基于时间序列分析的工尺谱自动翻译研究
2018-07-26李荣锋毕明辉李学明
李荣锋,毕明辉,李学明,柳 杨
(1.北京邮电大学 数字媒体与设计艺术学院,北京 100876; 2.北京大学 艺术学院,北京 100871)
工尺谱是应用范围最广的中国传统乐谱.工尺谱的鼎盛年代在清代,也就是中国戏曲盛行的年代.而词唱曲唱大量出现于当时盛行的昆剧中,因此词曲的工尺谱便作为昆剧中的一个重要部分被大量记载,现存许多珍贵资料.据《中国音乐书谱志》[1]记载,清代至民国年间共约有1071种工尺谱曲本,现存的乐谱是中国传统乐谱中保存最多的一种.相比中国的其他传统乐谱而言,工尺谱的符号体系是相对规范和统一的,对音高和节拍信息的记录也相对精确.然而,在节奏方面,工尺谱使用了一种相对自由的记谱方式,即只规定节拍的起始位置,而对于每一拍内的时值则未作任何规定.这种在节奏上的不确定性,是工尺谱在解读方面历来的难题.自古以来,如何决定工尺谱中的音符时值,主要是通过口传心授的方式代代相传的.如今,能够顺利解读工尺谱的专家越来越少,这就使得工尺谱的学习成本越来越高,从而使用这种传统乐谱的音乐形式(例如昆曲、京剧)的教学难度也变得越来越大.本文着力于研究如何使用现有的工尺谱的五线谱或简谱人工翻译结果作为数据,建立统计模型,让计算机进行工尺谱自动翻译.
1 关于工尺谱自动翻译的必要性与合理性
在详细介绍关于工尺谱自动翻译的统计模型之前,首先要回答的问题便是这种自动翻译的做法的必要性与合理性.我们需要回答两个问题: 在昆曲、京剧的传统教学过程中,将工尺谱翻译成简谱或者五线谱是否必要?在翻译过程中,将工尺谱中不确定的音符时值对应到简谱或者五线谱中确定的节奏型是否合理?
1.1 工尺谱翻译成简谱或五线谱的必要性
工尺谱作为一种独立于西方音乐的乐谱形式,其中包含中国传统音乐的内涵是其他乐谱所不具备的.从信息传递的角度来说,工尺谱相比西方的五线谱系统,除了基本的音高以及节奏符号之外,还记录了许多关于字腔表现、具体演唱与演奏法、音的虚实等符号以及关于句读、平仄方面的文学符号.因此其文化内涵是其他乐谱所不能代替的.然而随着时代的变迁,由于现代的中小学音乐启蒙教育大多基于西方的音乐理论基础,工尺谱在现今的基础教育中已经不再涉及.因此近几十年来,从事昆曲、京剧的教师、学生、乐师当中,使用简谱甚至五线谱进行传习与演奏已经变得越来越普遍,甚至已经成为主流.乐手们更愿意在简谱或者五线谱上添加原工尺谱中所标记的演奏记号来进行学习和演奏.可以说,虽然简谱或者五线谱在信息记载上,丢失了很多很重要的音乐、文学、文化上的符号,但由于其精确性、系统性更符合当代人学习音乐的现状,因此使用简谱或者五线谱学习中国传统音乐,是一种必要的妥协,并且已经成为不可逆转的趋势.
在这种妥协被普遍接受并已经成为一种需求的同时,中国传统音乐的简谱五线谱版本的数量相对而言是十分匮乏的.尽管经过几代音乐家在曲谱出版方面的努力,许多经典昆曲、京剧剧目的简谱以及五线谱版本[2-4]已经出版,然而现存的可以考证的中国传统曲谱中,绝大多数仍然只有工尺谱版本,被翻译成简谱或者五线谱的数量相比之下还是相当的少.作为一种已经渐渐失传的传统文化,能正确解读工尺谱的专家已经越来越少,这便意味着通过人工出版曲谱的形式可行性已经越来越低.为此,本文基于现有的翻译工作基础上,通过统计分析,让计算机自动地翻译现存的工尺谱,以满足当今的学生学习中国传统音乐的需求.
1.2 工尺谱翻译成简谱或五线谱的合理性

有关即兴演奏,大部分研究者秉持的是一种虽不精确但又不失逻辑的一种观点.其中,民族音乐研究学者奈特尔[5]认为,尽管影响同一首曲子每一次演奏的即兴因素有很多,随着时间和地点的不同还会有微妙的变化,然而这并不代表即兴等同于没有逻辑或者完全由演奏者根据个性随机决定的演奏,而是依赖一系列约定俗成的、隐性的规则.关于工尺谱的即兴演奏中的节奏问题,杨荫浏先生在《工尺谱浅说》[6]中明确地回答: “1、如何决定一板中每个音的长短?有没有简捷的口诀可以很快学会?回答是: 没有.只能结合民间音乐实际学习工尺谱才能学会.2、每个音的长短可否由应用者自由决定?回答是: 不能.因为在同一曲调中,在这些细微节奏的处理上,在民间实际流行的唱法中,一般来说是比较固定的.而且在各个流派之间,大体上是一致的.”由此可见,中外学者有关传统音乐中的即兴部分的观点是一致的.具体到工尺谱节奏翻译问题上,关于同一拍内音符时值的分配,虽然工尺谱没有公式化的规则,但是演奏者不能完全随机决定,而需要通过一定的演奏经验来进行合理的即兴.这种经验通常需要通过长时间的口传心授,并结合大量的演唱经验才能获得,这对本来就相对小众的中国传统音乐来说,更加让学习者望而却步.通过将工尺谱翻译成在节奏上更加精确的简谱或者五线谱,结果并不唯一但却可以做到合理,这将会给工尺谱的学习者带来极大的便利.
本文便是希望基于现有的译本,在统计模型中将凝结在译本中演奏者的经验通过数据的方式,部分地转换成可重复使用并且可不断更新的计算模型.此工作旨在为工尺谱的合理翻译提供一种计算机的角度,而非完全代替人工翻译.
2 工尺谱的符号系统
关于工尺谱的符号系统,国内的学者[6-8]已经进行了多年的研究并对其规则与内涵进行了大量总结.本文不讨论工尺谱中关于演奏法的符号(例如字腔与润腔符号),仅就与工尺谱翻译成简谱或五线谱关系最密切的音高与节拍符号做以下简要介绍.
2.1 音高符号
近代工尺谱是首调唱名体系,谱字(即音符)之间只有音程关系,当明确调高后,才能确定谱字的实际音高.
工尺谱的音高由10个汉字来表示.它们是: 合、四、一、上、尺、工、凡、六、五、乙.音程关系相当于sol、la、si、do、re、mi、fa(或升Fa)、sol、la、si.“六”是“合”的高八度,“五”是“四”的高八度,“乙”是“一”的高八度.这10个谱字实际为一个七声音节扩展了3个自然音级.若将“上”作为“宫”(c1),它的音域为g-b1.当超过这个音域时,采用如下的辅助记号来扩展工尺谱的音域.
1) 将字音提高八度的写法 在谱字的左旁添加单人旁“亻”,表示该字升高八度如“上”字的高八度写做“仩”.在字音旁边添加双人旁表示该字升高两个八度.也有采用在字音书写的末笔添加一个“挑”表示该字升高八度,添加两个“挑”表示把字升高两个八度的记法.
2) 将字音降低八度的写法 在谱字书写的最末笔法后添加一个“撇”,表示该字降低一个八度,添加两个“撇”表示该字降低两个八度.
工尺谱与简谱一样,谱字只决定相对的音高,其绝对的音高需要通过“上”字所在的律位(实际声音频率,中国古代以黄钟、太吕、太簇等称谓)表示音的高度,现代通用的音乐理论采用十二平均律中的A、bB、B、C等固定音高来表示12个音律的位置.中国古代所使用的律制是五度相生律和纯律,与十二平均律比较起来频率有细微的差异,但这里为了阐述方便,我们依然使用十二平均律的音高标记作为调名的对照.工尺谱的调高与笛、箫一类管乐器密切相关.这类管乐器有6个孔位,连同筒音共为7声,因此在转调时最多产生7调.工尺谱的命调方法一般以“工”字作为命调的关键音.以工字调(即D调)作为“正调”,其他6种调名都按照工字调的某字来命名.即工字调的某字作为新调的工字,则某字即为新调的命名.比如工字调的“上”字作为新调的“工”字,则新调就称为“上字调”,余者类推,如表1所示.
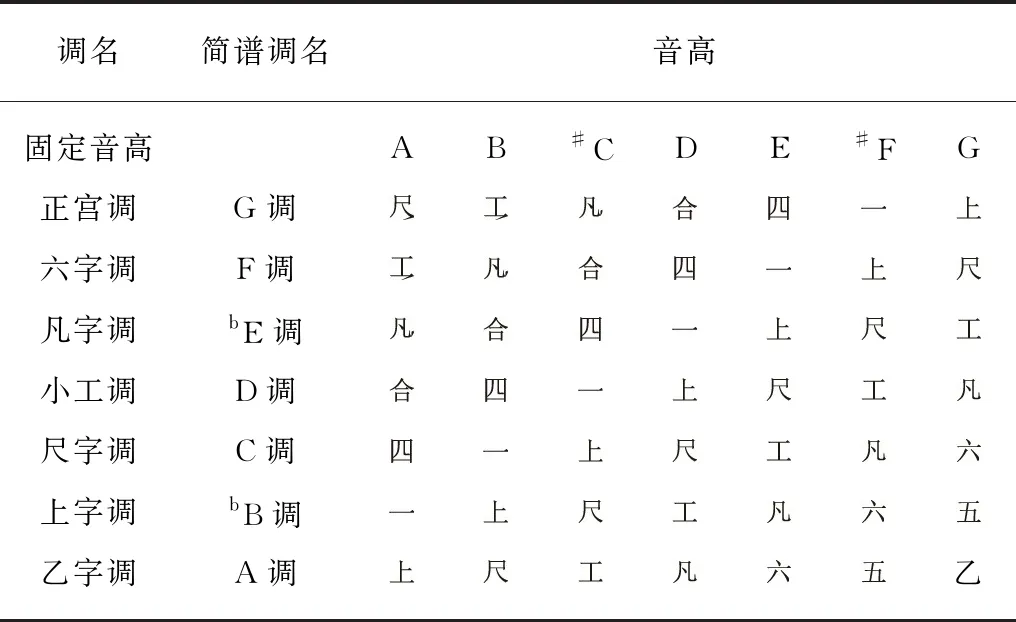
表1 工尺谱音高对应表

表2 工尺谱的板眼符号
2.2 节拍符号
工尺谱中表示节拍的符号主要是“板”、“眼”两种记号.音乐的节奏时值需要以“拍”作为衡量单位,一板与一眼都表示为一拍的时值量.板的符号用“、”或者“×”表示,记写在谱字右上角.眼用“。”或者“.”表示,具体如表2所示.
“板”原来是中国的打击乐器,用击板来统一多种乐器合奏或人声合乐时的节拍.工尺谱中的“板”就是表示乐曲进行中的相对单位拍值,用“板”位来明确谱字的组合.根据不同数量的板眼组合成的不同的循环样式,即板式,也就是我们今天所说的节拍形式.例如每一个循环中由一板一眼构成相当于2/4拍的节奏,而一板三眼则构成4/4拍的节奏.至于板和眼是否相当于西方音乐中的强拍和弱拍,学者之间有不同的看法,这里我们姑且只将其作为表示节拍循环的符号,而不讨论其强弱.从表2中我们可以看出板与眼具有“实”与“腰”之分,其区别是: 实板/实眼落在一个音符的开头,而腰板/腰眼则落在一个音的中间部分.
2.3 工尺谱节奏翻译步骤
音乐学上的前辈们对人工翻译工尺谱已经有多年的研究,其中许莉莉[9]总结了工尺谱节奏翻译方面的5个步骤: 添腰、分拍、断节、转写和整理.
1) 添腰
由于腰板/眼的位置发生在音符的中间部分,这说明该音符是在上一个拍子上已经开始,因此对于腰板/腰眼,我们需要在前一拍上加上腰板/腰眼的音符.例如“上、工△”我们应该翻译成“上、工(工).”
2) 分拍
在添腰的基础上,以一板或一眼所覆盖的范围为单位,划分拍子.
3) 断节
根据乐曲的板式(例如是一板一眼还是一板三眼),以一个循环为小节单位,划分小节,并用竖线隔开.
4) 转写
将工尺谱中的谱字一一转写成对应的简谱数字.
5) 整理
为每一拍中的音符分配时值.
前4步工作可以看作是机械工作,其转换规则是显式的.而第5步——整理这一步骤,需要根据上下文关系,结合演唱者的经验来决定.本文中的统计模型,便是专门针对此问题,将前人的翻译经验作为一种数据来对模型的参数进行估计,从而得到一种相对合理的节拍时值计算方法.
3 工尺谱自动翻译的时间序列模型

3.1 序列模型中的“抑扬值”

图1 工尺谱节奏翻译的序列模型Fig.1 Sequence model for Gongchepu interpretation
与文献[10]中的序列模型类似,我们用序列{Rn}表示一段乐中每一拍的节奏型,{Bn}表示每一拍数据的特征,例如一拍内的音高序列、歌词序列,歌词的平仄等.{Rn}与{Bn}的依赖关系由图1决定.
为了能体现{Rn}与{Bn}之间的数量关系,我们需要对它们进行量化.假设第n拍具有m个音符,我们为这一拍节奏型定义如下节拍“抑扬值”{Rn}:
Rn=第一个m分点所在音符时值/音符的平均时值.
(1)

对于每一拍的特征值{Bn},我们主要采用被文献[10]所验证的歌词平仄序列,并同样在一拍内定义以下平仄“抑扬值”:

图2 平仄抑扬值计算示例Fig.2 Example for Yiyang values computing
(2)
其中的平仄修正值取决于第一个歌词的声调,平声为1,上声为1.5,去声与入声为0.5.例如在图2的工尺谱中,歌词“秦楼”两个字在同一拍,歌词字数为2,其中第一个字“秦”占1个音符且为平声,因此平仄修正值为1,而“楼”字占2个音符,因此总音符数为3,于是得到的平仄“抑扬值”为(3×1)/(1×2)=1.5.平仄的抑扬值根据音符在歌词上的分布,配合平仄修正值在一定程度上描述了歌词的读音时值的左偏程度,与节拍“抑扬值”一一对应.
3.2 基于“抑扬值”的时间序列模型
定义了节拍与平仄的“抑扬值”后,我们便可以根据图1的序列模型建立如下的时间序列模型:
Rt=β0+β1Rt-1+αBt+et.
(3)
这是一个带自回归项的线性回归模型,其中α,β0,β1为待定的回归系数,et为期望为0的正态分布变量,其方差为:
(4)
该模型可以通过最小二乘法求得回归系数α,β0,β1的估计值.获得回归系数后,我们就可以得到以下的预测方程:
(5)
根据以上基于“抑扬值”的时间序列模型,我们可以从平仄抑扬值序列{Bn}预测出节拍抑扬值序列{Rn},前者可以直接从工尺谱的数据中计算得出,后者可以推算出每一拍的节奏型.因此,一旦求解出模型(3)的回归系数,自动翻译模型便自动完成.
4 工尺谱自动翻译的实验结果与分析
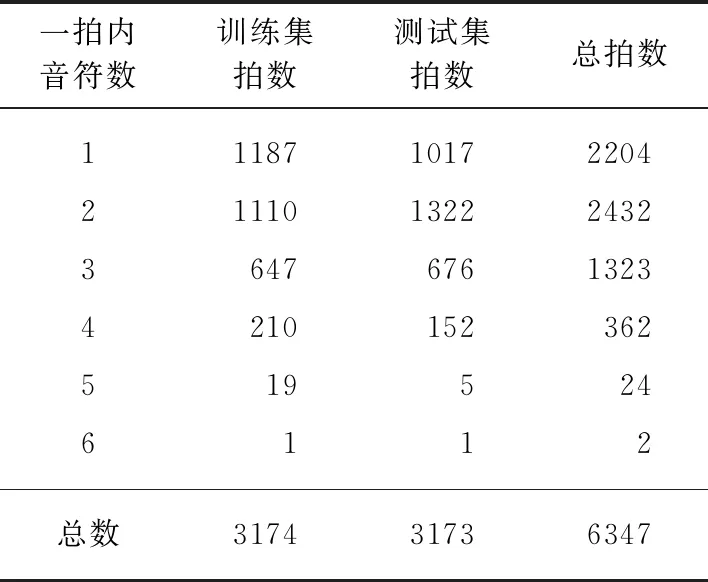
表3 《请君试唱前朝曲》的工尺谱数据集
在实验中,我们的工尺谱翻译数据来自钱仁康先生所著的《请君试唱前朝曲》[11].该书翻译了《碎金词谱》[12]中的96首曲谱,大部分为唐宋以来的著名古词.我们选择了其中的60首具备板眼符号的曲目作为时间序列模型的训练与测试数据.目前该数据使用人工录入的方式,并存储在MySQL数据库.该数据库包含了969个乐句,6347个拍子.我们将整个数据集随机分成两组(在同一乐句的拍子分在同一组),分别用于训练与测试.其中训练集的拍子数为3174拍,测试集的拍子数为3173拍,不同音符数的拍子数量统计见表3.
我们使用Python的scikit-learn模块实现了3.2节中式(3)的自回归时间序列模型.实验中,式(3)的模型中的系数估计以及自回归分析中的R值和p值见表4,数据表明该模型能够通过90%置信度的假设检验.
同时,作为比较,我们同样用Python的scikit-learn模块实现了文献[10]所使用的隐马尔可夫模型和条件随机场模型.这3种模型的正确率,结果见表5.由于隐马尔可夫模型和条件随机场模型是基于标注的模型,因此会出现训练集以外的标注,因此将正确率分为标准正确率(不计算训练集以外的标注)以及OOV正确率(即把标注以外的数据也进行统计)2种.
可以看出本文的时间序列模型的标准正确率为88.25%,略高于隐马尔可夫模型,而略低于条件随机场模型.但是时间序列模型的优势在于不会出现OOV情况,也即时间序列可以预测出每一拍的“抑扬值”,而一拍的“抑扬值”一旦确定,则该拍的节奏型也就完全确定.因此使用时间序列一定能保证翻译的结果中每一拍都有确定的节奏型,不会出现结果在训练集中没有标注而无法确定其节奏型的情况.因此时间序列模型在计算标准正确率时,是按照其他两个模型在计算OOV正确率时的标准,将所有测试数据统计在内计算出的正确率.如果按照实际应用的标准,考虑在小数据集上进行训练时,训练集中的标注不可能足够全面,一定会出现OOV的情况.此时,时间序列模型依然能保持88.25%的正确率,高于隐马尔可夫模型以及条件随机场模型.

表4 自回归时间序列模型的参数估计及结果
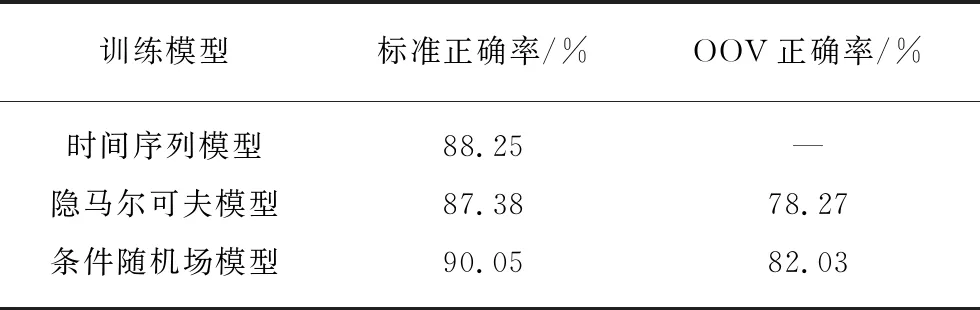
表5 工尺谱自动翻译正确率
此外,由于时间序列模型是一种参数模型,反映的是同一拍子内的节奏型与歌词平仄的数量关系.这种关系揭示的是一种乐理关系,是可解释的,而非序列标注模型中的概率转移关系.因此时间序列的模型在小数据集上的训练结果,应该比隐马尔可夫模型以及条件随机场模型这类模型在理论上具备更好的稳定性,并且可以减少过拟合的情况,尽管这种猜测依然需要在更大的数据集上进行验证.
虽然本实验所采用的数据集规模比较小,即便达到接近90%的翻译正确率,也不能说明在更大规模的工尺谱数据中,其翻译能保持合理.然而由于现存的工尺谱的简谱或五线谱版本数量实在太少,我们无法用计算的方式在更大规模的实验中检验其翻译的合理性.虽然各地的京昆社都有不少翻译的样本,但翻译的作者无从考证,更多是集体翻译的结果.在类似的片段,不同人翻译的数据有可能互相矛盾,不符合本文的假设,因此难以使用.此后我们将从乐谱数据以外,从实际演唱的语音记录中进行自动的节奏识别,从而扩大数据库.
另一种可行的对翻译结果的检验方法是利用自动翻译模型,将更多不为人知的中国传统音乐的工尺谱翻译成可以用于乐队演奏的简谱五线谱版本,并呈现给广大观众,让大众来进行评价.2012年,中央音乐学院作曲家李博禅先生所创作的《古风变奏曲》中的琵琶齐奏段落,便是取材自本文的自动翻译模型所翻译的晏殊的《浣溪沙》片段.该曲子由北京大学中乐学社在英国爱丁堡国际音乐节上演出(https:∥www.youtube.com/watch?v=g-4p6o7Rh8Y),在各种媒体报道中获得了一致好评.
5 总结与展望
本文提出了一种基于时间序列模型的工尺谱自动翻译模型.模型中,在前人的研究基础上,我们提出了节拍“抑扬值”与歌词平仄“抑扬值”的概念,并给出了具体计算公式.借助该计算公式,对工尺谱中每一拍的节奏型和歌词的平仄进行了量化,并由此建立了该时间序列的带差分项的线性自回归模型.相比隐马尔可夫模型和条件随机场模型这类基于序列标记的非参数模型,本文的模型在解决了OOV问题的基础上依然能够达到较高的正确率(88.25%),并可以期望在更大的数据集上保持其稳定性.
本文的研究虽然无法代替需要通过漫长的时间进行口传心授与演出实践所积累的人工解读工尺谱的经验,却在一定程度上将这种人的经验,通过数据的形式转换为可重复使用并且不断更新的计算模型.通过自动翻译模型,我们将有可能将无法用文字语言传达的有关中国传统音乐实践中的经验记录并传承下去.
