基于CUDA架构的LDPC码并行译码设计与实现
2018-06-19鲁邹晨
鲁邹晨
(中国电子科技集团公司第二十研究所,陕西 西安 710068)
0 引 言
信息在信道中传输时,难免受到噪声和衰落的干扰而出错。随着Shannon在信道编码定理[1]中证明采用信道编码技术能够在噪声干扰的环境中保持信息的高可靠传输,学者们陆续研究了多种有效的信道编码设计方法,其中包括了著名的Turbo码[2]和低密度奇偶校验码(LDPC)码。相较于Turbo码,LDPC码分组误码性能更优,译码算法简单。
随着半导体工艺的发展,高速计算研究理论逐渐兴起,在图形处理器(GPU)强大的并行运算架构下来实现算法加速具有的优越性使其成为可能。LDPC码的Scaled-MSA译码算法中,校验阵H各行(列)并行处理信息,符合采用全并行架构加速的特征。本文采用VS2010标准C编译器和CUDA6.0的集成开发环境,在GPU架构上实现了LDPC码的低时延、高吞吐量译码器,并与CPU译码以及不同线程数、并行度间的译码速度进行了比较。
1 系统开发环境
本文基于CUDA的集成开发环境研究并设计了高速率LDPC码编译码器,其中集成系统的开发环境需要以下支持:可以运行 CUDA平台的显卡和匹配驱动程序,CUDA工具包和C编译器。本文GPU采用GeForce 750Ti处理器,CPU采用Intel i3处理器,操作系统为WinXP。整个编译码系统采用CPU+GPU混合编译,GPU开发环境由NVIDIA公司开发的CUDA6.0提供;而CPU开发环境采用了VS2010中的标准C编译器。
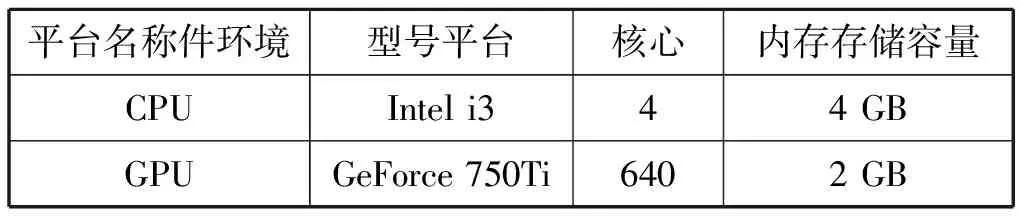
表1 CUDA架构的硬件环境
此款显卡的规格参数如表2所示,GPU并行计算加速比很大程度上依赖于流多处理器的数目和CUDA核心数。设备的显存决定了能存储的资源大小,各Block能够同时运行的最大线程数取决于图像处理器的硬件性能,在研究采用线程数对译码算法的加速能力时,调用线程数不能超过这个值。译码过程中只读不写的常量存储在常量存储器中,共享存储器的存储容量较小但可以显著提高数据的读写速度[3]。

表2 Geforce 750Ti显卡参数表
2 并行归一化MSA译码的CUDA实现
2.1 归一化 MSA译码算法
LDPC码的归一化最小和译码算法,其译码步骤可以划分为以下4项,其中:
M(n)为和第n个变量节点(VN)连接的检验节点(CN)的集合;
M(n)m为集合M(n)中除去m的子集;
N(m)为第m个校验方程中的VN节点集合;
N(m) 为从集合N(m)中去掉n之后的子集;
Lqnm为VN节点外信息;
LLRn为比特n的信道初始值(对数似然比);
Lrmn为VN节点外信息;
lmax为最大迭代次数;
LQn为VN节点n的后验概率;
(1) 对LDPC码的校验矩阵H中的各个非零元素进行初始化。
Lqmn=LLRn=L(xn|yn)=lg(P(xn=0|yn)/
P(xn=1/yn))=2yn/σ2
(1)
式中:0≤m≤M;0≤n≤N。
(2) 对校验节点传送到变量节点的信息进行更新,k为归一化因子。
(2)
αn′m=sign(Lqn′m)
(3)
Φ(x)=tanh(x/2)
(4)
(3) 对变量节点传送到校验节点的信息进行更新。
(5)
(6)

Scaled-MSA译码算法中,消息值在CN和VN之间传递、每次迭代计算译码结果并根据校验方程完成校验的步骤都彼此独立。将这些流程映射为几个独立CUDA核函数,再运行到GPU上利用划分的线程网格就能完成并行加速。编译码系统可简述为:
(1) 在CPU上完成信道初始化;
(2) 将CN节点的更新映射为设备上的一个Kernel函数(即CNP核),为该核在设备上分配一个对应GPU网格Grid1;
(3) 同样将VN节点的更新映射为VNP核,再为其分配一个对应网格Grid2;
(4) 尝试译码判决。
GPU并行译码包括GPU初始化、线程资源声明、核函数定义及运行。为了优化编译码系统的处理效率,应该减少PCIE总线非必需的信息传输,主机CPU和设备GPU间只传输初始化后的对数似然比值和硬判结果。其它变量由GPU核函数访问,无需在CPU和GPU间传输,例如Lrmn。
GPU初始化时完成内存分配和参数传递。QC-LDPC码的H矩阵高度结构化,可分为多个Z×Z子阵,有3种类型:全零阵、单位阵和单位移位阵。在GPU的Constant memory中为校验阵分配内存并以一种压缩形态存储,仅用4个字节实现矩阵元素的存储,有效节省了编译码系统的存储资源和访问效率。前两字节分别表示行标值和列标值,第3字节代表矩阵相对单位阵的移位值,末尾字节表征当前元素是否为0。
再调用函数cudaMemcpy()把信道初始化对数似然比(LLR)值传到GPU中:
cudaMemcpy(dev_lratio,lratio,sizeof(double),cudaMemcpyHostToDevice);
核函数CNP(VNP)中的线程和线程块的索引ID不需要初始化,值按自然数顺序递增。线程网格的Block数和CN节点(VN节点)数目有关;线程块的线程数和校验阵的行列重有关。各线程根据blockId和threadId计算对应H阵中元素的地址。
调用GPU的Grid和Block前先进行配置和声明:
dim3 dimBlock(x1,y1,1)
声明Block大小为x1×y1, CN节点处理的CNP中Block的大小设定为校验矩阵H的行重,满足各线程并行处理矩阵中的信息。
接下来是内核函数的执行:
CNP《
《<》>为Kernel函数执行符,尖括号内依次为Grid内的Block数目、Block内的Thread数量,()里面包含了CNP函数的参数。
LDPC码的编译码耗时和译码算法复杂度有较强关联,完成迭代译码步骤耗费的时延在系统总耗时中占了较大比重。传统CPU平台只能顺序、串行译码,而配置足够的GPU线程资源完成的LDPC码高速并行译码,在不改变Scaled-MSA译码算法的工作原理的前提下,却能以协同处理的方式利用设备丰富的计算资源,并行、高效完成译码,能够带来译码时延的显著减少。
2.2 仿真模型

图1 LDPC码编译码的仿真系统模型
2.3 译码器的CUDA实现
基于CUDA架构实现的译码器如图2所示,共包含以下处理流程:
初始化:在GPU上开辟内存并对校验(变量)节点赋初值,另开辟内存完成校验矩阵的存储。H矩阵的元素都是常量,利用constantmemory能够显著优化访问时延。信息比特经编码和调制后进入信道,加噪后的接收值从CPU上传递到GPU上。
译码过程中, CNP和VNP 2个核函数采用各自线程网格并行处理:
CNP核:每次迭代时,根据校验矩阵H每一行关联的VN节点对CN节点更新,各GPU线程选择相关VN节点信息并独立计算,再将结果回传CN节点。本文研究的码率为二分之一的(1 024,512)LDPC码,其H矩阵行重为6,即每个CN节点将与6个VN节点连接。那么对于各个CN节点,都可以分配设备的一个线程块进行运算处理,这个线程块内应至少包含6个thread。
VNP核: 在CN节点消息值更新后,校验阵H每列关联的CN节点对VN节点更新,译码迭代完成后进行判决。
译码结果回传:判决后的结果从设备GPU返回主机CPU,并释放在设备上开辟的内存资源。
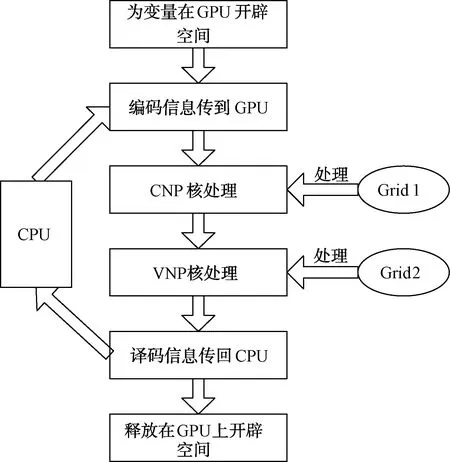
图2 基于CUDA的LDPC并行译码器的实现框图
2.4 并行译码的速度分析
统计CPU平台译码耗时使用clock()函数, GPU平台统计译码耗时能利用CUDA API中的事件管理函数来测量。
本文测试并行度对译码时间影响时分为4种方案。方案一在GPU上执行CN节点的处理,VN的处理在CPU上完成;方案二在CPU上对校验节点的更新进行处理, 变量节点运算在设备上进行;方案三将CN和VN的处理都放到了GPU来并行加速,方案四是原始的CPU串行译码方案。仿真使用的(1 024,512)LDPC码测试总帧数为10 000帧,采用BPSK的调制方式, 模拟信道的信噪比设置为3.0 dB,GPU分配的总线程数为256个。
采用CUDA架构并行译码方式的几种方案,虽然译码速率加速比的大小不同,但对比CPU平台的串行译码均取得明显加速,如图3所示。仅采用GPU线程资源支持CN节点并行处理或者仅对VN并行处理,加速比提升均不显著,为2.5倍左右;若采用行列全并行的译码方案,则获得大约7倍的译码速度提升。

图3 不同并行度方案的加速分析
2.5 采用不同线程数量的加速分析
在表1所示的实验平台上,对经过模拟的加性高斯白噪声信道传输,采用CUDA并行译码的LDPC码译码耗时进行统计。LDPC码测试帧数目为10 000帧,采用BPSK调制方式,模拟噪声信道的信噪比设置为3.0 dB。
并行译码时,采用不同数量的线程来比较译码加速效果的区别。从图4不难看出分配的GPU线程数对译码速度有明显的影响。当分配的设备线程较少时,译码速度可能要慢于CPU平台的串行译码,可见调用的GPU线程不足时,译码时带来的加速十分有限。随着为LDPC码译码分配的GPU线程资源的增加,CUDA高速率并行译码的加速特性逐渐明显。分配的线程数目在一定范围内变化时,译码速度与调用GPU线程数近似成线性增长。
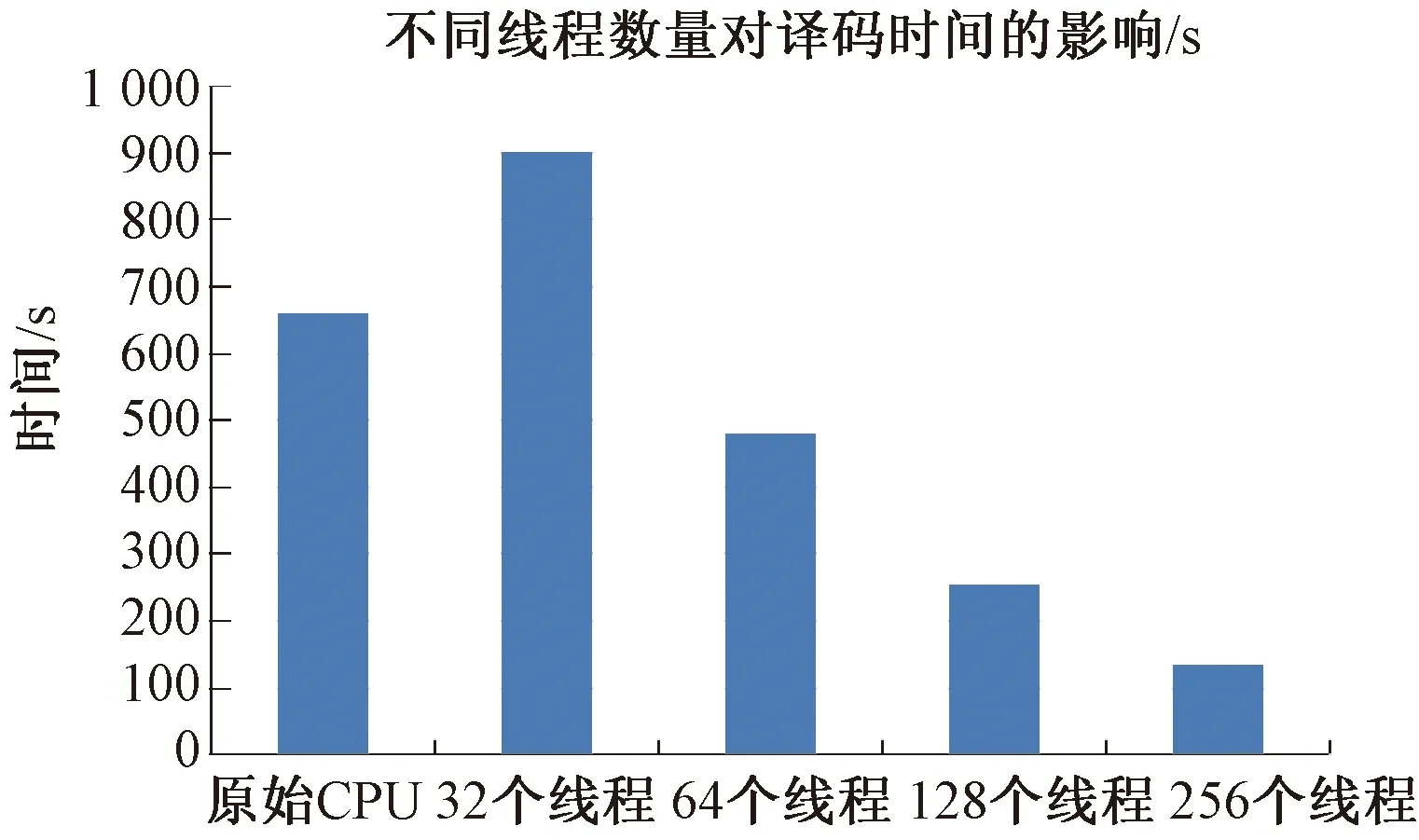
图4 采用不同线程数量的加速分析
3 结束语
结合本文对编译码系统译码速度性能决定因素的研究,不难发现:在设计基于GPU平台的LDPC码的高速编译码器系统时,合理利用CUDA架构下各存储器的访存特性,增加译码算法中各环节对图像处理器并行运算单元的利用度,尽可能利用更多数量的GPU线程对码字并行译码,就能最大限度减少编译码的访存时延,进而提升系统吞吐量。
[1] SHANNON C E.A mathematical theory of communication [J].Bell System Technical Journal,1948,27(3):379-423.
[2] BERROU C,GLAVIEUX A,THITIMAJSHIMA P.Near Shannon limit error-correcting coding and decoding:Turbo-Codes[C]//Proceedings of ICC 1993,Geneva,Switzerland,1993:1064-1070.
[3] WANG S,CHENG S,WU Q.A parallel decoding algorithm of LDPC codes using CUDA[C]//Signals,Systems and Computers,2008 42nd Asilomar Conference,2008:172-174.
