基于卷积降噪自编码器的藏文历史文献版面分析方法
2018-08-17张西群马龙龙段立娟刘泽宇
张西群,马龙龙,段立娟,刘泽宇,吴 健
0 引言
近年来,人们对传统历史文化的保护和传承越来越重视,研究人员对历史文献数字化的兴趣也越来越高涨。
藏族是一个拥有丰富传统文化的民族,是中华灿烂文明不可或缺的重要组成部分。藏文历史文献是藏族传统文化宝库中一颗璀璨的明珠,其作为承载藏族古老文明的载体,受到了历史学家、语言学家、佛学家、文献学家的广泛关注。一直以来,中央政府非常重视藏文历史文献及文物的保护及发掘,先后多次进行了藏族文物历史文献的收集和保护工作[1];但是,藏文历史文献的研究和发展现状仍然不容乐观。当前对藏文历史文献的保护主要停留在存放保护阶段。大部分的藏文历史文献被保存在博物馆、庙宇或研究院的库房中,只有部分根据需要以人工输入、扫描、拍照等电子化手段进行保存,以供研究。这种方式存在耗费大量人力物力、传输流通不便、不能对藏文历史文献内容充分挖掘和利用等问题。同时,历史文献的研究与保护也存在着矛盾。在研究藏文历史文献的过程中,无法避免对历史文献的触摸以及翻动,这一环节对有着几百年甚至上千年历史的文献来说,可能是致命的。而采用数字化的方法对藏文历史文献图像进行自动的版面分析和识别,将文献内容转化为数字化的文本存储,可以大大提高对藏文历史文献的利用效率;可以大批量远距离在线浏览和传输,实现资源的共享;能够在妥善保存原件的基础上,实现对藏文历史文献的充分研究和传承。因此,采用数字化技术对现有的藏文历史文献中的文本部分进行自动识别并转化为数字形式存储,对藏族历史文化的研究、保护和传承具有非常重要的意义。
版面分析是历史文献数字化过程中重要的基础步骤。在过去的几十年中,国内外的研究者针对印刷或手写的历史文献提出了许多不同的版面分析方法。版面分析方法多依赖于所处理文献的版面特点,通常针对不同的文献版面布局使用特定的版面分析方法。此外,现有的版面分析方法主要用来处理一些主流语言(如: 中文、英文、法语等)的历史文献,很少有针对少数民族语言历史文献特点的版面分析方法提出。由于藏文历史文献的固有特点,文本和边框、文本和图形之间通常会有粘连的情况发生;版面也较为复杂,文献图像颜色不一致,噪点多,文献中的边框、线段经常会出现弯曲、倾斜、断裂等情况。以上这些特点给实现高性能的藏文历史文献的版面分析带来了较大挑战。图1展示了一个藏文历史文献图像的样例。现有的文献版面分析方法大部分是对近现代比较规则的印刷书籍的版面进行分析,不适用于版面比较复杂的历史文献;已有的历史文献的版面分析方法,大多是针对某一种语言文字的历史文献特点提出的方法,并不完全适用于藏文历史文献。

图1 藏文历史文献图像
受文献[2]的启发,本文提出了一种基于卷积降噪自编码器的藏文历史文献版面分析方法,该方法克服了藏文历史文献的退化、颜色不一致、噪点多等特点对版面分析效果的影响。具体分为四步。第一步,首先使用超像素聚类算法将藏文历史文献的图像聚类成不同的超像素块;第二步,利用卷积降噪自编码器提取超像素块的特征;第三步,使用SVM分类器将藏文历史文献图像的超像素块进行分类;最后,将藏文历史文献的版面分析结果存储在XML文件中。实验结果表明,此方法能够有效地对藏文历史文献的版面进行分析,将不同的版面元素分离。
本文其他部分组织如下: 第一节介绍文档版面分析的相关工作;第二节引入本文提出的版面分析方法;第三节给出实验结果及分析;第四节简述结论。
1 相关工作
近年来,研究人员针对不同特点的文献提出了多种多样的方法对文献版面进行分析。Sébastien[3]将它们分为了三类。
第一种类型的方法通常用于典型的、版面布局较简单的文献,例如,曼哈顿布局类型的文献。Dai-Ton[4]提出了一种自适应的过分割和融合算法来对印刷出版物进行版面分割;利用图像背景中的白色矩形信息先将图像尽可能地过分割,然后将通过形态学方法检测出的直线和图画区域从图像中去除,通过连通区域分析得到候选文本;通过预定义的规则将字体大小相同、距离相近的候选文本组合成一个连通区域;然后使用段落分布模型将不同段落分割开;此方法在现代印刷报纸、杂志等出版物上获得了较好的分割效果。郭[5]提出了一种改进的连通区域分析方法,对报纸和杂志图像进行版面分析;该方法先对单个字域进行扩充以填补字内的空隙,然后再通过投影进行文本块连通,最后通过分析连通块的投影,对连通块进行标记;其实验结果表明此方法对报纸和杂志的版面分析是比较有效的。
第二种方法的不同之处在于它们尝试适应文献图像中的局部变化,以便能够使用相同的方法来分割更多布局类型的文献图像。Chen等[2]在他们以前研究[6]的基础上,提出了一种基于超像素分类的无监督学习方法来分析历史文献版面,对待分析文本图像先进行超像素聚类,然后对超像素进行分类,并将分类结果融合成连通区域;此方法与其原来的方法相比,不仅降低了计算复杂度,也提升了分析效果。Yadav[7]提出了一种基于角点检测的文本提取方法,其受到在视频中利用角点检测进行文本区域检测的启发和文本图像中文本区域的角点密度比其他区域的角点密度大的先验知识;先将文本图像均分成较小的块,然后利用角点密度对图像块进行分类;此方法在一些手写文本图像和历史印刷图像数据集上都得到了较好的结果。
第三种类型的方法通过结合先前提出的一些方法或者使用先进的神经网络来克服以上两类算法的缺点。Ramel[8]提出了一种混合的文本区域提取方法,通过在二值化的图像中进行连通区域检测,然后根据连通块的大小为每个连通块标记预分类标签;再融合前景和背景信息,根据预定义的规则将有重叠的连通区域进行合并及重新标记分类;最后将重心距离较近的文本块合并;此方法在其印刷历史书籍上得到了较好的效果。姜[9]在大型中文古籍《四库全书》自动版面分析系统中,使用了基于传统的混合方法和先验规则的自动处理与人工修正相结合的设计思想;能够自动采用相应算法处理多种规范和准规范的版面。肖[10]在复杂背景下彝文古籍文本提取方法的研究中,利用边缘检测和小波变换对原始图像进行了分解,然后通过GBDT(Gradient Boost Descent Tree)分类器进行文本和非文本的分类,并结合形态学变化和先验规则准确定位文本区域。Bukhari[11]提出一种手写阿拉伯历史文献的正文和侧边注释分割的方法;通过将图像连通区域归一化,提取连通区域的形状特征和上下文特征组成特征向量,然后利用AutoMLP(Auto Multi-Layer Perception)分类器对图像中的连通区域进行分类,结合最近邻分析得到最终的分割结果。
2 基于卷积降噪自编码器的藏文历史文献版面分析方法
本文所提出方法的流程图如图2所示。首先,将藏文历史文献进行超像素聚类,获得超像素块;然后,利用卷积降噪自编码器对超像素块进行特征提取;最后,利用SVM分类器对藏文历史文献的超像素块进行分类,从而提取出藏文历史文献版面的各个部分,并将结果保存在XML中。
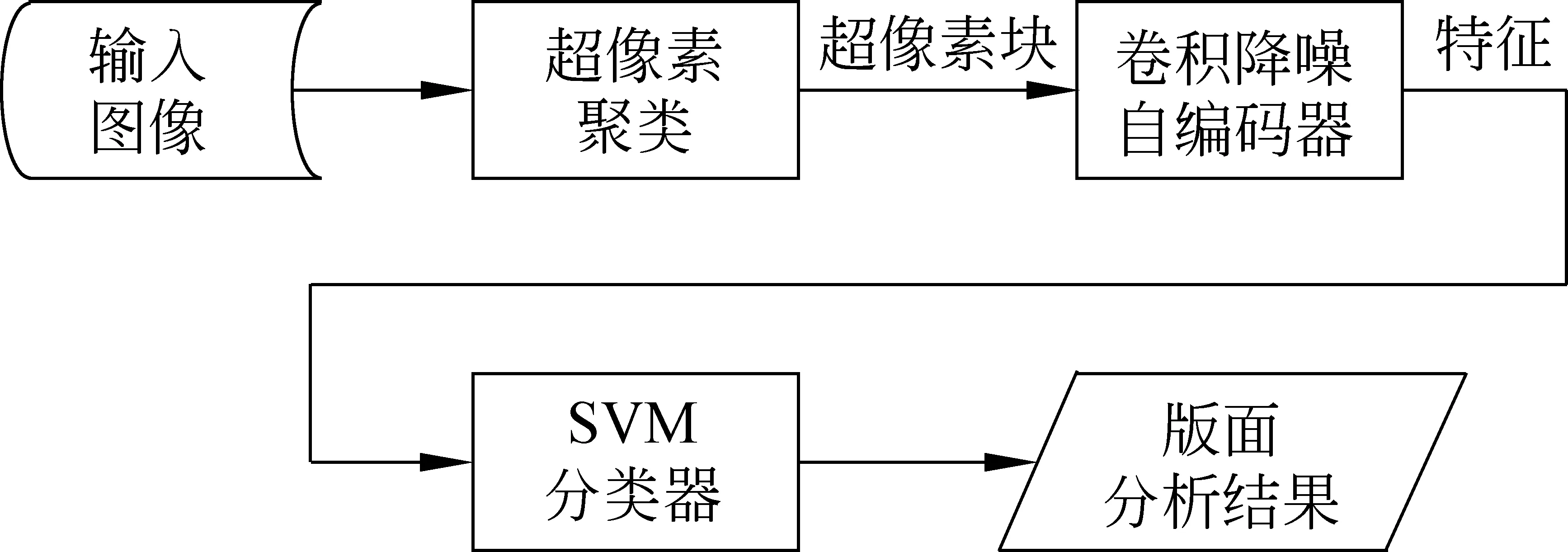
图2 版面分析流程图
2.1 超像素聚类
超像素(Superpixel)是一种图像预处理技术,它利用相邻像素点在纹理、颜色、亮度等特征上的相似程度将相邻像素点聚成一个图像块,从而获取图像的冗余信息,相比传统的图像处理基本单元——像素,超像素有利于提取图像的局部结构特征,能够大幅度减小后续处理的计算复杂度。
本文采用了SLIC[12](Simple Linear Iterative Clustering)算法进行超像素聚类。此算法不仅方法简单而且能够得到高质量整齐的超像素;还有比其他超像素分割方法更高的效率[13],并且可以用于彩色图像和灰度图像。SLIC唯一需要的参数就是设定预期超像素的个数。SLIC算法首先将图像换到CIELAB颜色空间,通过CIELAB颜色空间中的L(亮度通道),A(颜色通道,从红色到深绿),B(颜色通道,从蓝色到黄色)的值以及像素的坐标x、y定义的五维空间进行局部的像素聚类。在这个空间距离不规范的五维空间中,简单地使用欧氏距离进行聚类是不合适的,所以SLIC使用了一种全新距离计算方法,计算方法如式(1)所示。
(1)

超像素聚类算法在五维空间进行聚类时考虑了颜色相似性和像素接近度,使得预期的超像素块的大小和它们的空间范围大致相等,加强了超像素形状的整齐性。图3为藏文历史文献的超像素聚类结果,不同的灰度边缘代表不同的超像素块。从图3中可以看出,大部分不同的版面元素能够被超像素块分割开。

图3 藏文历史文献的超像素聚类结果
2.2 卷积降噪自编码器
2.2.1 自编码器介绍
自编码器(AutoEncoder,AE)是深度神经网络的一种。经过训练后它能尝试将输入通过编码器编码,然后利用解码器解码出与原输入尽可能一致的输出。一般意义上的自编码器内部有一个隐藏层h,可以产生表示输入的编码。通常会给自编码器加上一些强制的约束,使它只能近似地复制与训练数据相似的输入。强制约束使模型优先学习输入数据中具有显著性的特性,因此AE能够学习到数据的有用特征。除了这种单层的自编码器,还有堆叠自编码器(Stacked AE,SAE)、卷积自编码器(Convolutional AE,CAE)、降噪自编码器(Denoising AE,DAE)等多种类型的自编码器[14]。
堆叠自编码器,由一系列的自编码器堆叠而成。每个自编码器的编码作为下一层的输入,这样一层一层堆叠起来,构成一个深层网络,其能够逐层地学习原始数据的多种表达。卷积自编码器,利用卷积从数据中自动学习并提取特征。它的权值共享结构大大减少了网络的参数。结合局部连接,使得网络在图像分析中优势明显,能够自动提取图像的纹理、颜色等特征,其提取的特征有更好的鲁棒性和泛化能力。降噪自编码器,是在自编码器的基础上,将原始输入加入噪声,输出目标为没有被噪声污染过的原始输入;这就迫使编码器去学习输入信号的更加鲁棒的表达,使得其泛化能力比一般编码器更强。
大部分的藏文历史文献是写在藏纸上面的。藏纸是一种用传统手工技术制造的纸张,其表面粗糙,颜色不均匀。在获取藏文历史文献的图像时,也会产生光照不均匀、图像模糊等情况。为了克服藏文历史文献的以上缺点,取得比较好的版面分析效果,本文选用卷积降噪自编码器(Convolutional Denoising AE,CDAE)来提取超像素块的特征。
2.2.2 CDAE的结构
CDAE的结构如图4所示。为了能够展示清楚卷积降噪自编码器的结构,将其编码器部分和解码器分开展示,并标示了每层的Feature Map(FM)个数。它主要由三个卷积层(Conv1,Conv2,Conv3)和相应的三个反卷积层(DConv1,DConv2,DConv3)和两个全连接层(FC1,FC2)组成。各层的具体参数如表1所示。表中“-”的意思是没有此项参数。

图4 自编码器结构图

表1 CDAE的各层的参数
2.2.3 CDAE的输入和目标输出
一般的降噪自编码器的输入为原始图像加上噪声,输出目标为原始图像。通过这样的训练使自编码器能够学习到样本的鲁棒性的表达,降低噪声污染的影响。藏文历史文献图像本身有许多噪声存在,为了使CDAE能够学习到藏文历史文献的鲁棒性表达,消除噪声的影响,本文结合gamma矫正方法和Otsu算法消除了藏文历史文献中的噪点,光照不均衡等的影响,得到了较为清晰的藏文历史文献的二值化图像。并以超像素块在此二值化图像上的对应位置的像素块作为CDAE的目标输出,以原始藏文历史文献的灰度图像中对应位置的像素块为输入训练CDAE自编码器。
图5对CDAE编码器部分的输入和三个卷积层在这个输入上提取的Feature Map进行了可视化。图中每一个块代表该层不同的滤波器所提取的特征;从图中可以看出,同一个卷积层的不同滤波器所产生的特征具有相似性,而不同的卷积层之间所提取的特征差异比较大,这也证实了不同卷积层可以学习到原始输入不同层次的表达。图6展示了CDAE的输入,目标输出和真实输出之间的对比。输入数据为藏文历史文献的灰度图,从图中可以看出,输入图像有比较多的噪点;目标输出为输入图像相应的二值化图像;从CDAE经过训练以后产生的真实输出可以看出,与原始输入图像相比大部分的噪点被消除,而且与目标输出非常相似。

图5 CDAE编码器输入和三层卷积提取的Feature Map

图6 CDAE的训练数据和真实输出
2.3 SVM分类器
支持向量机(Support Vector Machine)是一种分类算法。通过寻求结构风险最小化来提高其泛化能力,实现经验风险和置信范围的最小化。通俗来讲,它是一种二分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,即支持向量机的学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。解线性分类问题,线性分类支持向量机是一种非常有效的方法,但有些分类问题是非线性的,这时支持向量机可以使用核技巧引入一个核函数K,将数据映射到高维空间,来解决在原始空间中线性不可分的问题。常用的核函数有多项式核函数、线性核函数和径向基核函数等[15]。以上介绍的SVM主要是用来解决二分类问题,如果使用SVM解决多分类问题,大致有两种思路。一种是将多分类问题转化为多组二分类问题直接求解;第二种思路是适当改变原始支持向量机的优化问题,直接得到多分类支持向量机;但由于第二种思想计算太过复杂、计算量太大没有被广泛应用。
本文将从藏文历史文献图像中提取的超像素分为三类,即边框、文本和背景,其类别标签分别标记为0、1、2。选用多分类带径向基核函数的支持向量机来训练超像素的分类模型。
3 实验结果及分析
3.1 实验程序框架
实验的操作系统为Ubuntu14.04,GPU为NVIDIA K40M。目前构建卷积神经网络的开源框架有很多,如Theano、Keras、Pytorch、TensorFlow、Caffe等。本文实验选用Keras进行模型搭建,Tensorflow作为Keras后端并利用TFRecords保存训练数据[16]。
3.2 实验数据准备
实验数据来源于青海民族大学提供的藏文历史文献《班禅大师作品全集》的图像,共440张。版面主要有两种类型,一种为边框内只嵌入文本;另一种为如图1所示的边框内嵌入文本和非文本。通过SLIC算法将每个图片聚成1 000个左右的超像素块,以超像素块中心点的像素点所属的类别代表超像素的类别;为了避免重复计算,图片的超像素块信息存储在相应的XML文件中。
由于超像素块的形状是不规则的,为了训练自编码器,选择超像素块的固定边长为45像素的外接四边形区域代替超像素块。自编码器的输入为超像素块的灰度图,输出为其对应的二值化图像块。在所有图像中,属于文本、边框、背景的超像素块分别为33万多块,4万多块和8万多块。为了均衡训练数据,从三类超像素块中分别随机取三类超像素块各4.65万块,共13.95万块构成实验数据集。其中,前12万块(每类包括4万块)作为训练集,其余1.95万块做测试集,训练集中的后10%做验证集。为了方便实验,将数据集以输入图像块,目标图像块,类标签的TFRecords格式存储在二进制文件中。
3.3 实验
3.3.1 自编码器的输入对结果的影响
文献[2]中以三通道彩色图像作为其CAE的输入和目标输出,其数据集的各个部分有明显的颜色区别,颜色信息能对其分类准确性产生比较积极的影响;然而藏文历史文献图像的不同页面之间在颜色和亮度上有比较大的差异;虽然卷积自编码器有比较强的特征提取和泛化能力,但是面对藏文历史文献图像的复杂性,本文认为颜色信息不会对藏文历史文献超像素块的分类产生积极的影响。以下实验验证了这一想法。
用同样结构的自编码器,输入分别设为彩色图像和灰度图像,目标输出均为其对位输入;训练好自编码器之后分别用它们提取的特征训练SVM分类器,对超像素块做分类。CAE为卷积自编码器,其结构与CDAE相同。实验结果如表2所示。

表2 颜色信息对分类结果影响的对比
从实验结果可以看出,输入为彩色图像的自编码器提取的特征分类结果低于灰度图像。此实验表明了对于藏文历史文献来说颜色信息没有对分类产生比较积极的作用,导致分类准确率低于单通道的灰度图像;所以在训练CDAE时,本文选择了藏文历史文献的灰度图像作为输入,消除颜色信息对特征提取过程的干扰,降低计算的复杂度。
3.3.2 降噪对超像素块分类的影响
降噪自编码器能够学习输入信号的更加鲁棒的表达,使得它的泛化能力比一般编码器更强。表3中分别用二值化图和灰度图做目标输出,训练同样结构的自编码器来提取特征对超像素块进行分类。

表3 降噪对分类结果影响的对比
由结果可以看出,用降噪方式训练的自编码器具有更高的分类准确率,这证实了降噪自编码器能够消除噪声的干扰,更专注于藏文历史文献中内容相关的信息。
3.3.3 实验结果对比分析
本文用相同的超像素数据分别对文献[2]中的方法和本文的方法进行了实验。文献[2]中的方法采用了三个不同的全连接层结构自编码器组成,选用不同尺度的训练数据逐层进行训练。对一个超像素块分别用这三个自编码器从不同的尺度提取特征,然后将三个自编码器提取的特征组成一个特征向量。为了更加全面地对比实验结果,除了按照文献[2]中的原始方法(输入图像和目标输出均为彩色图像)进行了实验,在不改变其自编码结构的情况下,还使用了跟本方法类似的降噪方式训练其自编码器。实验结果如表4所示。
从表4中可以看出,在藏文历史文献的版面分析方面,本文的方法要明显优于文献[2]中的方法。从实验结果可以看出,用不同的方式训练的文献[2]的自编码器,分类正确率差异比较小。这表明在藏文历史文献上,文献[2]中的方法获取的特征虽然也学习到了能够区分不同超像素类别的特征,但其特征的泛化能力和鲁棒性较弱。本文的方法可以弥补其不足,得到泛化能力和鲁棒性都较强的特征,取得了较高的分类正确率。

表4 实验结果对比
图7展示了进行超像素分类后的藏文历史文献的版面分析结果,文本区域、边框、边缘背景区域分别用不同的灰度边缘来区分。从图中可以看出大部分的版面元素都能够得到正确的分类结果,但是由于版面的不规则和算法的局限性,有部分超像素块被误分为其他类别。

图7 版面分析结果
4 总结
本文提出了基于卷积降噪自编码器的藏文历史文献的版面分析方法,首先对藏文历史文献图像进行超像素聚类,然后训练卷积降噪自编码器来提取特征,再利用SVM分类器对超像素块进行分类。实验表明,在藏文历史文献的版面分析上,本文的方法获得了较高的分类准确率。但本文设计的方法仍存在一些不足,如藏文历史文献图像数据种类和数量还需完善,网络结构还有改善空间,识别率有待提高,最终结果比较依赖超像素聚类结果等,后续将继续研究改进。
