基于属性特性算法的商品推荐系统模型
2018-07-04邱京伟
邱京伟
推荐系统是根据用户的兴趣爱好推荐符合用户兴趣的对象,也称为个性化推荐系统。商品推荐系统依据收集到的顾客的信息和交易记录等有关数据,查找具有某些特性的顾客与他们购买的商品间存在的关联规则,大致确定顾客喜欢的商品的种类范围,向客户推荐与客户购买的商品存在一定关联的其他商品,既为客户购买商品提供了方便,又可提高网站的销售量。近年来,随着人民生活水平的提高和网络购物的发展,各购物网站中商品的数量和种类都大大增加,为了方便顾客在海量的商品中尽快寻找到所需要的商品,可靠高效的商品推荐系统必不可少。
在粗糙集相关理论中,知识被定义为对论域的划分模式,知识具有颗粒性,称为信息粒度或知识粒度,简称粒度。由于每个粒度都带有一定的属性,这使粒度间存在相互包含的关系,而粒度存在的关联规则在其包含粒度中也同样存在,例如,当存在所有男人都喜欢篮球的时候,就可以推导出中国男人都喜欢篮球。依据粒度间属性的特性编写的算法稱为属性特性算法,该算法通过组织相关包含数组等方法,避免在某个粒度的包含粒度上挖掘相同的粒关联规则,达到节省时间,提高挖掘效率的目的。
将属性特性算法应用到商品推荐系统中,其优点有:
一般顾客在超市购物时,往往不会只购买一种商品,这种现象在网络购物平台也同样存在。但是,现有推荐系统大多根据顾客搜索的关键字提供同一类型的商品。由于单个顾客面对不同商家的同一类商品时往往只会选择其中一家的商品,这样对购物网站的交易量提高幅度有限。属性特性算法基于粒计算,关注的重点是带有相同属性的粒度间存在的关联规则,因此不限制推荐商品的种类,其挖掘结果涉及多种商品,这样在给顾客更多选择的同时,有利于提高购物网站的交易数量和交易额。
传统算法虽然可以较准确地推测出某位客户感兴趣的商品,但是在大数据背景下,当数据的规模增大后,传统算法所需的时间消耗随之增加,这大大影响了系统的运行速度。属性特性算法利用某粒度存在的关联规则在其包含粒度中同样存在的特性,通过减少判断关联规则的次数的方法,提高每次比较中输出关联规则的数量,从而减少系统在运行中的时间消耗。在有关数据集的实验表明,在同等要求下,属性特性算法可以有效提高挖掘效率,有利于在数据量增加的情况下,降低系统反应时间,提升系统性能。
一、属性特性算法基本原理
在实际应用中,往往根据具体要求将信息按照所含属性的多少划分为不同的粒度,这使各个粒度间由于所含属性的多少而相互包含,例如粒度<种类:酒>就包含<种类:酒>∧<颜色:红>等粒度。
源覆盖度、目标覆盖度、源置信度和目标置信度是衡量粒关联规则强度的4个度量标准。在粒计算中,每个大小不一的粒度都带有一定数量的属性和属性值,这些属性和属性值使部分粒度存在着一定的包含关系。当源覆盖度为100%,而目标覆盖度也为100%的时候,称为完全匹配。在完全匹配的情况下,一个粒度与其他粒度间存在的所有关联规则,在它的所有的包含项中同样存在,例如,当100%的美国人(粒度<国籍:美国>)喜欢100%的白色商品(粒度<颜色:白>)的时候,可以得出100%的美国已婚人士(粒度<婚姻:已婚>∧<国籍:美国>)喜欢100%的白色美国产商品(粒度<颜色:白>∧<产地:美国>。
利用粒度属性的特性设计属性特性算法,将粒度的包含项放入该粒度的包含数组中,当挖掘到粒度A和粒度B建存在粒关联规则时,采用遍历的方法直接输出粒度A的包含粒度粒度与粒度B的包含粒度间存在同样的粒关联规则,这样就节省了在其包含粒度上判断是否存在粒关联规则的时间,提高了挖掘的时间效率,具体做法如下:
为每个粒度开辟有关包含数组,该粒度为该数组的第1个元素;
在属性比自身不多1的粒度中为每个粒度查找其包含粒度,并放入其包含数组中,形成该粒度的初步包含数组;
从粒度的初步包含数组第2个元素(第1个子粒度)开始,查找其初步包含数组里的粒度,把它们放入父粒度的包含数组中,形成完全包含数组,其过程如图2所示;
按要求两个数据集中的粒度相互比较,如果存在关联规则,则输出两个粒度完全包含数组中的所有关联规则。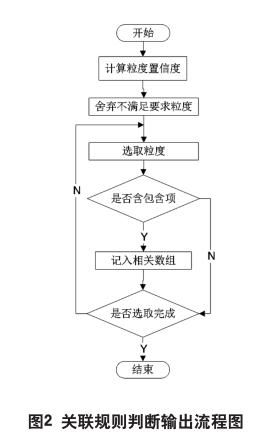
算法流程图如图2所示,当发现两个粒度间存在粒关联规则时,属性特性算法一次可以输出多条粒关联规则,与一般采用的逐个比较的方法相比,可以节省在某粒度的包含粒度上挖掘粒关联规则的时间,提高了挖掘效率。
二、属性特性算法的应用
本设计基于特点相似的人感兴趣的商品范围也相似的理念,将粒计算的思想和属性特性算法应用到商品推荐系统里,在把数据库中的用户信息和商品信息根据包含属性的多少划分为大小不一的粒度的基础上,根据近期的购买情况,结合粒度相关设定的源置信度和目标置信度等相关要素,利用属性特性算法查找相关粒度间的粒关联规则,快速从海量数据中挖掘出顾客特点与所购买商品间的联系,指导系统向特定顾客推荐特定范围的商品。
三、商品推荐系统模型设计
基于属性特征的粒关联规则挖掘算法的商品推荐系统以网上购物平台数据库为基础,主要围绕对数据的处理和分析展开设计。本商品推荐系统的全部功能模块图如图3所示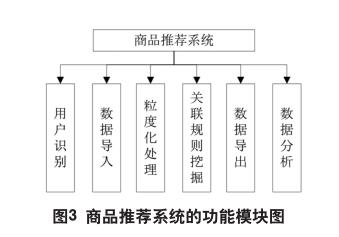
(一)数据模型及数据库设计
本商品推荐系统的系统的数据库由顾客信息表、商品信息表和购买情况表3张表构成,顾客信息表主要负责记录网站注册的会员相关信息,如年龄、籍贯和爱好等,商品信息表记录网站上出售的商品的种类、颜色、价格等信息,购买情况表的数据主要记录近一段时间内顾客在该网站上购买商品的记录。
(二)主要模块设计
本系统负责数据处理的主要功能模块有:数据导入模块、粒度化处理模块、关联规则挖掘模块和数据导出模块。
数据导入模块主要负责将数据库里的3个数据表进行识别后加载到系统中。在这个过程中。数据导入模块不但要读取数据表中的有关信息并对其进行转化,还要将有关数据项转化为一定数据类型且带有一定数值的数据。
粒度化处理模块主要涉及顾客信息表和商品信息表,它根据各个数据自身所含属性的多少按一定顺序把它们分解为一定大小的粒度,然后对所得粒度进行一定的清洗,去除重复的数据后,完成对重要信息进行必要的统计并设置相关标志位等操作。
在关联规则挖掘模块中,整理好的粒度按照属性特征算法有关步骤,首先为各粒度组织完全包含数组,再在比较中通过公式挖掘出存在的粒关联规则,通过遍历有关粒度的保护数组输出相关的粒度,并设置相关标志位,将结果记录到系统中。
数据导出模块通过对照当用户属性和关联规则挖掘模块所得出的粒关联规则,选出带有与当前顾客所涉及粒度相同的那些粒关联规则,依此列出顾客可能感兴趣的商品的目录。
(三)其他模块设计
为完善相关功能,系统加入用户识别和数据分析两个模块。用户识别模块通过输入的用户名和密码,分辨用户是系统管理员还是顾客,从而引导不同用户进入不同页面进行相关操作。数据分析模块的作用是统计查询的次数和符合要求的客户、商品数量等具有一定商业价值的相关数据,对商品受关注程度等信息进行反馈。
四、模型应用分析
商品推荐系统的数据流程如图4所示。
当系统启动后,管理人员通过系统管理员界面,可以读取有关数据的查询统计结果,还可以设置需要导入的数据表位置,修改覆盖率等参数。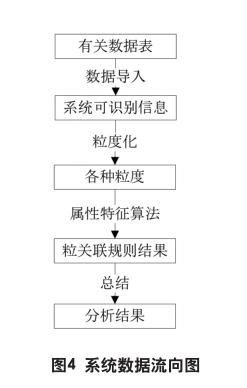
数据表由数据导入模块进行加工,数据导入模块将客户信息表、商品信息表的数据进行编码,使之能被系统识别和处理,同时将购买情况表的數据转化为布尔型数据,方便下一步的数据挖掘。
从数据导入模块得到数据后,粒度化处理模块根据顾客信息表和商品信息表数据自身所含属性的多少,按元组和属性种类由少到多的顺序,把表中的信息划分为大小不同的粒度,同时计算粒度总个数。由于在已经得到的数据中,不仅存在着许多重复的粒度,同时也缺少了如支持度等重要信息,所以要进行近一步的整理。在这个过程中,粒度化处理模块不仅要去除一定的冗余,还要计算每个粒度出现的频率并算出每个粒度的置信度,然后根据设置的置信度度对粒度进行筛选。最后,对只要数据设置有关计数位,为导出有关统计表格做准备。
关联规则挖掘模块在接收处理好的粒度的基础上,根据设定的条件(如源置信度和目标置信度)和有关统计结果(如粒度总个数),为各个粒度组织包含数组和所需标志位数组,然后利用有关公式挖掘各个粒度的包含项,放入该粒度的包含数组中。在挖掘顾客有关粒度与商品有关粒度间的粒关联规则过程中,当发现两个粒度存在关联规则的时候,按照属性特征算法有关步骤,输出两个粒度及其包含粒度间的相同粒关联规则。
当顾客登录购物网站时,数据导出模块将当前顾客所含相关粒度调出,与挖掘结果进行对比,选择那些带有与顾客相同粒度的粒关联规则,经过数据清洗后得到推荐结果,显示在相关页面上。
数据分析模块在这一过程中,收集有关数据,如近一段时间内各个粒度被推荐的次数、各商品被推荐的次数等,为有关人员下一阶段的商业活动提供必要的依据。
五、结束语
商品推荐系统不仅为顾客购物提供方便,也是电子购物网站提高销售量和销售额的重要手段之一。本文将粒计算的思想和属性特性算法引入到商品推荐系统设计中,通过分析顾客信息粒度与商品信息粒度间的粒关联规则来推荐有关商品,同时利用粒度属性间的特性减少时间消耗,在扩展推荐商品种类的同时,也提高了数据挖掘速度,不仅为客户购买商品提供了便利,还有利于提升网站的销售量。
