基于决策树推荐克隆重构的方法
2018-08-27折蓉蓉张丽萍
折蓉蓉,张丽萍,侯 敏,闫 盛
(内蒙古师范大学 计算机与信息工程学院,呼和浩特 010022)(*通信作者电子邮箱cieczlp@imnu.edu.cn)
0 引言
近年来软件开发环境、操作系统及软件相关领域的不断发展,导致软件复用的规模越来越大,软件开发的成果被越来越多的人们直接复用。为了提高软件的开发效率,开发人员会复用大量的代码,被复用的代码称为克隆代码[1],据统计一个软件系统中的克隆代码达到9%~17%,有的甚至达到50%以上[2]。
克隆代码的大量使用导致了软件复杂性的增加,仅仅检测出克隆代码并不能降低软件维护成本。现有研究表明,重构与软件的质量(如可维护性和稳定性)有着密切的联系,经过重构的克隆代码往往比未经过重构的克隆代码具有更高的质量,所以重构对于软件的进化具有积极的意义。
重构软件系统中克隆所有代码是不切实际的,也不是所有克隆代码都需要重构,虽然预测克隆重构代码的方法相继提出,然而国内外针对机器学习预测出需要重构的克隆代码的方法极少,因此本文将重构作为一个机器学习问题,预测需要重构的克隆代码,以降低软件的复杂性和维护成本。
1 相关工作
1.1 克隆代码定义及分类
当前,人们广泛采用的克隆代码的概念是将具有相似语法及语义特征的代码段称为克隆代码[3]。基于对代码质量造成重要影响的是克隆代码的大量使用,近年来代码分析领域中比较活跃的分支为克隆代码的相关研究。克隆代码的类型从不同的角度进行划分,当前进行分类的角度主要分为两种。一种角度是根据代码相似度,将其分成Type- 1、Type- 2、Type- 3及Type- 4四类[4](定义如表1);另一种角度是根据检测粒度,将其分成文件克隆、类克隆、函数克隆、块克隆以及语句克隆等五种类型[5]。

表1 克隆类型的定义
1.2 克隆检测
克隆检测是指查找源代码中的克隆代码,并以克隆对(Clone Pair)或克隆群(Clone Group)的形式反馈。其中,克隆对是指相互之间存在克隆关系的代码段;克隆群是一些克隆代码段的集合,其中任意两个代码段都是克隆对。目前,克隆检测领域的研究已较为成熟,许多检测方法及技术被提出,主要包括:基于文本的克隆检测方法[6]、基于Token的克隆检测方法[7]、基于抽象语法树(Abstract Syntax Tree, AST)的检测方法[8]、程序依赖图(Program Dependence Graph, PDG)[9]、基于低级语言[10]的检测方法、基于Metrics[11]的检测方法等。
本团队在克隆检测方面也进行了大量研究:史庆庆等[12]使用优化后缀数组的方法进行克隆代码检测,并实现了一款检测软件源代码中克隆群的工具——FCD(Function Clone Detector)。FCD能够把软件系统中的Type- 1和Type- 2函数克隆高效地检测出来;张久杰等[13]实现了基于Token编辑距离的检测方法,能有效检测Type- 3克隆代码,解决了克隆检测中Type- 3类型克隆检测的难题,解决了以往对克隆代码分析的研究对象大多局限于Type- 1和Type- 2类型的问题,并为后续研究克隆代码的演化、克隆代码性能分析提供更加全面、准确的数据来源。
1.3 克隆重构
重构的概念由Opdyke[14]提出,重构就是通过改变程序代码的内部结构而不改变程序代码的外部行为来提高代码的质量,尤其是代码的可扩展性与可维护性。多年来软件重构作为提高代码质量的有效途径,已成为软件工程领域的热点问题。出现了许多针对不同类型的克隆代码的重构方法和技术,主要包括:Bakota[15]采用进化分析方法提取可重构的克隆代码;Rahman等[16]用度量提取可重构的克隆代码。Fowler[17]提出两种重构方法:提炼函数(Extract Method)和函数上移(Pull Up Method),这两种方法是重构克隆代码常用的技术,通常重构克隆代码需要结合使用这两种方法,首先执行“提炼函数”,然后执行“函数上移”。克隆代码重构可以提高代码的可维护性。
以Apache Ant中的一小段代码为例来理解克隆重构。Apache Ant的r436724中的克隆代码重构细节如图1所示,开发人员在维护日志提交内容中有如下表述:“重构DirectoryScanner来减少重复的代码,测试全部通过”。源代码的更改确认了重构DirectoryScanner中的克隆兄弟姐妹:分散在两个方法中的克隆兄弟姐妹被提取到一个名为processIncluded的新方法中,并且这两个方法调用新的方法来保存程序的外部行为。这就是重构克隆代码的一个实例。

图1 克隆重构实例
1.4 决策树
决策树又称判定树,是一种运用于分类的树形结构,构造决策树采用的是一种自上而下的递归方法。将一组带有类别标记的训练数据作为决策树的输入,一棵二叉树或者多叉树作为输出,以下两步主要是决策树的分类过程。
第1步 构建决策树模型,此过程就是进行机器学习的过程。从数据中获取知识,使用训练集建立模型同时优化。
第2步 进行分类,使用生成的决策树对输入数据进行分类。对输入的记录,从根节点依次测试记录的属性值,直到到达某个叶节点,从而找到该记录所在的类。
尤为关键的是构造一棵决策树,构造决策树的过程分为三步:1)特征选择;2)生成决策树;3)剪枝。
具体原理如下:
InfoGain(D,A)=H(D)-H(D|A)
(1)
(2)

(3)
其中:D代表整个训练样本;训练样本有k类;A代表特征,A将训练样本分为n类;Pi为数据集中第i个类别占样本总数的比例,Pji为j个剪枝数目中第i个类别所占比例。
决策树相对于其他分类器而言有如下优点。
1)速度快:不仅计算量小,而且分类规则转化较容易。
2)准确性高:挖掘出的内容不仅可以清晰地反映出哪些字段比较重要,而且分类规则精准性较高、便于理解。
2 基于决策树推荐克隆重构的方法
本文提出的基于分类器推荐克隆代码重构的方法共分为5个步骤,如图2所示。

图2 整体工作流程
2.1 克隆检测
如果不知道哪些代码片段是克隆代码、克隆代码所在的位置,也无法识别重构代码,解决克隆代码引起的问题,克隆代码检测是研究克隆重构的基础,因此本研究使用目前比较成熟的克隆检测工具——NiCad进行克隆检测。NiCad检测工具是由加拿大皇后大学Roy等[6]开发的克隆检测工具,当前最新版本为NiCad 4.0,适用于C、Java、Python等主流开发语言,能够检测Type- 1、Type- 2、Type- 3的克隆代码。由于它能有效检测Type- 3克隆代码,解决了以往对克隆代码分析的研究对象大多局限于Type- 1和Type- 2类型的难题,并为后续研究克隆代码的重构、克隆代码性能分析提供更加全面、准确的数据来源。
本研究使用subversion从版本管理器中获取某次提交之后的结果作为一个版本的源码,然后使用NiCad进行克隆检测,该工具可以检测Java语言的Type- 1、Type- 2与Type- 3函数克隆,并具有很高的精度值和召回率。检测结果以克隆对、克隆群和克隆函数的形式反馈出来,本研究只用克隆函数、克隆群形式的检测结果,检测结果存储到XML文件中。下面以Tomcat软件为例,介绍克隆检测结果。图3呈现了以克隆函数形式反馈出来的部分内容检测结果,它显示的是一个代码片段的文件,提供每一个代码片段的文件路径、起始行号、结束行号、片段源码等信息。图4呈现了以克隆群形式反馈出来的部分检测结果,它是克隆群文件,克隆群包含的克隆片段、检测出来的克隆群信息都包含在里面。
2.2 识别重构的克隆代码
近年来随着克隆代码检测技术日益成熟,克隆代码的重构也逐渐成为了热门,在对软件系统中克隆代码重构之前,识别出需要重构的集合是非常重要的。本文识别克隆代码重构实例具体过程分为如下3个步骤。

图3 部分检测结果(克隆函数)

图4 部分检测结果(克隆群)
步骤1 通过相邻版本间定义重构实例。克隆重构简单来说就是代码的更改,即定义克隆类C为由两个或更多个克隆片段组成的集合。一个克隆类C至少有两个克隆片段被合并,并且保留原始代码段的外部行为,超过两个克隆片段的克隆类C,则C被认为是克隆重构,如果任何两个克隆片段被重构,则为重构实例。
步骤2 生成重构候选集。本实验选择了5个著名的开源系统,Tomcat、ArgoUML、PostgreSQL、Lucene、Apache Ant,收集了这些系统的所有公开版本,要在所选目标系统中识别克隆重构实例,用Demeyer等[18]开发的度量工具Moose Metrics从源代码中提取类、方法、属性、计算必要的度量来生产重构候选集。
步骤3 优化重构候选集。生成重构候选集之后,依据以下3个条件对重构候选集进一步筛选和优化:
1)相邻版本间克隆类的两个兄妹消失;
2)对于克隆代码片段内的方法,源代码行数减少,并且至少一种方法被添加进此方法中;
3)一个原始克隆代码中新的源类被创建并作为父类。
选择这3个条件是因为它们包含了所有与克隆重构有关的重构模式。通过使用这种基于度量值的方法,手动检查克隆克隆重构候选者,据Demeyer等[18]使用发现,这种方法可以检测到适用于克隆重构的所有Fowler重构模式,包括“Extract Method”“Extract Superclass”“Pull-Up Method”“Replace Method with Method Object”“Template Method”等方法。
若满足其中任意一个条件则一个克隆类C被当作候选,重构实例如表2所示。
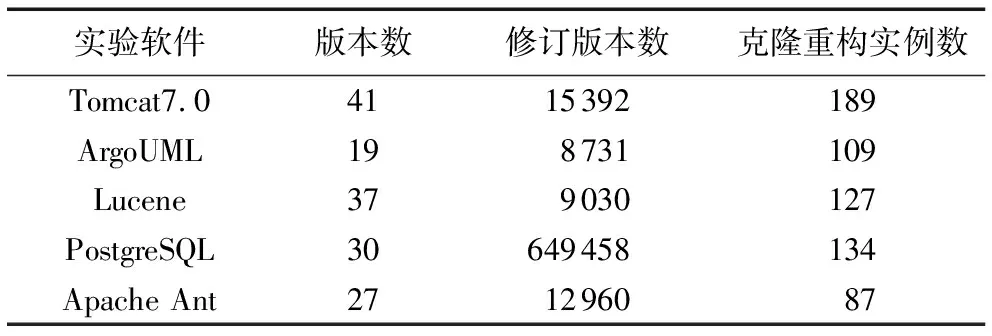
表2 识别克隆重构实例
为了构成完整的分类器训练数据集合,还需要收集非克隆重构实例。非克隆重构实例的收集则比较简单,只需观察从克隆开始版本到本研究中的最后一个版本,选择没有任何重构的克隆代码(包括重命名标识符),则为非克隆重构实例。
2.3 特征提取
特征提取是机器学习和模式识别领域常用的数据预处理方式,是训练机器学习模型的必要步骤,Wang[19]提出了使用克隆代码的危害性可能与克隆代码段的特征以及克隆内容的特征有关,并在两个大型工业软件上进行了评估。Steidl等[20]用克隆代码段、克隆关系的特征来自动识别克隆代码的bugfixes,并进行了验证。本团队王欢等[21]针对克隆代码有害性特征数量多且不容易提取、质量粗糙的情况,提出了一种有害性特征选取的组合模型。基于以上研究得出Type- 3的克隆、克隆代码的圈复杂度、克隆代码段的行数、分支语句的比例等特征与克隆代码的有害性和重构相关,因此本文从克隆关系、克隆代码段及克隆内容这3个维度中提取特征,详细特征信息如表3所示。
特征的提取是建立在克隆代码检测和重构标注的基础上,通过分析克隆检测结果可以为本文研究基础性的克隆代码数据,包括克隆代码的数量、位置等数据。克隆群是不是Type- 3的克隆、克隆代码段的Token大小这两个特征直接从NiCad克隆检测结果中提取,对于其他特征本文使用代码工具SourceMonitor提取。SourceMonitor是一款可对多种语言(C++、C、C#、VB.net、Java、Visual、Basic和HTML)编写的代码进行度量的工具,并且针对不同的语言,输出不同的代码度量值。将克隆代码作为输入,SourceMonitor便会输出相应克隆代码的静态特征值。图5是SourceMonitor对部分克隆代码进行度量的结果。代码行数是从SourceMonitor工具的
2.4 训练决策树分类器
决策树方法在分类、预测等领域有着广泛的应用,C4.5是比较成熟的决策树算法,C4.5算法是决策树分类问题中必不可少的挖掘工具。之所以选择C4.5是因为它产生的预测准确性不低于其他的分类方法。哈尔滨工业大学袁悦[22]使用机器多种学习的方法来预测克隆代码的一致性维护需求模型,经实验发现决策树的预测模型最佳,Wang等[23]用决策树预测克隆代码的质量且取得良好的效果。受此启发本研究选用决策树来预测需要重构的克隆代码。

表3 特征选择
构造一棵决策树的步骤如下。
1)数据预处理:将属性变量处理形成决策树的训练集,这里只需处理连续型的属性变量,若没有连续型的属性变量则忽略。
2)计算属性的信息增益率。
3)生成决策树:每一个根节点属性的取值对应一个子集,对样本子集递归执行步骤2),直到分类属性上取值都相同时生成决策树。
4)对新数据集进行分类:根据构造的决策树,提取分类规则且进行分类。
算法描述如下。
输入:训练样本samples,候选属性的集合attributelist。
输出:一棵决策树。
创建节点N
ifsamples都在同一个类Cthen
returnN作为叶节点,以类C标记
ifattribute_list为空then
returnN作为叶节点,标记为samples中最普通的类
选择attribute_list中具有最高信息增益的属性best_attribute
标记节点N为best_attribute
for eachbest_attribute中的未知值ai
由节点N长出一个条件为best_attribute=ai的分枝
设si是samples中best_attribute=ai的样本的集合
ifsi为空then
加入一个树叶,标记为samples中最普通的类
else 加上一个由Generate_decision_tree返回的节点

图5 部分克隆代码度量结果
训练分类器,需要一个包含克隆重构实例和非克隆重构实例的样本数据库,然而未经重构的克隆实例通常比重构实例多出几倍,训练所有克隆实例将会在构造分类器时引入对未克隆重构的偏奇。为了解决这个问题,使用随机欠采样来减小未重构克隆的大小。随机欠采样简单来说就是从原始数据集中删除数据,从而提供相同比例的数据。具体来说,本文随机选择一组Dmaj中的多数类实例,并从D中删除这些样本,计算过程如下:
|D|=|Dmin|+|Dmaj|-|E|
(4)
其中:D是数据集;Dmin表示少数类数据的集合,在本实验中就是克隆重构实例;Dmaj表示多数类数据的集合,在本实验中就是非克隆重构实例;E表示D上采样过程中产生的任何集合。
2.5 评估分类结果
在对未知数据样本进行预测时,部分被正确分类,部分被错误分类,因此,为了评价克隆代码重构预测模型,本研究选用常用的召回率、精度值、F值来评价分类器的性能,对应的混合矩阵如表4所示。表4中:正确的正例(True Positive, TP)用TP来表示;错误的反例(False Negative, FN)用FN来表示;错误的正例(False Positive, FP)用FP来表示;正确的反例(True Negative, TN)用TN来表示。

表4 混合矩阵
精度值(Precision)的定义如式(5)所示、召回率(Recall)的定义如式(6)所示、F值的定义如式(7)所示:
Precision=TP/(TP+FP)
(5)
Recall=TP/(TP+FN)
(6)
F=(2*Precision*Recall)/(Precision+Recall)
(7)
其中:精度值是分类问题中常用的指标,它反映分类器对数据集的整体分类性能;召回率度量分类器正确预测克隆重构的比例。
3 实验结果与分析
3.1 实验目标软件
本实验选取5款开源软件分别是:Tomcat 7.0、Apache Ant、ArgoUML、Lucene、PostgreSQL,基本信息如表5所示。本研究之所以选择这些系统不仅仅是这些系统比较庞大,而且这几个系统已经通过赵玉武等[24]在克隆代码Bugs的研究中进行了实验。

表5 实验软件基本信息
3.2 实验结果
由于位于决策树根部附近的特征不能代表其预测能力,因此选择不同的特征子集,并使用每个子集来训练一个新的分类器。本实验选择三个子集的特征。这三个子集分别是克隆关系、克隆内容以及克隆代码段。
实验结果如表6所示(使用子集对克隆重构组、非重构组进行分类训练的性能),从表6中可以得出如下结论。
1)在5个目标系统中,没有一个特征子集的性能始终优于其他子集。
2)和所有特征训练的分类器相比,克隆代码片段的特征可以产生最接近的结果。如重构组ArgoUML目标系统中所有特征训练分类器的精度值为0.813、召回率为0.785,与此最相近的是受过克隆上下文训练分类器的精度值为0.798、召回率为0.779。其他目标系统也是如此。
3)与克隆上下文相关的特征产生的结果略低于受过所有特征训练的分类器。如重构组ArgoUML目标系统中所有特征训练分类器的精度值为0.813、召回率为0.785。受过克隆上下文训练分类器的精度值为0.751、召回率为0.732,略低于所有特征训练的分类器。其他目标系统也是如此。
4)通过学习克隆关系的特征,例如特征3(克隆类是否是一个Type- 3克隆),或者特征4(克隆片段是否在同一个文件中,或者是兄妹姐妹),分类器的性能获得一小部分的改进。如重构组ArgoUML目标系统中所有特征训练分类器的精度值为0.813、召回率为0.785,受过克隆关系训练分类器的精度值为0.635、召回率为0.801,略低于所有特征训练的分类器。其他目标系统也是如此。
基于以上结论,得出克隆代码段的特性独立于克隆关系及克隆内容,产生的结果可用于推荐重构的克隆代码。

表6 使用子集对不同组进行分类训练的性能对比
本实验选取K折交叉验证来评估验证,此方法的基本思想是将输入数据集划分为训练集和测试集,因为测试集和训练集中测试集对分类器是不可见的,所以进行交叉验证的对象是训练集输出的结果。
第1步 将数据集D划分为k个大小相似的互斥子集,即D=D1∩D2∩D3∩…∩Dk,每个子集之间没有交集。
第2步 然后每次用k-1个子集的并集作为训练集,余下的那个作为测试集,这样得到k组训练/测试集。
第3步 可以进行k次训练和测试,最终返回的是这k个结果的均值。
第4步 可以随机使用不同的划分次数。
本实验选取K=10,即K折交叉验证来评估分类器预测模型,通过利用大量数据集以及使用不同技术进行大量实验发现10折获得的误差最小,因此本实验将数据集分为10份。验证结果如表7所示,分别显示了重构组和非重构组的精度值、召回度、F度量。
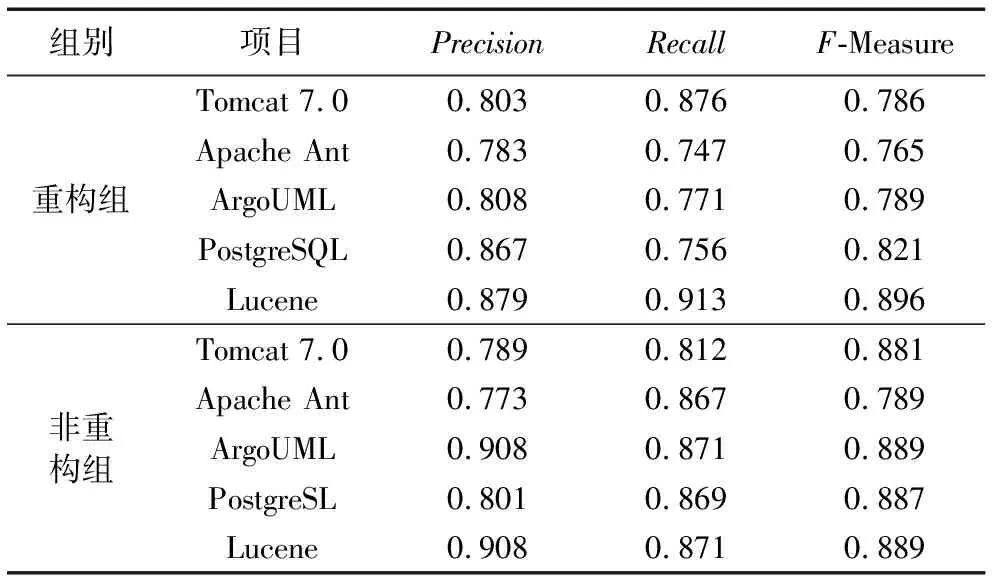
表7 对不同组的测试结果对比
从表7的重构组对比可以得出,重构组10倍交叉验证的精度值从78.3%提高到了87.9%,提高了9.6个百分点;召回率从74.7%提高到了91.3%,提高了16.6个百分点;F值从76.5%提高到了89.6%,提高了13.1个百分点。从表7的非重构组对比中可以得出,非重构组10倍交叉验证的精度值从77.3%提高到了90.3%,提高了13个百分点;召回率从81.2%提高到了87.1%,提高了5.9个百分点;F值从78.9%提高到了88.9%,提高了10个百分点:因此得出本文所构造的分类器比随机选择执行来的效果更佳。
3.3 同类实验对比分析
当前国内外使用机器学习的方法预测出需要重构的克隆代码方法较少,本团队的刘冬瑞等[25]也曾使用机器学习方法预测需重构的克隆代码,然而其度量值的选取是根据ISO软件质量标准选取的,不能很好地体现需重构克隆代码的特征,而本研究度量值的选取是从重构实例中提取的,相对而言,可信度更好,可行性更强。使用机器学习方法预测出需要重构的克隆代码具有代表性的是文献[26]所提出的方法,鉴于文献[26]直接从公司收集的克隆代码,而本研究使用NiCad来检测克隆代码,同时本研究与文献[26]提取的特征也不完全一致,因此仅对推荐克隆重构做对比实验。其中本文研究与文献[26]所使用的项目均为Java项目,实验平台同为操作系统:Ubuntu14.04 64位、8 GB内存、2核CPU。版本信息如表8所示。
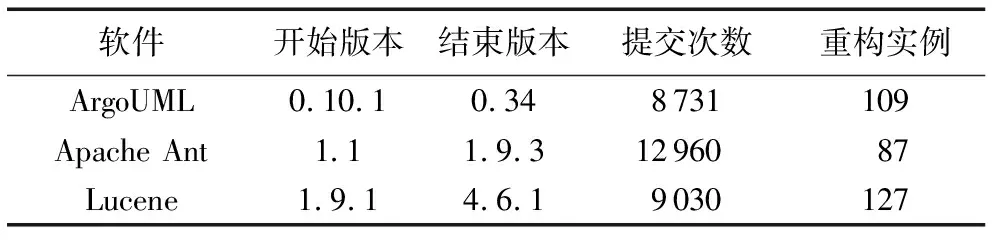
表8 推荐克隆重构对比实验软件信息
通过对比实验,结果如表9所示。

表9 推荐克隆重构同类实验结果对比
从推荐克隆重构结果中分析软件ArgoUML的精度值、召回率和F值,与文献[26]的方法相比,本文方法的精度值提高了10个百分点、召回率提高了10个百分点、F值提高了9.8个百分点。从推荐克隆重构结果中分析软件Apache Ant的精度值、召回率和F值,与文献[26]的方法相比,本文方法的精度值提高了10个百分点、召回率提高了6个百分点、F值提高了3.3个百分点。从推荐克隆重构结果中分析软件Lucene的精度值、召回率和F值,与文献[26]的方法相比,本文方法的精度值提高了4.5个百分点、召回率提高了9.6个百分点、F值提高了2.4个百分点。综上本文推荐克隆代码重构方法的召回率、精度值、F值均高于文献[26]方法。
4 结语
针对克隆代码的大量使用会导致长期软件维护问题甚至引入错误的问题,本文提出了一种基于决策树的分类器来推荐克隆进行重构的方法,通过Nicad检测出源代码中的克隆代码,使用基于度量值的方法将重构实例标注出来,同时使用SourceMonitor提取出特征并构建样本数据集。最后对600多个克隆实例使用10折交叉来验证,发现本文提出的基于决策树的分类器来推荐克隆重构方法的精确度、召回率及F值都能达到80%以上,验证了本文方法的有效性。本研究可以为克隆重构提供更好的资源分配,从而改进克隆管理。
本文的研究内容与实验仍然存在一些不足之处,例如目前只能推荐用Java开发项目的克隆重构、推荐克隆重构精度有待提高,在后续研究中将继续改进,尝试使用深度学习、半监督学习来推荐克隆重构。
