基于增量学习的非平衡SVM分类方法
2018-08-07崔丽娜郭虎升
崔丽娜,郭虎升
(1.长治学院沁县师范分院,山西 长治 046400; 2.山西大学计算机与信息技术学院,山西 太原 030006)
0 引 言
根据维基百科定义,大数据指规模巨大且类型复杂的数据,在许多大数据挖掘与分析的实际应用领域,数据呈现非平衡化的趋势越来越明显,如极端气候预测、基因检测、欺诈检测、电子商务等[1-3]。在这类问题当中,一般将多数类样本作为负类样本,将少数类样本当成正类样本,由于负类样本规模巨大,其价值密度低,容易对高价值密度的正类样本分类产生负面作用,如采用SVM处理非平衡分类时,甚至会将全部的正类样本预测为负类,忽略了重要的正类样本信息,得到泛化能力较低(甚至完全失效)的学习器(如图1所示)。

图1 SVM非平衡分类导致错误超平面示意图
针对这个问题,研究者已提出一些面向非平衡数据的优化模型,通常可分为2类[4]:
1)预处理模型。首先,针对样本规模分布不平衡的分类问题,对正类数据进行上采样(即扩展小规模样本)或对负类数据进行下采样(即压缩大规模样本),然后再进行学习;其次针对样本密度分布不平衡的分类问题,对稀疏区域数据进行收缩(收缩稀疏数据的分布区域)或对密集区域数据进行扩张(扩张密集数据的分布区域)并进行训练。典型的面向非平衡数据的预处理方法包括基于SMOTE上采样方法[5]、基于多类样本的下采样方法[6]、重要样本预抽取的方法[7]、树形结构剪枝技术[8]、基于关联规则的非平衡分类方法[9]等。
2)权值调整模型。即对分布不平衡的数据赋予不同的权值参数或惩罚因子,以改变不同分布区域内样本的重要性和对分类超平面的贡献程度。典型的权值调整方法包括惩罚因子调整方法[10]、损失函数加权方法[11]等。
此外,也有许多学者结合预处理模型和权值调整来改进非平衡问题的性能[12-13]。
在面向非平衡的大数据分析挖掘问题中,传统的样本预处理方法或者权值调整方法由于需要删除部分样本信息及人为调整权值参数,容易导致分类信息的丢失及分类结果的不可解释性,且实验结果的优劣不易控制,训练结果时好时坏。针对这些问题,本文提出一种基于增量学习的非平衡分类方法。先提取负类样本中的部分样本,与正类样本合并参与训练得到初始的分类器,然后根据分类器与其他样本的关系,选择距离分类器最近的负类样本作为增量样本加入训练集参与训练,从而减小实际参与训练的负类数据规模,提高非平衡分类的性能。
1 基于增量学习的非平衡SVM分类
1.1 增量学习
传统的机器学习方法大多采用批量学习的方式进行,即假设在训练之前所有样本一次性得到,并且这些样本进行一次性学习,学习完成即可得到最终的学习器。然而,在实际问题中,一方面所有的训练样本可能不是一次性得到,另一方面即使一次性得到的训练样本也可能由于规模巨大或类型复杂很难一次性进行训练或者训练得到的学习器效果较差。增量学习算法采用样本分批次进入的方式,可以将大规模的复杂机器学习问题转化为小规模的简单求解问题,可有效利用历史训练结果,显著减少后续训练的时间。
增量学习具有如下几个方面的特点[14]:1)可以从新数据中学习新知识;2)已训练的数据不需要重复训练;3)每次增量过程中只有少量样本加入;4)能有效保存已经学习得到的知识;5)一旦学习完成仅保留学习器而丢弃大量冗余样本;6)不需要整个数据集的先验知识。
1.2 基于增量学习的非平衡SVM算法
针对传统SVM分类时无法有效识别重要的正类样本而导致分类效果较差的问题,本文提出一种基于增量学习的非平衡SVM分类方法。该方法首先从不重要的负类样本中随机提取部分样本,将其与全部正类样本结合,构成初始的训练集并训练SVM,以得到初始的分类器及初始的负类支持向量集;然后根据当前没有参与训练过程的剩余负类样本与当前分类器的距离,选择距离分类器最近的负类样本作为增量样本,与当前得到的负类支持向量集以及正类样本合并后训练新的SVM模型,以更新分类器。本文方法中,每次训练过程中,负类样本中仅有保留下来的支持向量和当前新加入的增量样本参与训练,因此减小了负类样本的规模,使得原始分布不平衡的数据变得更为平衡,以增加SVM对于重要的正类样本的辨识能力,提高非平衡分类的性能。
在标准SVM当中,分类超平面可以表示成f(x)=w·φ(x)+b的形式,其中φ(·)为映射函数。当SVM得到的分类面表示形式标准化后,对于任意的支持向量样本sv,都有|f(sv)|=1成立,即对于负类支持向量sv-,有f(sv-)=-1,对于正类支持向量sv+,有f(sv+)=1成立。尽管在支持向量机当中,从低维空间到高位特征空间的映射函数φ(·)无法显式得到,因此任意负类样本到超平面的绝对距离也无法计算得出。但对于任意的输入样本,SVM可以通过式(1)反映样本x到超平面f的相对距离:
(1)

具体地,本文提出的ISVM_IL算法如算法1所示。
算法1ISVM_IL算法


(2)
更新训练样本集:
(3)
Step3在训练集Trt+1上训练并测试,得到新的ft+1、SVt+1及各种测试指标值。
Step4迭代循环执行Step2~Step3,直到满足设置的迭代次数为止。
Step5算法结束。
2 实验结果及分析
为验证所提出的ISVM_IL方法的性能,本文在3个标准数据集[15]上进行了测试(见表1),实验中高斯核参数取1.0,惩罚因子取1000。实验采用文献[16]所提出的4种评价指标来评价算法性能。
表1 实验数据集

数据集训练集(负/正类)测试集(负/正类)维数Thyroid1820(1800/20)1011(1000/11)5Spambase1530(1500/30)765(750/15)57Australian Sign Language (ASL)130(100/30)120(93/27)22
实验中,将本文所提出的方法与基于聚类的SVM非平衡多分类方法(C_SVM)[16]进行了对比,表2为2种方法在Thyroid上得到的实验结果,其中ISVM_IL方法对应的参数是迭代次数(为快速得到最优值,实验中每次选择最近的2个样本加入到训练集当中,在实际操作中,可以根据问题的情况选择每次加入的增量样本规模),C_SVM方法对应的参数是聚类个数。
表2 ISVM_IL与C_SVM在Thyroid上的结果比较

StepG_meansImpor_rateSacri_rateAccISVM_ILC_SVMISVM_ILC_SVMISVM_ILC_SVMISVM_ILC_SVMk10.6140.6290.4810.4550.1320.2620.8740.8651020.6550.5820.4980.3640.0970.1730.9310.9251530.6730.5950.5350.3640.1540.0700.9250.9652040.7140.5090.5640.2730.0730.1730.9660.9412550.7420.4090.5820.1820.0970.3900.9450.9143060.5990.4090.4730.1820.1580.3950.9530.9303570.6340.4180.4320.1820.0910.2050.9120.9514080.5380.5110.2990.2730.2330.1370.9230.9524590.4430.2960.2910.0910.3640.3900.9170.96250
从表2可以看出,在最能反映正类样本分类情况的G_means和Impor_rate这2个指标上,本文提出的ISVM_IL方法均明显优于传统的基于聚类的非平衡SVM分类方法,其中ISVM_IL方法的G_means最优值达到了0.742,比C_SVM提高了18%,其Impor_rate值达到了0.582,比C_SVM方法提高了27.9%,这说明本文提出的ISVM_IL方法对于重要的正类样本有较好的辨识能力。此外,本文提出的Sacri_rate的指标也明显低于传统的C_SVM方法的值,这说明与C_SVM方法相比,ISVM_IL对于大量的负类样本分类效果也并不差。图2和图3为2种方法对应的最优分类情况时得到的分类超平面效果图。

图2 ISVM_IL分类超平面 图3 C_SVM分类超平面
在其他2个数据集上的实验结果见表3和表4,从表3和表4中也可以看出,本文提出的基于增量学习的方法对于重要的正类样本和对于大量的负类样本都具有较好的分类效果,即在非平衡分类的多数类和少数类样本的分类过程中得到了更好的分类折中。
表3 ISVM_IL与C_SVM在Spambase上的结果比较
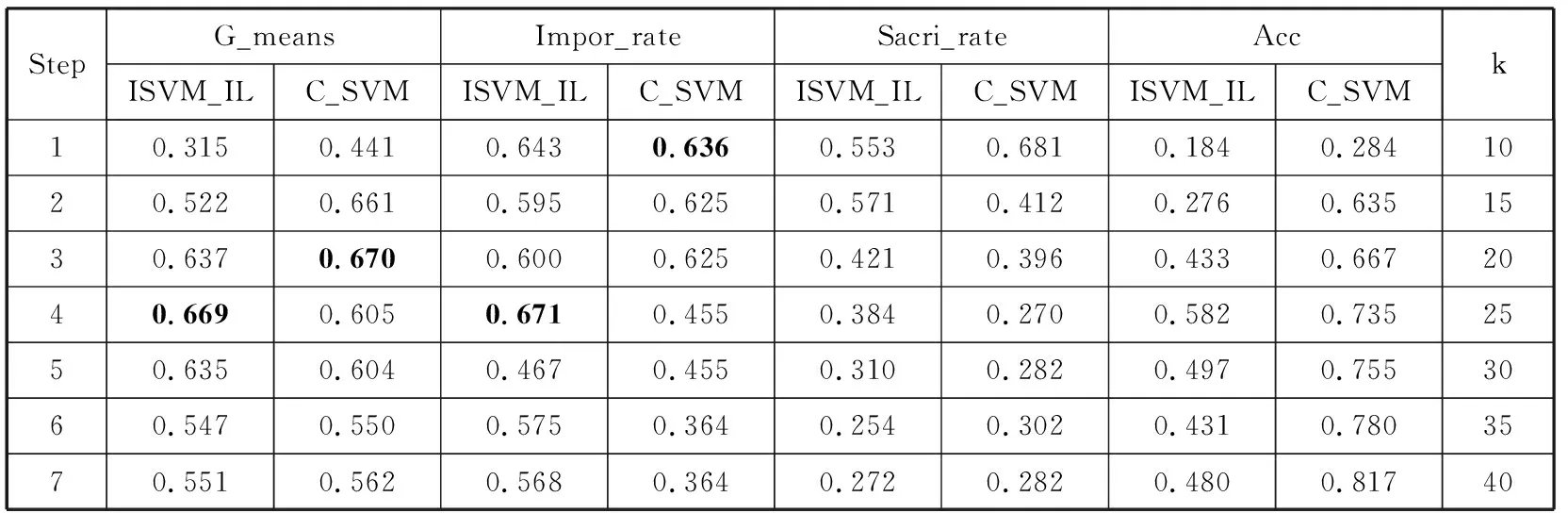
StepG_meansImpor_rateSacri_rateAccISVM_ILC_SVMISVM_ILC_SVMISVM_ILC_SVMISVM_ILC_SVMk10.3150.4410.6430.6360.5530.6810.1840.2841020.5220.6610.5950.6250.5710.4120.2760.6351530.6370.6700.6000.6250.4210.3960.4330.6672040.6690.6050.6710.4550.3840.2700.5820.7352550.6350.6040.4670.4550.3100.2820.4970.7553060.5470.5500.5750.3640.2540.3020.4310.7803570.5510.5620.5680.3640.2720.2820.4800.81740
表4 ISVM_IL与C_SVM在ASL上的结果比较
综上可看出,本文提出的基于增量学习的非平衡SVM分类方法,可以有效地提取负类样本中对于分类起关键作用的增量样本,而删除大量对于分类不起作用的冗余负类样本,增强样本分布的平衡性,提高非平衡分类的性能。
3 结束语
针对传统SVM在处理非平衡分类问题时,容易将重要的少数正类样本错误地识别为负类样本而导致丢失了非平衡分类问题中的重要信息的问题,本文结合增量学习的思想,提出了一种基于增量学习的非平衡SVM分类方法,通过近似超平面的启发式信息,逐步提取负类样本中重要的增量样本,迭代加入到训练样本集当中,从而提高了非平衡分类的性能。
由于在非平衡分类特别是基于SVM的非平衡分类当中,对于重要的少数类样本往往分类性能较差,甚至完全分不开,在平衡分类算法的改进研究中,首要关注少数类样本的分类性能。无论采用采样方法还是采用惩罚因子加权的方法,包括本文所提出的方法以及本文对比的C_SVM方法,预处理的过程大多都是较耗时间的,但为了能够获得更好的少数类样本的分类正确率,在非平衡分类问题当中,这种时间损耗往往不被专门考虑。在未来处理大规模非平衡分类问题当中,可以适当结合其他加速方法来提高非平衡分类的效率。
