基于本体的媒资知识图谱研究与实现
2018-06-28唐兆琦
唐兆琦
国内的广电文化传媒行业,从20世纪90年代开始逐步实施媒体内容资产的数据库管理,经过20多年的发展和积累,产生了海量的编目和使用信息。如何有效地分析这些“媒资大数据”的内部关系,帮助用户快速准确全面地检索到自己所需要的信息,甚至从知识层面提供关联信息的发掘和推荐等,有着重要的意义和应用前景。
基于知识地图的媒资检索研究能对海量媒资库进行更为智能化的知识管理,从而实现多维度的、自动化的知识整合。该研究在互联网视音频和图文内容呈现爆炸式增长的当下,具有很好的理论研究意义和广泛的应用推广价值。
一、知识图谱技术
(一)知识图谱的定义
知识图谱(Knowledge Graph)最早是由Google推出的产品名称,利用知识图谱可以为查询词赋予丰富的语义信息,建立与现实世界实体的关系,从而帮助用户更快找到所需的信息。在Google之后,Bing、百度、搜狗等搜索引擎公司也都纷纷推出了自己的知识图谱产品。现在,知识图谱已经被用来泛指各种大规模的知识库。
知识图谱旨在描述真实世界中存在的各种实体或概念,以及它们彼此之间的关系或关联。其中,每个实体或概念用一个全局唯一确定的ID来标识,称为它们的标识符(identifier);若干属性-值对(attribute-value pair,又称AVP)用来刻画实体的内在特性;而关系(relation)用来连接两个实体,刻画它们之间的关联。
(二)本体与知识图谱的构建
知识图谱的构建对文本信息处理和信息检索具有重要的价值,而构建知识图谱,就是获取大规模结构化数据并在其中进行实体发现和关系映射的过程。
构建知识图谱有以下七个步骤:
(1)确定本体的专业领域和范畴;
(2)考查复用现有本体的可能性;
(3)列出本体中的重要术语;
(4)定义类和类的等级体系(完善等级体系可行的方法有:自顶向下法、自低向上法和综合法);
(5)定义类的属性;
(6)定义属性的分面;
(7)创建实例。
二、项目技术方案与实施
本文对媒资知识图谱的建立方法是采用“自顶向下”和“自底向上”相结合的方式。其中,自顶向下的方式是通过本体编辑器预先构建本体,它依赖于从媒资百科和结构化数据得到的高质量知识中所提取的模式信息;而自底向上的方式则通过前面介绍的各种实体和关系的抽取技术,将这些置信度高的模式合并到知识图谱中。
(一)定义领域相关的知识本体
本文基于上海广播电视台从二十世纪八十年代至今的媒资内容,尤其是其中的编目信息(侧重在“娱乐”和“体育”这两个领域),建立本体和媒资知识地图。
这些编目信息中的纯文本的标引数据是获取知识图谱的主要数据源。这些文本描述数据需要通过分词、实体抽取技术来分离出其中的实体,借助媒资标引(XML文件)提供的辅助信息和SMG的媒体百科链接信息,从标引的文本描述中抽取实体类型和关系,判别其所对应的本体概念,建立图谱知识库。
本文以媒资库中的编目文件作为实验数据源,它们都是以XML格式保存的。这些以XML格式标注的媒资素材,提供了半结构化的数据,但其中关键的分镜头内容描述基本上为纯文本的数据,因此需要对这些数据通过自然语言处理和文本挖掘的技术进行自动实体抽取、实体对齐,属性值决策,才能获取知识地图所需的实体关系。
对标注数据的信息抽取是本项目的关键问题之一。本文先对XML格式文档进行预处理,包括:去除冗余、重复、不规范的信息;依据现有文档结构获取初始的分类信息;获取待处理的正文主体。
对媒资数据的进一步加工处理方式与基于互联网的搜索引擎对可用数据的处理原则略有不同。互联网上来自于网页的原始数据不仅有标题等,许多还包括各种详尽的内容,而媒资资源的数据内容通常只有标题句或大段的描述文字组成。所以,若直接借鉴互联网公司建立知识图谱模型的方法,会导致出现大量的空关联。因此本文必须在现有媒资编目数据的基础上,统计出常见的、有价值的关联关系,从而建立“可用”的知识图谱。
本文把实体对的上下文中可以用来描述实体之间关系的一般动词和名词称作“特征词”。另外,把特定实体类型在文本库中的高频实体称作种子实体,如经常出现在娱乐资讯中的“章子怡”“成龙”“刘德华”等,即属于人名实体类型的种子实体。种子实体可以用于后续特征词的抽取。
本文首先以实体对类型(如“人名-人名”和“人名-机构名”代表两个不同的实体对类型)为单位,采用基于大规模语料库统计的方法抽取与特定实体对类型相关度较大的候选特征词集;然后,采用启发式通用过滤规则对候选特征词集进行过滤;最后,借助语义词典计算候选特征词之间的相似度,对候选特征词聚类,完成关系类型的自动发现,此时每类即为自动发现的一个关系类型。
具体处理过程如下:
(1)正文抽取:对正文文本素材,取出其中的编目信息中的大段描述文字部分;
(2)文本处理:对原始文本进行断句、中文分词、词性标注、依存句法分析、命名实体识别等底层自然语言处理操作;
(3)特征词抽取:读取句子的处理结果,计算实体出现频率,选取种子实体,进而,从与种子实体形成实体对的句子集中统计抽取特征词集,它们将用于描述实体关系;
(4)特征词聚类:由于不同的特征词可以表达相同的实体关系,所以,进一步利用语义词典计算特征词之间的相似度,通过聚类,得到自动发现的实体关系类型。
(二)知识图谱的生成
通过之前的方法,已从媒资编目的正文文本中抽取构建了知识图谱所需的各种候选实体(概念)及其属性关联,但这些信息是彼此孤立的,为了形成一个真正的知识图谱,需要将这些信息孤岛集成在一起。
其中实体融合的目的在于发现具有不同标识却代表真实世界中同一对象的那些实体,并将这些实体归并为一个具有全局唯一标识的实体对象,然后添加到知识图谱中。
当融合来自不同数据源构成知识图谱时,有一些实体会同时属于两个互斥的类别(如男女)或某个实体所对应的一个属性(如性别)对应多个值,这就是不一致性。由于不一致性的检测要面对大规模的实体及相关事实,纯手工的方法不完全可行。一个简单有效的方法是充分考虑数据源的可靠性以及不同信息在各个数据源中出现的频度等因素来决定,再辅以人工的校对,以决定最终选用哪个类别或哪个属性值。
这里采用的是利用该实体词所出现的上下文的概率,通过大规模语料筛选以及人工校对,对特定的实体词分别定义一些正向词和反向词。例如当成龙作为明星实体词出现时,给它定义的正向词包括成龙曾经出演过的电影名、房祖名(成龙的儿子)、功夫、受伤、公益等与他的工作、生活、社会活动密切相关的词汇,而给它定义的反向词包括望子(望子成龙这个成语的前半部分)、学校、教育等相关的词汇,这样根据与该实体词协同出现的正向词或反向词的概率,就可确定将它映射到哪个实体ID上了。
之后的实体关系抽取则采用前面提到的特征词聚类,以及基于预定义的规则模板匹配的方法来实现。
(三)原型系统描述
在上述研究和实验的基础上,本文开发了基于媒资知识地图的查询应用原型系统(如图1所示),用于展示知识搜索在媒资领域的应用场景。
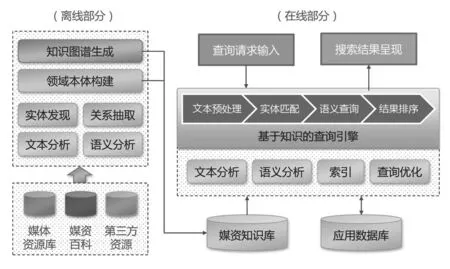
图1:查询应用系统原型的组成结构
大体上,该系统分为“离线”和“在线”两个部分,离线部分主要用于构建领域相关的本体和知识图谱(媒资知识地图),形成媒资知识库,供在线搜索系统使用。
其基础数据来源包括SMG的媒资百科(如人工整理的结构化的词条)、SMG的媒体资源库(如人工编目的媒资内容对应的元数据XML),以及第三方资源(如中文词汇表和文法分析规则库),采用手工或半自动的方法,利用文本分析、语义分析等NLP工具对上述资源进行清洗、预处理和整理,然后通过实体发现、消歧、实体关系抽取等步骤,构建了娱乐领域和体育领域的本体,并进一步生成媒资知识图谱。
在线部分主要实现了基于知识的查询应用原型系统,它采用离线部分生成的媒资知识库,以B/S(Browser/Server)模式运行。其前端采用浏览器界面(HTML5),后端采用J2EE架构实现。
它从PC前端的浏览器接收用户输入的查询请求(可以是短语,也可以是关键词列表),送到后端的知识查询引擎中后,进行必要的预处理(包括NLP文本分析和语法分析),然后在媒资知识图谱(或领域相关本体)中对实体、关系、属性等进行匹配或推理,最后对得到的候选资源(即指向相应词条或媒资编目文件的链接)按相关性进行排序,并输出到结果呈现界面(网页)上。
经过实测统计,该原型系统对于一般的查询请求,均可以在2秒以内返回结果,这其中包括了分析、查询、读取数据库,以及格式化页面等动作。
三、总结与展望
本文在基于本体的媒资地图的研究与实现方面进行了非常有成效的探索,但仍有很多细节有可改进或完善的空间。例如,在构造本体和知识图谱过程中,如何尽可能地提高自动化程度、减少人工干预或校对的工作量,将是非常有意义的工作。
此外,目前个别领域进行了探索,将来可尝试将该方法应用到其它更多的领域,基于更大规模的数据进行建模、应用,并在此过程中发现和改善原方法的不足之处,从规模上、应用效果等方面向实用化更进一步。
