片上网络在多核公钥处理器中的应用研究*
2018-07-09杨瑞瑞
何 涛,杨瑞瑞
(成都三零嘉微电子有限公司,四川 成都 610041)
0 引 言
随着万物互联的信息发展,现有的公钥处理器芯片已无法满足接入认证服务器的性能需求。椭圆曲线密码算法的运算量巨大,造成单核性能的提升空间有限。近年来,提出的片上网络技术可以提供强大的多核互联能力,具有良好的扩展性,非常适用于高速公钥处理器芯片的多核设计。
1 算法特点简述
公钥算法的特点是所需的传输数据量小,但计算时间长。以国家密码局推荐的商秘SM2算法为例,推荐的曲线域宽是256 bit,曲线参数是p、a、b、Gx、Gy、n这六个基本参数。它们一般是在初次分发时就确定下来,除非全系统升级才可能进行更换。因此,片上网络设计时不需考虑曲线参数的传输性能。
在进行签名运算时,所需传递的数据有:随机数k、私钥d、消息杂凑值m,总数据量为256×3=768 bit。考虑到每个数据具有32 bit的标识位,因此总的输入数据量为864 bit,对应的输出数据为签名结果(r,s),共512 bit。
在进行验签运算时,所需传递的输入数据有:公钥坐标(Px,Py)、签名结果(r,s)、消息杂凑值m,总数据量为256×5=768 bit。同样,按每个数据具有32 bit标识位估算,总的输入数据量为1 440 bit。对应的输出数据为签名通过与否的标识,为32 bit。
考虑到实际应用中数字签名验签操作会交替进行,因此数据输入性能需求按最大数据量1 440 bit进行评估。
2 网络性能分析
片上网络中所需运算核的数目和数据路径的性能决定于芯片的整体性能期望。假设芯片上共有M个运算单核,单核的单次签名计算耗时计为Tcalc,则理论上的芯片整体签名性能应为单核的数据输入耗时计为Tin,单核的结果输出耗时计为Tout,考虑芯片仅有一个输入接口和一个输出接口,则多核运行耗时如图1所示。可以看到,数据传输所消耗的Tin和Tout会造成整体性能的损失。
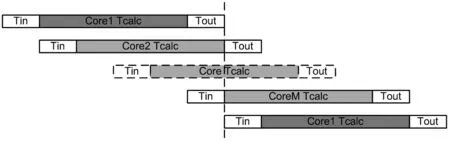
图1 多核运行耗时情况
为了让M个核均达到满负荷工作,需满足条件该条件下,每个
从图1可得,芯片整体的运算性能为单核的当前结果输出后,可紧接着输入下一个运算任务。按进行估算,则得到单核数据传输时间和单核运算性能的关系为Tin≤Tcalc/(M-2)。该公式给出了多核网络满负荷工作对数据传输性能的要求。
结合上述分析,在满足全部运算核满负荷工作所需的最低数据传输速率的前提下,芯片整体性能和单核性能的关系为该公式给出了满足目标性能所需多核数量的计算方法。假设芯片签名的期望性能是30 000次/s,单核的签名性能为1 000次/s,那么单核数目应为32个。
根据公式得到单核数据传输时间不应大于33 μs。单次运算所需数据量为1 440 bit,那么每个运算单核的输入端的数据速率为1 440 bit/33 μs=43 Mb/s。通常来说,芯片具有唯一的输入接口,多个任务数据均依次从该输入接口进入,再分发到每个运算单核,那么芯片输入接口到每个核的传输速率应不低于43 Mb/s。
3 片上网络设计方法
3.1 网络拓扑与路由设计
由于单个运算核的面积较大,网络节点数目多,并有扩展需求,因此选用规整的Mesh结构[1]作为网络拓扑,以最低的布线成本实现多核互连,避免因核数增加而带来的布线拥塞。
Mesh拓扑确定了网络中的路由器具有5个端口——东、南、西、北和本地端,如图2所示。
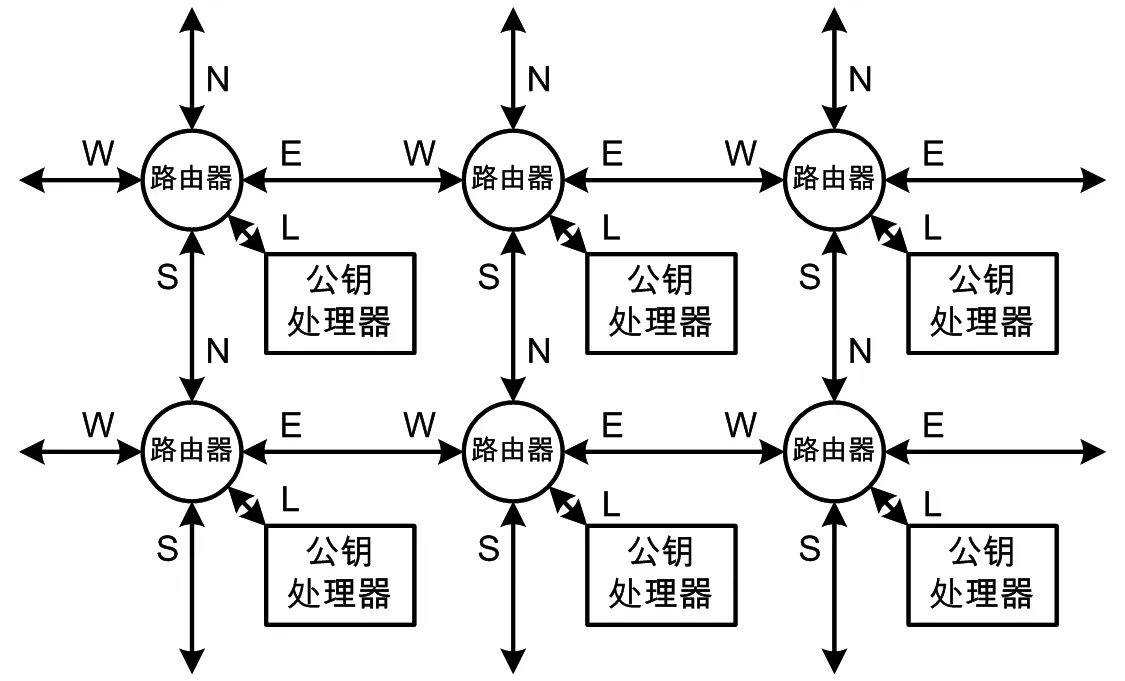
图2 路由器结构
Mesh网络采用维序路由算法,实施方法是:每个路由器用横纵坐标标识自己在网络中的位置,对比自身坐标与数据包目的坐标,其中优先比较横坐标;若不等,则选择横坐标接近目的坐标的方向进行传递;若横坐标相等,再比较纵坐标,若不等则选择纵坐标接近目的坐标的方向进行传递;如果横纵坐标均相等,则将数据包转到本地端口,送至公钥处理器。
3.2 传输链路设计
在数据传输链路设计方面,核心是解决如何让数据从任意源节点传输到任意目标节点,并兼顾逻辑资源的最小化和传输效率的最大化。
如图3所示,数据采用虫洞传输[2]方式,将待传输的数据包进行分片。从源节点到目标节点的传输路径上,每个中间节点仅保存一个分片,以降低节点缓存的开销,极大地节省了面积。但是,当该点到点的传输未完成时,将会持续占用该传输路径上的所有节点。考虑到数据传输耗时与公钥计算耗时相比可忽略,且数据传输量小,因此该方式完全适合公钥计算特点。

图3 数据包分片
片上网络中传输的数据分片分为三种类型:头分片、载荷分片和尾分片。头分片包含目标节点的地址信息,用于路由器选择传输数据的方向,且该方向将会被该数据包独占,直到传输完成。尾分片用于释放在数据传输路径上的所有路由器节点,使得路由器可以为其他数据包服务。
以32 bit的数据分片为例,链路上的每个节点使用寄存器缓存一级32 bit数据即可。考虑相邻的两个网络节点,下游节点需要知道何时有从上游节点传来的新数据,而上游节点也需要知道下游节点有没有将上一笔数据取走。因此,在节点间加入了full信号和new信号。new信号由上游节点驱动,以向下游节点声明是否有新数据;full信号由下游节点驱动,以向上游节点声明是否能锁存新数据。
如图4所示,网络中一个数据包的传输描述如下。初始时,网络中所有节点的new和full均为无效状态;若源节点产生了新数据,那么它将new置为有效;下一个时钟沿,下游节点看到上游节点的new有效,且自身为空状态,那么下游节点将锁存新数据,且在下一个时钟沿将自己的full置为有效,同时上游节点在该时钟沿看到下游节点的full为无效,那么它知道本次数据已经被下游节点锁存,因此在该时钟沿将自己的new置为无效。
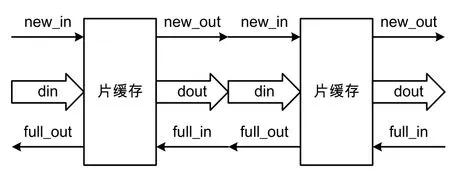
图4 相邻节点传输结构
从上述流程可以看到,数据包分片在网络中的传输是由源节点的new信号驱动,并一级一级传导下去。这种相邻节点握手的传输方式,避免了长线信号的存在,可有效提高片上网络的工作频率。
如图5所示,数据DATA0从节点N0的输入端抵达节点N1的输出端,需要使用2个时钟周期。后续的DATA1由于full信号的握手,需要花费2个时钟周期才能传输到下一个节点。假设两个节点的距离为N,数据包的分片数为M,那么数据包在两个节点间传输所需的时钟周期数为个。8×4的Mesh网络中,两个最远的节点距离为10。以输入数据为1 440 bit计算,共45个载荷分片。一个数据包的传递最坏情况下,需要花费100个时钟周期。传输时延要求为不超过33 μs,那么得到片上网络的传输时钟频率不低于3 MHz即可。
3.3 输入输出节点选择
考虑如图6所示的8×4 mesh网络。
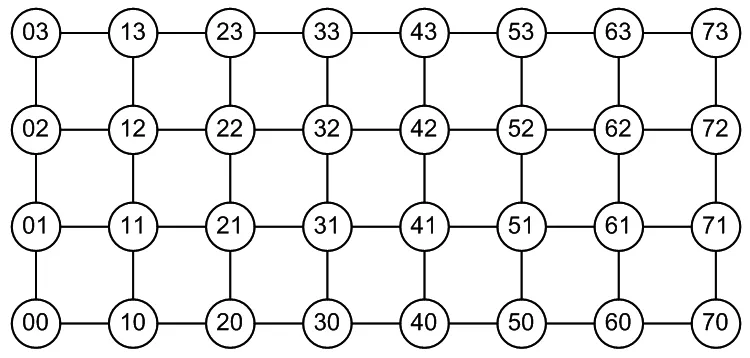
图6 8×4 mesh网络
图6中,每个圆圈代表一个网络节点,数字为横纵坐标的组合。首先需要选取最优的输入节点和输出节点,使得:
(1)输入节点到网络中32个节点的路径之和最短;
(2)网络中32个节点到输出节点的路径之和最短。
该选取方式可以使任务加载和结果收集的数据传输效率最高,并降低工作功耗。
由于输入节点和输出节点仅仅是数据传输的方向相反,因此该问题可简化为寻找网络中某一个节点到其他所有节点的路径之和最短[3-4]。
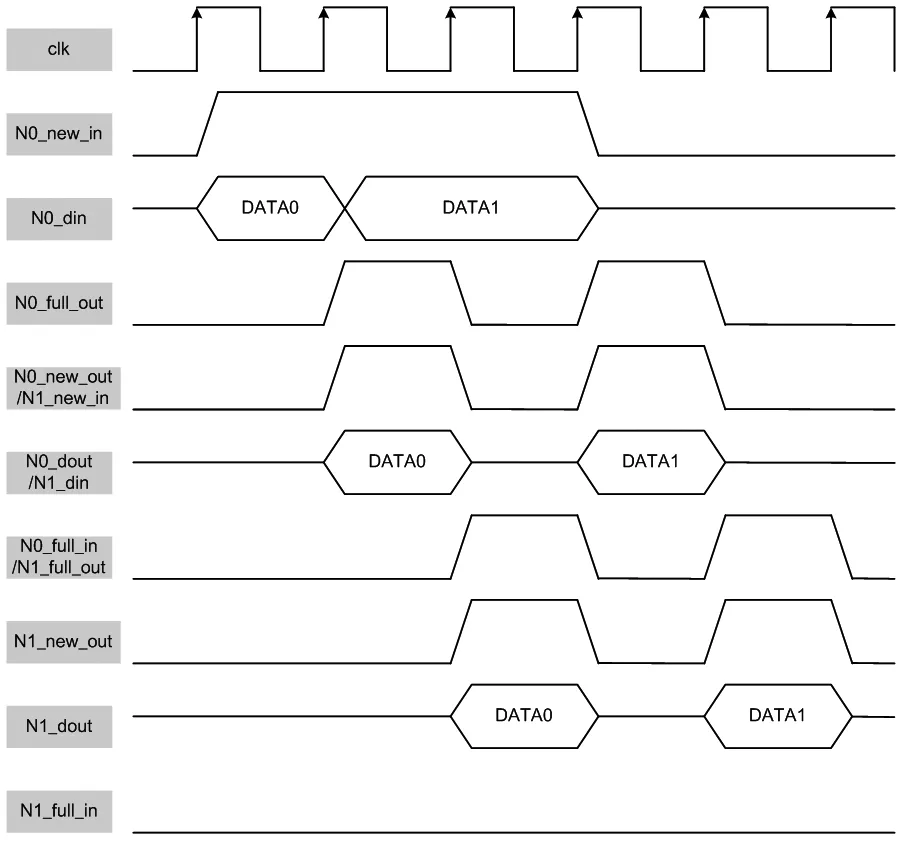
图5 相邻节点数据传输时序图
采用等势线作图的方法进行分析,如图7所示。
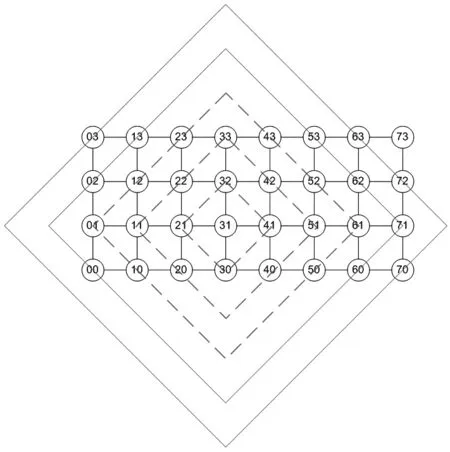
图7 网络等势线分析图
以源节点“31”为例,图中每一条虚线都称为该源节点的等势线,即指同一条虚线框所连接的节点到源节点的距离均相等。因此,选定一个节点,画出其等势线。若距离越短的等势线包含的节点越多,则该节点就是最优节点。不难看出,节点“31”即是一个最优节点,它到其他31个节点的距离之和为:4×1+7×2+8×3+7×4+4×5+1×6=72。
再将图形按轴对称和旋转对称进行翻转,不难发现节点“32”“41”“42”均是和“31”等效的最优节点。所以,输入节点和输出节点从这四个最优节点中任意选取即可。本文将节点“31”作为输入输出节点进行设计。
3.4 任务分发和回收设计
在选定了输入输出节点的基础上,考虑任务的分发和结果的回收顺序。为了降低应用复杂度,本文中采用任务的先入先出机制,即最先进入的任务,其结果也最先输出。
任务输入时,根据节点坐标,按照从左到右、从上到下的固定顺序,依次进行任务分发。结果输出时,由于不同节点的运算核可能承担不同类型的运算,且参与运算的参数权重各异,从而造成各个节点的运算耗时长短不一,有可能较晚启动的运算任务比较早启动的运算任务领先完成,因此结果输出时,不能采用哪个节点有运算完成就输出的策略。为此,引入了令牌机制。全网络中仅有一个输出令牌,当且仅当运算节点拥有输出令牌时,才能向输出节点传输结果数据。同时,全网络中也仅有一个输入令牌,当且仅当运算节点拥有输入令牌时,才能向输入节点请求任务数据。
如图8所示,初始化时,节点“03”同时拥有输入令牌和输出令牌。该节点检测到自己拥有输入令牌且运算核状态为空闲,则主动向输入节点发出包含自身坐标的请求命令(图8中a曲线)。输入节点响应该命令,并根据坐标信息将运算任务发送至节点“03”(图8中b曲线)。该节点的任务接收完成后,主动将输入令牌传递给相邻的节点“13”(图8中c曲线)。节点“13”重复相同动作,实现了输入令牌的依次传递,达到了每个节点依次主动向输入节点申请运算任务的效果。
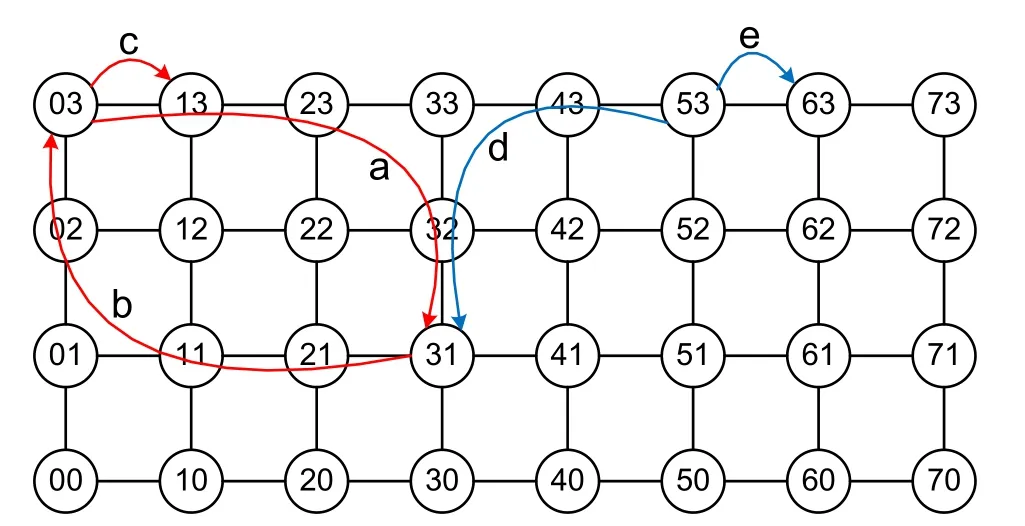
图8 任务分发和回收
当节点“53”检测到自己拥有输出令牌且运算核状态为运算完成时,则主动向输出节点传输结果数据(图8中d曲线)。当结果传输完成后,主动将输出令牌传递给相邻的节点“63”(图8中e曲线)。节点“63”重复相同动作,实现了输出令牌的依次传递,达到了每个节点依次输出运算结果的效果。
采用这种令牌机制,也可以方便地实现容错设计。多核芯片往往面积较大,由于工艺缺陷会造成芯片良率较低。可以采用屏蔽部分故障运算核的方式,使得有缺陷的芯片也可以降低性能使用。仅需在输入节点的任务分发逻辑上,做一个可配置的设计,用于指定输入令牌和输出令牌的传递方式即可。
4 结 语
本文介绍了片上网络技术在多核公钥处理器设计中的应用方法,给出了多核性能分析方法、物理链路设计方法和最优输入输出节点的选取方法,提出了基于令牌的任务分发和回收机制,解决了片上网络技术实施过程中的关键问题。本文提出的片上网络结构应用于某款高速公钥芯片中,集成了32个运算核。经芯片实测,SM2算法256 bit数字签名性能达到了30 000次/s,符合预期设计。
[1] 朱晓静.片上网络的结构设计与性能分析[D].合肥:中国科学技术大学,2008.ZHU Xiao-jing.Structural Design and Performance Analysis of On-chip Network[D].Hefei:University of Science and Technology of China,2008.
[2] 张剑贤.高性能片上网络关键技术研究[D].西安:西安电子科技大学,2012.ZHANG Jian-xian.Research of Key Technology of High Performance NoC[D].Xi'an:Xidian University,2012.
[3] YANG Lei,FoToNoC:A Folded Torus-Like Networkon-Chip Based Many-Core Systems-on-Chip in the Dark Silicon Era[J].IEEE Transactions on Parallel and Distributed Systems,2017,28(07):1905-1918.
[4] Reza H.Customizing Clos Network-on-Chip for Neural Networks[J].IEEE Transactions on Compute rs,2017,66(11):1865-1877.
