一种结合SSD特征的分布式文件系统元数据优化技术
2018-07-04罗圣美陆游游秦雄军杨洪章张佳程舒继武
罗圣美,陆游游,秦雄军,杨洪章,张佳程,舒继武
1(清华大学 计算机科学与技术系,北京 100084)2(中兴通讯股份有限公司,南京 210012)
1 引 言
分布式文件系统是高性能计算、互联网大数据等大规模系统的关键组成部分[1].近年来,随着高性能计算和互联网大数据系统的规模急剧增长,数据的存储与处理面临更严峻的挑战.在分布式文件系统中,元数据服务(Metadata Service)是制约分布式文件系统性能的瓶颈.分布式文件系统数据访问首先需要向元数据服务器请求文件的元数据描述信息,然后依据所获得的元数据信息,访问数据服务器,如高性能计算领域的文件系统Lustre、OrangeFS等均采用类似访问模式.元数据服务位于数据访问的关键路径上,元数据的访问性能直接影响数据的访问性能,因而,优化元数据操作的性能对分布式文件系统整体性能的提升至关重要.
由于元数据操作具有粒度小、更新频繁的特点,元数据操作性能一直是分布式文件系统中的设计难点.元数据操作的粒度小,体现为每次操作通常仅仅修改很少的字节,例如inode索引元数据通常修改128字节,甚至只是修改其中一个或仅几个结构体的字段.元数据操作的另一特点是更新频繁,体现在同一操作需要更新多个地方,并需要及时写回持久性介质以保证数据正确性.例如,文件创建操作需要修改文件索引节点、父目录及父目录索引节点.这两个特点使得元数据写回操作呈现分散随机写特征,且数据写放大问题严重,即数据写回持久性介质的数据量远大于软件程序写入的有效数据.由于固态盘(Solid State Drive,SSD)具有远高于传统磁盘的随机读写能力与数据持久性,所以目前通常将SSD作为分布式文件系统元数据服务器的存储介质,以降低系统访问的延迟.然而直接在元数据服务器中使用SSD替换硬盘存在几个问题.SSD的随机写性能远远低于顺序写与读性能,因而不能完全发挥SSD的性能优势.同时,SSD具有磨损问题,即具有有限的写入量限制.元数据的写放大问题不仅对系统性能产生严重影响,而且加速了闪存的磨损.因而,直接将SSD用于分布式文件系统的元数据加速仍然不能取得理想效果.
本文提出了一种结合SSD特性的分布式文件系统元数据读写优化技术,并基于该技术实现了元数据节点的本地文件系统MDSFS.MDSFS基本原理是将要更新的元数据中的脏数据以记录(record)形式拼接在一起,仅将拼接而成的数据页写入物理盘.这样在每次同步操作时,需要真正落盘的数据量大大减少,不仅降低了写放大系数,而且减少了同步操作的时间,提升了文件系统写入性能.元数据写入具有粒度小,同步频繁的特点,传统文件系统在这种环境下写放大严重,且延时较大.MDSFS根据元数据的特点进行优化,元数据写入粒度越小,同步操作越频繁,MDSFS表现得比传统文件系统越有优势,通过对元数据的优化管理,使得系统免受频繁小数据同步的冲击.
2 相关工作
分布式文件系统的元数据优化技术可分为两类:分布式元数据服务优化技术和元数据服务读写优化技术.面向SSD存储设备的本地文件系统在近年来也得到了较大的关注.除了早期的嵌入式闪存文件系统之外,服务器端的通用闪存文件系统也得到了较快发展.
2.1 分布式元数据服务优化技术
分布式元数据服务优化一直是分布式文件系统中的关注问题.为提高元数据服务性能,不少文件系统采用元数据集群的方式提供元数据服务.如何切分元数据以实现在多元数据节点上的分布与均衡是其中的研究热点,Ceph文件系统通过动态子树的方式实现元数据在多节点之间的动态均衡[2].针对大目录的文件元数据访问慢的问题,GIGA+将同一目录划分为固定长度的目录分区,并哈希到不同节点,以提高访问效率[3].文献[4]进一步提出了动态的两层分割方法,提供更细粒度的目录并发与查询.
为提高元数据性能,分布式文件系统还采用了客户端缓存、预取等技术.NFS文件系统在第三版本中引入READDIRPLUS命令,在获取文件句柄的同时传输文件属性,减少了LOOKUP的访问次数[5].NFS在第四版本中还引入RPC组合(Compounded RPC),即将多个RPC组合到单个RPC中,减少网络交互次数[6,7].文献[8]进一步提供了放松顺序性,以提高分布式文件系统的操作性能.
近年来,不少研究人员还提出采用键值存储的方式加速文件系统元数据性能.卡内基梅隆大学提出的IndexFS,采用了LevelDB键值存储系统存储文件系统元数据,大幅提高了元数据性能[9].类似的,XtreemFS文件系统*XtreemFS.http://www.xtreemfs.org/也基于BabuDB[10]实现了基于键值存储的元数据管理.文献[20]提出了在并行文件系统GPFS、Lustre上,使用SSD作为元数据服务器的存储介质,以提高元数据操作的带宽.PLFS[22]将SSD作为磁盘的缓存,以加速分布式文件系统元数据的读写.然而,如何在元数据服务器中深度优化SSD以提高元数据性能尚未得到广泛研究.
2.2 元数据服务读写优化技术
分布式文件系统中元数据的组织多以本地文件系统的形式存储,本地文件系统的读写优化直接服务于元数据性能的提升.面向SSD存储设备的本地文件系统在近年来也得到了较多的关注.除了早期的嵌入式闪存文件系统之外,服务器端的通用闪存文件系统也得到了较快发展.
FusionIO公司与普林斯顿大学的研究人员联合提出了DFS(Direct File System)文件系统.DFS通过VFSL(Virtualized Flash Storage Layer)实现块的分配和回收.VFSL是Linux设备驱动和FushionIO的特殊硬件的一个结合*FushionIOioDrive specification sheet.http://www.fusionio.com/PDFs/Fusion%20Specsheet.pdf,向文件系统或数据库系统提供了一个巨大的线性虚地址空间,隐藏了从虚拟地址到物理页面之间的映射细节,使得客户端程序可以更加灵活的方式在单一层面上直接访问多个闪存设备.DFS利用VFSL进行inode和数据块的分配与回收,实现了简单的映射机制,大大简化了文件系统的设计和实现.与Ext4相比,DFS在direct模式和buffered模式下均有一定的性能提升[11].
对象式闪存系统OFSS(Object-based Flash Storage System)主要是为了解决文件系统写放大系数过大的问题而提出的[12].OFSS提出了一种基于对象式的闪存转换层OFTL(Object-based Flash Translation Layer),OFTL能够以对象存储方式提供闪存存储管理功能,实现从对象逻辑操作到闪存物理地址之间的转换.OFTL向文件系统提供对象式接口(oread,owrite,oflush等).读写操作均以字节为粒度进行,可以有效地进行数据的紧凑组织与页面组合,以减少写入量,从而减小写放大系数[13].
文件系统目录树更新有分散小写和频繁同步两个特点,导致其一致性与持久性的维护需要极高的代价.分散小写导致SSD设备性能下降,频繁同步则导致SSD设备寿命下降.ReconFS[14]通过分离易失性与持久性目录树的文件系统命名空间管理机制来降低元数据更新代价,同时ReconFS还提出了嵌入式索引技术,将索引页面元数据嵌入被索引页面,来提供目录树一致性,减少了数据写回.
F2Fs*A.B.Bityutskiy.JFFS3 design issues.http://www.linux-mtd.infradead.org, 2005是一个专门针对闪存设备优化过的log-structured文件系统.F2Fs引入了segment,section和zone三种分配单位.为了解决日志型(log-structured)文件系统的雪球式更新的问题,F2Fs引入了node address table,索引块中不再存放物理地址,而是存放node ID,根据node ID在node address table中查找相应的物理地址.F2Fs中存在六个不同的log区,根据数据的冷热程度,F2Fs将数据写入到对应的log区,实现了数据的冷热分组[15].
ParaFS[16]是一个充分利用闪存设备并发特性的日志型(log-strutured)文件系统.ParaFS提出了一种二维数据分配策略,既保证了数据的冷热分组不会遭到破坏,又保证了闪存通道(channel)级的并发得到了充分利用.为了保证垃圾回收的有效性,ParaFS将传统文件系统级的垃圾回收和FTL级的垃圾回收整合到文件系统里,减少了冗余.ParaFS还在文件系统级实现了一个请求调度器,每个调度队列对应一个channel,ParaFS将新的请求分配到当前负载最小的队列里.
综上,这些面向闪存的本地文件系统的研究,有效提高了SSD设备在存储系统中的利用效率.然而,分布式文件系统中元数据的存储与本地通用文件系统的存储呈现不同特征,如何基于分布式文件系统元数据的存储特征,设计更为高效的组织结构是本文的一个重要研究内容.本文针对元数据细粒度、更新频繁等特点,研究了内存页面的重新组织、多次变化数据的迭代更新、元数据写入方式的进一步优化等内容.
3 元数据更新优化方法
本节主要描述一个基于本地元数据文件系统MDSFS的架构设计,以及结合SSD特征而进行的细粒度元数据更新技术、日志式写入方式和意外故障恢复关键技术.
3.1 方案设计
基于本地元数据文件系统MDSFS的元数据系统架构设计如图1所示.主要包括客户端,数据服务器和元数据服务器三部分.MDSFS对元数据的处理流程如图2所示.

图1 MDSFS元数据系统架构图Fig.1 MDSFS′s metadata architecure
MDSFS对元数据的管理分为两个部分,即内存部分和闪存部分.在闪存部分,MDSFS划分了两个区域,一部分是传统的文件系统映像区,用来存储持久化的文件系统数据,另一部分是缓冲区,用来存储更新的元数据记录.在内存中,除了传统的页高速缓存部分,MDSFS还定义了一套专用的数据结构来进行数据标记和管理.

图2 MDSFS数据流程图Fig.2 MDSFS′s data flow chart
当分布式文件系统的元数据被更新时,MDSFS的内存管理程序会对写入的脏数据建立索引,并在同步操作时,将这些小于页粒度更新的脏数据进行拼接组合,然后将拼接组合后的新数据页,写入到闪存的缓冲区中,这样减少了频繁的元数据更新所带来的写放大问题.当缓冲区的数据达到一定阈值后,MDSFS会对缓冲区中的数据进行检查点(checkpoint)操作,将这些脏数据写入到文件系统映像中,完成整个数据持久化的过程.
在分布式文件系统更新元数据的过程中,MDSFS使用记录级的更新方式,采用基树索引和位图标记的方式,详细记录数据的更新位置和长度.在数据写入缓冲区和文件系统映像时,MDSFS采用日志式写入方式,即所有的数据都写入新的地址上,这样便于掉电恢复,有利于保证数据的一致性.
3.2 记录级更新
MDSFS以记录的形式将每个内存页中脏的部分进行标记和拼接.在记录级更新方式中,MDSFS记录所有写请求中的数据更新范围.在同步操作发生时,如用户显式调用同步操作(fsync,fdatasync等)[17,18],或者操作系统的后台线程(如pdflush)*Flushing out pdflush.http://lwn.net/Articles/326552启动回写操作,文件系统启动写回操作写回脏数据.MDSFS遍历属于该文件的所有记录,将其所指向的页高速缓存中的脏数据段拼接在一起,组成完整页面后,再以日志形式顺序写入闪存的缓冲区中.
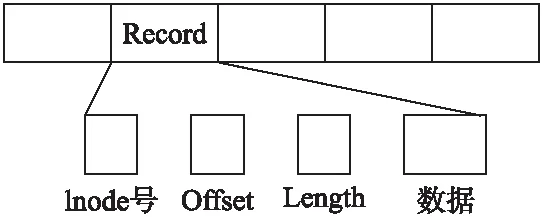
图3 记录(record)组成示意图Fig.3 Record organization
图3描述了记录(Record)的组成结构.每个页面中的脏数据以变长形式组织,为了描述这些变长数据,MDSFS为每段数据加上了标记其身份的信息元组,该元组以
MDSFS采用变长的形式,以字节为粒度组织最近更新的这部分数据,可能使得读取最新数据时需要结合文件系统映像和内存数据进行合并更新,导致定位较慢,而专门为这部分数据建立索引开销较大.为了解决这个问题,MDSFS通过增加脏数据相对应的内存页面的引用计数,强制将被记录指向的数据页保留在文件系统页高速缓存中.由于记录中的脏数据为最近更新数据,将其对应的数据页保留在高速缓存中的命中率较高,因而MDSFS不会影响读操作的性能.
当写请求到来时,对于符合预置条件的细粒度元数据更新,MDSFS首先按正常的文件系统路径更新页高速缓存,但是并不把内存页面标记为脏,这是为了防止脏的内存页被后台pdflush线程整页写回到底层存储设备中.然后,MDSFS将根据写请求的长度以及位置信息,建立记录的四元组
3.3 日志式写入
尽管SSD的随机读写性能相比磁盘有了质的提高,但是不能忽视的是,SSD的随机读写性能仍然要远低于其顺序读写性能.因此MDSFS以日志更新的形式顺序地将拼接后的数据页写入SSD盘中,以实现最大的写入性能.

图4 MDSFS日志式顺序写入缓冲区Fig.4 MDSFS write jounal to buffers sequencely
图4中,MDSFS在SSD上划出固定大小的空间(可配置)专门用于日志式写入,称为缓冲区域.缓冲区域不属于文件系统的地址空间,因而文件系统不能检索到其中的数据.
当文件的同步操作到来时,首先,MDSFS根据文件的inode号,在内存中找到与该文件相关的记录;然后遍历属于该文件的所有记录,把每条记录中data pointer指向的数据段连同记录信息,拼接到临时的内存页面中,当临时页面不足以容纳一条完整的记录时,以padding填充页面剩余部分.之后,MDSFS将临时页以日志的形式顺序写入当前缓冲区中进行持久化.重复以上步骤直到所有记录处理完毕,此时该文件的同步操作完成,该文件的所有脏数据已经写入到闪存盘的缓冲区域,完成了数据的持久化保证.
综上所述,对于分布式文件系统元数据细粒度和频繁更新模式,MDSFS采用记录级标记方法,让小于一页的脏数据拼接在一起,形成一个完整的脏数据记录.然后将这些拼接后的脏数据记录以顺序的方式写入缓冲区域,以完成数据持久性要求.该技术能够大幅度减少分布式文件系统在元数据同步时的写入数据量,同时,由于写入的数据是以顺序的方式进行写入,能够有效利用SSD盘的高速顺序读写性能,降低了分布式文件系统元数据写操作的时间.
3.4 数据一致性保障
MDSFS使用两个技术来保障系统数据的一致性,分别是检查点(checkpoint)和故障恢复.检查点是当SSD的缓冲区使用量超过阈值时,将缓冲区中的以记录形式拼接的脏数据写回到文件系统的映像中,实现文件系统映像的一致性.故障恢复是保证在故障发生时,MDSFS可以通过SSD缓冲区和文件系统映像区中的数据,进行恢复,保证数据的持久性与文件系统的一致性.
3.4.1 检查点(checkpoint)
MDSFS将专用的缓冲区域分为两块,每块大小为64MB(可配置).当用户发出显式同步操作或者操作系统后台线程pdflush发出同步请求时,MDSFS均按上节所述的记录级更新方式将脏的元数据页进行拼接,以日志形式将拼接记录顺序写入到当前缓冲区.当前缓冲区域空间即将耗尽时,MDSFS将进行checkpoint操作,将缓冲区中的脏数据页写回到SSD盘的文件系统映像区域中.被索引的数据页面因为引用计数被加一,所以这些数据会被强制保留在内存中,不会被换出,即在checkpoint过程中需要写回文件系统映像区域内的数据页都保留在内存中,不需要额外的读缓冲区操作.这样能够加快MDSFS执行checkpoint的时间.在内存数据页内容已经写回原地址后,缓冲区域的数据可以被丢弃,清空的缓冲区能够被重复使用,被保留在页高速缓存中的数据页也能够被释放.

图5 MDSFS checkpoint示意图Fig.5 MDSFS checkpoint
在checkpoint期间到来的所有同步请求,将以日志式更新的方式写入另一个缓冲区.通过两个缓冲区的轮流使用,使得后续同步操作不需要停下来等待checkpoint的完成.图5描述了checkpoint实现过程.
3.4.2 故障恢复
在日志式写入的更新过程中,如果发生意外故障,导致系统宕机,需要考虑数据的一致性问题.
如果故障发生在非checkpoint期间,MDSFS在恢复时,会读出当前缓冲区中的所有记录.对于每条记录,根据其文件inode号和偏移值,从文件系统映像中读出对应的数据到页高速缓存中,注意此时的数据是陈旧的,然后根据缓冲区记录中的数据对页高速缓存中的陈旧数据进行更新,并把内存页面标记为脏.重复以上步骤直到当前缓冲区中的所有记录处理完毕,最后,调用sync_fs命令,将文件系统页高速缓存中的所有脏页持久化,此时整个系统已处于一致的状态,故障恢复过程结束.
如果故障发生在checkpoint期间,由于checkpoint过程没有完成,缓冲区中的记录还没有被清除,因此MDSFS恢复时,仅需要对缓冲区的记录重新做一次checkpoint即可.
4 系统实现
基于上述技术,本文实现了一个面向SSD的元数据文件系统MDSFS,该系统使用一棵基树(Radix Tree)和链表对所有的更新进行索引,基树中存储了被修改的元数据文件的inode号.在每个inode索引节点上,通过一个链表来维护该文件的记录信息.记录中包含了指向页高速缓存中相应页面的指针(data pointer)、在页面中的偏移值(offset)及数据段长度(length)等关键信息.系统实现时,使用链表将属于同一文件的记录串联起来,完成对所有脏数据的遍历,从而加速元数据文件同步操作.
MDSFS中数据结构间的组织关系如图6所示.
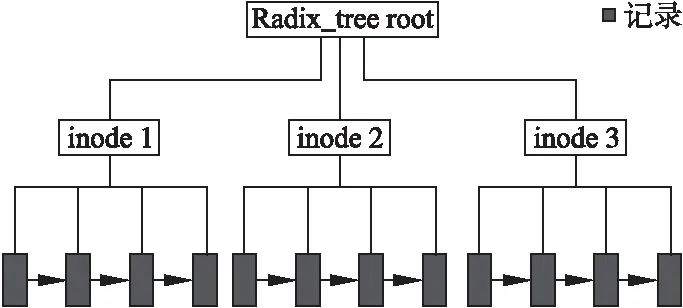
图6 MDSFS数据结构组织示意图Fig.6 MDSFS data structure and organization
当写操作到来时,MDSFS需要在索引基树(Radix Tree)中登记相应的记录.首先,以文件的inode号为索引,在索引基树中找到相应的inode,如果不存在该inode的索引节点,则新建一个该文件的基树节点.若找到对应的基树节点,则以写操作的偏移量,即offset为索引值找到相应的记录,MDSFS将属于同一个页面的记录进行合并.同时,MDSFS将页高速缓存中的页面引用计数加一,强制保留在内存中以供高速读取.
在写操作开始时,MDSFS还需要根据本次写操作的写入长度进行判断.如果写操作的写入长度小于内存页面的二分之一,则按照上述流程进行;如果写入长度大于内存页面的二分之一,则不再将其封装成记录加入到索引基树中,因为对于过大的数据段进行拼接反而会降低效率.对于写入长度大于内存页面一半的写请求,MDSFS将按照正常文件系统处理写请求的路径进行处理,即不对大粒度的写操作进行拼接写入.
当同步操作到来时,MDSFS根据被同步文件的inode号在索引基树中找到相应的inode节点.如上文所述,每个inode节点的所有记录通过链表链接在一起.MDSFS顺序扫描该链表,将每条记录及其所指向的数据段拷贝到一个页面中,当该页面满时,将其写入到闪存的缓冲区中进行持久化.重复此过程,直到该链表中所有记录都已经被正确处理.然后,MDSFS从索引基树上删除相应的inode节点,因为该文件的所有脏数据都已经持久化到SSD盘上了.
在当前SSD上缓冲区满时,专门负责checkpoint的后台线程被唤醒.该线程扫描缓冲区对应的所有记录,把记录指向的内存缓存页面标记为脏,同时将其引用计数减一,最后通过调用VFS的sync_fs接口将所有的脏页写回到文件系统映像中.
5 实验测试
5.1 测试环境
本节分别在顺序写入和随机写入两种情况下,采用专用测试工具,对Ext4[19]、F2FS[15]和MDSFS三者的写性能和写入量分别进行了对比测试,以评估MDSFS对系统性能和SSD使用寿命的影响.该测试工具,是根据实际使用的分布式文件系统的元数据io特征来设计的,测试使用的trace是从分布式文件系统中采集的,可以反映真实的分布式文件系统下的元数据负载特征.同时使用fio测试工具对三者进行了性能对比测试.
实验在linux 3.0.76内核环境下进行,所用服务器的配置如表1.测试使用的SSD设备容量为400GB.

表1 实验环境配置Table 1 Configuration of experiment
5.2 写性能测试
5.2.1 顺序写性能
表2为顺序写条件下Ext4、F2FS和MDSFS三者性能对比结果.该实验包含五个文件的写操作,五个文件分别为DIC,DIRNODE,FENTRYIDX,FENTRY(FNODE),FNODEIDX.这五个文件分别模拟目录索引、目录元数据节点、目录项索引、目录项元数据(文件元数据节点)、文件元数据节点索引的数据访问模式.每个文件均包含86400条记录,每条记录在这五个文件中的长度分别为30B,50B,60B,70B,4096B,其中30B,50B,60B,70B代表细粒度读写,4096B代表粗粒度读写的情况.本实验中,每写入100条记录调用一次fsync进行同步,测试结果单位为秒.

表2 顺序写入性能测试Table 2 Benchmark of sequence write
表2数据显示,在顺序写入情况下,MDSFS在细粒度写入时,所需时间仅为Ext4的24%~39%.MDSFS所需时间较F2FS也有一定下降.MDSFS的性能优势主要来源于其记录级拼接技术,即将数据页中的脏数据部分进行合并后写入,减少无效数据的写入.
在粗粒度写入时,MDSFS所需时间为Ext4的62%左右,较F2Fs也有一定下降.主要原因是,MDSFS和F2Fs都采用日志式的顺序写入方式,而Ext4采用原地更新的随机写入方式.

图7 顺序写入性能对比Fig.7 Performance comparison of sequence write
图7是对顺序写入性能的图形化表示.由图可见,顺序写入情况下,无论是细粒度的写入,还是粗粒度的写入,MDSFS较Ext4均有明显的性能提升.
5.2.2 顺序写入量
为进一步评估MDSFS对SSD寿命的影响,本实验对顺序写情形下的写入量进行采集和评价.
表3显示了Ext4、F2Fs和MDSFS在顺序写入下的写入量,其结果以Ext4的写入量为基础进行了归一化表示.在顺序写入的情况下,MDSFS在细粒度写入时,写入量是Ext4的31%-46%.这进一步验证了表2在顺序读写性能实验中的结果,即由于记录级拼接技术大幅降低了细粒度写回情形下的写入量,从而提升了数据写入性能.
MDSFS在粗粒度顺序写入时,写入量是Ext4的0.98倍.这是因为一方面MDSFS的记录拼接技术没有发挥作用,另一方面MDSFS和F2Fs一样,都是采用日志式写入,在写入时不仅要更新数据,还需要更新索引数据,在顺序写情况下,索引数据具有良好的局部性,写入量较小,因此写入量和Ext4相差不大.
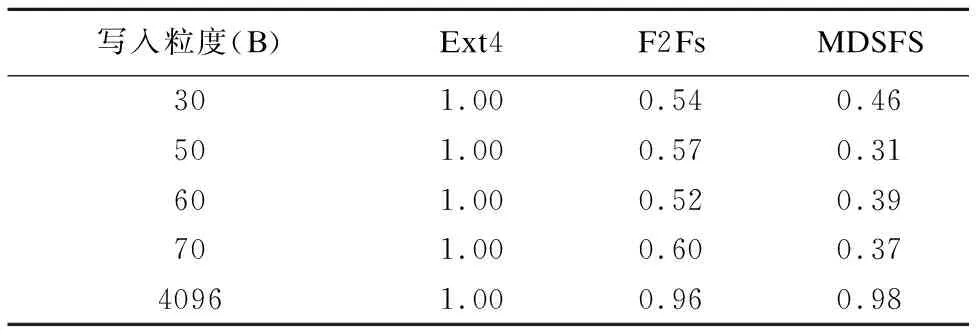
表3 顺序写入量测试Table 3 Perfoamance of sequence write in different block siz

图8 顺序写入量对比Fig.8 Comparison of sequence write size
由图8可知,在细粒度顺序写入的情况下,MDSFS写入量较Ext4有明显减少,但在粗粒度情况下,MDSFS写入量减少不明显.
5.2.3 随机写性能
表4为随机写条件下Ext4,F2Fs和MDSFS三者性能对比结果.该实验所采用数据集与顺序读写性能测试数据集相同.不同的是,每次写入的记录个数是随机的,记录之间的间隔也是随机的,直到一共写入86400 * 10(循环十次)条记录后结束.测试结果单位为秒.
表4显示,在随机写入情况下,MDSFS在细粒度写入时,所需时间仅为Ex4的19%-25%,为F2Fs的28%~56%.主要原因是在细粒度写入情形下,MDSFS的性能优势不仅仅来源于其记录级拼接技术减少了数据写入量,还源于其记录级拼接技术中对脏数据合并后的日志式顺序写入.后者在MDSFS与F2FS的结果对比中可以体现出来.F2Fs没有记录级拼接技术,数据以整页4 KB粒度写回.尽管其采用日志式写入方式,但由于数据逻辑上随机,其元数据更新引入较大开销.而MDSFS将脏数据部分拼接写回,以记录粒度顺序写回,无需立刻修改元数据.相比于顺序写入测试,MDSFS比F2Fs性能提升更多.
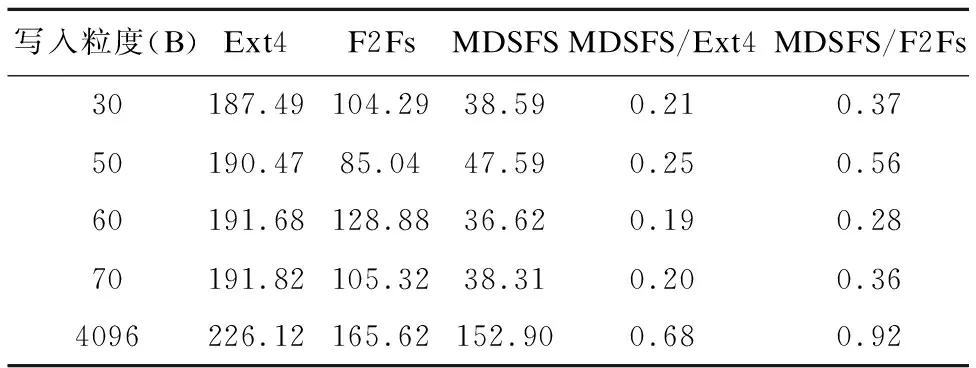
表4 随机写的性能测试Table 4 Random write benchmark
在粗粒度随机写入时,MDSFS写入时间为Ext4的68%,为F2Fs的92%.

图9 随机写入性能对比Fig.9 Comparizon of radom write performance
由图9可知,在细粒度随机写入情况下,MDSFS性能较Ext4和F2Fs有明显提升.在粗粒度随机写入情况下,MDSFS也比Ext4和F2Fs有一定提升,但是,性能提升不及细粒度明显.
5.2.4 随机写入量
表5显示了Ext4、F2Fs和MDSFS在随机写入下的写入量,其结果以Ext4的写入量为基础进行了归一化表示.在随机写入的情况下,MDSFS在细粒度写入时,写入量减少达到了90%以上.相比于顺序写入测试,MDSFS在随机写入测试的写入量进一步减少.这是因为在随机写入测试中,元数据较为分散,因而数据得到进一步聚合,降低了元数据的写入量.
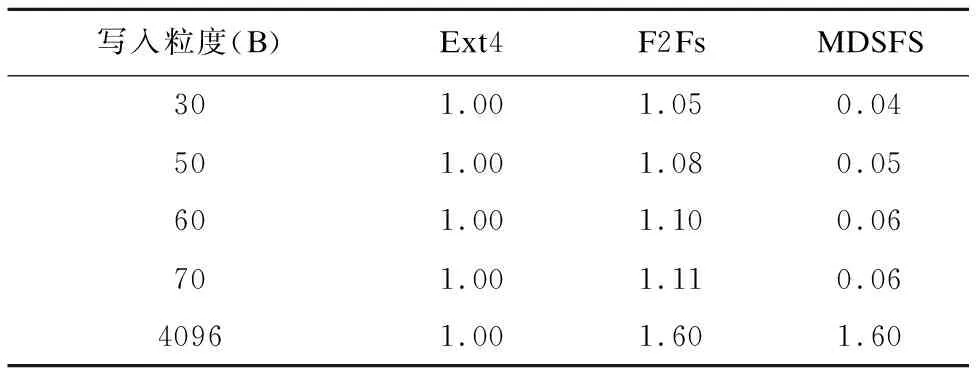
表5 随机写入量测试Table 5 Perfoamance of sequence write in different block size
MDSFS在粗粒度随机写入时,写入量是Ext4的1.60倍.这是因为MDSFS和F2Fs一样,采用日志式写入,在写入时不仅要更新数据,还需要更新索引数据(也即元数据),但是在随机写情况下,元数据比较分散,缺少局部性,对索引数据的写入量较大所致.
由图10可知,细粒度随机写入的情况下,MDSFS写入量较Ext4和F2Fs明显减少.仅在粗粒度随机写情况下,MDSFS写入量比Ext4增大.
5.3 fio测试
5.3.1 fio性能测试
fio*Fio.http://freshmeat.net/projects/fio/是一个I/O测试工具,常用来进行性能测试和压力测试.fio支持对文件系统和块设备的直接测试.fio简单易用,以一种易于理解的文本模式对测试工作进行描述.

图10 随机写入的写入量对比Fig.10 Comparison of radom write size
本实验使用fio对MDSFS,Ext4和F2Fs分别进行了随机写入性能测试.I/O引擎使用psync方式,测试时间为10分钟,测试线程10个.
从表6可以看出,使用fio测试情况时,MDSFS写入速度是Ext4的2.33倍,是F2Fs的1.26倍.对比示意如图11所示.

表6 fio测试随机写入速度测试Table 6 Performance of random write tested by fio
由于fio是通用的存储系统性能测试工具,本测试说明MDSFS不仅可用于元数据性能优化,同时对于数据块存储也会有较好的提升效果.

图11 fio测试随机写入速度对比Fig.11 Comparison of random write in different filesystem
5.3.2 fio写入量测试
从表7可以看出,在本实验中使用fio进行测试时,MDSFS写入量仅为Ext4的73%,为F2Fs的59%.主要原因是,F2Fs采用日志式写入方式,尽管在性能上体现了优势,但是放大了写入量.本文所提MDSFS采用记录级拼接方式,适合fio测试采用的64B~2048B的细粒度写入数据,不仅在性能上有优势,在写入量上也有一定的比较优势.

表7 Fio测试随机写入量测试Table 7 Performance of amount of radom write tested by fio

图12 fio写入量对比Fig.12 Comparisonof write sizein different filesystem
由图12可以看出,在fio随机测试情况下,MDSFS写入量上对比Ext4和F2Fs都有明显的降低.
6 结 论
在分布式存储系统中,元数据写入具有粒度小,同步频繁的特点.传统文件系统在这种情况下写放大非常严重,且延时较大.本章介绍了一种基于SSD的元数据读写优化的文件系统MDSFS,采用记录级拼接和日志式写入方式,以记录的形式将内存页中真正脏的数据部分进行标记和拼接,同时在SSD设备上划出了独立的缓冲区,在同步操作时,以日志的形式顺序写入到缓冲区中,消除了这一过程中的随机写操作,提高了元数据的写入性能.
测试表明,在细粒度随机写情况下,元数据写入时间较Ext4减少77%,写入量较Ext4减少94%以上.在细粒度顺序写情况下也有较好的提升效果,但是粗粒度写情况下,提升效果不明显.该项技术已应用于中兴通讯分布式文件存储系统中,并在中国移动南方基地云存储项目中实际使用,有效提升了元数据访问性能,同时延长了SSD使用寿命.
:
[1] Shvachko K,Kuang H,Radia S,et al.The hadoop distributed file system[C].2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST),IEEE,2010:1-10.
[2] Weil S A,Brandt S A,Miller E L,et al.Ceph:a scalable,high-performance distributed file system[C].Proceedings of the 7th Symposium on Operating Systems Design and Implementation(OSDI),USENIX Association,2006:307-320.
[3] Patil S,Gibson G A.Scale and concurrency of GIGA+:file system directories with millions of files[C].USENIX Conference on File and Storage Technologies(FAST),2011:1-14.
[4] Xing J,Xiong J,Sun N,et al.Adaptive and scalable metadata management to support a trillion files[C].Proceedings of the Conference on High Performance Computing Networking,Storage and Analysis(SC).ACM,2009:1-26.
[5] Pawlowski B,Juszczak C,Staubach P,et al.NFS version 3:design and implementation[C].In Proceedings of USENIX Summer,1994:137-152.
[6] Shepler S,Eisler M,Robinson D,et al.Network file system (NFS)version 4 protocol[EB/OL].http://tools.ietf.org/html/rfc3530,2003.
[7] Goodson G,Welch B,Halevy B,et al.NFSv4 pNFS extensions[EB/OL].http://tools.ietf.org/html/draft-ietf-nfsv4-pnfs-00,2005.
[8] Lu Y,Shu J,Li S,et al.Accelerating distributed updates with asynchronous ordered writes in a parallel file system[C].2012 IEEE International Conference on Cluster Computing (CLUSTER),IEEE,2012:302-310.
[9] Ren K,Zheng Q,Patil S,et al.Indexfs:scaling file system metadata performance with stateless caching and bulk insertion[C].International Conference for High Performance Computing,Networking,Storage and Analysis(SC),IEEE,2014:237-248.
[10] Stender J,Kolbeck B,Högqvist M,et al.BabuDB:fast and efficient file system metadata storage[C].2010 International Workshop on Storage Network Architecture and Parallel I/Os (SNAPI),IEEE,2010:51-58.
[11] Josephson W K,Bongo L A,Li K,et al.Dfs:a file system for virtualized flash storage[J].ACM Transactions on Storage (TOS),2010,6(3):85-99.
[12] Lu Y,Shu J,Zheng W.Extending the lifetime of flash-based storage through reducing write amplification from file systems[C].USENIX Conference on File and Storage Technologies(FAST),2013,13:257-270.
[13] Boboila S,Desnoyers P.Write endurance in flash drives:measurements and analysis[C].USENIX Conference on File and Storage Technologies(FAST),2010:115-128.
[14] Lu Y,Shu J,Wang W.ReconFS:a reconstructable file system on flash storage[C].USENIX Conference on File and Storage Technologies(FAST),2014,14:75-88.
[15] Lee C,Sim D,Hwang J Y,et al.F2FS:a new file system for flash storage[C].USENIX Conference on File and Storage Technologies(FAST),2015:273-286.
[16] Zhang J,Shu J,Lu Y.ParaFS:a log-structured file system to exploit the internal parallelism of flash devices[C].2016 USENIX Annual Technical Conference (USENIX ATC),USENIX Association,2016:87-100.
[17] Harter T,Dragga C,Vaughn M,et al.A file is not a file:understanding the I/O behavior of apple desktop applications[C].ACM.Proceedings of the 23rd ACM Symposium on Operating Systems Principles(SOSP),ACM,2011:71-83.
[18] Jeong S,Lee K,Lee S,et al.I/O stack optimization for smartphones[C].USENIX Annual Technical Conference(USENIX ATC),2013:309-320.
[19] Mathur A,Cao M,Bhattacharya S,et al.The new ext4 filesystem:current status and future plans[C].Proceedings of the Linux Symposium(OLS),2007,2:21-33.
[20] Alam S R,El-Harake H N,Howard K,et al.Parallel I/O and the metadata wall[C].Proceedings of the Sixth Workshop on Parallel Data Storage(PDSW),ACM,2011:13-18.
[21] Bent J,Grider G,Kettering B,et al.Storage challenges at los alamos national lab[C].2012 IEEE 28th Symposium on Mass Storage Systems and Technologies (MSST),IEEE,2012:1-5.
