基于MatlabGUI的语音感知照明系统仿真设计
2018-06-11刘鹏辉房建东
刘鹏辉,房建东
(内蒙古工业大学内蒙古呼和浩特010080)
近年来,语音识别理论研究飞速发展,其相应的现实应用大大提高了人们的工作效率和生活质量[1]。语音技术的广泛应用是移动互联网条件下各种平台的核心应用,在微信公开平台催生的语音生态圈情况下,抓住这一机遇,以用户需求为导向,将语音应用在更加广阔的应用中,催生更多更好的应用场景。语音模式识别分为两种情况,一种是实时语义转化为文字,另一种是将语音命令识别出来,去执行指令内容,控制关联载体。本文以语音感知识别为理论基础,通过与模式识别相结合的方式将其应用到家居照明系统控制领域,实现对特定语音信号自动识别,并且自动关联照明模拟图像效果,通过仿真实验论证了方法的可靠性及正确性。
语音识别算法有很多种,DTW是一种小词汇量,孤立词语音识别的相对成熟,它是把时间规整和间距量计算连接在一起的非线性动态规划算法,相对比较简单而且有效[2]。本文以语音感知识别为基础,通过与模式识别相结合的方式将其应用到家居照明的模拟控制领域,实现对语音信号进行识别并自动控制照明系统,具有一定的使用价值。
1 仿真界面的设计与实现
1.1 GUI设计方法
Matlab GUI界面的设计方法有两种,一是直接编写.m文件来开发整个GUI;二是通过Matlab图形用户界面开发环境duide命令来形成相应文件。guide为用户提供了一个方便高效的集成环境,使用guide创建GUI时,可以将设计好的GUI界面保存为一个fig资源文件,同时自动生成对应的.m文件。该.m文件包含了GUI的初始化代码和组建界面布局的控制代码。由于这种方法比较直观,且在.m文件的管理和程序代码的修改上也比较方便[3],因此本文采用第二种方式完成界面设计。
1.2 仿真界面的设计
本文以Matlab2014a作为实验环境,设计图形用户界面GUI,可以实现语音信号的读取、MFCC特征参数的提取、音频文件的播放、模拟照明等通用功能,界面美观,易于拓展,可以作为语音感知的照明控制系统的初始工具。
GUI设计模块分为信号显示模块、操作流程控制面板模块、识别结果输出模块、模拟灯光展示平台模块、退出模块等,用于实现对语音信号的显示、处理、识别、操作及说明等功能。这些操作分别通过文件、错误提醒的方式进行显示,同时给出下一步该操作的提醒。通过对语音库及特征参数的提取来建立已知知识库(也称为参考模板),通过选择音频文件和播放音频文件来控制音频信号的获取;通过文本输出和模拟灯光显示以及播放音频文件的操作来执行模式匹配,进而验证其识别的准确性。
基于以上功能,设计Matlab GUI软件界面架构图如图1所示。
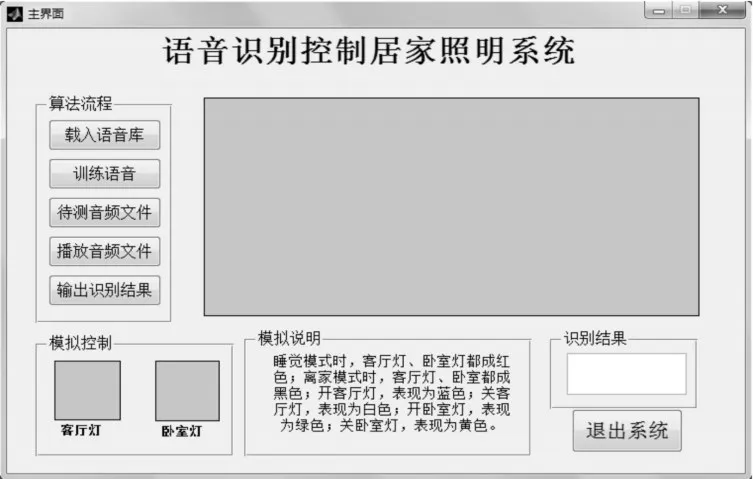
图1 软件界面设计架构图
2 语音感知识别组成
语音识别就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的高技术,也就是让机器听懂人类的语音[4]。语音识别的原理框图如图2所示。

图2 语音识别原理框图
2.1 模板库的建立
将提取的语音特征序列经过特定训练产生语音参考模板,形成供识别的参考模型库;语音识别包括对声音的起始点、结束点判断和处理,对一些控制命令语义的理解。在整个系统开发中,语音识别是最关键的,需要建立模板库。语音库的建立是在实验室安静环境下,分别请2名同学在一定时间内录制‘离家模式'、‘睡觉模式'、‘开客厅灯'、‘开卧室灯'、‘关客厅灯'、‘关卧室灯'6种语音。目前每种语音进行6次录制,其中5次用来训练,1次用来测试,即构成了60条的语音信号的语音库,由于可用的语音信息只占整个语音信号的一部分,所以需要对60条语音遍历进行预处理、MFCC特征提取、训练,从而构成语音库。这样可以提高识别率和识别速率。
2.2 预处理
由于原始语音信号一般不能满足实际需要,处理起来很复杂或者根本无法处理,所以在进行语音识别之前都要对原始语音信号进行预处理[5]。预处理是通过一些环节得到有用的语音信号,例如预加重、加窗分帧、端点检测等;
1)预加重:预加重是通过提升语音的高频部分,将其进行加重,增加语音高频分辨率。具体是将语音信号通过一阶滤波器实现,本文采用传递函数为H(z)=1-0.975z-1的一阶FIR高通数字滤波器来实现预加重。
2)加窗分帧:语音信号可认为是短时平稳的,所以需要将其作分帧处理。本文采取汉明窗对语音信号进行分帧。
3)端点检测:端点检测就是找到语音信号的起点与终点,减少真实数据的处理量,缩短处理时间,提高识别效率。本文采用基于特征的双门限检测法,即利用语音信号的短时能量与短时过零率联合检测。在Matlab中对语音“离家模式”端点检测进行绘制[6],结果如图3所示。
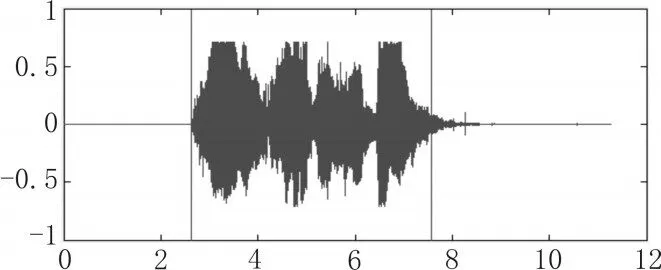
图3 截取真正的语音信号
2.3 特征参数提取
特征提取是从有用的语音信号中提取出随时间变化的特征序列来表征语音信号。本文选择Mel频率倒谱系数(MFCC)作为其特征参数进行训练与识别。因为MFCC参数比较充分的利用人耳这种特殊的感知特性提取语音信号的特征参数,并且有较高的识别率[7]。
Mel频率倒谱系数(MFCC)考虑到了人类的听觉特征,先将线性频谱映射到基于听觉感知的Mel非线性频谱上,然后再转换到倒谱上[8]。提取MFCC的过程[8]:
1)对原始语音信号进行预加重、分帧、加窗;
2)对每一帧短时信号,通过FFT变换得到对应的频谱;
3)对每一帧的频谱分别通过24阶Mel滤波器组得到Mel频谱;
4)计算每个滤波器组输出的对数能量;
5)对Mel频谱进行倒谱计算,具体是:取对数,做逆变换,一般是通过DCT离散余弦变换,取DCT后的第二个到第13个系数作为MFCC,获得特征系数MFCC。具体流程图如图4所示。

图4 MFCC特征向量提取流程
MFCC模仿了人耳特殊的非线性感知特性参数,它与线性频率的转换关系为[9]:
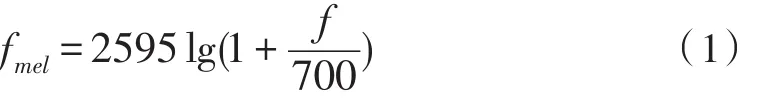
本文采用的是12阶标准MFCC参数作为特征参数。
在构建完成语音库后,对每一个语音提取MFCC特征参数,然后进行训练,训练过程中,将MFCC特征向量存入S.mat中,方便进行匹配。
2.4 模板匹配
语音识别过程实际上是一个模式匹配的过程。模式匹配是指在识别时将未知的语音特征序列同参考模板库进行匹配和比较,计算出它们之间的匹配程度,具体算法见章节3。
3 软件算法实现
3.1 算法思想
软件算法主要采用动态时间规整DTW算法,实现的功能有原始语音数据的提取、预处理、特征参数提取、训练以及语音识别,软件算法设计架构图如图5所示。

图5 软件算法设计架构图
为匹配之前录制好的60条种训练集的MFCC特征向量,我们采用DTW算法进行匹配,DTW是基于动态规划(DP)的算法来实现的,成功解决了发音长短不一的问题[10-11]。DTW使用所有这些相似点之间的距离的和,称之为归整路径距离来衡量两个时间序列之间的相似性,DTW算法的训练中几乎不需要额外的计算[12]。DTW算法要求参考模板与测试模板采用相同类型的特征向量、相同的帧长、相同的窗函数和相同的帧移[13]。
3.2 模板匹配
为了将两条语音序列匹配,需要计算两条语音序列中各帧的匹配程度[14]。参考模板表示为{R(1),R(m),…,R(M)} ,测试模板表示为T(1),T(n),…,{T(N)}(n,m表示语音帧的时序标号,n=m=1表示起始语音帧,n=N,m=M表示终止语音帧),参考模板与测试模板均为提取的MFCC特征参数。为了比较它们的相似情况,计算它们之间的欧氏距离,即d[(T,R)],距离越小代表二者相似度越高。
为了得到最小匹配路径,通常采用动态规划方法[15]。在传统的DTW算法中,需将测试模板中的每一帧与参考模板中的每一帧作相似度比较[16]。这有一定的局限性,需要对其加以限制,将其路径范围弯折率的变化区间设定在[0.5,2]。
即如果路径已经通过了格点(ni,mi),那么下一个通过的格点(ni+1,mi+1)可能是下列3种情况:
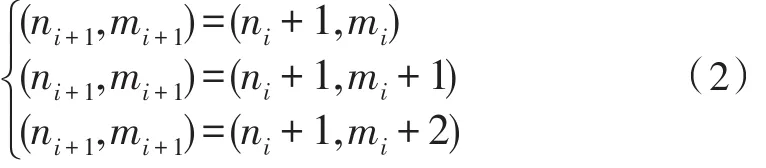
即搜索路径的方法如下:搜索从(ni,mi)点出发到(N,M)结束,可以展开若干条满足公式(2)的路径,假设可计算每条路径达到(N,M)点时的总的累积距离,具有最小累积距离者即为最佳路径。最佳路径对应的模板记为识别结果。累计距离计算公式为:
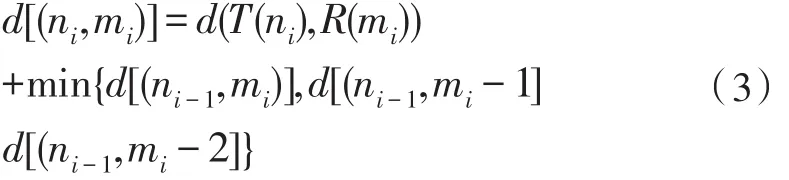
经过对路径进行约束后,匹配范围进行了缩小,减少了一些不必要的计算量,提高了识别效率与缩短了识别时间。
4 实验结果分析与模拟实现
本文基于2名同学、6种不同语义内容作了识别实验。在语音库的建立一节中已经表明:实验所需样本共72个,其中60个为参考模板存入模板库,12个样本作为测试用。实验结果显示可以正确识别语音信号,并且有正确的关联输出。
对于不同的语音信号可以控制不同的模拟灯光状态,可以通过点击输出识别结果命令按钮可以获取识别结果,并执行指定的控制模拟操作。
本文使用的模拟灯光具体操作表现为:睡觉模式时,客厅灯、卧室灯都成红色;离家模式时,客厅灯、卧室都成黑色;开客厅灯,表现为蓝色;关客厅灯,表现为白色;开卧室灯,表现为绿色;关卧室灯,表现为黄色。语音识别完成后,需要对模拟灯光进行关联输出,通过对语音信号类别进行对应来得到相应的已知语义,进而对应相应的模拟灯。
在打开该程序所在的Matlab程序后,打开EmotionRec.m文件,在此.m文件下点击运行,会出现如图1显示的界面。然后就可以在这个界面上完成所有用户想要完成的动作了。首先训练库文件,点击载入语音库按钮后,选择语音库所在的文件路径;点击训练语音按钮,系统将会遍历库中所有的.wav文件,并从每一个语音的起始到结束提取特征向量,训练完成后构建成语音库;用户可以点击待测音频文件选择需要识别的语音文件,点击完成后,界面中会出现对应的音频原始信号图;点击识别结果,模拟灯光会执行相应的动作,同时输出文本框显示识别出来的对应文字。点击播放音频文件,会播放对应的音频。点击退出系统做出判断后会关闭界面。
图6与图7是训练过程界面显示图与识别完成结果显示图。
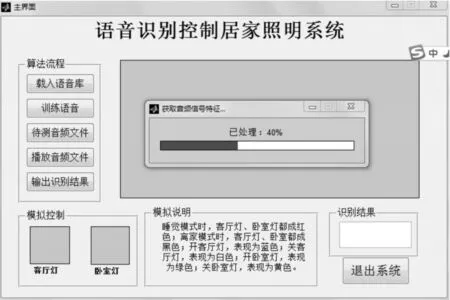
图6 训练过程界面显示图

图7 识别完成结果显示图
5 结论
本文主要介绍了处理语音信号的前期步骤,并且利用MatlabGUI开发平台,设计开发了语音识别控制照明系统一体化平台,实现了语音识别的集成化、可视化、交互式的功能,同时实现了DTW算法的改进。目前平台上已经集成了Matlab语音处理工具包中的部分算法以及模拟灯光显示,结果可以直观地帮助用户方便快捷的实现语音识别的操作,同时使用文字输出、模拟灯光的输出、语音播放待识别语音的方法高效地判断语音识别的正确性。
