基于Adaboost算法的水质组合预测方法研究
2018-08-24,,,,
,,,,
(1.北京工商大学 计算机与信息工程学院,北京 100048; 2.北京市水务局办公室,北京 100038)
0 引言
随着城市化进程快速推进,环保基础设施建设未得到同步发展,城市雨污水在排入时携带较多污染物,导致了城市水环境形势面临严峻威胁。为了防止水污染扩散,在河湖关键位置设立了监测站点,自动监测水质信息状况,为水污染防治提供信息基础。在此基础上,根据水质监测信息预测水质变化趋势,对水环境的有效防范治理具有重要意义。
在水质预测研究中,数理统计方法和人工神经网络技术得到了广泛应用。在基于数理统计的水质预测方面,颜剑波等人建立了多元回归模型[1],在自变量和因变量之间规律分析的基础上,对三门峡断面水质的COD浓度进行了预测。荣洁等人应用了指数平滑法-马尔科夫预测模型[2],对数据进行平滑处理,并结合马尔科夫法对合肥湖滨与巢湖裕溪口两大断面的CODMn、TP、TN浓度进行了预测。刘东君等人将最优加权组合预测法应用到永定河的DO 值的预测[3]。然而传统的数理统计方法对于数据要求较高,且影响水质的各因素之间存在着复杂的非线性关系,使得数理统计方法应用受到限制[4]。人工神经网络技术目前已成为水质预测的主要研究方向之一。李景文等人利用基于TSC-RBF的预测方法,对漓江阳朔段流域水质中的CODMn和NH3-N进行了预测[5],张森等人提出了将偏最小二乘法和支持向量机相耦合的水质预测方法,以长江朱沱的高锰酸钾指数为例进行分析[6]。宦娟等人提出了基于K-means聚类和ELM神经网络的水质预测模型[7],应用于养殖水质溶解氧预测。
上述文献中虽然对水质预测方面作了深入的研究,但并未针对原始数据中的噪声信号进行有效处理,同时传统的数理统计方法受到多方面的限制,神经网络方法也只采用了单一预测模型,不能避免单一方法的局限性。因此本文将优化后的RBF、Elman神经网络以及支持向量机相结合,构建基于Adaboost的水质组合预测模型,通过对北海水域中溶解氧浓度进行预测分析,结果表明该模型具有较好的预测精度和泛化能力。
1 基本原理
1.1 小波去噪
小波分析利用小波函数做为基函数,将原始信号按频率分解为多层,各层之间信号不重叠,且所分解的信号包含了原信号的所有频率,其中对于小波函数的选择最为重要[8]。本文选取Symlets和Daubechies小波系作为小波函数进行去噪效果对比。
小波去噪的基本步骤如下:
1)结合实际数据,将信号分解为不同频率的信号,并计算每层的小波分解系数。
2)设定各层小波的阈值,阈值处理方式包括软阈值和硬阈值两种。
3)将各层信号与阈值比较并处理后进行小波重构,得到去噪后的信号。
采用的小波去噪效果评价指标为如下两种:
均方根误差RMSE,表示去噪后信号与原始信号的均方误差,值越小表示去噪效果越好:
(1)

信噪比SNR,表示原始信号和噪声值比值,值越大表示去噪效果越好:
(2)
其中:powers表示原始信号功率,powern表示噪声功率信号。
1.2 RBF神经网络
RBF神经网络是具有单隐层的三层前向网络,其基本思想是,用RBF作为隐单元的“基”构成隐藏层空间,隐藏层对输入矢量进行变换,将低维的模式输入数据直接变换到高维空间内,使得在低维空间内的线性不可分问题在高维空间内线性可分[9-10]。RBF神经网络的结构示意如图1所示。
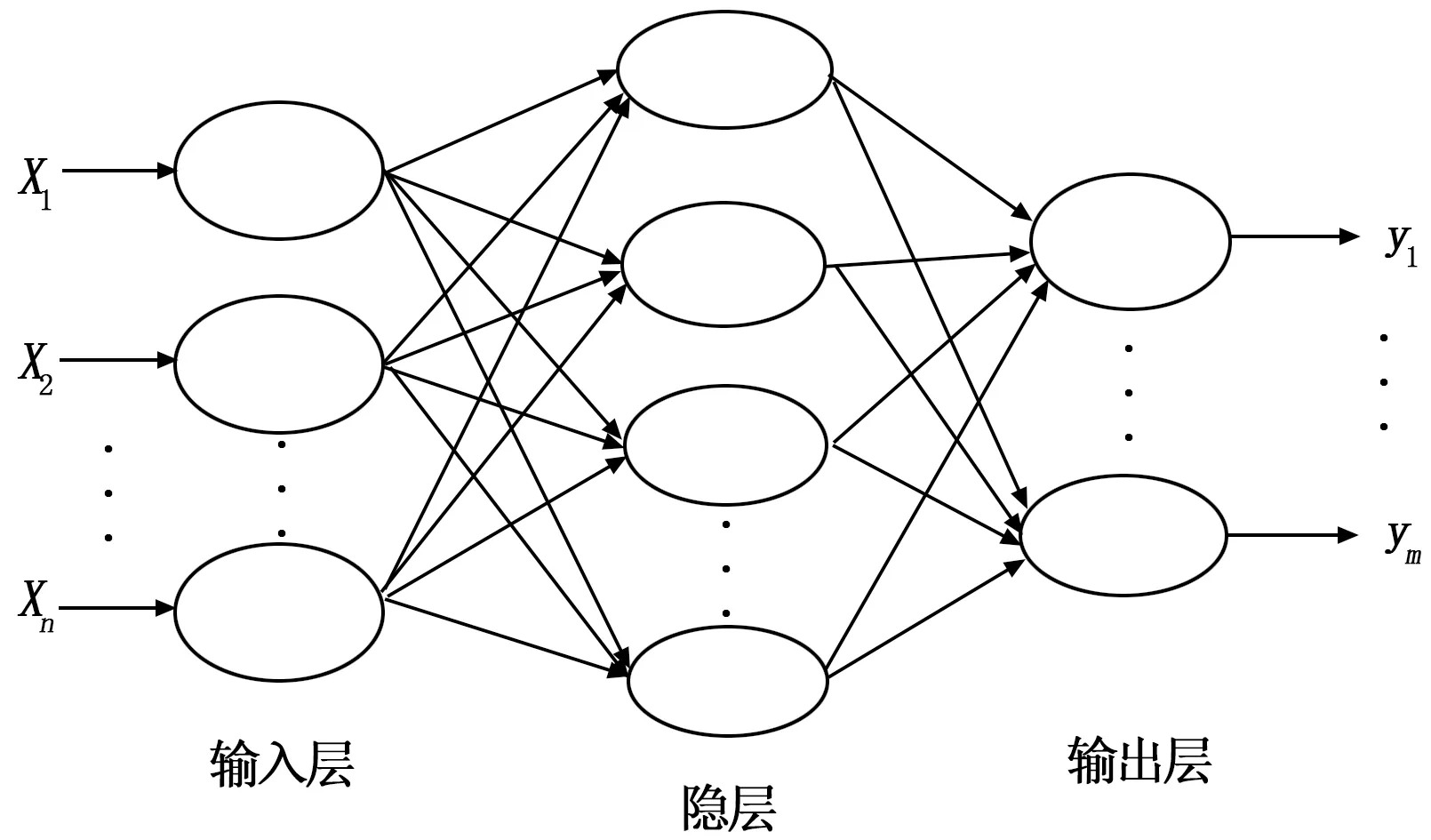
图1 RBF神经网络结构图
其中:Xi为第i个输入向量,yi为第i个输出向量,N代表隐含层神经元个数。隐含层中的每一个神经元都使用了非线性径向基函数φ(·),即输入向量通过输入层到达隐含层,经过隐含层神经元的径向基函数进行非线性变换,再将变换结果加权求和得到输出结果[11]。
1.3 支持向量机
支持向量机SVM可用于模式分类和非线性回归,其主要思想是建立一个分类超平面作为决策曲面,使得正例和反例之间的隔离边缘被最大化。将样本数据从样本空间映射到高维特征空间进行线性回归,从而求解出一个包含了多种因素影响的水质最优回归函数。在最优回归函数中采用适当的核函数代替高维空间中的向量内积,就可以实现非线性变换后的线性拟合,而计算复杂度却没有增加,从而得到最优回归函数[12]:
(3)
其中:αi,αi*为拉格朗日乘子;b为回归阈值;SV为支持向量;k(xi,x)为核函数。
1.4 Elman神经网络
Elman 网络是一种比前向神经网络具有更强计算能力的反馈型神经网络,能够更好的反映系统的动态性[13]。Elman网络是在BP神经网络基础上多了一个承接层,具有适应时变特性的Elman反馈动态递归网络预测性能[14]。

图2 Elman神经网络结构图
其中:w1为承接层到隐含层的连接权值,w2为输入层到隐含层的连接权值,w3为隐含层到输出层的连接权值。
1.5 Adaboost算法
提升(boosting)方法是一种常用的统计学习方法,通过改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,以提高分类的性能[15-16]。
Adaboost方法是其中最典型的一种算法,其主要思想是:首先给出弱学习算法和K组样本数据,每组数据的初始权重为1/K;然后利用弱学习算法进行训练,将训练结果与实际值进行比较,将预测失败的训练样本赋予较大权值,使得在下一次迭代运算时这些训练样本得到更多的关注,训练失败判定由错误率ε决定,当ε大于给定阈值时判定为预测失败样本。从而得到了一系列采用不同权重的训练样本的弱预测器序f1,f2,…,fn,并且每个弱预测器也具有相应的权值,预测效果越好,弱预测器权值越大;最后在迭代完成后将所有弱预测器加权求和得到强预测器,再用强预测器进行预测[17]。
2 组合预测方法
2.1 参数优化
RBF网络可以自适应的确定网络结构,但采用固定的目标误差goal以及扩展系数spread,无法针对样本进行优化,导致训练精度仍有待提升,在此使用梯度下降法得出一系列相对应的目标误差及扩展系数,通过试凑法获取最优的预测结果。
关于SVM参数的优化选取,并没有公认统一的最优方法,现在目前常用的方法就是让惩罚系数c和核函数半径g在一定的范围内取值,对于取定的c和g把训练集作为原始数据集,利用交叉验证方法得到在此组c和g下训练集验证分类准确率,最终取使得训练集验证分类准确率最高的那组c和g做为最佳的参数[17]。
Elman网络采取权值更新方法—梯度下降法[18],其缺陷是收敛速度慢、容易陷入局部最小值,在此借助遗传算法GA训练初始权值和阈值对Elman网络进行优化。改变Elman网络依赖梯度下降法来调整网络权值的思想,利用GA全局性搜索的特点,寻找最为合适的网络连接权值、阈值和网络结构,提高预测精度和泛化能力。
2.2 组合预测模型建立步骤
以北京北海公园水域作为研究对象,北海作为地表湖泊且为城市景观水,其水质指标的变化同时受到自然和人为因素的影响,对于水环境治理具有指导意义。本文预测模型主要针对北海水域1~4月份溶解氧浓度进行分析研究。同时分别采用RBF网络、支持向量机以及Elman网络进行建模预测,将预测结果进行对比分析。
第一步,构造弱预测器。将3种单一模型分别作为3个弱预测器。在使用神经网络以及支持向量机进行预测时,本质是找出输入输出之间的非线性函数关系,要得到良好的预测效果,输入输出数据的选择很重要。
由于溶解氧浓度的变化是一个渐变的过程,所以根据历史数据变化趋势来预测后面的输出可以取得较好结果,如下所示:
d(t)=F(d(t-1),d(t-2),…,d(t-n))
(4)
式中,d(t)为t时刻溶解氧的监测数据,n为输入层的节点数,F为由单一预测模型确定的输入-输出映射关系。经试验确定采用最近3天的溶解氧历史数据来预测输出效果最好,即n=3。
在模型输入输出选择方面,分别以溶解氧数据的前3天历史数据为模型输入向量,未来一天的预测值为输出向量,构建3输入1输出的弱预测器:
d(t)=F(d(t-1),d(t-2),d(t-3))
(5)
第二步,构建Adaboost强预测器。用Adaboost算法将得到的多个弱预测器序列组成新的强预测器。基于Adaboost组合预测方法实现流程如图2所示。

图3 组合预测方法实现流程图
Adaboost组合预测模型具体建模步骤如下:
1)样本数据权重初始化。首次迭代时数据的初始权重为D1(k)=1/n(k=1,2,…,n代表样本序号,下标1代表迭代次数),为每个样本数据分配相等的权重。
2)弱预测器预测。每次迭代前将此预测器权值初始化为0,再利用相同的训练集训练3个弱预测器,若某一样本数据预测误差大于一定值,则将其累计权值相加最后得到这一弱预测器的权值之和:
Errorj=Errorj+Di
(6)
其中:Errorj代表第j个弱预测器权值累加和,Di代表超过误差阈值的数据的权值。
3)更新样本数据权重。若当前样本误差未超过阈值则权值Di不变,顺延到下一次迭代当中,若超过误差阈值,则将权值变大:
Di+1=1.1·Di
(7)
4)预测序列权值计算。根据弱预测器权值累加和Errorj算序列权值:
(8)
5)构建强预测函数。经过n轮迭代后得到强预测结果:
F=at·[f1,f1,…,fn]
(9)
2.3 模型评价指标
选取平均相对误差绝对值MRE、最大相对误差绝对值MaxRE以及均方误差MSE作为对预测结果的评价标准:
(10)
(11)
(12)

3 仿真实验
3.1 数据预处理
选取2015年1月至4月北海水质监测数据作为训练样本,2016年1月至4月监测数据作为测试数据。选用的水质指标溶解氧浓度,其中采样频率为每日一次,两年分别有120组数据。选用Symlets和Daubechies作为小波函数,阈值处理采用硬阈值,阈值选择标准为启发式阈值,分解层数为5,分别对原始数据进行去噪处理,结果如表1所示。
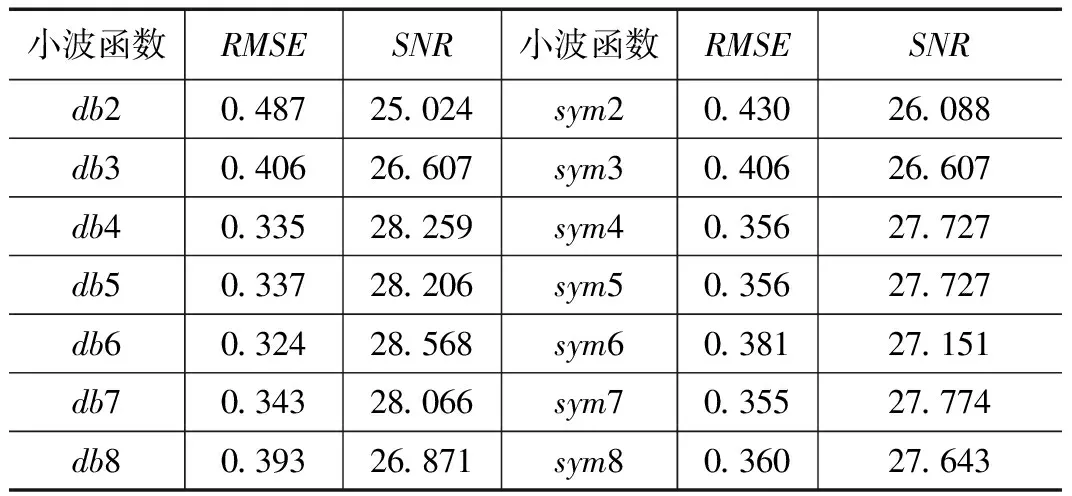
表1 去噪评价指标结果
由表1可以看出不同小波函数具有不同的去噪效果,其中db6均方误差最低以及信噪比最高,因此采用db6作为小波基对数据进行去噪。
3.2 实验及结果分析
将基于Adaboost组合预测模型应用于溶解氧浓度预测步骤如下:
第一步,将去噪后的数据归一化处理。数据经过转化映射在[0,1]范围内,采用式(13)进行归一化处理:
y=(ymax-ymin)·(x-xmin)/(xmax-xmin)+ymin
(13)
式中,y为经过处理的数据,x为原始数据,xmin、xmax分别为最小值和最大值;ymax和ymin分别默认值为1和-1。
第二步,训练和预测。利用所选数据对组合预测模型进行训练和预测,预测精度对比结果见表2。
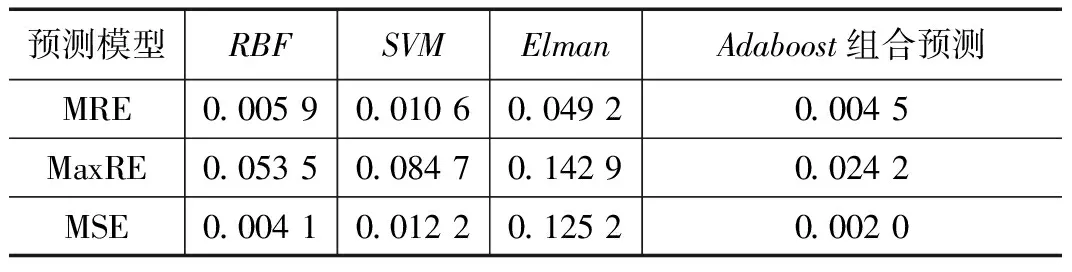
表2 各预测模型预测结果
由表2对2016年1~4月份溶解氧预测精度对比可知,Elman网络的平均相对误差约在5%,平均相对误差则更大,达到了14%以上;RBF网络和SVM相较于Elman网络各项指标的预测精度都有了不同程度的提升。而Adaboost组合预测模型的预测效果最好,其中均方误差仅有0.002,相较于前3种单一模型,组合模型表现出了明显的优势,预测精度最高,适合于非线性的水质指标预测。单一模型在面对多样环境时,总会有不足,而组合模型恰好的弥补了这一点。
图3给出了组合预测模型和3种单一模型对于2016年1~4月份溶解氧预测的误差曲线。

图4 误差曲线
由图4可以看出,Adaboost组合预测模型的误差曲线最低、预测结果最接近真实值,表明了使用Adaboost算法对多个不同的弱预测器进行集成,可以有效的提升水质指标的预测精度。
4 结论
1)在去噪过程中小波函数的选择对于去噪效果具有显著的影响,在其他条件相同下,db6小波函数的去躁效果在Symlets和Daubechies小波系表现最优,有效的去除了数据中的误差信号,为实现水质精准预测奠定了基础。
2)建立了基于Adaboost的组合水质预测模型,通过对北海水域溶解氧浓度历史情况进行分析,并与经过参数优化后的RBF网络、支持向量机和Elman网络预测结果进行对比,证明相对于传统的单一预测模型,通过Adaboost优化的组合预测模型预测结果更加接近真实情况,提高了预测精度和泛化能力。将此方法应用到河湖水质指标变化预测中,可为城市水环境污染防治提供参考依据,满足了人们生产、生活用水的需求。
