基于本体和语义距离的DBpedia领域知识抽取方法
2018-07-10张志申王会勇张晓明艾青孟明明
张志申 王会勇 张晓明 艾青 孟明明


摘 要: 关联开放数据(LOD)中蕴藏着大量不同领域的知识,但是目前抽取其中特定领域知识的方法大多需要人工参与。为了能自动地抽取领域知识,提出根据领域本体抽取DBpedia中特定领域知识的方法。使用领域本体、Wikipedia和主题提取算法获得用于抽取领域知识的种子关键词集。在直接链接子图语义距离算法中,添加能够代表边指向性权值的参数,用于领域知识的抽取,并基于本体和字符串相似度比较的筛选策略对抽取的知识进行筛选。通过实验表明,该方法不仅能够获得较好的抽取效果,而且不需要人为地挑选关键词和参与筛选过程,极大地节省了时间和精力。
关键词: DBpedia; 领域本体; 直接链接子图语义距离算法; 知识抽取; 抽取策略; 筛选
中图分类号: TN911.1?34; TP391 文献标识码: A 文章编号: 1004?373X(2018)13?0128?05
Abstract: The linked open data (LOD) contains huge amounts of different domain knowledge, and most of the approaches to extract the specific domain knowledge require manual intervention. A method of extracting domain specific knowledge from DBpedia based on domain ontology is proposed to extract the domain knowledge automatically. The domain ontology, Wikipedia and topic extraction algorithm are used to obtain the seed keyword set for domain knowledge extraction. The parameter representing the side?directivity weight is added into the direct linked subgraph semantic distance algorithm to extract the domain knowledge. The screening scheme based on ontology and character string similarity comparison is used to screen the extracted knowledge. The experiment results show that the proposed method can obtain perfect extraction performance, and needn′t select keywords or perform manual participation in the screening process artificially, which can greatly save people′s time and effort.
Keywords: DBpedia; domain ontology; direct linked subgraph semantic distance algorithm; knowledge extraction; extraction scheme; screening
0 引 言
隨着科技的发展,关联开放数据(LOD)中的数据呈爆炸式增长,如DBpedia[1],Yago[2]等。这为语义网领域提供了大量可用数据,并且推动了本体技术的快速发展。但是正因为LOD中数据的不断增加,这在为使用者提供强大数据来源的同时,也使得从中抽取特定领域数据变得困难。目前,针对从LOD中抽取领域数据的方式[3?4]大多相似,基本采用人工指定关键词或者人为筛选关键词作为抽取LOD知识的入口,并设计抽取策略或算法对LOD中的特定领域知识进行抽取。但是这些抽取领域知识的方式容易受到关键词的影响,人为指定的关键词直接决定了该抽取策略的最后结果。并且使用者不仅需要对该领域知识有一定的了解,而且还需要进行多次实验来确定关键词集,从而耗费大量的时间和精力。同时,随着本体技术的高速发展,各个领域的本体也迅速出现,如金属材料领域的STSM[5],睡眠医学领域的SDO[6]等。由于领域本体中基本都包含着相应领域的大部分知识,所以本文根据领域本体提取用于抽取领域知识的种子关键词集。
本文提出根据领域本体提取DBpedia中特定领域知识的方法。该方法首先采用LDA算法[7?8],同时结合领域本体和Wikipedia[9]获得领域本体的种子关键词集;然后对直接链接子图语义距离算法[3,10](DLSSD)添加边指向性的权值参数,使用种子关键词集和该算法抽取DBpedia中的领域知识,并使用SMOA[11]和最大公共子串算法[12](LCS)结合当前领域本体进行筛选;最后得到特定领域知识。本文以STSM抽取DBpedia中金属材料领域知识为例。通过实验表明,该方法不仅能获得相对有效的种子关键词集和DBpedia中特定的领域知识,而且不需要领域专家的介入,极大地减少了人为工作量。
1 根据领域本体获得种子关键词集
在领域本体中,schema层基本囊括了该领域的知识,但是领域本体中也存在着不属于该领域的数据,只是与领域本体中部分数据存在关联,如STSM中的author等。
为了能够根据领域本体获得可以代表该领域的种子关键词集,本文利用LDA算法提取领域本体schema层,获得候选关键词集,并结合Wikipedia和LDA进行扩展。然后利用余弦相似度算法结合本体的schema层进行相似度计算,设定阈值进行筛选。重复扩展和筛选的过程直到结果中的关键词集不变为止,即获得能够代表该本体领域性的种子关键词集。例如,使用STSM获得的种子关键词集为{ iron, carbon, steel, metals, metal, alloys,alloy}。以下展示了通过候选关键词获得种子关键词集的算法描述。
算法:getSK (List listck, Model model)
输入:listck //候选关键词集
model //领域本体
输出:listck //获得的种子关键词集
Step:
1 listldaf = createArrayList() //接收初次筛选的关键词
2 listldas = createArrayList() //接收最后筛选的关键词
3 calssset←getClassset(model) //获得领域本体的类名集
4 tostop = true files=null
//用于判停的标识tostop,初始值为true,同时定义文档files
5 While tostop
6 FOR each ck∈listck //遍历listck中的每个关键词
7 destext ← getWebDes(ck)
//获得该关键词在Wikipedia中的文本描述
8 similarity ← getWebDes(destext, calssset)
//获得该文本与类名集的相似度
9 IF similarity >= 0.89
10 files ← write(destext)
11 //将文本描述写入文档listldaf.add(ck)
12 listk← getLDA(files) //使用LDA获得该文档的关键词
13 FOR each k∈listk //遍历listk中的每个关键词
14 kdestext ← getWebDes(k)
//获得该关键词在Wikipedia中的文本描述
15 ksimilarity ← getWebDes(kdestext, calssset)
//获得该文本与类名集的相似度
16 IF ksimilarity >= 0.89
17 listldas.add(k) //将关键词存入listldas
18 IF listck == listldas //如果listck与listldas相等
19 tostop = false //给tostop赋值为false
20 ELSE listck ← listldas
//将listldas中的数据赋值给listck,作为下次循环使用的数据
21 listldaf.clear() listldas.clear()
//清空listldaf和listldas
22 RETURN listck
2 基于语义距离抽取DBpedia中的特定领域知识
DBpedia中的数据保存在多个数据集中,首先获得SKOS_Category数据集中的特定领域概念,然后将获得的概念通过字符串匹配的方式获得其他数据集中的相关知识。本文对DLSSD算法添加能够代表边指向性的权值参数,形成IDLSSD算法,并使用该算法抽取SKOS_Category数据集中的特定领域概念。
2.1 IDLSSD算法
在SKOS_Category数据集中,各个数据之间存在联系,并且是以图的形式存在。为了能够获得SKOS_Category中与领域本体相关的概念,使用DLSSD算法获得特定领域的概念。该算法计算兩个节点的直接链接子图语义距离,当该直接链接子图语义距离值越接近0时,说明这两个节点越相关。该算法再根据人为筛选的关键词和使用Wikipedia中金属材料分类作为背景数据集获取DBpedia金属材料知识,已取得了较好的应用[3]。为了更加充分地体现节点之间的语义关系,以便更加准确地获得相关领域节点,本文向该算法中添加能够代表边指向性的权值参数,添加参数后的DLSSD算法(IDLSSD)如下:
在有向图中,当节点[a]指向节点[b]时,说明节点[a]为节点[b]的子节点。即如果节点[b]为已知金属材料领域的知识,那么节点[a]必然也为金属材料知识;但是如果节点[a]为已知金属材料知识,节点[b]有可能不为金属材料知识。当节点[a]指向节点[b]的同时,节点[b]也存在一条指向节点[a]的线,这基本可以说明,节点[a]和节点[b]为相同或相似概念,即它们的领域性基本相同。例如,在DBpedia中,“Alloys broader Metals”表示“Alloys”指向“Metals”,“Metals”为金属材料领域知识,显然“Alloys”也为金属材料知识。然而对于“Metals broader Crystalline_solids”,“Metals”为金属材料领域知识,但是“Crystalline_solids”表示的是结晶固体,不为金属材料领域知识。所以在计算[a]节点与[b]节点的IDLSSD值时,本文也将表示[a]节点与[b]节点的指向方向性的权值[D]考虑在内,当[a]节点指向[b]节点时,[D]值设为1;当节点[b]指向节点[a]时,[D]值设为2;当[a]节点与[b]节点相互指向时,[D]值设为4。
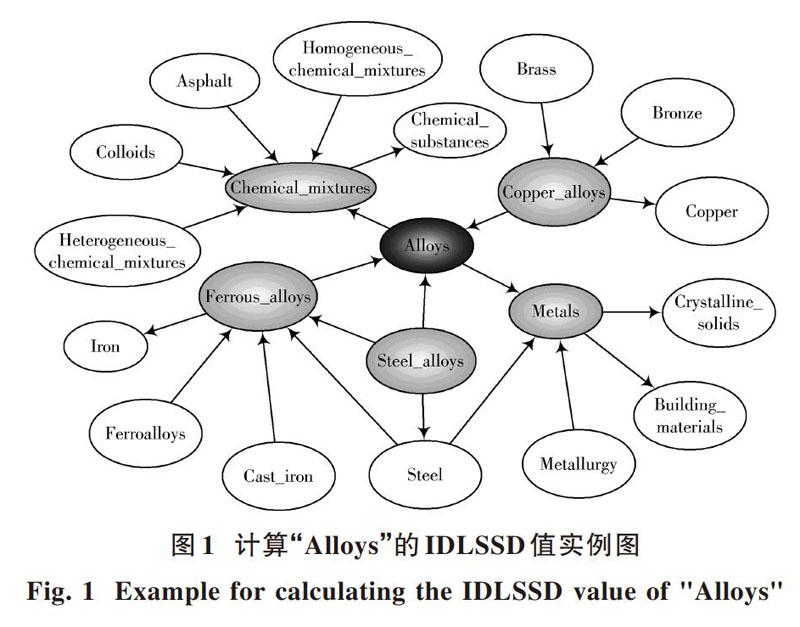
图1展示了DBpedia中“Alloys”周围的部分节点。计算“Alloys”与周围节点的IDLSSD值,通过种子关键词集中的“Alloys”获得其直接链接子图的概念{Chemical_mixtures,Copper_alloys,Metals,Steel_alloys, Ferrous_alloys}。以计算IDLSSD(Alloys, Ferrous_alloys)为例,其中“Alloys”指向“Ferrous_alloys”的边数为0,即[E(a,b)]为0。“Ferrous_alloys”指向“Alloys”的边数为1,即[E(b,a)]为1。其中,“Alloys”的直接链接子图和“Ferrous_alloys”的直接链接子图中都有相同的元素“Steel_alloys”,所以[N(a,b)]为1。并且已知节点“Alloys”被“Ferrous_alloys”指向,所以[D]值为2。即IDLSSD(Alloys, Ferrous_alloys)的值为0.20。
2.2 利用IDLSSD算法抽取DBpedia中的特定领域知识
根据SMOA算法获得种子关键词集在SKOS_Category中的对应概念,将获得的对应概念作为抽取SKOS_Category数据集的入口,使用IDLSSD算法抽取其相关的概念。为了保障抽取到的概念与当前领域本体相关,设定阈值[T1]和[T2]分段进行筛选。当IDLSSD值小于[T1]时,视为与当前领域本体相关的概念;当IDLSSD值在[T1]~[T2]范围内时,使用SMOA和最大公共子串算法(LCS)结合领域本体schema层做进一步筛选。将满足筛选条件的概念再次作为SKOS_Category数据集的入口进行抽取并筛选,一直重复该过程,直到获得满足筛选条件的概念集不再增多为止。最后根据获得概念集利用字符串匹配的方式获得DBpedia其他数据集中的相关知识。
使用SMOA和LCS算法结合当前领域本体进行筛选。将领域本体schema层中的概念作为背景数据集,对已获得SKOS_Category中的概念集分别与背景数据集中的概念使用SMOA进行相似度计算,当最大值大于等于阈值TH1时,视该概念属于金属材料领域;当最大值小于阈值TH1并大于等于阈值TH2时,使用LCS算法判断该概念是否包含背景数据集中的概念,如果包含,那么该概念属于金属材料领域。其他情况都视为该概念不属于金属材料领域。
结合SMOA和LCS的筛选策略如下:
算法: getSMOAandLCS (List listBD, String con, int TH1, int TH2)
输入: listDB //背景数据集
con //需要进行判定的概念名称
TH1 //设定的SMOA的阈值其中偏大的
TH2 //设定的SMOA的阈值其中偏小的
输出: sc //con是否与背景数据集相同领域的标识
Step:
1 sc = false //用于返回的标识sc,初始值为false
2 simimax ← getSMOAMax(con, listBD)
//获得最大相似度值
3 IF simimax >= TH1
//判断最大相似度值是否大于TH1
4 sc = true //將sc的值设置为true
5 ELSE IF simimax < TH1 && simimax >= TH2
//判断最大相似度值是否小于阈值TH1并且大于等于TH2
6 lcs ← judgeLCS(con, listBD)
//判断con是否存在包含背景数据集中的概念
7 IF lcs == true //判断lcs是否为true
8 sc = true //将sc的值设置为true
9 RETURN sc
3 实验评估
3.1 评估IDLSSD算法的阈值[T1]和[T2]
本文将[T1]值设定为0.15,[T2]值设定为0.34。当IDLSSD值小于等于0.15时, IDLSSD算法公式中4个值的总和必须大于等于6。当IDLSSD值在[T1]和[T2]之间时,其公式中4个值的总和须在6和2之间。由于[E(a,b)],[E(b,a)]表示节点之间的连线,[D]表示节点之间指向性的权值,所以[E(a,b)],[E(b,a)],[N(a,b)]和[D]的取值之间存在一定联系。表1展示的是4个值总和为6和2时,各个参数的取值情况。
对于本文,将[T1]值设定为0.15,即将该4个值的总和最小设定为6,因为在SKOS_Category中,节点之间的连线关系都为“broader”,并且当节点a和节点b之间存在相互指向的连线关系(S6_3)时,说明节点a和节点b极为相似或密切关联,所以本文视这两个节点的领域性相同。并且在4个值总和为6时的其他情况(S6_1和S6_2)中,当节点a的直接链接子图和节点b的直接链接子图中相同元素个数大于等于3时,也可以认为这两个节点为相同领域的节点。
对于其他情况,当节点[a]和节点[b]至少存在一条连线关系(S2_1)时,不能肯定地判断节点[b]与节点[a]的领域性是否一致,所以需要对这种情况的节点进行进一步的判定筛选,即将[T2]值设定为0.34。
3.2 评估筛选策略中的阈值TH1和TH2
在对大于等于阈值[T1]并小于阈值[T2]中的节点进行筛选时,本文使用SMOA和LCS算法设计分段筛选策略。为了确定筛选过程中TH1和TH2的选择,从SKOS_Category中选取100个与当前领域本体相关的节点,900个与当前领域本体不相关的节点,分别采用不同的阈值对TH1和TH2进行实验,并使用准确率(P),召回率(R)和F值进行实验评估,实验结果分别如图2和图3所示。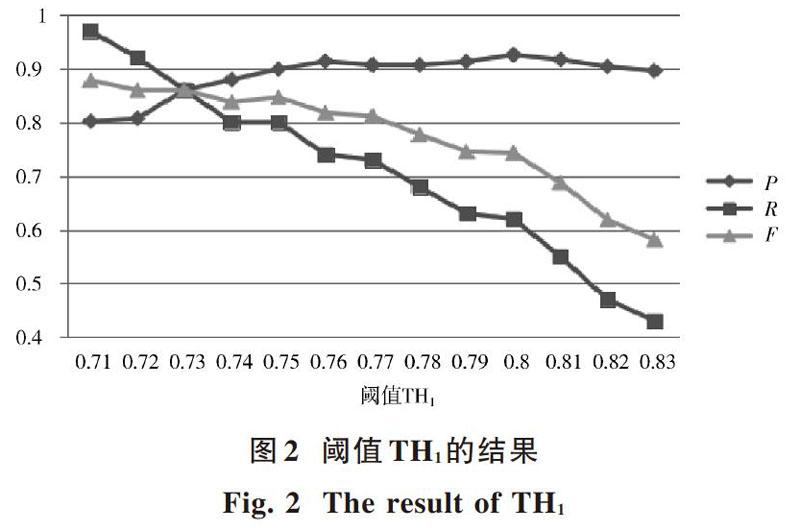
对TH1值的选择,在F值可以接受的范围内主要考虑其准确率,因为这里主要是尽可能多并且准确地获得与当前领域本体相关的节点。对于其余节点,通过LCS算法和TH2进行筛选,以保障F值最高。从图2可以看出,随着阈值TH1的增加,其准确率在不断增长,并在0.76之后基本达到稳定的状态。但是,随着TH1的增加,其召回率一直持续下降,导致其F值也一直呈现下降的趋势。TH1在0.78~0.8准确率出现略微的增长,在0.8时准确率达到最大值,在0.8之后准确率又开始有轻微下降的趋势,并且在TH1为0.8时,其F值还保持在一个可以接受的范围。所以在本文中,TH1值设定为0.8。同时在图3中,当TH2值为0.7时,其F值达到最高,所以选取TH2值为0.7。
3.3 使用不同的金属材料领域本体评估抽取方法
为了说明本文所提抽取方法的适用性,使用不同的金属材料本体提取SKOS_Category数据集中的特定领域概念,如使用AMO本体[13](Ashino创建的材料本体)。并且本文提出的抽取方法也适用于同时根据两个相同领域的本体进行抽取DBpedia中的特定领域知识,如使用STSM和AMO本体。在表2中,展示了分别使用AMO,STSM和同时使用AMO和STSM对SKOS_Category中的概念进行抽取的结果。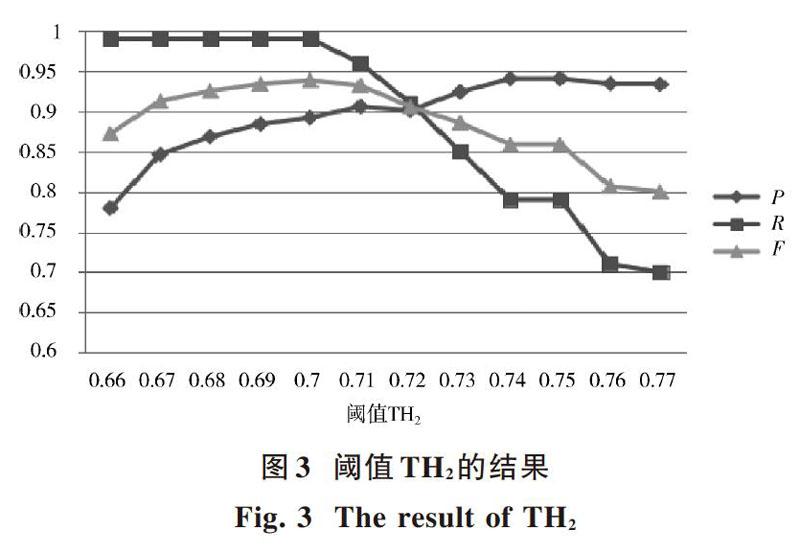
从表2中可以看出,虽然AMO和STSM都为金属材料领域的领域本体,但是由于本体之间的差异,导致抽取出的候选关键词集不同,进而使得种子关键词集也不同。并且作为筛选条件的背景数据集也存在明显的差异,所以最后获得特定领域概念的数量也不同。
并且从表2中可以看出,随着背景数据集中概念的增加,抽取的SKOS_Category中的特定领域概念的数量也在增加。在使用AMO抽取SKOS_Category中的特定领域概念时,背景数据集中概念的数量为63个,共抽取SKOS_Category中的概念200个;使用STSM抽取SKOS_Category中的特定领域概念时,背景数据集中的概念为146个,抽取到SKOS_Category中的概念338个。因此可以发现,随着背景数据集中概念数量的增加,抽取到的SKOS_Category中概念的数量也在明显增加。当使用STSM和AMO同时抽取SKOS_Category中的特定领域概念时,背景数据集中的概念为209个,但是抽取到的概念只有366个,这是因为STSM和AMO同属于金属材料本体。同时,在AMO本体中,“Steel”归为“Alloy”下的子类,并且基本都是与“Alloy”相关的概念名称,关于“Steel”概念的信息很少,这就导致使用AMO本体抽取的领域概念较少。通过上述分析,说明该抽取方法在根据该领域其他本体进行抽取时,也能获得相对满意的效果。
3.4 使用睡眠医学领域本体评估抽取方法
为了评估该抽取方法在其他领域的适用性,本文使用不同于金属材料领域的睡眠医学领域本体SDO[6]抽取SKOS_Category中的领域概念。因为使用的本體领域不同,所以适当地更改抽取方法中的相关阈值。在此次实验中,将使用SMOA和LCS算法进行筛选过程中的TH1设置为0.88,TH2设置为0.82,其他阈值不变。其结果如图4所示。
图4展示了使用SDO本体抽取SKOS_Category中领域概念的结果,一共抽取出156个与该本体相关的概念,图中A区域和B区域展示了其中部分抽取结果。在B区域中展示了与当前SDO本体相同领域的概念,在SDO本体中存在“Sleep function”“Sleep apnea disorder”等关于睡眠的一些概念,通过本文提出的抽取策略可以获得SKOS_Category中相同领域的概念,如“Sleep”“Sleep_disorder”“Sleep_medicine”等。并且利用本文的抽取方法还能够抽取出与当前领域本体SDO相关的领域概念,如A区域展示的“mind”及其相关的概念“Thought”“Brain”等。同时,通过调整TH1和TH2,能够获得不同数量与当前领域本体相关的概念。所以本文提出的抽取策略同样适用于其他领域,并且能够得到较好的结果。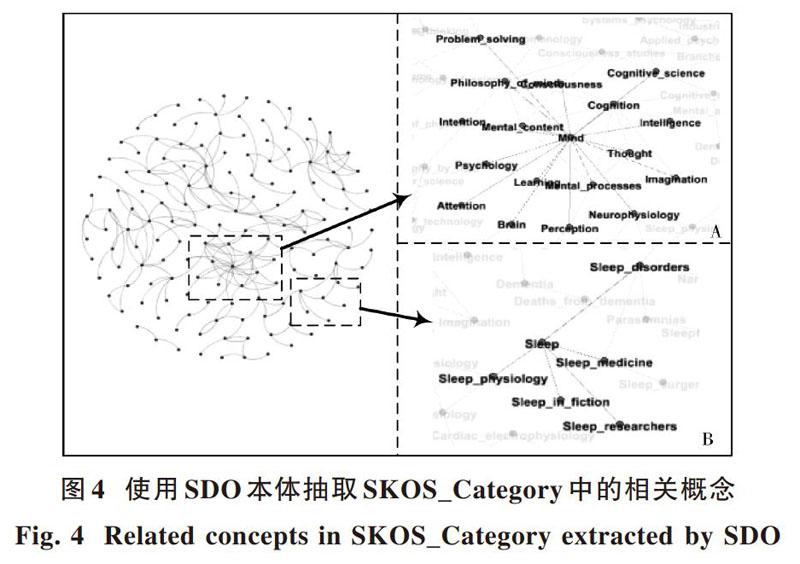
4 结 论
本文提出根据领域本体抽取DBpedia中相应领域知识的方法。该方法利用领域本体,Wikipedia和LDA算法获得种子关键词集,并对种子关键词集利用IDLSSD算法抽取DBpedia中的领域知识,同时结合当前领域本体的schema层,使用SMOA和LCS算法进行筛选。实验结果表明,本文提出的抽取方法能够相对有效地提取DBpedia中的特定领域知识,并且不需要人为参与。此外,该抽取策略在应用于不同领域本体进行抽取时,也能获得较好的结果。所以本文提出的抽取方法可以在获得相对有效的特定领域知识的同时,也能极大地减少人为工作量。然而,该抽取方法只是针对抽取DBpedia中特定领域知识,为了能够比较有效地抽取其他LOD,下一步打算设计更具通用性的抽取方法。
参考文献
[1] LEHMANN J, ISELE R, JAKOB M, et al. DBpedia: a large?scale, multilingual knowledge base extracted from Wikipedia [J]. Semantic Web, 2015, 6(2): 167?195.
[2] BIEGA J, KUZEY E, SUCHANEK F M. Inside YAGO2s: a transparent information extraction architecture [C]// 2013 ACM International Conference on World Wide Web. New York, USA: ACM, 2013: 325?328.
[3] ZHANG X, LIU X, LI X, et al. MMKG: an approach to generate metallic materials knowledge graph based on DBpedia and Wikipedia [J]. Computer physics communications, 2016, 211: 98?112.
[4] ZHANG X, PAN D, ZHAO C, et al. MMOY: towards deriving a metallic materials ontology from Yago [J]. Advanced engineering informatics, 2016, 30(4): 687?702.
[5] ZHANG X, L? P, WANG J. STSM: an infrastructure for unifying steel knowledge and discovering new knowledge [J]. International journal of database theory & application, 2014, 7(6): 175?190.
[6] WHETZEL P L, NOY N F, SHAH N H, et al. Sleep domain ontology [DB/OL]. [2017?04?16]. http://purl.bioontology.org/ontology/SDO.
[7] SANTOSH D T, BABU K S, PRASAD S D V, et al. Opinion mining of online product reviews from traditional LDA topic clusters using feature ontology tree and Sentiwordnet [J]. International journal of education and management, 2016, 6(6): 34?44.
[8] RAMAGE D, HALL D, NALLAPATI R, et al. Labeled LDA: a supervised topic model for credit attribution in multi?labeled corpora [C]// Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: Association for Computational Linguistics, 2009: 248?256.
[9] FREIRE T, LI J. Using Wikipedia to enhance student learning: a case study in economics [J]. Education and information technologies, 2016, 21(5): 1169?1181.
[10] PASSANT A. dbrec: music recommendations using DBpedia [C]// 2010 ISWC. Shanghai: Springer Berlin Heidelberg, 2010: 209?224.
[11] STOILOS G, STAMOU G, KOLLIAS S. A string metric for ontology alignment [J]. Hermochimica acta, 2005, 3729(15): 624?637.
[12] PROZOROV D, YASHINA A. The extended longest common substring algorithm for spoken document retrieval [C]// 2015 International Conference on Application of Information and Communication Technologies. [S.l.]: IEEE, 2015. 88?90.
[13] ASHINO T. Materials ontology: an infrastructure for exchanging materials information and knowledge [J]. Data science journal, 2010, 9(9): 54?61.
