基于残差量化卷积神经网络的人脸识别方法①
2018-08-17周光朕杜姗姗欧丽君
周光朕,杜姗姗,冯 瑞,,欧丽君,刘 斌
1(复旦大学 计算机科学技术学院,上海 201203)
2(上海市智能信息处理重点实验室 上海视频技术与系统工程研究中心,上海 201203)
3(上海临港智慧城市发展中心,上海 201306)
4(上海无线电设备研究所,上海 200090)
1 引言
人脸识别是一种重要的生物识别技术.利用人脸特征信息,可实现用户无感的身份识别,具有广阔应用前景.过去数十年间,许多人脸识别方法被提出,早期方法通常利用人工设计的特征,结合不同分类器和度量方法进行识别,但识别精度并不理想,存在较大提升空间.
近年来,基于神经网络的方法被广泛用于人脸识别[1,2],取得较好的识别精度.文献[3]提出基于残差学习的卷积神经网络(ResNet),这是一种具有良好学习与泛化能力的网络模型,也可被用于人脸识别[4].文献[4]采用残差卷积神经网络结构,用三个公开数据集总计17 189人,约70万张图像在交叉熵损失函数监督下训练,在人脸识别数据集LFW[5]上取得优异的识别精度.
然而残差卷积神经网络模型中存在海量浮点参数,应用时要消耗巨大的计算和存储资源,效率低下.例如ResNet-50有超过2500万的参数,对224×224大小的3通道输入,计算总量需要42亿多次的浮点乘法.对网络模型进行参数量化是一类可以有效降低网络模型存储消耗和提升计算效率的方法[6],包括二值神经网络BNN[7]、异或网络XNOR-Net[8]和多位量化网络DoReFa-Net[9]等.BNN根据模型参数的符号,用±1表示,并以符号变换甚至异或替代卷积的浮点乘法,大幅压缩了网络模型并提升了计算速度,但有较大的模型精度损失.XNOR-Net在BNN基础上对每层引入一个浮点系数,来减少量化导致的模型精度损失.DoReFa-Net则采用量化到多个比特位的方法,能进一步减少模型精度损失,但相比前二者,需要损失一定的计算加速和网络压缩比.
针对应用于大规模人脸识别的超深残差卷积神经网络存在网络模型过大和计算效率低下的问题,设计了一种基于网络参数量化的超深残差网络模型,包含残差网络模型选择和网络参数量化两部分.具体在模型Fase-ResNet(https://github.com/ydwen/caffe-face)中添加批归一化层和dropout层,并去除中心损失函数,作为基准模型,再通过残差构件堆加和内部层数加深提升基准模型识别精度,并对精度最优的网络参数进行二值量化,在模型识别精度损失极小的情况下,大幅压缩了网络模型大小,并提升了计算效率.
本文组织如下:在第2节介绍了本文工作的算法设计框架;在第3节和第4节分别介绍了框架中两大部分工作,残差卷积神经网络模型选择和卷积神经网络参数量化;在第5节通过理论分析和实验研究分析了本文所设计网络模型的精度、相对基准模型的网络压缩比和效率提升比;最后在第6节对全文工作进行了总结.
2 算法设计框架
基于网络参数量化的超深残差网络模型的设计包括两部分内容:残差卷积神经网络的模型选择和卷积神经网络的参数量化如图1所示.图1的上部和实线右侧图1(c)到(f)给出了其主要工作流程及网络结构,实线左侧图1(a)和(b)是结构(c)到(f)中使用的不同残差构件的内部细节.
模型选择部分对应图1 上部左侧三个方框的内容.在Fase-ResNet的训练模型中加上批归一化(BN)层和dropout层以加快训练收敛和防止过拟合,并去除中心损失函数,以此作为基准模型A,对应图1(c)的网络结构.结合残差网络结构加深的方法,依次在B和C模型中加深了残差构件的堆积次数和内部层数,分别对应图1(d)和(e)的网络结构.其中A和B网络采用图1(a)的残差构件,C网络采用图1(b)的残差构件.在图1中,标识了B和C网络与A使用不同数量和类型残差构件的区别,三者的dropout层应用于Fc5层.
网络量化部分对应图1上部最右侧方框内容,采用了基于BNN、XNOR-Net和DoReFa-Net中的量化函数对神经网络模型的参数进行了量化,并参考其实验方法训练量化网络.考虑到量化操作会一定程度降低原网络模型的识别精度,保留了网络第一个卷积层Conv1a和最后一个全连接层Fc6的浮点数参数,其他量化层在图1(f)中加上了Q作为标记.通过对模型选择工作设计的三个网络模型识别精度最优者进行了网络参数的二值量化,实现在极小的识别精度损失情况下,大幅压缩网络模型大小并提升计算效率.
3 残差卷积神经网络模型选择
3.1 残差学习机制
残差学习在残差神经网络ResNet中被提出,是一种简单高效的网络模型学习机制.深度卷积神经网络通常直接学习输入数据到输出标签的目标映射,但简单地加深这类网络却可能出现训练精度不升反降的情况,即网络模型的恶化(degradation)问题,且该问题并非由过拟合引起.残差学习机制则学习目标映射与原输入的残差量,通过残差值与原输入相加恢复最终的目标映射,可有效解决这一恶化问题.
令H(x)表示输入x的目标映射,卷积神经网络学习的目标函数为F(x).常见方法直接学习这个目标映射,即F(x)=H(x).当恒等映射H(x)=x为目标映射时,F(x)较难拟合这个目标.残差学习机制则学习目标映射与输入之间的残差量,即F(x)=H(x)−x,而目标映射则可以简单地通过原输入与残差量相加来恢复,即H(x)=F(x)+x.
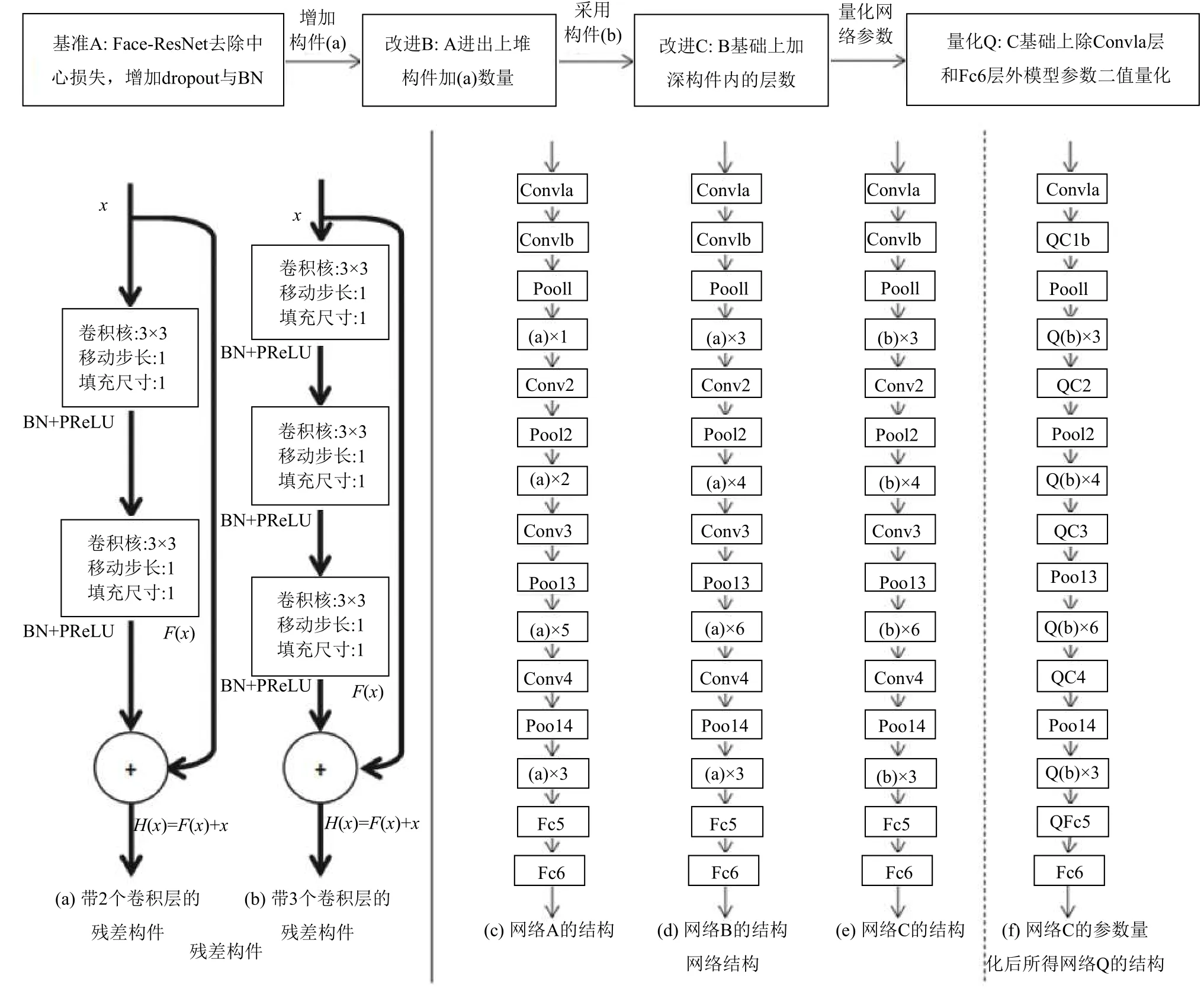
图1 本文工作主要流程(上部)与算法细节(下部)
完成如上残差量与原输入相加操作的一个模块被称为残差构件.设计不同的残差量学习函数可得到不同形式的构件,图1中(a)和(b)就是可能的两种.图中的纵向卷积分支用于学习残差量,而原输入通过旁路分支直接与残差量相加,来恢复目标映射.同时,在每个卷积层的激活函数前添加批归一化层可加快网络模型的训练速度.
残差学习机制在ResNet中被证明可用来训练超深层次的卷积神经网络,精度优于其他常见的卷积神经网络方法,且网络模型层次越深,精度越好.
3.2 模型选择过程
针对Face-ResNet网络设计基准模型存在的两个问题:一是此模型的全连接层存在较多参数,dropout层被引入来防止模型发生过拟合情况;二是为加快网络训练,在每个卷积层的激活函数前添加批归一化层.
但是,网络中原有的中心损失函数需要计算全连接层输出特征与原数据空间每一类中心值之间的差异,而Dropout层却按设定比例随机舍弃全连接层参数,将导致训练时全连接层输出特征分布非常不稳定,极大影响中心损失函数的监督效果.另外,中心损失函数需要得到训练数据每类中心.若存在离群值,将对中心的位置造成影响,进而影响中心损失函数的监督效果.基于这两个问题,本文在基准模型中舍去中心损失函数,只用交叉熵损失函数作为监督.经过以上改进可得网络模型A,图1(a)是A使用的残差构件,图1(c)是其网络大致结构.
根据残差卷积神经网络层次越深,精度越好的特点,本文在网络A基础上加深网络模型.但过深的残差网会参数过量,训练数据量一定时,网络可能得不到充分训练而使精度的提升并不多,同时却要消耗更多存储和计算资源,影响量化带来的压缩比和效率提升,故本文只参考了34层与50层ResNet的设置.首先对A网络增加残差构件的堆积数,在Conv2_x、Conv3_x、Conv4_x分别增加了2个、2个、1个图1(a)的残差构件,得到网络B.接着,又在B的基础上增加构件内部的卷积层数,即用图1(b)的残差构件,得到网络C.网络B和C的大致结构如图1(d)和(e)所示.除以上设计,Face-ResNet其他层的参数设均被保留.
残差构件中卷积层的卷积核、移动步长和填充尺寸分别是3×3、1和1,其他卷积层不作填充.卷积支路的填充操作可保证原输入x和残差量F(x)相加时维度对应相等.池化层的区间设为2×2,移动步长为2.在相同通道数的卷积层中间,输出的特征图大小不变;而特征图经过池化长宽均缩小一半时,卷积层通道数则加倍.网络模型A到C每层具体的参数设置见表1,其中输入均为112×96像素大小的3通道图片数据.

表1 模型选择3种结构的具体参数设置
4 卷积神经网络参数量化
卷积神经网络参数量化方法通常将网络每层参数量化到k个值,用位索引表示,量化模型保存索引与这些值.取整和符号函数常用于量化.若k=2,且取值为±1,则为二值量化.二值量化网络只用1比特位表示参数,可大幅压缩网络模型,计算时用符号改变替代浮点乘法,可提高模型的计算效率.
4.1 二值神经网络
假设卷积神经网络模型有L层,记第l(l=1,2,···,L)层权值参数矩阵为Wl∈Rkl×kl×cl,每个元素为w,其中kl为卷积核边长,cl为通道数.用Wlb表示二值量化后网络每层参数,每个元素wb∈{+1,−1}.二值神经网络BNN中使用了符号函数进行量化,如公式(1).

符号函数的导函数几乎处处为0,反向传播算法不能训练网络,需要设定其梯度反传函数.BNN在训练时保留绝对值较小参数的梯度而抑制绝对值较大参数的梯度,以gs和gw分别表示符号函数和恒等函数的梯度,BNN使用gs=gw1|w|≤1,具体如公式(2)所示.

将以上两者用于普通卷积神经网络训练中,BNN对网络每层参数进行二值量化,可一定程度保持原浮点网络模型的精度,同时大幅压缩网络模型并提升计算效率.
4.2 异或网络
由于BNN应用于大规模数据集上将造成网络模型精度大幅下降,异或网络XNOR-Net做了改进.离散卷积操作可转为矩阵相乘.令每层的输入矩阵为X,参数矩阵为W,则每层卷积计算为W·X.异或网络在每层二值矩阵Wb前乘上一个浮点系数α,卷积计算近似变为W·X≈α(Wb·X).选取最佳α和Wb近似原卷积计算则通过固定W后 最小化得到.利用WbT·Wb=N(N为卷积核元素个数),可得到最优解Wb∗=sign(W)和α∗=‖W‖/N.Wb仍由W用符号函数二值量化,α为每层卷积矩阵参数绝对值和的平均.
神经网络中间层的输入为上一层输出的激活值.按同样方式,可得到每层输入X的二值量化近似表示X≈βXb.此时,原来的卷积计算就可以近似变为W·X≈αβ(Wb·Xb).其中Wb·Xb可用异或操作计算,计算速度大幅提升.
卷积神经网络的卷积模块包含四部分,依次为卷积、批归一化、激活和池化.若按此顺序对神经网络参数和激活值二值量化,且采用最大池化方式,将导致多数+1被保留而–1被舍去,对模型精度会造成巨大影响.因此,将池化放在激活之前,改动卷积模块为卷积、批归一化、池化和激活,再对卷积参数和池化输出作二值量化.此外,将输入归一化,使其均值为零,也可减少二值量化带来的模型精度损失.
异或网络可用BNN的训练方法,给每层二值量化参数和激活值乘上一个浮点系数,相比BNN,可在网络模型精度更小损失的情况下获得相近的网络压缩比和计算效率提升.
4.3 多位量化网络
在前两种量化网络基础上,多位量化网络DoReFa-Net提出对网络参数进行多位量化的方法.设是闭区间[0,1]上的一个实数,将它量化到0到1闭区间上的k位(k≥2)量化值xq的函数qk(x)如公式(3).
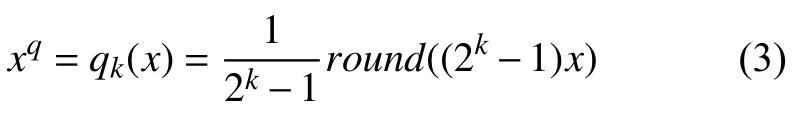
神经网络每层参数W 和激活值A的量化函数如公式(4)和(5)所示.
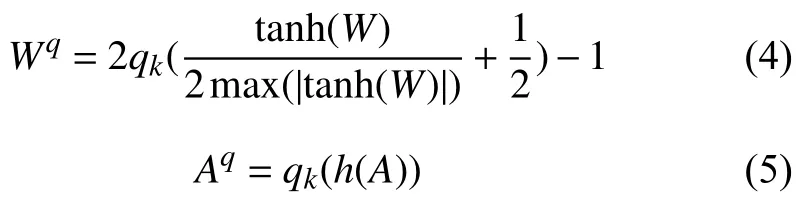
其中,h(x)是值域在[0,1]上的函数,可用的有h(x)=0.5(tanh(x)+1),h(x)=min(1,|x|),h(x)=clip(x,0,1)等.当k=1时,则使用异或网络的二值量化方法.
DoReFa-Net使用前两种量化网络的训练方式,设置网络参数的不同量化位数k,可对网络模型进行不同程度的量化.相比BNN和XNOR-Net,量化位数k越大,对原浮点网络模型精度导致的损失越小,但同时网络模型也越大,需要更多存储空间,对计算效率的提升也越少.需要设置合理的k值折衷网络精度损失和网络模型压缩比与计算效率提升.
DoReFa-Net也有对训练梯度的多位量化方法,但本文考虑到梯度对训练的重要性,保留其浮点表示.本文基于多位量化网络的参数量化方法,在实验中对网络模型参数进行二值量化.实验情况将在第5节中说明.
5 实验与分析
5.1 实验环境与数据集准备
本文算法实验的系统环境为Linux Ubuntu 16.04,服务器配置为Intel Xeon E5-2620 v4处理器、128 G内存和NVIDIA图形处理单元GTX 1080 TI GPU卡.实验采用tensorpack(https://github.com/ppwwyyxx/tensorpack)工具包搭建本文设计的网络模型.
CASIA-WebFace数据集[10]被用于实验的训练,利用室外带标注的人脸数据集LFW用于网络模型的精度测试.CASIA-WebFace是目前最大的公开人脸识别数据集之一,全部数据采集自互联网,包含10 575人共494 414张图片.LFW数据集则有5749位名人的13 233张网络图片,均采集自室外场景.
一些方法被用于训练和测试数据的预处理.对CASIA-WebFace的标注(http://zhengyingbin.cc/Active AnnotationLearning/)[11]被用于提升训练数据质量.MTCNN(https://github.com/kpzhang93/MTCNN_face_detection_alignment)[12]则被用于检测图像中人脸位置和人脸特征点,如双眼中心、嘴角两侧等.文献[13]方法(https://github.com/AlfredXiangWu/face_verification_experiment)可用特征点进行对齐,将人脸转为基本正视前方.若MTCNN未检测到人脸,直接舍弃训练集图片,而对测试集图片截取中心144×144像素区域并对齐.训练数据集经过处理后余下约44万张图片,图像被调整到128×128大小,测试集图片被调整到144×144大小.
图像输入网络时被裁剪到112×96大小,训练集使用随机裁剪,测试集采用中心裁剪.另外,实验对训练和测试数据的每个像素减去127.5并除以128,将像素归一化到–1与+1之间,使其整体上具有均值为零的分布,尽可能减少量化带来的网络精度损失.
5.2 实验设置与评判方式
随机抽取训练数据集每人两张图片,共21 150张图片作为训练的验证集,剩余图片用于训练.训练中,除使用随机裁剪外,输入图像的翻转被用于数据增强.网络模型训练阶段共100个epoch,每个epoch有10 000个step,每个step输入一个批次图像.实验设置每批次64张图,初始学习率为0.01,在40、70、90个epoch时将学习率依次缩小10倍.
量化网络模型的训练采用相同设置,并采用多位量化网络的量化设置,对Conv1a层和Fc6层外的卷积和全连接层进行二值量化.实验中,未量化网络约在50个epoch后收敛,而量化网络则在约55个epoch后收敛.
由于两数据集的人并不相同,测试时先对测试图片和其翻转输入网络模型,取Fc5层的输出,得到两组1024维特征,拼接得到2048维特征.判断两张测试图片是否为同一人时,对两组2048维特征计算余弦距离相似度,按照设定阈值进行判断.
LFW提供一份分为10组随机生成的共6000对图像的测试集合验证算法精度.其中3000对是相同的人,另3000对是不同的人.通过以上方法对6000对图像进行测试,算法在10个分组中交叉验证,以10组验证结果的均值报告算法精度.
5.3 实验结果
首先对模型选择中设计的三个网络模型进行了精度测评,结果见表2.可以看到,随着网络层次的增加,基于残差学习的超深卷积神经网络模型的精度可以逐步提升,并且加深后的网络B和C都超过了其他两个神经网络方法.其中网络C精度达到97.83%,超过LFW报告的人类水平97.53%,是这些网络模型中的精度最优者.
接着,对精度最优的网络C根据5.2节的设置进行了量化训练,得到了量化模型Q,并在测试集上报告了97.43%的准确率,相比模型C仅有0.4%的模型精度损失,而比基准网络模型A更有精度的提升.

表2 各种方法在LFW验证集上报告的精度结果
5.4 压缩比与效率提升分析
由于测试时最后一层Fc6未参与计算,故本文中针对模型计算效率提升的比较不含Fc6层.参考异或网络文献,量化网络Q相比网络C可有2倍的计算加速,并能将网络压缩32倍.表3列出了本文工作设计的4种网络结构的参数量、浮点计算量和相对基准模型A的压缩比与效率提升情况,均通过理论计算得出.可以看到,尽管网络C相对A增加约30%的参数,但经过二值量化,模型Q相对A有整体上接近4倍的压缩.当除去最后的Fc6层时,压缩比甚至可以达到22.8,并有1.05倍的效率提升.
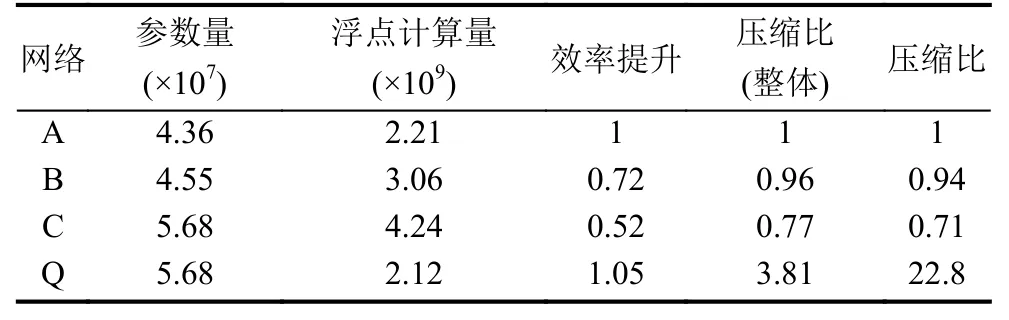
表3 各网络模型的参数与相比基准模型的压缩比和效率提升情况
6 总结
本文针对应用于大规模人脸识别的超深残差卷积神经网络存在网络模型过大和计算效率低下的问题,设计了一种基于网络参数量化的超深残差网络模型,具体在Face-ResNet模型基础上,增加批归一化层和dropout层,加深网络层次,对网络模型参数进行二值量化.通过理论分析和实验验证,本文设计的网络可以在模型识别精度损失极小的情况下,将网络模型压缩22.8倍并提升1.05倍计算效率.由于目前仅量化了网络的参数,未来可以考虑调整训练方式,将计算时每层输入也进行量化,以提升更多的计算效率.量化的网络也适用于FPGA,可以考虑将其移植到FPGA上来进一步提升计算效率.
