基于共享近邻相似度的密度峰聚类算法
2018-08-28鲍舒婷孙丽萍郑孝遥郭良敏
鲍舒婷,孙丽萍* ,郑孝遥,郭良敏
(1.安徽师范大学计算机与信息学院,安徽芜湖241002; 2.网络与信息安全安徽省重点实验室(安徽师范大学),安徽芜湖241002)(*通信作者电子邮箱slp620@ahnu.edu.cn)
0 引言
聚类是数据挖掘中重要的研究领域之一,用来分析数据的分布。聚类是一个将数据对象划分成若干个类簇的过程,使得簇中的对象相似度高,但每个簇之间的对象相似度低。聚类在模式识别、分类、图像处理、Web搜索、商务智能等领域都有广泛的研究。聚类方法主要分为以下几类:基于层次聚类、基于划分聚类、基于密度聚类以及基于图聚类。
K-means算法[1]是基于划分聚类的经典算法,该算法是通过多次迭代找到最佳聚类中心,根据样本到聚类中心点的距离对样本进行划分。由于K-means算法是将样本分配到与其最近的簇中,因此该算法不能发现任意形状的簇。如果初始聚类中心选择不好,结果很容易陷入局部最优,导致聚类结果不稳定[2]。基于密度的空间聚类(Density-based Spatial Clustering of Applications with Noise,DBSCAN)算法[3]是基于密度聚类的经典算法,该算法是通过定义邻域半径eps和样本的最小邻域个数minpts来决定样本分布的紧密程度。但是,该算法对参数eps较为敏感,较小的eps值可能会导致过度聚类的情况,较大的eps值可能会使得较小的簇被合并。标准谱聚类(Spectral Clustering,SC)算法[4]是基于图聚类的经典算法,利用矩阵谱分析理论对原始的数据对象进行提取,得到新的数据特征,实现过程较为简单,但聚类结果依赖于相似矩阵。
文献[5]提出了基于密度的密度峰聚类 (Density Peaks Clustering,DPC)算法,简单高效,无需迭代;同时,不需要考虑概率分布函数或将数据映射到向量空间,性能不受数据空间维度影响[6]。但存在一些缺陷:算法需要设置截断距离dc,算法的准确性需要依赖dc的选择和对数据集的密度估计;算法使用欧氏距离定义样本之间的相似性来计算局部密度,存在局限性;聚类中心的选择需要人工干预等。
近年来,DPC算法得到了广泛的研究。文献[7]首先对数据集进行主成分分析处理,再将k近邻引入样本局部密度计算中,对聚类结果进行了优化。文献[8]提出基于DPC的模糊聚类算法,自适应地寻找聚类中心的个数,而不需要预先指定类簇个数。文献[9]基于热扩散技术提出一种非参数的估计给定数据集的概率分布的DPC改进算法。但是以上算法都没有考虑到样本之间相似性度量和聚类中心自适应选择的问题。
针对以上缺陷,本文提出一种基于共享近邻相似度[10]的密度峰聚类算法(Density Peaks Clustering algorithm based on Shared Near Neighbors Similarity,DPCSNNS)。该算法将共享近邻相似度和欧氏距离相结合计算样本之间相似度,避免了dc的设置,更精确地计算样本间相似度。同时,该算法给出了一个新的聚类中心选择策略,使得该算法能自适应地进行聚类中心的选择。
1 相关工作
1.1 相关记号
假定数据集 XN×M=[x1,x2,…,xN]T,对于任意向量xi=[xi1,xi2,…,xiM]表示样本xi(1≤i≤N)的M个属性,N为样本总个数。聚类是将数据集X中的样本划分成L个类簇C={C1,C2,…,CL}。在聚类评价过程中,本文使用 R={R1,R2,…,RL}来表示标准分类结果,{γi}={γ1,γ2,…,γN}。聚类结果要尽可能满足如下两个要求[11]:1)簇内样本相似度高;2)簇间样本相似度低。
1.2 密度峰聚类算法
密度峰聚类算法基于一个假设条件,该条件是:理想的聚类中心被密度较低的邻居样本包围并且与另一个更高密度样本之间的距离相对较远。DPC算法主要有三个步骤:第一步,通过度量每一个样本的局部密度ρ和距离δ得到决策图(Decision Graph);第二步,根据聚类中心的特征,在决策图上选择最佳的聚类中心;第三步,将剩余样本分配到距其最近并拥有较高密度的样本所在类簇中。
原始的DPC算法通过欧氏距离度量样本xi和xj之间的相似性,计算公式如下:
为了找到理想的聚类中心,原始的DPC算法需要计算每一个样本局部密度ρ和距离δ,样本xi的局部密度ρi计算公式如下:
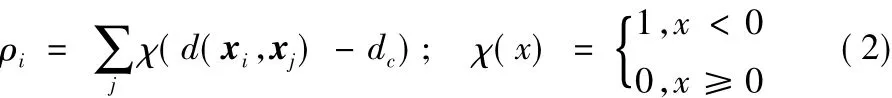
其中:ρi就等于所有到xi的距离小于dc的样本的个数。参数dc是截断距离,DPC算法给出了dc选择的标准:使样本的平均近邻个数是整个数据集规模的1% ~2%[12]。针对小规模数据集,DPC算法采用指数核[13]计算样本的局部密度来提高聚类中心选择的准确性,具体的计算公式如下:

原始的DPC算法需要计算样本的局部密度和距离来选择聚类中心,样本xi的距离δi为xi到其他较高密度样本之间的最短距离,如果xi已经是最高密度的样本,δi就等于xi到其他样本的最大距离,具体计算公式如下所示:

根据计算后的局部密度ρi和距离δi得到决策图,DPC算法根据决策图确定最佳的聚类中心需要人工干预。由式(2)~(4)可见,若一个高密度样本与另一个更高密度样本相距较远,则该样本为聚类中心的可能性较大,即理想的聚类中心为高δ值和相对较高的ρ值的样本。因此,在文献[5]中采用式(5)进行聚类中心的选取:

在聚类中心选出后,DPC算法对剩余样本进行分配。根据样本的距离δ,将剩余样本分配到距其最近并拥有较高密度的样本所在类簇中。DPC算法的具体描述如算法1所示。
算法1 密度峰聚类算法(DPC算法)。
输入 数据集XN×M,类簇个数L;
输出 聚类结果C={C1,C2,…,CL}。
1)根据式(2)或式(3)计算样本的局部密度;
2)根据式(4)计算样本的距离;
3)根据决策图选择聚类中心;
4)将剩余样本分配到距其最近并拥有较高密度的样本所在类簇中;
5)返回聚类结果C。
2 基于共享近邻相似度的密度峰聚类算法
原始的DPC算法主要存在以下两个缺陷:1)在样本局部密度度量中,使用欧氏距离度量样本间的相似度存在局限性,并且dc的选择存在一定主观性,对聚类结果影响较大[7]。例如,当两个簇的密度相差较大时,两个簇的聚类中心的局部密度也应该相差较大;但是,如果dc比较小,就会使得两个聚类中心的局部密度相近,使得聚类效果不理想。2)在聚类中心的选择上,根据决策图选择聚类中心需要人工干预[14];如果使用式(5)选择聚类中心,往往会忽视样本较少、局部密度较低的簇。
为了解决上述问题,本文提出了一种基于共享近邻相似度的密度峰聚类算法(DPCSNNS)。DPCSNNS在局部密度的计算和聚类中心的选择上引入共享近邻相似度的概念,有效地避免了DPC算法因dc的选择导致聚类结果较差和根据决策图选择聚类中心需要人工干预的缺陷。
2.1 局部密度的计算
DPC算法将dc作为全局密度阈值来计算样本的局部密度,但如果存在一个数据集不同簇之间分布差异较大,通过决策图选取聚类中心的准确性较低。本文将k近邻集的概念引入局部密度的计算中,这样就避免了参数dc的选取。本文给出定义1。
定义1 k近邻集。将数据集X中的样本xi到其他样本的欧氏距离升序排列,取第k个距离记作dki,则样本xi的k近邻集KNN(xi)定义如下:

两个样本之间的共享近邻个数越多,说明这两个样本越相似,它们所在一个簇的可能性就越大。DPC算法将欧氏距离作为判断两个样本之间相似性的唯一标准来计算样本的局部密度,局限性较强,本文将共享近邻相似度和欧氏距离两种准则进行统一,提出了新的基于共享近邻相似度的局部密度计算方式,更能反映出数据集中样本的分布特征。本文给出定义2和定义3。
定义2 共享近邻相似度。KNN(xi)为样本xi的k近邻集,KNN(xj)为样本xj的k近邻集,则样本xi和xj的共享近邻相似度SNN(xi,xj)定义如下:

定义3 样本局部密度。样本xi的局部密度定义如下:

2.2 聚类中心选择策略
DPC算法选择聚类中心需要人工干预,或者使用式(5)进行聚类中心的选择,但是错误率较高。聚类中心的错误选择,会直接导致样本的错误分配,所以本文给出了一种新的聚类中心选择策略,其步骤如下。
步骤1 初始化聚类中心队列Q。
步骤2 根据式(5)计算{γi},并将样本集 XN×M按{γi}N
i=1降序排列,记为{。
步骤5 若队列Q中样本个数小于等于类簇个数,转步骤4;否则,返回Q,结束。
2.3 算法流程
本文提出的DPCSNNS首先根据式(7)计算每个样本之间的共享近邻相似度,根据式(8)和式(4)计算样本的局部密度和距离,再根据聚类中心选择策略选择聚类中心,最后对剩余节点进行分配,DPCSNNS伪码如算法2所示。
算法2 基于共享近邻相似度的密度峰聚类算法(DPCSNNS)。
输入 数据集XN×M,类簇个数L;
输出 聚类结果C={C1,C2,…,CL}。
normalized XN×M;
for i←1 to N
for j←1 to N
calculate SNN(xi,xj)by Equation(7);
end for
end for
for i←1 to N
calculate ρiby Equation(8);
calculate δiby Equation(4);
calculate γiby Equation(5);
end for
initialize Q and C;
while length(Q)≤L
//判断Q中样本个数是否小于等于类簇个数L
end if
end for
end while
assign each remaining sample to the cluster Cj∈ C(j=1,2,
…,L)as its nearest neighbor with higher density;
//将剩余样本分配到离它最近并拥有较高密度的样本所在类簇中
end if
end for
return C
DPCSNNS流程如图1所示。
3 实验与结果分析
3.1 实验环境
实验采用Matlab 2013b编程实现,硬件配置为Windows 7操作系统、4 GB物理内存、CPU为1.9 GHz的计算机。
实验参数设置如下:对于DPCSNNS,本文设置近邻个数k=6;对于DBSCAN算法,首先根据文献[3]算法思想给出dist图,根据dist图设置minpts=4,eps设置为图中拐点处纵坐标;对于K-means算法,最大迭代次数设置为1000,对每个数据集进行20次独立的K-means算法实验,实验结果取20次重复实验的平均值。为了方便数据的处理,本文首先对数据集进行归一化处理,将数据集中样本映射到[0,1]内,计算式如下:

其中:Xmax为数据集X中当前属性的最大值;Xmin为数据集X中当前属性的最小值。
3.2 评价指标
为了验证本文提出的DPCSNNS的有效性,实验在UCI数据集和模拟数据集上进行了仿真,采用准确率(ACCuracy,ACC)[15]、标 准 化 互 信 息 (Normalized Mutual Information,NMI)[16]、F 值 (F-Measure)[17]三种评价指标对聚类结果进行评价,并将本文算法与DPC算法、DBSCAN算法、K-means算法、SC算法进行比较。这三种评价指标范围是[0,1]。准确率将算法得到的类标号和正确的类标号进行比较,记录了正确分类样本个数占总样本的比值,数值越高表示聚类的质量越好。计算式如下:

其中:ri表示样本xi正确分类时的类标号;ci表示算法得到的样本 xi的类标号,当ri=ci时,ω(ri,ci)=1,否则ω(ri,ci)=0。

图1 DPCSNNS流程Fig.1 Flow chart of DPCSNNS
NMI量化聚类结果和已知类别标签的匹配程度,NMI值度量了聚类结果的鲁棒性,计算式如下:

其中:H(R)为正确分类R的熵;H(C)为算法得到的聚类结果C的熵。
F-Measure指标综合了精度(precision)和召回率(recall)两种评价指标,其优势在于对聚类结果优劣的整体区分能力。精度评估聚类结果的精确程度,计算方式如式(13)所示;召回率评估实验结果的完备程度,计算方式如式(14)所示;F-Measure的计算方式如式(15)所示:


其中:TP表示在R中为同一类的样本在C中也被分到同一类;FP表示在中R为不同类的样本在C中被分到同一类;FN表示在R中为同一类的样本在C中被分到了不同类;R为正确分类,C为算法得到的分类。
3.3 UCI数据集实验结果与分析
为了验证DPCSNNS的可用性,本文从UCI机器学习库(http://archive.ics.uci.edu/ml/)中选取了 8 个完全不同的样本规模、维数和类簇个数的UCI数据集进行仿真实验,数据集的基本特征如表1所示。
本文实验中采用当β=1时的F-Measure:
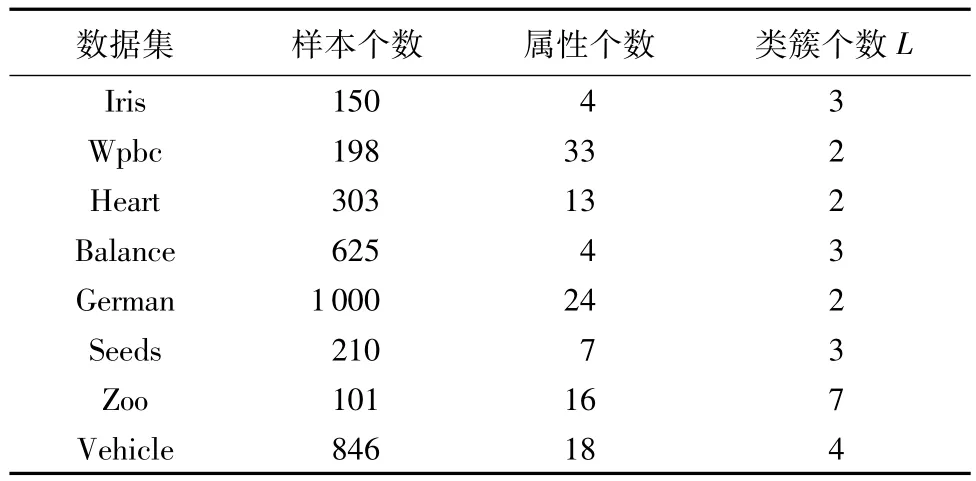
表1 实验使用的UCI数据集Tab.1 UCI datasets used in the experiment
针对UCI数据集,本文提出的DPCSNNS与对比算法的实验结果如表2所示。
从表2中可以看出,使用ACC指标评价算法,本文提出的DPCSNNS在8个UCI数据集上都优于其他算法,并且相较于原始DPC算法有了较大的提高。其中:对于鸢尾花卉数据集Iris,本文算法ACC指标较原始DPC算法提高了60.3%;对于动物园数据集Zoo,本文算法的ACC指标较DPC算法提高了94.9%;使用NMI指标评价算法,本文提出的DPCSNNS在7个UCI数据集上都优于其他算法;对于车辆数据集Vehicle,本文算法的NMI指标比SC算法高出68.6%;对于心脏病数据集 Heart,本文算法比 K-means算法的 NMI指标高出148.1%;使用 F-Measure指标评价算法,本文提出的DPCSNNS在5个UCI数据集上优于其他算法;对于乳腺癌数据集Wpbc,本文算法的F-Measure指标较K-means算法提高了33.3%;对于天平数据集 Balance,本文算法的F-Measure指标较DBSCAN算法提高22.72%。
实验结果表明,在UCI数据集上,本文提出新的基于共享近邻相似度的局部密度计算方式和聚类中心选择方式在聚类中心选择的正确性以及聚类结果的准确性较原始DPC算法有了一定程度的提高并且优于其他对比聚类算法。
3.4 模拟数据集实验结果与分析
本文使用4个模拟数据集来进一步验证DPCSNNS的有效性,数据集的基本特征如表3所示。
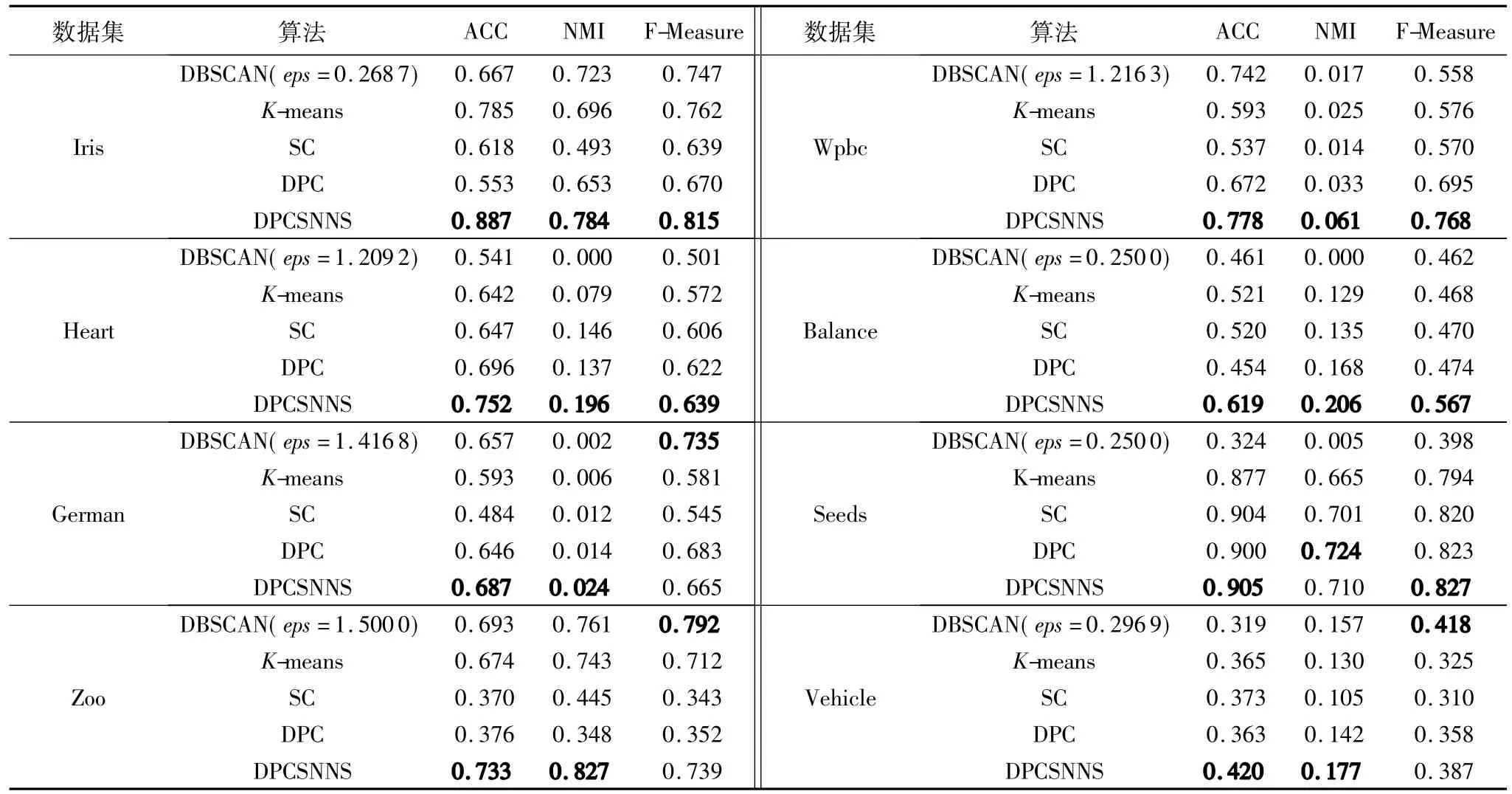
表2 不同聚类算法在UCI数据集上的实验结果Tab.2 Experimental results of different clustering algorithms on UCI datasets
针对模拟数据集,本文提出的DPCSNNS与对比算法的实验结果如表4所示。
从表4中可以看出,用ACC、NMI、F-Measure三个指标评价聚类结果,本文提出的算法较其他算法都存在优势。对Aggregation数据集,本文算法的ACC指标较K-means算法提高了29.4%;对R15数据集,本文算法的F-Measure指标较SC算法提高95.4%;对于Size5数据集,本文算法的ACC指标较DPC算法提高47.8%,NMI指标较SC算法提高59.8%;对于Forty数据集,本文算法在三个指标上都达到了100%的聚类效果。
实验结果表明,在模拟数据集上,本文提出的算法在评价结果中相较其他算法有明显的优势。对于DPC算法聚类效果不够理想的模拟数据集,通过本文提出的算法可以改进其聚类效果;对于DPC算法聚类效果已经比较理想的模拟数据集,本文的聚类算法也可以保持其较好的聚类效果。

表4 不同聚类算法在模拟数据集上的实验结果Tab.4 Experimental results of different clustering algorithms on artificial datasets
本文对模拟数据集的聚类结果通过不同形状聚类分布图进行展示。图2~5分别为数据集 Aggregation、R15、Size5、Forty的原始分布及 DPCSNNS、DPC算法、SC算法、K-means算法和DBSCAN算法的聚类结果图。由图2~5可以看出:本文算法得到的聚类结果与标准分类最接近,更能准确地反映样本的分布特征;而对于数据集Aggregation和Size5,DPC算法由于错误计算样本的局部密度,使得密度较高的簇选出多个聚类中心,从而使得聚类结果较差。

图2 数据集Aggregation原始分布及不同算法聚类结果Fig.2 Original distribution of dataset Aggregation and clustering results of different algorithms

图3 数据集R15原始分布及不同算法聚类结果Fig.3 Original distribution of dataset R15 and clustering results of different algorithms

图4 数据集Size5原始分布及不同算法聚类结果Fig.4 Original distribution of dataset Size5 and clustering results of different algorithms

图5 数据集Forty原始分布及不同算法聚类结果Fig.5 Original distribution of dataset Forty and clustering results of different algorithms
4 结语
针对DPC算法对参数dc敏感和不能自适应地选择聚类中心的不足,本文提出了一种基于共享近邻相似度的密度峰聚类算法,将共享近邻相似度和欧氏距离进行统一计算样本的局部密度,并提出一种新的聚类中心选择策略。UCI数据集和模拟数据集的实验结果表明,对比经典的聚类算法和原始DPC算法,本文提出的算法具有良好的聚类效果。但是,本文的近邻个数k是特定值,不能根据数据集的特性自动生成,因此近邻个数k是进一步研究的重点。
