音乐信号稀疏分析方法研究
2018-07-26徐忠亮李海峰
丰 上,徐忠亮,马 琳,李海峰
(哈尔滨工业大学 计算机科学与技术学院,哈尔滨 150001)
稀疏分解作为一种目前相对比较成熟的信号压缩存储、传输及成分解析的手段,一直以来都受到学界的广泛关注,并已获得了长足的发展[1].这一方法通过构建过完备稀疏字典可以把信号分解为字典原子与稀疏系数构成的线性组合方程,实现信号高精度的压缩存储、传输;同时,对由学习过程得到的非确定基字典而言,其字典原子可以视作由训练样本集得出的特征集合,而稀疏系数则可以视为这些特征的强度系数,由此即可进行对信号内在结构和本质属性的鉴别和分析.在各类信号之中,音乐信号的结构相对固定、特征比较显著、噪声成分与信号本征成分特征差异明显,尤其适合利用稀疏化分析方法进行分析与识别;同时,借由低信息量泄露的分解算法,可以对音乐信号进行精确可靠的定量分析,这对音乐相关领域的研究也具有重要的意义和价值.
对稀疏分解字典的学习,目前有若干种有效算法,如最优方向法(Method of Optimal Direction, MOD)[2]、K-SVD算法(K-means Singular Value Decomposition)[3]及在线字典学习(Online Dictionary Learning Algorithm)[4]等.使用字典对语音信号进行稀疏建模可得到每个信号对应的稀疏分解系数矩阵,作为原始数据的压缩表征.稀疏建模算法主要分为两类: 凸松弛法和贪婪法.凸松弛法中最有代表性的是基追踪(Basis Pursuit, BP)算法[5].贪婪法中比较常用的是匹配追踪(Matching Pursuit,MP)算法[1]和正交匹配追踪(Orthogonal Matching Pursuit, OMP)算法[6].
在信号处理及分析领域,稀疏分解算法一直受到广泛关注和应用.如Jafari等提出了一种运用稀疏字典实现立体声音信号识别的算法[7],董丽梦等利用稀疏表示分类器对音乐中和弦进行识别[8],Panagakis等将稀疏表示技术与时间调制结合,用于音乐体裁的分类[9],都达成了较好的识别效果;此外,Plumbley等还用稀疏编码实现了复调音乐的转录[10],Cogliati等也用快速卷积稀疏编码完成了钢琴音乐的转录[11],等等.以上这些工作涵盖音乐和弦、体裁、乐器分类以及其他调制分析方法,充分说明了稀疏分解在音乐信号解析领域的有效性.
目前稀疏分解问题的求解对象包括l0,l1及l2范式,其中求解l0范数是稀疏分解的根本问题,但对其直接求解非常困难;在近似求解模型中,使用l2范式求解会导致重构系数矩阵中系数绝对值小而数量众多,若将该矩阵应用于特征提取和分析领域,将会消耗大量不必要的计算;l1范式的使用最为广泛,但其分解得到的重构系数矩阵中仍存在一定的系数均一化情况,对特征提取和分析仍然存在一定影响.
因此,为了实现音乐信号的高区分度特征提取及精密分析,有必要对对稀疏分解重构矩阵的系数分布情况进行研究,以此作为现有求解范式及分析方法的补充.另外,作为近似求解方法,基于l1及l2范式的求解模型难以避免地会产生相当程度的误差,会对分析结果产生影响;为了精确地评估这种偏差的程度,也有必要对音乐信号的稀疏质量进行研究.在本文中,我们尝试将一类稀疏质量评价指标应用于音乐信号的分析之中,并评估该指标与稀疏分解重构误差(模型精度)的相关性,并进一步尝试探讨将该指标应用于音乐分析与识别的可能性.
1 稀疏分解基本原理
信号的稀疏建模即是通过一个N×k维的字典矩阵D=[d1|d2|…|dk]∈N×k中的原子dk进行线性组合,对信号y∈N进行表示的过程,其中k为字典维数,N为信号长度,如式(1)所示:
y=Dα+e,
(1)
式中:e∈N为模型的逼近误差,‖e‖≪‖y‖.1×k维稀疏系数向量α中只有很少的非零值,即‖α‖0≪K.信号的稀疏建模问题就是对以下问题求解:
(2)
或
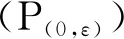
(3)
式中: ‖·‖0表示l0范数;ε为误差限制;(P(0,ε))和(P0)表示包含或不包含误差限制的l0稀疏建模问题.字典学习的过程是对一组训练信号Y={yi|i=1,2,…,M},寻找字典D,基于该字典求解问题(P0)或(P(0,ε)),可以对每一个训练信号yi建模,得到对应的稀疏模型ai.
在实际应用中,字典D可以是确定基字典,也可以是非确定基字典.确定基字典的原子的形态事先已知,很难与较复杂的音频信号的特征完全匹配,重构效果相对较差.非确定基字典由目标信号集训练得出,可以对任意类别音乐信号进行针对性的特征提取,从而实现更精确的重构.通常来说,这一类字典的学习和训练都是在特定的约束下,通过最小化目标函数完成的.由于求解l0范数是一个NP难问题,所以常使用l1范数作为l0范数的近似.用l1范数代替l0范数作为约束条件的稀疏字典求解目标函数可以表述如下:
(4)
式中:D表示稀疏字典;αi,yi分别表示第i个训练样本的稀疏重构矩阵及该样本本身;λ为罚函数的修正系数.在优化求解过程中,一般需要在确保l1范数不大于事先设定阈值τ的限制下,对稀疏字典D及稀疏模型{ai}进行迭代更新.迭代过程分为两个步骤,即在稀疏模型{ai}及训练集{yi}确定的情况下更新字典D,而后在稀疏字典D与训练集{yi}确定的情况下更新稀疏模型{ai},同时保证‖αi‖1≤τ.
当{ai}及{yi}确定:
(5)
当D及{yi}确定:
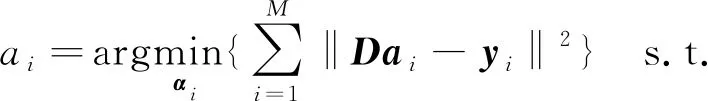
(6)
2 音乐稀疏化分析方法研究
2.1 音乐稀疏化分析基本思想
与其他类别信号类似,对音乐信号进行稀疏化分析需要首先对其进行稀疏分解.首先将信息量充分(包含待分析样本集中所有特征的小规模训练集),以此训练得到稀疏分解字典,而后使用最小绝对值收敛和选择算子(Least Absolute Shrinkage and Selection Operator, LASSO)、OMP等算法对所有待分析样本进行稀疏建模,将得到的稀疏系数矩阵作为提取后的特征.在某些稀疏分解算法如K-SVD算法中,这两步是同时进行的.在特征提取完成后,可以使用聚类、支持向量机(Support Vector Machine, SVM)、深度神经网络(Deep Neural Network, DNN)等具体分类方法和训练样本的标记对分类模型进行训练,完成最终的分类识别模型.
值得注意的是,使用可靠的分解算法对音乐信号进行稀疏分解后,其稀疏系数矩阵中的系数分布情况根据音频性质会出现很大的差异.其中,样本重构系数矩阵中非零值越少、能量的集中程度越高(有效原子的绝对值越大),表示重构矩阵的稀疏质量越好、重构中使用的字典原子(音乐基础特征)越接近样本的本征特征.这种分布情况本身既可作为待识别样本的一类特征,参与到后续的分析及识别工作中;另外,这种分布情况也跟稀疏分解的复原误差存在很高的相关性,这一点我们将在后文的实验中进行详细证明.
为了将这种分布情况纳入实际的分析识别工作中,需要对其进行准确、快速的分析和度量,接下来,我们将详细介绍由稀疏分解后的重构系数矩阵(特征矩阵)出发,度量样本当前稀疏性能特征的方法.
2.2 系数矩阵的稀疏性能评价
对稀疏性能矩阵进行稀疏性能度量需要考虑以下几个因素: 首先,最关键的因素就是矩阵中非零元素的个数,这一指标在稀疏问题中受到最多关注、同时也易于评价;其次,另一个同样重要的因素就是样本中主要成分(绝对值较大的重构系数)相对于其他成分的强度,这个因素对稀疏性能的影响同样重大,但受到关注相对较少;此外,数据的偏移程度(绝对值的差异)还会受到原始信号能量(也即音乐音量)的影响.故为了准确地评价稀疏系数矩阵内元素的偏移程度(即稀疏性能),必须消除信号的l1范数或能量的影响.
基于以上评价准则,本文使用所有元素间差的累加和作为基础,使用如下稀疏性能统计指标SPS(Sparse Performance Statistics)统计系数矩阵αi的稀疏性能:
(7)
式中:αij,αik表示重构系数向量αi的第j,k个元素.易知SPS(αi)>0.
该统计指标的物理意义即是在除去待重构样本音量的影响之后,稀疏系数的相对偏移程度.该指标的值越大就表示稀疏系数相对偏移量越大,即系数的分布情况倾向于只有极少数绝对值较大的系数;在这种情况下,重构误差能量一般也较小.然而,传统方法使用l1范数求解模型(4),该模型要求最小化目标函数.因SPS(αi)>0,且SPS(αi)越大,稀疏性能越好,故SPS(αi)指标的优化方向与字典求解模型的优化方向是相反的.为了将二者统一起来,我们实际应用的重构系数矩阵的稀疏性能评价指标SPI(Sparse Performance Index)可以表示为:
(8)
由SPI(αi)的定义方式可知,同样的稀疏建模算法和稀疏度限制下,较小的SPI(αi)说明待重构信号可以被更少的字典原子线性表示,意味着字典对αi对应的训练样本完备程度较好;而对若干个不同的字典,同一样本yi对应SPI(αi)更小的字典也可以更好地匹配yi的固有特征.在实际应用中,只需计算所有样本重构矩阵对应的SPI并将其排序,重构矩阵SPI指标较大的即是稀疏性能较差的样本.该指标只需读取稀疏分解系数矩阵即可计算,与稀疏字典无关,实际操作起来也较简便.
接下来,我们将通过实验验证该指标与音乐样本信号重构误差的关系,并探讨其与音乐本质特征的相关性.
3 实验与结果分析
为了令实验结果精确可靠,我们首先选取K-SVD算法训练稀疏字典,对音乐样本进行分析.样本分为两组: 第一组包含两首乐曲,来自两类不同音乐体裁(肖邦夜曲第20号及贝多芬第五交响曲“命运”),验证本文方法对音乐类别进行分类的效果;第二组包含4首小提琴独奏曲,验证本方法对统一类型不同内容的音乐进行鉴别的效果.选取音乐信息见表1.

表1 实验选取的音乐信息
在训练稀疏字典时,参数如下: 音乐数据先分为长度为256采样点的帧,帧间交叠为128点.字典维数为256维,样本重构稀疏度限制为非零元素小于等于50,使用K-SVD算法迭代10轮,并对其进行统计分析.实验参数的设计综合考虑了稀疏性和计算复杂度两方面,帧长影响了字典原子数和帧数,而过高的帧长会导致字典原子数的大量增长,降低帧数会导致字典训练不足,无法获得稀疏的系数矩阵,进而影响SPI的参考价值.
3.1 第一组音乐实验结果
首先,使用肖邦夜曲第20号(升C小调)作为训练集,共得到93238个分析样例,对其根据SPI指标进行排序后结果如图1所示.

图1 1号音乐样本分析试验结果Fig.1 Experiment results of music sample No.1
从实验结果中可以看出,该指标在音乐分析结果中与重构误差存在高度的相关性,即该指标可以相当精确地度量样本实际稀疏情况和复原效果.
接下来,作为比较,我们将贝多芬C小调第5号交响曲“命运”作为不同类别的样本,同样分为长度为256采样点的帧,帧间交叠128采样点,得到151536个分析样本,使用同一稀疏字典进行稀疏建模,对其SPI指标排序后结果如图2所示.

图2 2号音乐样本分析实验结果Fig.2 Experiment results of music sample No.2
由实验结果可见,“命运”交响曲与肖邦夜曲的整体趋势皆相同,但由于两者调式和体裁的不同,其SPI分布及对应的误差能量分布都存在着较大的差异.
3.2 第二组音乐实验结果
图3所示为第二组音乐的分析试验结果.图中(a),(b),(c),(d)分别对应第二组乐曲的各个乐曲;第一列为SPI的时变曲线,第二列为排序后的相对误差分布,第三列为相对误差趋势.
从第二组的结果来看,利用本文的方法可以较好地展示同一种乐器在演奏不同乐曲时的时域特征,从而提供了较好的区分度.同时利用相对误差分布,可以发现乐器演奏不同乐曲的共同特征,可以用于乐器的识别应用中.
由此可见,SPI指标不仅与单一样本的稀疏性能、重构精度存在很高的相关性,同时其分布也可以用来度量不同类别的音乐调式和体裁,对基于稀疏分解的音乐类别分析具有显著的参考价值.
4 结 语
本文面向音乐的稀疏化分析,介绍了使用稀疏分解思想进行音乐类别鉴别分析的具体思路,并给出了将稀疏系数分布情况进行精确统计并纳入音乐类型识别体系中的方法,且通过实验验证了我们给出的指标与音乐样本本身稀疏分布情况及重构精度的关系,探讨了使用这类指标进行音乐体裁和调式分别的可能性.若能对该指标与音乐体裁、调式的内在关联进行进一步的探讨和研究,这一指标将可以成为音乐类型分析工作的一个有力参照和依据.


图3 第二组音乐的分析试验结果Fig.3 Experiment results of music sample group 2
