大数据平台下的电力负荷预测系统设计与实现
2018-06-12郑凯文
夏 博,杨 超,郑凯文
(贵州大学电气工程学院,贵州 贵阳 550025)
0 引言
随着常规电力系统向智能电网的逐步发展,电力系统中使用了大量的传感器和智能设备,使得需要处理的各类数据呈指数级增长。数据存储规模将增长到TB级,甚至PB级[1]。而电力系统负荷预测的误差大小直接影响发供电计划的制定、电网的供需平衡以及电力市场的平稳运行[2-3]。现有的预测方法中,数据挖掘法[4]、小波分析法[5]、近似熵法[6]等都具有较好的预测精度,但是在处理海量数据方面还存在很大的不足。文献[7]提出了调和分类-聚类的负荷预测模型,能够较好地对大量数据进行分析处理并且提高预测的精度。文献[8]提出了适用于智能电网大数据环境下的预测方法,能够有效提高负荷预测的速度与精度。文献[9]分析了电力大数据的相关特征,介绍了正在研发的智能电网大数据分析系统。
针对上述问题,本文提出了基于Gradient Boosting思想和Shrinkage思想的Xgboost算法负荷预测模型,并通过负荷预测试验分析验证了该算法的有效性。
1 极端梯度上升算法
Xgboost是基于梯度提升决策树(gradient boosting decision tree,GBDT)提出的算法[10]。Xgboost可以使用CPU多线程进行并行计算,并对目标函数进行二阶泰勒展开,在目标函数之外加入正则项整体求最优解。
对于一个给定预测模型,需要通过目标函数来寻找最优参数。一般的目标函数模型为:
Obj(θ)=L(θ)+Ω(θ)
(1)
式中:L(θ)为误差函数,表示模型拟合数据的程度;Ω(θ)为正则化项,表示惩罚复杂的模型。
为了防止过拟合,Xgboost除了目标函数正则化项,还引入了用于GBDT的缩减和用于随机森林(random forest,RF)的列抽样,以防止过拟合。其中,缩减认为残差仍然是其学习目标,而且各个树的残差是渐变的;而列抽样则是对样本的特征量进行随机抽样计算,从而减少了工作量。
分类回归树中的回归树是提升树最基本的组成部分,但是单棵决策树往往不能有效而精确地作出预测。而由多棵决策树组成的决策树森林模型是一个有效而精准的模型。决策树森林模型公式为:
(2)
式中:F为所有回归树集合;f为一个在函数空间F里的一个函数;xi为数据i的特征向量。
目标函数需要遵循的主要原则为:
(3)

参数采用加和策略的方式来训练,通常面对不是平方误差的时候,可以使用泰勒展开来定义一个近似的目标函数,并对这一步计算进行简化,即除去常数项,进而会发现目标函数仅仅取决于每个数据点在误差函数上的一阶导数和二阶导数。简化后目标函数为:
(4)
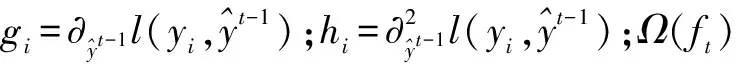
(5)

(6)

Xgboost单棵决策树训练流程如图1所示。
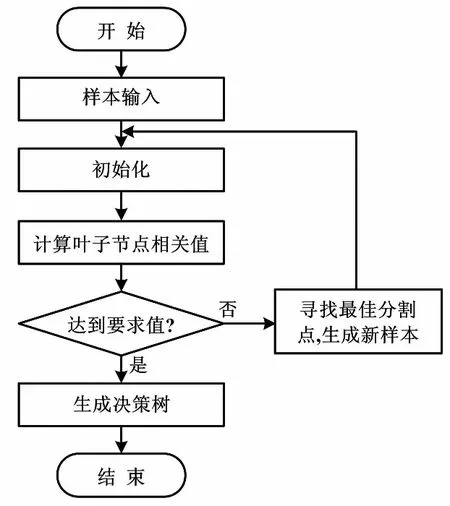
图1 单棵决策树训练流程图Fig.1 Training flowchart of single decision tree
整个Xgboost算法决策树迭代流程如图2所示。
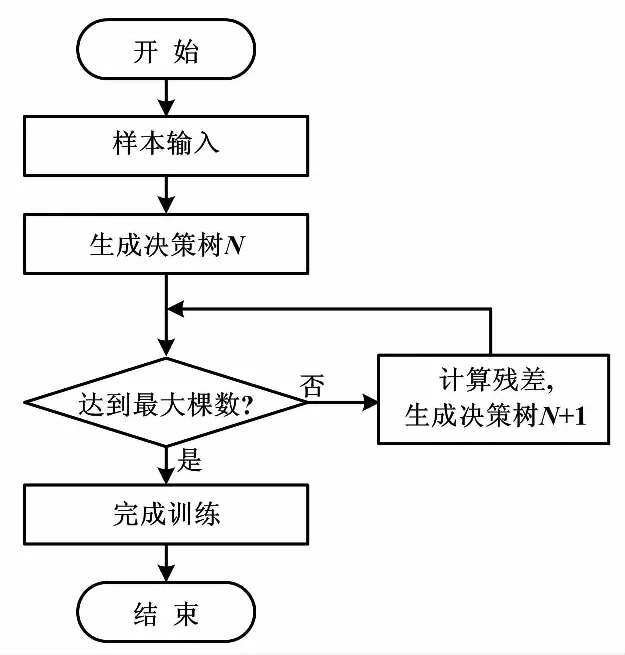
图2 决策树迭代流程图Fig.2 Iterative flowchart of decision tree
2 大数据平台实现
2.1 MapReduce
MapReduce是Hadoop的核心组件之一,是一种数据处理的编程框架。MapReduce采用“分而治之”的办法。首先,各个节点处理其分得的数据集,再整合节点的处理结果得到最终结果。在分布式计算中,MapReduce框架负责处理并行编程中一些相对复杂问题,把处理过程高度抽象为map和reduce两个函数。map可以对操作进行分解,reduce则是要综合各个结果。
2.2 MapReduce架构
与Hadoop分布式文件系统(Hadoop distributed file system,HDFS)一样,MapReduce采用了主从结构模型,主要由Client、JobTracker、TaskTracker和Task四个部分组成。
Client 客户端:每一项任务都会将应用程序和所要配置的相关参数打包处理后再存储到HDFS,并将路径提交到JobTracker的master服务中,然后由master创建每一个Task(即MapTask和 ReduceTask),并将它们分发到各个TaskTracker 服务中去执行。在Hadoop中,依据自己的需求对调度器进行设计。
TaskTracker 定期将自己节点情况汇报给JobTracker,并且接受反馈的命令,然后执行相应的操作。TaskTracker使用“slot”等量划分本节点上的资源量。“slot”代表计算资源(CPU、内存等)。调度器可以把每个TaskTracker上空闲的slot分配给Task使用。slot分为Map slot和Reduce slot两种,分别供MapTask和ReduceTask使用。可配置参数又能够对Task的并发度进行限定。
Task分为MapTask和ReduceTask 两种,均由TaskTracker启动。采用map函数对输入的信息进行处理,并且把中间结果存储到本地磁盘上,临时数据会被分成若干个partition,每个partition对应一个ReduceTask。ReduceTask从节点上读取MapTask中间结果;按照key对key/value进行排序;调用reduce函数,将结果保存到HDFS上。
2.3 Hadoop平台搭建及Xgboost部署
本次试验通过虚拟机虚拟3台主机进行数据处理。其中1台作为主节点Master,另外2台作为分节点Node1、Node2。每台主机配置为4核处理器,3G内存并安装CentOS 6.5系统作为基础环境。构建的Hadoop集群拓扑示意图如图3所示。
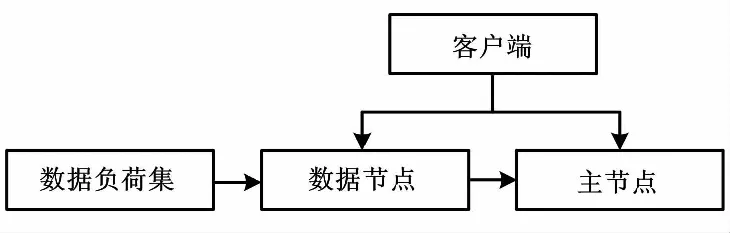
图3 Hadoop集群拓扑示意图Fig.3 Schematic diagram of Hadoop cluster topology
在CentOS 6.5系统中创建Hadoop账户,并赋予Hadoop账户管理员权限,通过修改hosts为主节点和从节点配置IP地址,然后配置ssh使各节点间实现密码登录,完成后各台机器之间可以直接通过ssh+机器名进行访问。
Spark安装成功后,将Xgbooost克隆到本地并进行编译。编译成功后通过指令以yarn模式启动spark-shell,并引用Xgboost包。将训练数据及相应参数输入Xgboost后运行,至此Xgboost算法基于Spark的分布式计算部署成功。
3 负荷预测试验及结果分析
试验采用平均绝对百分比误差 (mean absolute percentage error,MAPE) 和均方根误差(root mean squared error,RMSE),公式如下:
(7)
(8)
式中:Xi为实际负荷值;Yi为预测负荷值;n为负荷预测结果的个数。
在负荷预测中,MAPE越小,负荷预测结果就越准确。RMSE越小,则负荷预测结果的精度就越高。
本次预测的数据来源于某省M县2013年1月1日至2016年9月30日:每5 min采集一次的负荷数据,共计368 640条数据;以及对应日期的天气数据,如最高气温、平均气温等共计10 240条数据。短期负荷受天气、时间、日期等因素的影响而出现波动。这些因素都为负荷特性分析提出了挑战。分析这些因素与负荷之间的互相关系,有利于负荷预测模型特征的建立。
选择2016年6月1日至2016年8月24日的日最大负荷值作为训练数据,预测2016年8月25日至2016年8月31日的日最大负荷值。同时,选取上星期同日的日最大负荷值、上月同日的日最大负荷值、当日最高气温、当日平均气温、当日是否为工作日等数据,构成预测数据的特征。其中:上星期同日的日最大负荷值、上月同日的日最大负荷值、当日最高气温、当日平均气温的特征值均为具体真实的数值;当日是否为工作日用0、1表示,0表示当日为非工作日、1表示当日为工作日。训练数据及特征如表1所示。

表1 训练数据及特征Tab.1 Training data and features
分布式Xgboost算法成功运行后,将单机版Xgboost算法所采用的样本重新输入分布式Xgboost算法进行预测。夏季和冬季的分布式预测结果MAPE和RMSE对比如表2所示。
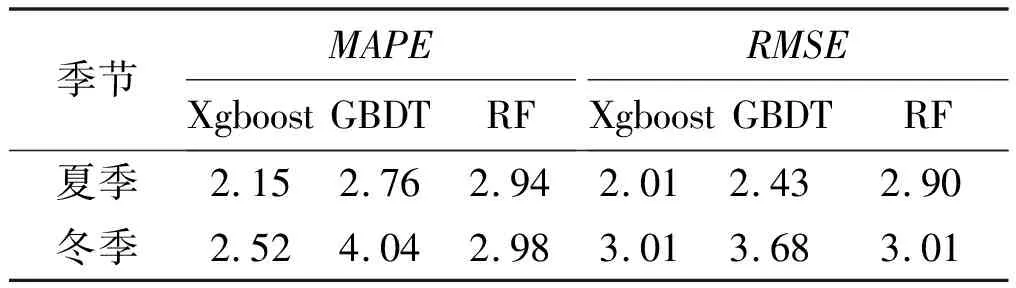
表2 MAPE和RMSE的对比Tab.2 Comparison between MAPE and RMSE
从表2可以看出,Xgboost算法预测精度略高于其他两个算法。由于样本量大,各算法训练速度出现较大差异,考虑计算过程中相关因素对结果造成的影响,经过多次训练求平均值,结果见表3。
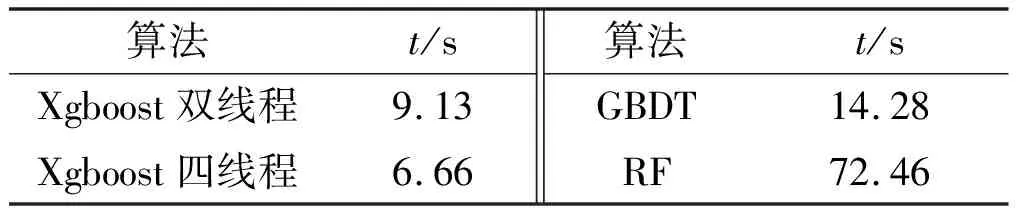
表3 算法训练速度对比Tab.3 Comparison of the training speed
分布式Xgboost采用的是分布式加权值算法。在数据无法一次载入内存或在分布式情况下,该方法可以高效地生成候选的分割点。
从表3可以看出,RF训练模型的时间比其他两个算法训练时间多,这是由于RF需要多次随机抽取特征,导致训练时间增加。Xgboost开启多线程模式后,训练速度相对于其他算法有较大的优势。
平台首先通过将负荷数据、气象数据以及其他特征由客户端输入;然后,将对应的数据进行分块,分给两台机器进行处理,并将各台所处理得到的结果汇总到主机上得到整体的预测模型;最后,可以通过测试数据的输入进行相关的负荷预测工作。
4 结束语
本文针对电力系统负荷预测所用的预测方法不能快速、有效地训练大量数据样本,也不能有效地利用历史数据这些问题,提出了基于Gradient Boosting思想和Shrinkage思想的Xgboost算法负荷预测模型。通过对某省M县实际负荷数据特性分析,构建了基于负荷的时间特性、温度特性的训练样本,并分别进行了夏季、冬季情况下的负荷预测,同时与RF和GBDT两种算法进行对比。预测试验对比验证了Xgboost算法具有准确性好、训练速度快等特点,且在开启多线程的情况下,Xgboost算法有更明显的速度提升。
参考文献:
[1] 李龙,魏靖, 黎灿兵, 等.基于人工神经网络的负荷模型预测[J].电工技术学报, 2015, 30(8): 225-230.
[2] 杨甲甲,赵俊华,文福拴,等.电力零售核心业务架构与购售电决策[J].电力系统自动化,2017,41(14):10-18.
[3] 廖旎焕,胡智宏,马莹莹,等.电力系统短期负荷预测方法综述[J].电力系统保护与控制,2011,39(1):147-152.
[4] 李黎,杨升峰,邱金鹏,等.电力系统供电短期负荷预测方法仿真研究[J].计算机仿真,2017,34(1):104-108.
[5] 姚李孝,刘学琴.基于小波分析的月度负荷组合预测[J].电网技术,2007,31(19):65-68.
[6] 杨茂,董骏城,罗芫,等.基于近似熵的电力系统负荷预测误差分析[J].电力系统保护与控制,2016,44(23):24-29.
[7] 窦全胜,史忠植,姜平,等.调和聚类-分类方法在电力负荷预测中的应用[J].计算机学报,2012,35(12):2645-2651.
[8] 于希宁,牛成林,李建强.基于决策树和专家系统的短期电力负荷预测系统[J].华北电力大学学报,2005,32(5):57-61.
[9] 刘广一,朱文东,陈金祥,等.智能电网大数据的特点、应用场景与分析平台[J].南方电网技术,2016,10(5):102-110.
[10]CHEN T,GUESTRIN C.Xgboost:A scalable tree boosting system[C]//Proceedings of the 22Nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.ACM,2016:785-794.
