面向场景的数据交换隐私保护模型研究文献综述
2018-08-13赵小柯刘志天
赵小柯,刘志天,刘 瑶
(北京交通大学 北京 100044)
1 引言
伴随着计算机技术的飞速发展,网络连接和磁盘存储空间日益增加,网络数据安全的保护工作也得到了越来越多人的重视,给隐私保护带来了新的挑战与机遇。目前各大高校内运行的应用系统数量已经比较庞大,各个应用系统之间交流频繁,对于数据交换与数据共享的需求也日益增加[1]。
隐私保护最早是T Dalenius提出来的,1977年,他给隐私保护出具了一份说明,把访问发布后的所有数据与不访问数据做了一个对比,目的是为了不让不法分子得到目标外的其他信息,即使他们有着其他渠道获得消息,从中发现只有在不发布数据的时候,完美隐私才会实现,这个时候没有任何的泄露风险。”[2]最重要的一个任务是开发发布数据的方法和工具,以便公开的数据在保持可用性的同时保护个人隐私,这就是数据发布过程中的隐私保护。认为数据收集阶段是诚实的模型,数据共享的阶段是非诚实性的,数据接收者的诚实性无法保证[3],在此阶段为了避免隐私泄露,就需要适当地采取一定的数据隐私保护技术。
本文以一些特殊的场景为出发点,比如数据交换,从而对隐私保护模型进行阐述,发表自己的观点。
2 静态数据隐私保护模型研究现状
目前关于隐私保护模型的研究中,数据记录属性主要有三种,分也就是显式标识、准标识和敏感属性。显式标识属性是唯一标识单一个体的属性,准标识属性是组合起来能唯一标示一个人的属性。在公布数据时人们能意识到通过对于显式标识属性的处理来保护个人信息,但是准标识属性结合到一起同样可以识别一个人的属性,在1998年Samarati等人就曾提出K-匿名模型来解决这一问题[4]。也就是说至少要有K-1条记录体现在发表的数据里,使得准标识属性能够取得相同的值,如果K条记录相同,这种情况就称为等价类。根据Machanavajjhala等人的研究,k-匿名模型很容易受到攻击,如果攻击者确定了目标在等价类中敏感属性都相等,那么攻击者就必然发动攻击。
除此之外基本的隐私保护模型还有ι-多样性匿名模型[5],ι-多样性匿名模型要求所发布的数据表中每一个等价类都得由代表,能够代替敏感值属性,这个代表要满足相异ι-多样性、信息熵ι-多样性与递归(c,l)-多样性。
为了弥补上述两种匿名模型的缺陷,2007年Machanavajjhala等人提出了t-closeness模型[6],该模型在k-匿名模型与ι-多样性模型的基础上作出了改进,它要求任何等价类中的敏感属性的分布接近于整个表中属性的分布,即两个分布之间的距离应该不超过阈值t。
(a,k)-匿名模型着眼于个人身份与敏感属性之间的关联,是一种限制推测敏感信度的方法[9]。

表1 静态数据隐私保护模型对比
3 动态数据隐私保护模型研究现状
拓展动态数据主要有四种发布情形,以下做简单的介绍:
多次查询的发布[7]:适用于原始数据都相同,根据用途和对象不同,属性也不一样,之后再发布匿名数据。当攻击者获得两次以上的数据表时,就可以把多张数据表连接起来,发动联合攻击。
相继查询的发布[8]:这个适用于原始数据都相同的情况,根据用途或者对象不同,选择属性也不一样,之后再发布匿名数据。即数据发布者发布了数据表T1,T2,…,TP-1,即将要发布数据表Tp,数据拥有者对Tp进行匿名化操作。
连续数据发布:指数据发布者己经发布了数据表T1,T2,…,TP-1,现在要发布数据表Tp,而在发表T1,T2,…,TP的过程中每一张表都是前一张表的增加、删除、修改。
联合数据发布:适用于数据分布不同的组织,目的是为了融合数据,就把分布式存储的数据共同发布给第三方,除了要避免数据泄露给第三方之外,还需要避免泄露给其他拥有者。

表2 动态数据隐私保护模型对比
4 信息度量
为了在满足隐私保护的需求的同时兼顾信息共享,使得数据的接受者能够获取足够的信息进行分析处理,就需要引入信息度量的概念来评价信息质量。
4.1 通用的信息度量
一般来说,当发布数据的人不知道数据将来会被用做何种用途,为了提高匿名数据的质量,就会与原数据比对,减少信息损失程度。
最小失真(MD:Minimal Distortion)是指通过计算含有范化或抑制数值的记录来计算该数值的失真的计算方法。
失真比率(Distortion ratio):敏感属性值的变化都会按照固定结构进行,当值进行泛化时就会失真,失真反映了这个值的泛化程度。数据表中的记录rj的准标识属性qi泛化后的高度记为整个泛化的数据表的失真等于整个表中全体数值的失真的总和,即
广全面信息损失(ILoss:Information Loss):这是一种比较常见的计算信息损失的计算方法,在计算信息损失时需要按照泛华结构来进行,例如,属性x泛化的属性值vg,|Dx|是属性x的值域相异值,值域相异值也就是属性x的分类树的叶子节点数量,则计算vg的信息损失是:
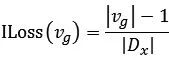
|vg|就是指泛化结构中节点vg的后代的叶子节点的数量。
辨识度(DM:Discernibility Metric)被定义为:
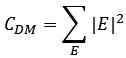
其中|E|表示的是等价类E的大小,每条记录的准标识属性与其他记录的相似程度通常用辨识度表示。
4.2 基于权衡的信息度量
简单来说,保留有用信息的匿名操作会使数据丢失。隐私和信息影响了混合的信息损失度,二者平衡一下,需要找到一个更加细化的空间。
信息和隐私权衡的搜索原则[9],由Fung等人提出。在匿名化的算法中,每次都要选取一个节点来保证细化操作s。将操作前后对比,如果获得信息记作IG(s),丢失的隐私信息记为PL(s),那么在多次的匿名操作中,搜索满足损失单位隐私所获得的信息增益最大的细化空间:
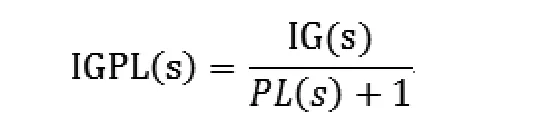
其中信息度量IG(s)和隐私模型PL(s)是由不同模型决定的。在进行分类的应用里,IG(s)定义为细化后减少的分类熵获得的信息增益,PL(s)定义为细化操作s之后信息失真MD的减少量。
在自底向上的算法中,信息和隐私之间的权衡满足搜索原则,当执行泛化操作时,操作前后对比搜索保持每个单位的隐私所造成信息损失的最小的泛化空间:
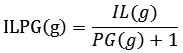
其中IL(g)是信息失真,PG(g)是获取的隐私。
5 数据价值评定
目前的数据价值评定方法很多,面向不同的应用场景评定数据价值时考虑的因素也不同,数据价值评定的方法也不同。
目前的数据价值评定研究主要着眼于两个方面,即数据科研价值、数据存储价值,面对不同的数据价值评定诉求,使用不同的价值标准。
