一种采用贝叶斯推理的知识图谱补全方法
2018-07-04翟社平段宏宇李兆兆
翟社平,郭 琳,高 山,段宏宇,李兆兆,马 越
1(西安邮电大学 计算机学院,西安 710121)2(西安邮电大学 经济与管理学院,西安 710121)
1 引 言
自Web概念诞生以来,人类先后历经了Doc Web、Social Web、Data Web时期,目前处在Web 2.5阶段,随后将朝着Intelligent Web、Social Machine(Meme Web)的方向发展,最终达到物联网与互联网相结合的万物互联阶段(Web 5.0)*http://blog.memect.cn/?p=3475.2017-06-21/2017-07-06.Web技术发展的同时也导致互联网的信息过载,这些多源异构数据及知识的爆发式涌现,给用户对所需知识的准确快速定位带来困难.知识图谱[1](KG,Knowledge Graph)是图形结构的知识库,具有强大的语义表达处理能力和图结构化展示的优势,可以对海量网络信息进行合理有序的归并整理.然而,在Web的迭代更新中仍然夹杂着大量冗余、错误以及丢失的数据信息.2014年,Linking Open Data云社区项目提供了1091个互联的KG,共包括8×106个实体、188×106个链接关系,目前实体及其关系仍呈迅猛增长趋势.尽管如此,在Google Knowledge Vault的核心项目FreeBase中,71%的人没有“出生地”描述信息,75%的人缺失“国籍”属性.这对KG的构建补全工作产生了负面影响.
针对上述问题,文献[2,3]提出了TransE模型,该模型利用词向量在空间中平移不变特性,通过将高维连续的实体间关系向低维空间嵌入进行推理预测,从而补全KG.文献[4]提出一种可扩展的启发式框架—基于张量因子分解的随机语义张量集合(RSTE,Random Semantic Tensor Ensemble),通过采集KG中语义张量形成集合,进行因式分解来执行链接预测.文献[5]基于递归神经网络(RNN,Recurrent Neural Network)使用路径排列算法对KG路径进行预测推理.文献[6]将FreeBase15K和WordNet18两个网络规模语料库结合建立了特征观测模型实现预测推理.虽然大多数模型方法对KG的补全研究工作做出了贡献,但是在数据量急剧增长的Web环境下仍然显现出实时更新性差、错误信息干扰度高、推理预测准确率低等问题.
本文在对现有KG网络链接预测模型方法进行深入对比分析的基础上,提出了一种基于贝叶斯推理的KG补全方法.该方法将贝叶斯推理理论与潜在因子模型相结合实现链接预测,通过计算节点间关系置信度判断关系的可靠性,发现实体间潜在的关系预测未来关系网络.并对KG的节点附加注释信息,利用本体库的构建推理规则进行KG的预测补全,在信息过载的情况下实时更新图谱,同时在预测精确度提升和时间开销减少方面有很好的表现.
2 相关概念
2.1 知识图谱
KG是以语义Web知识架构为基础发展而来,本质上为语义网.KG是知识的一种结构化图解表示,它由节点和弧线组成,节点用于表示实体、概念和情况等,弧线用于表示节点间的关系.KG的通用表达方式是一个三元组,即(head,label,tail),简记为(h,l,t),其中head与tail分别表示三元组中的头实体和尾实体,两个实体之间的关系用label做标记,h、t属于实体集合E(Entities),l属于关系集合R(Relationships)[7],一个简单KG示例如图1所示.
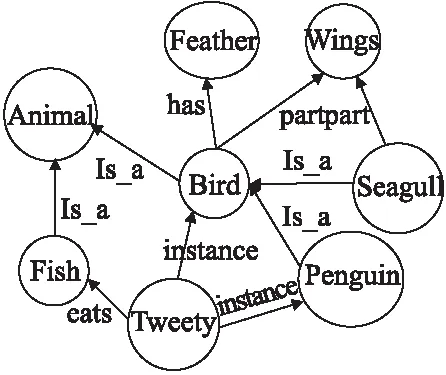
图1 知识图谱示例Fig.1 Knowledge graph example
2.2 实体描述语句
资源描述框架(RDF,Resource Description Framework)是语义Web的基本数据模型,用来描述Web资源,这里的Web资源与知识图谱中的实体相对应,RDF语句则采用(主语,谓词,宾语)的三元组形式.例如将图1表述成RDF语句如下:
(Bird,rdfs:subClassOf,Animal);
(Penguin,rdfs:subClassOf,Bird);
(Tweety,rdf:type,Penguin);(Tweety,rdf:colour,grey);
……
而RDF模式(RDFS,Resource Description Framework Schema)则提供了将Web对象组织成层次的建模原语,包括类、属性、子类、子属性关系、定义域(domain)和值域(range)约束.
2.3 贝叶斯网络链接预测
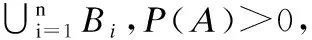
(1)
贝叶斯网络形式上是一个有向无环图(DAG,Directed Acyclic Graph),节点表示随机变量,节点间的有向边表示条件依存关系,箭头由父节点指向子节点.BN将图形理论的表达和计算能力与概率论有机的结合,使得其在处理不确定性问题上具有灵活的依赖性拓扑结构,易于理解和解释、有明显的语义以及能有效的进行多元信息融合等优势.BN使用概率推理中的先验概率与后验概率的方法对不确定问题进行定量的推理预测.
3 方法模型构建
3.1 贝叶斯潜在因子模型
对于一个知识图谱G,定义实体集εG={h|∃(h,l,t)∈G}∪{l|∃(h,l,t)∈G},关系集RG={l|∃(h,l,t)∈G},知识图谱中显式的三元组集合SG=εG×RG×εG,潜在因子用向量ex∈Rk表示,x∈εG表示知识图谱中的实体,k∈N是一个用户自定义的超参数.G中实体间有关系的三元组为可观测三元组,隐含关系的三元组集合为SG/G.由于知识图谱与贝叶斯网络结构上具有极高的相似性,在对贝叶斯网络结构的学习过程中所采用的基于打分—搜索算法的基础上进行改进,提出针对模型中潜在因子的发现预测算法.该方法的核心思想是对所有的εG与RG中的元素全排列组合,采用潜在因子的发现算法发现新的实体关系,通过对知识图谱实体添加注释信息进行属性判断并使用概率推理打分函数确定是否新增关系边.贝叶斯潜在因子模型示例如图2所示,以图书实体为例的属性矩阵(注释信息)的添加内容如表1所示.
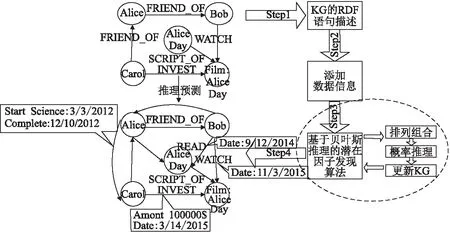
图2 贝叶斯潜在因子模型Fig.2 Bayesian potential factors model

表1 图书实体注释信息Table 1 Book entity comment information
3.2 潜在因子发现算法
潜在因子发现算法经RDF语句对知识图谱进行描述,使用RDFS蕴含模式进行推理,同时并行使用BN理论进行概率加强推理,最终依据打分函数综合两者的推理结果打分,进而对弧线的增、删、改做出判定.其中RDFS蕴含模式*http://www.w3.org/TR/REC-rdf-syntax,1999-02-22.定义了一组逻辑蕴含规则,用于从给定的RDF图中通过演绎推理出新的正确的RDF语句,从模式中抽取与值域、定义域相关的蕴含推理规则,如表2所示.

表2 RDF蕴含推理规则Table 2 RDF entailment regime
表2表明,如果谓词aaa有值域(定义域)xxx,实体yyy是谓词aaa的主语(宾语),则yyy的类型将归属于xxx.由于RDF语句也通过三元组的形式表达,RDF图与知识图谱同属于语义网范畴,故关于值域、定义域的RDF蕴含规则同样适用于知识图谱推理预测.值域定义域的内容来自于KG的实体或采用深度信念网络(DBN,Deep Belief Nets)方法[8]对数据集中实体关系数据的自动抽取,以实现注释信息对KG推理提供充分证据.其中,深度置信网络是一种典型的深度学习模型,由多层受限玻尔兹曼机(RBM,Restricted Boltzmann Machine)网络组成,采用无监督的学习进行模型训练,具有优良的特征提取能力.
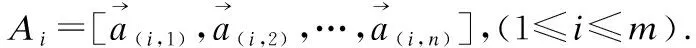
(2)
添加注释信息后对潜在链接关系的正确预测概率是
(3)
式(3)括号内参数表示在属性矩阵存在的条件下三元组的个数.由贝叶斯公式(1)可知,W′与W″存在如式(4)的关系,
(4)
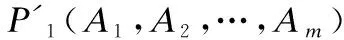
对推理结果进行定量分析时,本文在搜索—打分函数[9]基础之上进行改进,提出利用贝叶斯打分函数对实体间依赖程度打分判定.对于初始KG的实体及其关系抽象为变量集合Y={Y1,Y2,…,Yn},变量对应的取值数据集合D={y1,y2,…,yn},将初始G结构G0赋值给最佳网络结构Gk后使用贝叶斯打分函数式(5)对节点间依赖程度打分.
(5)
式(5)中Gs是KG更新过程中的一种中间状态结构,接下来在Gs收敛的条件下迭代改变Gk-1的节点间关系链接,得到新的KG网络结构,再利用贝叶斯打分函数寻找正确的网络关系Gk,并将更新后的KG赋给Gk,算法描述见表3.

表3 潜在因子发现算法Table 3 Potential factors discovery algorithm
4 实验分析
4.1 实验环境及数据
本实验平台的硬件环境为Intel(R)Core(TM)i3-4160 CPU @3.60 GHz处理器,8GB物理内存;软件环境是Ubuntu操作系统+gcc 4.3.0编译器以及64位Windows 7操作系统+集成开发环境My Eclipse;知识图谱的存储使用Neo4j图形数据库,使用面向对象的语言C++及Java编写程序.

表4 实验数据集Table 4 Experimental dataset
知识图谱构建使用如表4所示实验数据集.其中Wikidata是一个可以自由协作编辑的多语言百科知识库,它将维基百科等项目中结构化知识进行抽取、存储、关联,Wikidata中的每个实体存在多个不同语言的标签、别名、描述、以及声明(statement).DBpedia是一个大规模的多语言百科知识图谱,可视为是维基百科的结构化版本.DBpedia使用固定的模式对维基百科中的实体信息进行抽取,包括abstract、infobox、category和pagelink等信息.Zhishi.me是涵盖三大中文百科全书(百度百科、互动百科和维基百科)的中文链接开放数据[10].
4.2 实验结果与可视化展示
4.2.1 算法测试
为了全面测试算法的准确度与高效性,本文选用3种常见的知识图谱链路预测模型算法TransE(Translating Embedding)算法、Rescal算法、RSTE(Random Semantic Tensor Ensemble)算法与本文提出的贝叶斯潜在因子模型方法进行横向对比实验分析.
TransE模型[2]是一种基于转换推理方法的能量模型,用于低维实体的嵌入学习.模型通过不断调整头实体嵌入向量与关系向量的方向,使二者矢量和与尾实体向量近似相等.调整过程中的能量用一个距离函数d(h+l,t)(d可以是欧几里得距离或者是曼哈顿距离)表示.Rescal算法[11]可被看作是一个集体矩阵的分解方法.该算法对每一个知识图谱张量的正面切片进行分解,并利用稀疏线性代数计算推理技术减小内存开销.RSTE[4]是基于张量因式分解的可扩展使能集合框架.该方法通过从知识图谱中抽取形如Xk=ARkAT(A是一个n×r的矩阵,Rk是一个r×r的不对称矩阵.r为分解等级,是用户定义的参数)的张量对KG进行表示,并通过张量因式分解集合进行链接预测.本文选择准确率(Precision)、召回率(Recall)作为算法链接预测准确性的评价指标,准确率、召回率定义如(6)、(7)式.
(6)
(7)
(6)、(7)式中,假设测试结果数据集中三元组关系分为两类,正确的类(简称为正类)和错误的类(简称为负类).TP表示算法将正类推理预测成正类的数目,FN表示正类推理预测为负类的数目,FP表示负类推理预测为正类的数目.
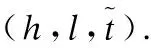
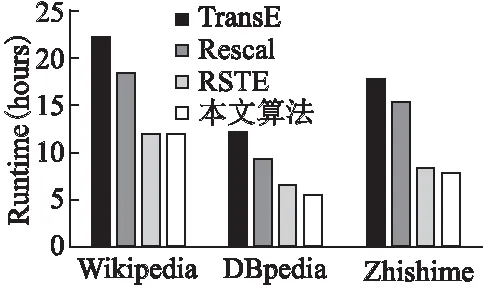
图3 算法运行总时间Fig.3 Algorithm running total time
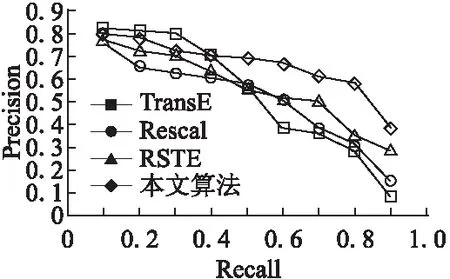
图4 算法准确率—召回率曲线横向比较结果Fig.4 Accuracy-recall rate curve of algorithms horizontal comparison results
图3显示了横向测试实验中获得最佳结果的四种算法的运行时间开销,实验数据集经过训练、评估与三元组测试等步骤进行筛选,且四种算法均保证在统一实验环境下进行.通过数据分析可得,数据集规模不同,算法的运行时间有差异.若单从Zhishi.me数据集来看,本文算法比TransE方法测试时间减少了55.6%,比Rescal方法减少了49.1%,比RSTE方法减少了5%.由图4可以清楚地看到,由于本文算法在预测推理时采用RDF蕴含推理与贝叶斯理论综合的加强推理方式,使得推理准确率较高.其中,若召回率取值固定在0.4,本文算法的精确度就开始展现出优势.随着召回率的增加,精确率总体呈递减趋势,但远高于另外三种算法.
4.2.2 模型方法实例分析及可视化展示
对图书类实体及关系属性采用DBN方法进行部分知识抽取,而后经知识融合、知识存储、知识推理、可视化展现的步骤得到如图5所示的知识图谱片断,实验的可视化分析工具采用基于Javascript的图表库Echarts,它兼容当前绝大部分浏览器,底层依赖轻量级的Canvas类库ZRender,提供直观、生动、可交互、可高度个性化定制的数据可视化图表.

图5 本文构建的知识图谱片断Fig.5 Fragment of KG proposed by this paper
图5中的实体为书籍名称B(Book),其余均为实体属性也即注释信息,作者A(Author)、出版商P(Publishers)、书籍类型T(Type)、读者U(User).注释信息的种类在图数据库Neoj4容量可承载范围内可任意添加,注释信息越多,则推理预测精确度越高.对于图5所示知识图谱,实验随机删除50%的现有链接,以此为样本测试本文提出的基于贝叶斯推理的知识图谱链接预测算法.通过测试验证,推理预测得到的知识图谱片断与初始KG进行比较并统计计算出预测准确率为82.4%.
5 总结与展望
本文针对知识网络中结构不完整、边缘或属性数据丢失以及潜在关系三元组发掘效率低下的问题,提出了一种基于贝叶斯推理的潜在因子的发现算法.此算法结合RDF蕴含推理规则与贝叶斯概率推理,通过计算节点间关系置信度来判断关系的可靠性,发现实体间潜在的关系预测未来关系网络,使得知识图谱在动态数据环境下能够实时更新.通过三种链接预测算法与潜在因子的发现算法横向对比分析测试,实验结果表明,基于贝叶斯推理的潜在因子的发现算法具有较高的准确率及较少的时间开销.知识图谱作为语义搜索的关键技术,它的不断完善将有助于搜索引擎智能化的发展.由于本论文提出的方法在实验数据规模上还没有达到真正意义上的海量且数据预测效率还有上升的空间,下一步的工作,是将链接预测算法深度嵌入至KG中进行扩大数据集的搜索引擎效率测试并不断完善算法.
:
[1] Liu Qiao,Li Yang,Duan Hong,et al.A survey of knowledge graph construction technology[J].Computer Research and Development,2016,53(3):582-600.
[2] Bordes A,Usunier N,Garcia-Duran A,et al.Translating embeddings for modeling multi-relational data[J].Advances in Neural Information Processing Systems,2013,112(9):2787-2795.
[3] Nickel M,Tresp V,Kriegel H P,et al.A three-way model for collective learning on multi-relational data[C].International Conference on Machine Learning,Bellevue,Washington,USA,2011:809-816.
[4] Yi T,Luu A T,Brauer F,et al.Random semantic tensor ensemble for scalable knowledge graph link prediction[C].Tenth ACM International Conference on Web Search & Data Mining.Shanghai,China,2017:751-760.
[5] Neelakantan A,Roth B,Mccallum A,et al.Compositional vector space models for knowledge base completion[J].Computer Science,2015,43(2):1-16.
[6] Toutanova K,Chen D.Observed versus latent features for knowledge base and text inference[C].The Workshop on Continuous Vector Space MODELS & Their Compositionality,2015.
[7] Xu Zeng-lin,Sheng Yong-pan,He Li-rong,et al.A survey of knowledge graphs[J].Journal of University of Electronic Science and Technology of China,2016,45(4):589-606.
[8] Chen Yu,Zheng De-quan,Zhao Tie-jun.The research of Chinese entity classification based on deep belief nets methods[J].Intelligent Computer and Applications,2014,35(2):29-31.
[9] Dong Li-yan.Research on Bayesian network application[D].Changchun:Jilin University,2007.
[10] Qi Gui-lin,Gao Huan,Wu Tian-xing.Research progress on knowledge graph[J].Technology Intelligence Engineering,2017,3(1):4-25.
[11] Nickel M,Tresp V,Kriegel H P.A three-way model for collective learning on multi-relational data[C].International Conference on Machine Learning,Belleevue,Washington,USA,2011:809-816.
附中文参考文献:
[1] 刘 峤,李 杨,段 宏,等.知识图谱构建技术综述[J].计算机研究与发展,2016,53(3):582-600.
[7] 徐增林,盛泳潘,贺丽荣,等.知识图谱技术综述[J].电子科技大学学报,2016,45(4):589-606.
[8] 陈 宇,郑德权,赵铁军.基于Deep Belief Nets 方法的中文名实体分类研究[J].智能计算机与应用,2014,35(2):29-31.
[9] 董立岩.贝叶斯网络应用基础研究[D].长春:吉林大学,2007.
[10] 漆桂林,高 桓,吴天星.知识图谱研究进展[J].情报工程,2017,3(1):4-25.
