数据处理周期为T,节点缓冲区拥塞阈值为QT;则当前时刻节点中缓存队列长度为:

依据节点数据处理能力和缓存队列长度将节点拥塞度划分为3个等级,节点拥塞度等级划分规则如下:
1)若ui≥(vi+),随时间增加节点缓存队列中数据包数量会逐渐减少,节点i不易发生拥塞,其拥塞等级为Ⅲ。
2)若ui<(vi+)且Qi(t)<QT,随时间增加节点缓存队列中数据量可能增大至拥塞阈值,节点i可能发生拥塞,其拥塞等级为Ⅱ。
3)若ui<(vi+)且Qi(t)≥QT,随时间增加节点缓存队列中数据量可能溢出缓存区,节点i极易产生拥塞,其拥塞等级为Ⅰ。
节点拥塞等级标识越低则节点发生拥塞的可能性越大。
若节点为拥塞等级为Ⅰ或Ⅱ时,则对该节点缓存区中的数据包按照业务优先级进行调度,尽可能减少紧急型业务的丢包率。假设t时刻拥塞节点i缓存队列中有6个(S1,S2,…,S6)不同优先级的数据包,按照如图2所示的方法对该节点中的数据进行调度。

图2 拥塞节点缓存队列调度过程Fig.2 Scheduling process for cache queue of congestion nodes
对易产生拥塞节点中的数据缓存队列按照业务优先级进行调度之后,从队尾丢弃优先级较低的业务,并发送消息通知被丢弃业务的源节点重新进行路由选择。同时对拥塞节点的上一跳节点重新进行路由选择,以避免数据的继续丢失。由于重新路由选择要避开负载较重的节点并选择出最优路径,本文利用链路跳数、流量负载率和链路利用率求取复合边权值,利用改进的Dijkstra算法获得最优路径。
2 基于复合边权值的流量调度算法
在智能电网通信网络中业务流量从终端采集设备逐渐集中至网关,越靠近网关的节点其业务量越大越容易造成数据丢失,为避免拥塞节点的产生并提升网络性能,对于分层网络拓扑图边值计算引入三个度量值:跳数指标、流量负载率指标和链路利用率指标,综合考虑下一跳路径的选择。
2.1 跳数
网络中的节点定期与其周围的邻居节点交换信息,设节点i到达距其最近的网关的最少跳数为。为了简化智能电网数据采集网络模型,规定任意节点i的邻居节点列表中只包含上层和同层邻居节点,即节点i只能从(-1)层和Hi层的邻居节点中选择下一跳节点;且第一层节点只能选min择网关作为下一跳节点。本文还利用跳数来间接表示节点间的距离。在此将节点i和节点j到达距其最近目的网关的最少跳数之差作为跳数指标,如式(2)所示:

2.2 流量负载率
根据文献[15]利用梯度模拟节点缓存队列,节点按照最陡梯度感知节点中的数据流量分布,从而在数据传输过程中规避拥塞节点。本文定义节点i到节点j的有向链路lij的流量度量为 (lij),令Qij表示节点i到节点j的队列长度,Mi为节点i的邻居节点数,且M=max(Mi)。节点i到节点j链路lij的流量负载度量如式(3)所示:
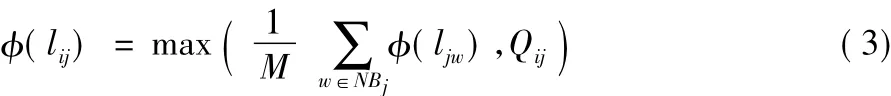
式中:NB(j)为节点j的邻居节点集合;w为j的邻居节点即w∈NB(j)。节点i的流量负载度量如式(4)所示:

式中:max和min分别表示节点i的输出链路中流量度量值的最大值和最小值。节点i向j传输数据的归一化流量负载率如(5)所示:

式中:Cij表示链路代价度量值。TM越大则表示节点i与其邻居节点链路lij之间流量负载值差异越大,节点i向节点j传输数据的趋势越明显。
2.3 链路利用率
文献[16]定义链路的使用率为链路上业务流总速率和链路的有效传输速率的比值。本文采用链路上业务流总速率与网络传输速率的比值作为链路度量值。GW为网关集合,P为各业务流到达网关的路径集合,F为业务流集合,业务流f在路径p上的速率为,则业务流f的总速率为x(lij,p)=1 表示链路 lij在路径 p上,否则 x(lij,p)=0。经过链路lij的业务流总速率为路lij的链路度量值,即为链路利用率,如式(6)所示:
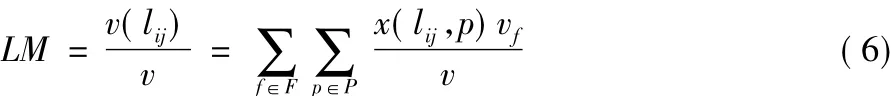
式中v即为网络数据传输速率。
2.4 复合边权值
有向图模型G(N,L)中的边权值综合考虑了跳数、流量负载率和链路利用率,定义网络拓扑图中节点i到节点j的有向边权值为eij,如式(7)所示。

式中α、β和γ分别为跳数、流量负载率和链路利用率指标的加权系数,取值范围为[0,1],且 α + β + γ =1。加权系数 α、β和γ可以依据文献[18]中的多业务权值分配方法,依据配用电紧急型、关键型和常规型三类业务需求偏好求取权值。
3 算法描述
本文结合最少跳数构建节点分层网络拓扑结构与Dijkstra算法[17],利用跳数、流量负载率和链路利用率综合求取越大越优有向边权值,求取所有边权值最大的链路相邻的节点即为下一跳优先节点。最坏情况下需要遍历网络中所有节点以选取最优路径,此时算法的时间复杂度为O(n2)。算法具体步骤如下:
步骤1 网关收集更新网络中所有节点的信息,并依据源节点到达距网关的最少跳数构建最短路径节点分层模型,删除信号强度小于阈值的邻居节点。
步骤2 初始时刻t,各节点交换状态信息,维护各节点的邻居节点信息表。对于Ⅰ级拥塞节点断开该节点的所有输入链路,并在(t-T)时刻向该节点传输数据的所有邻居节点列表中删除该拥塞节点;对于Ⅱ级拥塞节点则断开同层节点的输入链路,并在(t-T)时刻向该节点传输数据的同层邻居节点列表中删除该中度拥塞节点。T为一个数据处理周期。
步骤3 依据本节点信息和获取的邻居节点信息计算有向边复合权值,并构建链路边权值矩阵Eij,其中的元素eij表示节点i指向节点j链路边权值,若节点i与j没有直接相邻,则eij=0。
步骤4 使用Dijkstra算法求取从源节点到达目的网关边权值之和最大的路径。
步骤5 网络因突发状况产生链路中断时,则在数据源节点与邻居节点重新交换信息并更新邻居节点列表,重新调用Dijkstra算法求取新的路径。
4 仿真结论与分析
采用Matlab对本文算法DDTA进行仿真测试,为验证算法优越性,在相同条件下与最短路径(Shortest Path Fast,SPF)算法、贪婪背压算法(Greedy Backpressure Routing Algorithm,GBRA)的丢包率、端到端平均时延和网络吞吐量进行对比。
本章采用1个局域网关及36个随机分布的数据采集节点构建多网关多跳数据采集网络。仿真过程中,所有节点数据生成速率相同,假设网关不限带宽。其中α、β和γ的取值参照文献[18]的权值求取方法,并经过多次仿真获取最优取值,该系数可以依据业务需求和网络状态进行相应调整。依据配用电通信网实际运行过程中配用电业务的数量设置紧急型、关键型和常规型业务生成比率。网络仿真环境的相关参数设置如表3所示。

表3 网络仿真环境参数Tab.3 Network simulation environment parameters
4.1 平均端到端时延
端到端的时延主要分为传输时延和等待时延,传输主要与跳数相关,而等待时延即为业务流在传输路径中排队等待时间。假设节点的数据流f到达网关所经过的跳数为h,单跳传输时延为th,节点发送一个数据包的时延tp,则业务流的端到端时延如下:

对仿真区域内的所有节点进行时延性能仿真,仿真结果如图3所示,图3中本文算法端到端时延为三类业务从源节点到达目的节点的平均时延。当节点数据生成速率较小时,本文算法DDTA与GBRA平均端到端时延相当;随着节点数据生成速率增大,节点缓存队列长度增加使得平均端到端时延增大。本文所提算法路由选择综合考虑了跳数和节点数据流量负载,在一定程度上规避了向拥塞节点传输数据,从而减少了传输时延和等待时延。随节点数据生成速率增大,本文所提算法平均端到端时延小于GBRA和SPF,提高了配用电通信网络业务传输的可靠性。

图3 不同算法平均端到端时延对比Fig.3 Comparison of average end-to-end delay of different algorithms
本文算法仿真环境下,紧急型业务、关键型业务和常规型业务的平均端到端时延对比如图4所示。由图4中可以看出,由于所提算法在拥塞节点处优先传输紧急型和关键型业务,从而减少了这两类业务数据包的排队时延,因而传输紧急型和关键型业务的平均端到端时延小于常规型业务。随着节点数据生成速率增大,易拥塞节点优先保障紧急型业务的传输,其次才是关键型,因而紧急型业务的端到端时延低于关键型。本文的流量调度策略通过对易拥塞节点进行业务调度,保证了配用电通信网中重要业务的时延特性。
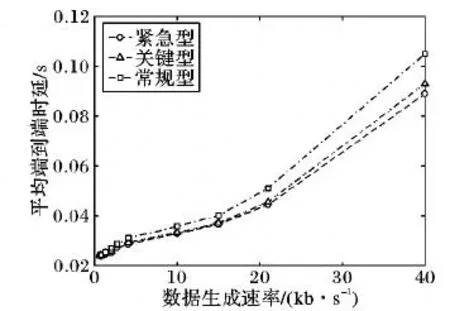
图4 不同业务平均端到端时延对比Fig.4 Comparison of average end-to-end delay of different services
4.2 丢包率
紧急型、关键型和常规型三类配用电业务在本文算法DDTA、最短路径(SPF)算法和贪婪背压算法(GBRA)下丢包率仿真结果如图5所示。
数据生成速率对紧急型业务数据包丢失率的影响,仿真结果如图5(a)所示。从图5(a)可知,本文所提算法的紧急型业务数据包丢失率低于SPF和GBRA。具体而言,在数据生成率为80 kb/s时,本文所提算法的紧急型业务丢包率相比SPF和GBRA分别减少了81.3%和67.7%。由于本文研究对拥塞节点进行了业务调度以保证紧急型业务优先传输,因而随数据生成速率的提高本文所提算法中紧急型业务丢包率较小且增长较缓慢。
图5(b)为三种算法关键型业务丢包率仿真结果。从图5(b)中可知,本文所提算法的关键型业务丢包率低于SPF和GBRA。当节点数据生成速率为80 kb/s时,本文算法较SPF和GBRA关键型业务丢包率分别减少了79%和63.8%。本文算法在易拥塞节点处优先保证紧急型业务的传输,次之保证关键型业务的传输,因而随着节点数据生成速率逐渐提高本文所提算法中关键型业务丢包率增长较其他两种算法慢。
图5(c)为三种算法常规型业务丢包率仿真结果。从图5(c)中可以看出,本文算法常规型业务丢包率和GBRA相当,低于SPF,这是因为本文所提算法常规型业务优先级最低,在易拥塞节点处以牺牲常规业务而减少紧急型和关键型业务丢包可能性。
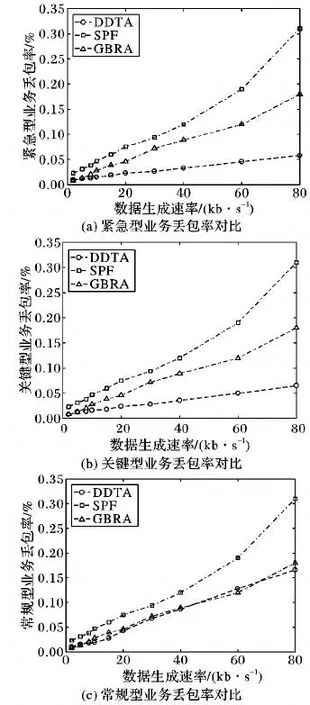
图5 不同业务丢包率对比Fig.5 Comparison of packet loss rate of different services
4.3 网络吞吐量
网络的有效吞吐量为单位时间内目的网关接收的数据量与网络中所有节点数据生成量的比值。图6分析了网络中目的网关有效吞吐量和节点数据生成速率的关系。随着数据生成速率的增大网络逐渐趋于饱和,更多的数据滞留在节点缓存队列中或者丢失,使得网络的有效吞吐量随着数据生成速率增大而逐渐降低。由于本文所提算法综合考虑了链路负载和链路利用率,因而均衡了配用电通信网络的流量分布,并提高了网络利用率。

图6 不同算法有效吞吐量对比Fig.6 Comparison of effective throughput of different algorithms
5 结语
针对智能电网通信网络数据采集汇聚过程中,因网络中业务流量分布不均匀造成某些关键节点易产生拥塞的问题,本文提出了一种基于复合边权值的负载均衡的Dijkstra路由算法。依据节点当前状态划分节点拥塞等级,对于中度拥塞节点进行业务调度以保证紧急业务优先传输。综合考虑链路跳数、流量负载率和链路利用率求取复合边权值,利用改进的Dijkstra算法求取最优路径。仿真结果表明本文所提算法在节点数据速率增大的情况下能有效降低网络端到端平均时延和丢包率,提高网络吞吐量,改善了电力通信网数据采集网络的通信性能。本文仿真是在简化的理想模型中进行仿真,下一步将结合实际的配用电通信网数据进行仿真,测试并完善算法。
