基于节点特征的不确定图社交网络隐私保护方法
2018-06-15田堉攀
颜 军 胡 静 温 阁 田堉攀
1(商洛学院数计学院 陕西商洛 726000) 2 (陕西师范大学计算机学院 西安 710119) (yanrongjunde@snnu.edu.cn)
随着互联网技术的日益普及,互联网应用从深度和广度上不断扩展,现在基于互联网的办公、娱乐、购物、教育等活动已经深入到人们日常生活中.互联网不仅仅提高了人们的生活质量和工作效率,更重要的是改变了人们的思维方式.
中国互联网络信息中心(China Internet Network Information Center) 2018年发布了《第41次中国互联网络发展状况统计报告》,截至 2017 年 12 月,我国网民规模达到 7.72 亿,普及率达到55.8%.当前互联网手机网民占比达 97.5%,截至 2017 年 12 月我国手机网民规模达 7.53 亿[1].这些数据显示当前移动互联网占据了互联网的主导地位.
伴随着移动互联网的发展和普及,社交网络与人们日常生活越来越紧密.社交网络也就是网络+社交,它涵盖以人们社交为核心的所有网络服务形式.通过社交网络把人们连接起来,从而形成具有某一特点的团体,最终社交网络逐渐成为一个人们社交的工具.截至2017年6月,中国网络用户使用率排名前3的社交应用均属于综合类社交应用.微信朋友圈、QQ空间用户使用率分别为84.3%和65.8%;微博用户使用率达38.7%[1].2018年3月5日,在十三届全国人大一次会议首场“代表通道”集中采访中,腾讯公司董事会主席兼首席执行官马化腾在接受记者提问时透露,在刚刚过去的2018年春节,微信和WeChat的合并月活跃账户数超过10亿.据美国市场研究公司eMarketer估计,2017年全球有13的人正在使用社交网络,总数达到了惊人的24.8亿[2].
有了社交网络这个平台,越来越多的社交网络用户将个人相关信息上传到个人空间,朋友们之间可以分享这些信息,以了解彼此的生活状况.随着社交网络与人们的日常生活密切相关,基于社交网络的移动支付已经成为一种主要的交易方式.在中国,基于微信的移动支付已经成为一种基本的交易方式.当人们在社交网络上获得乐趣时,当通过社交网络享受各种便利时,用户大量与隐私信息密切相关的数据都保留在了网络.
据搜狐科技报道,暗网供应商 “双旗(DoubleFlag)”利用黑客技术,窃取了数家中国互联网巨头的大量数据.这些数据属于以下公司:网易及其下属的126.com,163.com和Yeah.net;拥有QQ.com的腾讯控股.在2016年十大数据泄露事件中社交网络成重灾区[3].当大量用户在社交网络上的信息被发布,而且这些信息包括了网上交易、个人信息等敏感信息,如果其他非法用户对这些数据进行整理、挖掘、分析,窃取用户的隐私信息,从而用户的隐私会受到威胁.因此,如果对社交网络的数据实施隐私保护后再发布,恶意用户将不能挖掘到用户的隐私信息,极大地限制了利用隐私信息进行的非法活动.
当前对于社交网络的隐私保护显然存在严重的不足,因此社交网络的隐私保护研究越来越受到关注[4].与传统关系型数据的隐私保护方法不同,社交网络的隐私保护不仅要保护每个社交网络个体的属性,又要保护个体间的关系.为此将社交网络抽象成图,用节点表示社交网络的个体,个体之间的关系用边来表示,个体间关系的紧密程度用对边进行加权重来表示[5].当社交网络被抽象为图结构后,可以通过对图结构的隐私保护来实现社交网络的隐私保护.
在社交网络隐私保护的图修改方法中,不确定图是一种有效的保护方法.与基本的不确定图方法不同,本文提出了基于节点特征的不确定图隐私保护方法.通过实验证实,该方法不仅能够实现社交网络的隐私保护,而且具有较好的数据效用.
1 相关工作
目前,在社交网络隐私保护中图修改方法是一重要方法,包括点边修改、聚类[6]、不确定图.点边修改方法分为随机修改[7-8]和限定修改[9-10]2种方法.
与常用的图修改方法相比较,不确定图方法是当前一种新的隐私保护方法.不确定图方法的主要原理是将不确定性注入到社交网络图的边中,发布经混淆后的不确定图来达到隐私保护目的.通过为图中的边分配概率值,该方法既能实现隐私保护,又能对原图数据改变较小,保持了较高的原图数据的效用.
Boldi等人[11]首次提出了(k,ε)混淆算法,该方法能够抗击对顶点身份攻击,而且能满足图结构数据的最小化失真;文献[12]指出,Mittal等人利用随机游走的方法生成不确定图,得到的不确定图能够防止基于链接攻击;为了提高不确定图中边的概率分配的效率,Nguyen等人[13]提出了基于最大化方差的方法来提高数据效用;Nguyen等人[14]将邻接矩阵UAM引入到方差最大化算法中,提出了不确定方法的通用匿名模型.
然而真实的社交网络是一个复杂网络,而复杂网络中各个节点在网络中位置不同、连接关系不同、在网络动态变化时相互影响的程度不同[15],因此需要考虑网络结构中节点的特征以实现更有效的隐私保护.为此本文的方法通过对网络特征的分析,确定网络中关键位置的节点,结合不确定图方法实现基于重要节点的隐私保护.
2 基础知识
在本文中,我们将社交网络抽象为一个无向无权重的简单图G=(V,E),V表示网络所有节点的集合,E表示网络所有边的集合,我们用(i,j)表示节点Vi到Vj的边,DVi表示节点Vi的度数.
2.1 不确定图
定义1. 不确定图.
给定一个图G={V,E},如果映射p:Vp→[0,1]是边集合中每条边存在的概率函数,那么图G′={V,Ep}是关于图G={V,E}的不确定图,其中Vp表示集合V中所有可能的顶点对,即Vp={(i,j)|1≤i≤j≤n}.
2.2 网络节点的中心性
中心性定义了网络中一个节点的重要性.在社交网络中,也就是谁是中心角色.度中心性(degree centrality)描述了节点在社交网络的重要程度.
定义2. 在无向图中,节点Vi的度中心性是:CD(i)=DVi=∑aij,其中当节点i与节点j连接时,aij=1.
3 方法设计
社交网络中节点特征对于理解和分析网络拓扑结构具有重要的作用.节点中心性是一种常用度量节点特征的方法,节点中心性的度量值越大,表示该节点在网络中影响力也越高.在社交网络的隐私保护中,这些重要的网络节点也应该成为隐私保护的重点,因此,我们提出了基于网络节点特征的不确定图隐私保护方法,如图1所示:

图1 基于节点特征的不确定图隐私保护方法模型
3.1 模型设计
该方法首先分析社交网络的节点特征,计算所有节点度中心性的度量值,根据度量值的大小进行节点排序,然后选择出度量值大的节点,将这些节点作为网络的重要节点.以重要节点为核心,在网络中通过边修改方法对网络进行修改,对于修改后的网络,给选择的边赋概率值,最终得到不确定图.
3.2 算法设计
算法1. 重要节点选择算法.
输入:原图G={V,E}、节点集合V、边数集合E.
输出:重要节点集合VH.
① 计算所有节点的度中心性的数值;
② 节点根据数值排序;
③ 选取前10%的节点并计算所有节点的度数和;
④ 判断度数和是否大于社交网络边数和的80%;
⑤ 如果满足条件,则输出重要节点集合VH;
⑥ 如果不满足条件,则返回③,再增加选取的节点,继续判断.
算法2. 不确定图生成算法.
输入:原图G={V,E}、节点集合V、边数集合E、重要节点集合VH.
输出:不确定图G′={V,EP}.
① 任选重要节点集合中一节点;
② 以该节点为中心,选取该节点的所有相邻节点;
③ 判断相邻节点是否相连,如果没相连则2点间加边;
④ 选取加边构成的所有三角形;
⑤ 选择出没有公共边的三角形;
⑥ 在该三角形中每条边赋概率值;
⑦ 循环执行以上步骤,对所有重要节点完成操作;
⑧ 得到不确定图G′.
4 实验分析
4.1 实验数据集
实验中的数据集有2种:一种为合成的数据集;一种为真实数据集.合成数据集分别为拥有300和600个节点,连接概率为0.5的随机网络图,进行10次实验操作后取平均值.真实数据集是karate和dolphin俱乐部数据集.
4.2 隐私保护度量
依据香农定律,信息熵值的大小反映了系统不确定性的大小.当我们将社交网络图转换为不确定图时,由于不确定图的边具有很强的不确定性,因此很难从不确定图找出原图.为了度量隐私保护的效果,我们引入了边熵,使用边熵来衡量不确定图的不确定性,即不确定图的隐私保护程度.
不确定图的边熵定义如以下公式所示:

Ente是不确定图的边熵值,该数值越大,表示不确定图的不确定性越大,同时对应隐私保护方法的隐私保护效果越好.
4.3 数据效用度量
NE表示图中边的个数,AD表示图中节点的平均度,DV表示图中节点的度方差,NE′表示不确定图中边的个数,AD′表示不确定图中节点的平均度.
在社交网络中,我们用d1,d2,…,dv来表示社交网络中节点度的序列.不确定图中节点的度等于节点的期望度,即任意的节点v∈V,节点v的期望度是与它相连的边的概率之和.
4.4 结果分析
基于节点特征的不确定图方法在生成不确定图的过程中,先选择重要节点,以这些重要节点为核心进行邻接点加边,然后再对筛选得到的三角形边赋概率值.m为生成不确定图的过程中总共添加的边数,c为调节加边数的因子,实际添加的边数为m·c.在表1中,添加的边数增加,生成的不确定图的边熵值不断增长,这说明达到的隐私保护效果越来越好,同时证明了该方法能够实现隐私保护.
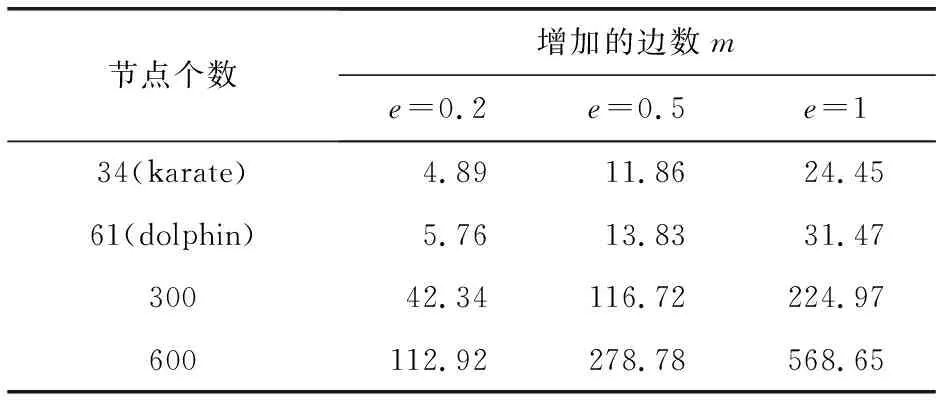
表1 基于节点特征不确定图方法中边熵变化情况
为了直观地衡量隐私保护的效果,我们将本文中的方法与 (k,ε)混淆算法进行了对比,表2为(k,ε)混淆算法中边熵的变化情况.主要参数即混淆级别k的取值分别为10和20,其他参数分别为:ε=0.1,e=1,q=0.01.

表2 (k,ε)-混淆算法中边熵变化情况
通过表1可知本文的方法能够可以达到较好的隐私保护效果.对比表1和表2的隐私保护效果度量数值,当网络较小时,本文算法的保护强度优于(k,ε)混淆算法.随着网络规模增大,(k,ε)混淆算法优于本文算法.
在表3中,将基于节点特征的不确定图方法得到的不确定图与原图比较,度量指标NE与NE′、AD与AD′之间数值变化较小,这表明由于对原图修改较少,该方法的数据效用性较好.与原图对比,在不确定图中度量指标DV的数值明显增大,这说明在生成不确定图之后节点的度发生了变化.表4记录了不同k值的(k,ε)混淆算法的数据效用度量值.比较表3和表4的数据效用度量数值,表4中的数据效用度量指标与原图相比变化较大,这表明基于节点特征的不确定图方法的数据效用优于(k,ε)混淆算法.
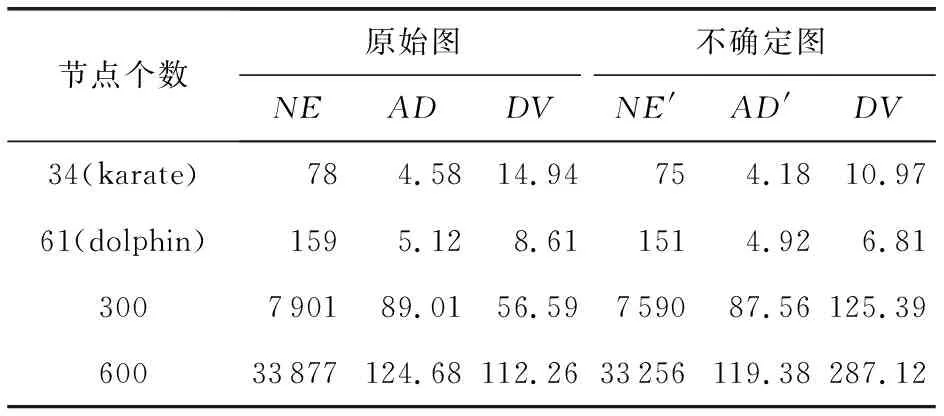
表3 原始图与本文方法生成的不确定图的数据
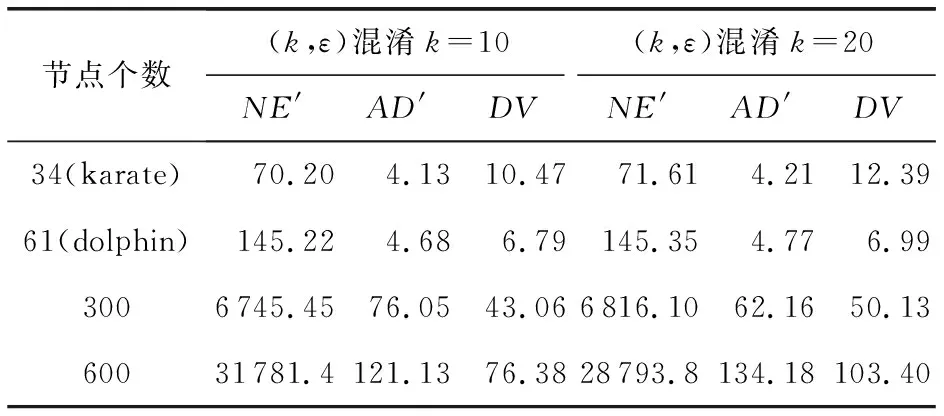
表4 (k,ε) -混淆算法中不同k值的数据效用性对比
5 结论与展望
本文方法在实现隐私保护时,通过节点的度中心性选择出重要节点,以这些重要节点为核心,结合不确定图方法实现了社交网络的隐私保护.经过各种数据集的实验验证,基于节点特征的不确定图方法不仅能够实现社交网络隐私保护,而且与(k,ε)混淆算法相比具有较好的数据效用.
虽然本文方法实现了社交网络的隐私保护,但还需要在保持数据效用的前提下,研究进一步提高隐私保护的效果.
[1]中国互联网信息中心. 第41次《中国互联网络发展状况统计报告》发布[EBOL]. [2018-03-20]. http:www.cnnic.net.cngywmxwzxrdxw201801t20180131_70188.htm
[2]eMarketer. 2017年全球社交网络用户达24.8亿[EBOL]. [2018-03-20]. http:www.199it.comarchives678247.html
[3]Hely. 2016年十大数据泄露事件: 社交网络成泄露重灾区[EBOL]. [2018-03-20]. http:www.raincent.comcontent-10-8087-2.html
[4]刘向宇, 王斌, 杨晓春. 社会网络数据发布隐私保护技术综述[J]. 软件学报, 2014, 25(3): 576-590
[5]Casas-Roma J, Herrera-Joancomartí J, Torra V. A survey of graph modification techniques for privacy-preserving on networks[J]. Artificial Intelligence Review, 2017, 47(3): 341-366
[6]Campan A, Truta T M. Data and structuralk-anonymity in social networks[C]Proc of Privacy, Security, and Trust in KDD. Berlin: Springer, 2009: 33-54
[7]Ying X, Wu X. Randomizing social networks: A spectrum preserving approach[C]Proc of the Data Mining, Society for Industrial and Applied Mathematics. Philadelphia: SIAM, 2008: 739-750
[8]Ying X, Pan K, Wu X, et al. Comparisons of rando-mization andk-degree anonymization schemes for privacy preserving social network publishing[C]Proc of the 3rd Workshop on Social Network Mining and Analysis. New York: ACM, 2009: 1-10
[9]Zou L, Chen L, Özsu M T. K-automorphism: A general framework for privacy preserving network publication[J]. Proceedings of the VLDB Endowment, 2009, 2(1): 946-957
[10]Casas-Roma J, Herrera-Joancomartí J, Torra V.k-Degree anonymity and edge selection: Improving data utility in large networks [J]. Knowledge and Information Systems, 2017, 50(2): 447-474
[11]Boldi P, Bonchi F, Gionis A, et al. Injecting uncertainty in graphs for identity obfuscation[J]. Proceedings of the VLDB Endowment, 2012, 5(11): 1376-1387
[12]Nguyen H H, Imine A, Rusinowitch M. A maximum variance approach for graph anonymization[C]Proc of Int Symp on Foundations and Practice of Security. Berlin: Springer, 2014: 49-64
[13]Nguyen H H, Imine A, Rusinowitch M. Anonymizing social graphs via uncertainty semantics[C]Proc of the 10th ACM Symp on Information, Computer and Communi-cations Security. New York: ACM, 2015: 495-506
[14]Zhang Xiaohang. Identifying influential nodes in complex networks with community structure[J]. Knowledge-Based Systems, 2013, 42(2): 74-84
[15]Liu Y, Tang M, Zhou T, et al. Identitfy influential spreaders in complex networks, the role of neighborhood[J]. Physica a Statistical Mechanics & Its Applications, 2016 (3): 289-298
