DBSCAN算法优化及其在GSM-R铁塔监测系统中的应用
2018-05-22胡淼淼刘宏志
胡淼淼 刘宏志 张 铎
1(北京工商大学计算机与信息工程学院 北京 100048)2(北京工商大学食品安全大数据技术北京市重点实验室 北京 100048)3(北京博时远信技术有限公司 北京 100070)
0 引 言
在数据挖掘中,聚类算法可以根据数据的属性(对象之间的距离)将数据划分为不同的类。目前,主要的聚类算法可以划分为以下几类:基于划分的方法、基于密度的方法、基于网格的方法以及基于层次的方法[1-4]。其中,基于密度的聚类算法主要的目标是寻找被低密度区域分离的高密度区域,与其他聚类算法不同的是基于密度的聚类算法可以在具有噪声数据的空间数据库中发现任意形状的聚类。本文对基于密度的聚类算法DBSCAN的原理进行了分析并对算法进行了优化,使得算法能自适应确定参数满足GSM-R铁塔监测系统中倾角传感器的校正需要。
1 GSM-R铁塔监测及DBSCAN算法
1.1 GSM-R铁塔监测
GSM-R系统是我国针对铁路运输的实际需要而专门设计的综合专用数字通信系统[5-6]。近年来,随着铁路无线通信技术的飞速发展,越来越多的GSM-R通信铁塔被部署应用。GSM-R通信铁塔监测系统结合了物联网技术,使用倾角传感器、气象传感器、电磁传感器和沉降传感器等多种传感器监测铁塔状态,保证了GSM-R铁塔的正常使用[7]。其中,倾角传感器是直接监测铁塔的倾斜状态的传感器,在环境恶劣的情况下,倾角传感器能及时发现铁塔倾斜,方便维护人员及时加固铁塔,避免倾倒影响铁塔的正常使用。但是,倾角传感器在人工安装过程中会出现一定的角度偏移,因此在使用前需对倾角传感器进行校正。
目前,GSM-R铁塔监测系统多采用在稳定条件下倾角传感器采集数据的平均值作为铁塔中心角度偏移值进行传感器校正。由于实际应用中的倾角传感器在稳定条件下仍会受铁塔塑性形变的影响,采集到部分噪声数据,并且噪声数据会影响铁塔中心角度偏移值的计算结果,进而影响告警数据的产生,造成严重的后果。因此,本文提出使用DBSCAN算法代替平均值计算法进行倾角传感器的校正,通过对算法进一步优化使其可以自适应确定所需参数适用于GSM-R铁塔监测系统的倾角传感器校正需要。优化后的DBSCAN算法可以通过密度聚类避免噪声数据的影响,对聚类结果计算聚类中心可获得铁塔中心角度偏移值对倾角传感器进行校正。
1.2 DBSCAN算法基本原理
基于密度的聚类算法DBSCAN算法是由MARTIN等[8-10]提出的一种基于密度的聚类算法,用来寻找被低密度区域分离的高密度区域。该算法将具有指定要求密度的相应区域划分为簇,并在具有噪声数据的数据库样本中发现任意形状的簇,其对簇的定义即为密度相连点的最大集合。
DBSCAN算法使用之初需要用户输入参数Eps值和MinPts值。其中,Eps为邻域半径参数,MinPts为邻域密度阈值。DBSCAN算法基本定义如下。
定义1以输入数据集内任意一个数据对象为圆心,Eps为半径的球形区域内所有数据对象的集合即为Eps邻域。
定义2在Eps邻域内的数据对象个数大于或等于MinPts的数据对象为核心点。在Eps邻域内的对象数小于MinPts,但是在核心点Eps邻域内的数据对象为边界点。
定义3数据对象Pi在核心点Pj的Eps邻域内,则Pi到Pj直接密度可达。
定义4若存在一个对象链P1,P2,…,Pn,且有Pi+1到Pi直接密度可达,则P1到Pn密度可达。
定义5基于密度可达性的最大的密度相连对象的集合称为簇。数据集中不属于任何簇的数据对象即为噪声点。
DBSCAN通过检查数据集中每个对象的Eps邻域来寻找聚类。如果一个点P的Eps邻域包含多于MinPts个数据对象,则创建一个P作为核心对象的新簇。然后,DBSCAN反复地寻找从这些核心对象直接密度可达的对象,这个过程涉及密度可达簇的合并。当没有新的点可以被添加到任何簇时,聚类过程结束。
1.3 算法应用分析
在传统GSM-R铁塔监测系统中,倾角传感器的校正是由传感器在稳定状态下采集的数据取平均值来确定的。根据中国铁路总公司印发的《铁路通信铁塔监测系统技术条件》可知,稳定状态即风速为零级(风速小于等于0.2 m/s)时的状态,此时风速不能对铁塔倾斜造成明显影响。研究表明铁塔在风载荷影响下的随机振动不会立刻停止[11],当传感器采集校正所需零级风数据时,由于随机振动的影响传感器仍会采集到部分噪声数据。因此,使用平均值计算铁塔中心偏移值对倾角传感器进行校正并不准确。
稳定状态下倾角传感器采集数据较为集中,从中心向外侧数据密度逐渐降低,噪声数据周围数据密度最低。DBSCAN算法是一种基于密度的空间聚类算法,该算法可以忽略噪声数据的影响对铁塔中心区域数据进行聚类,聚类中心即为铁塔中心偏移值。此外,受风向影响铁塔中心偏移方向不确定,运动轨迹没有规律,因此采集数据的高密度区域形状并不固定。与传统的基于划分方法的聚类算法和基于层次方法的聚类的凸形聚类簇算法不同,DBSCAN算法的聚类簇可以是任意形状的。因此DBSCAN算法适用于GSM-R铁塔监测系统的倾角传感器校正。
但是,DBSCAN算法在使用过程中聚类对象的密度由事先指定的两个参数Eps(邻域半径)和MinPts(邻域密度阈值)来确定。用户需要在没有先验知识的情况下设定这两个参数,DBSCAN算法对参数十分敏感,这两个参数的选择将直接影响算法最终的聚类结果质量。而GSM-R铁塔监测系统通常能监测2 000个左右的铁塔,这些铁塔地理位置不同,环境不同甚至铁塔种类也不同,因此在GSM-R铁塔监测数据集中不同铁塔的数据密度不同,使用全局参数难以准确计算出不同铁塔的中心角度偏移值。本文对DBSCAN算法进行了优化,使其可以针对不同铁塔数据集自适应确定Eps和MinPts参数,从而可以准确计算各个铁塔的中心角度偏移值,对倾角传感器进行校正。
2 DBSCAN算法优化
针对DBSCAN算法的参数敏感问题,已有不少学者提出了解决办法。OPTICS算法通过对数据集中的数据对象进行排序得到一个有序的对象列表(cluster-ordering),根据对象列表的信息对数据对象进行分类进而提取聚类[12]。文献[13]根据数据对象在不同维度的密度分布动态设置Eps参数。文献[14]提出了动态近邻概念,即参数随数据对象的密度动态变化。文献[15]基于密度最大区域中心点对DBSCAN算法进行了改进。文献[16]通过分析数据的统计特性自适应确定参数。本文在DBSCAN算法及其各类改进算法的研究基础上,根据GSM-R铁塔监测系统的使用需要对DBSCAN算法进行了优化。通过Canopy粗聚类确定算法所需参数Eps值,然后根据统计学方法确定参数MinPts,使得算法可以根据不同数据集自适应确定参数,解决了DBSCAN算法的参数敏感问题,提高了聚类效果。
2.1 邻域半径确定方法
根据DBSCAN算法的原理可知,算法根据数据对象之间的距离确定数据对象之间的亲疏关系,Eps参数的选择将直接影响最后的聚类效果。在参数MinPts一定的情况下,参数Eps选择越小,则聚类结果中簇的密度越高,但会导致本该完整的簇被拆分为多个簇,大量的数据对象被错误的标记为噪声数据。参数Eps选择越大,则聚类结果中簇的密度会降低,同时会导致噪声数据被归入簇中,无法成功分离噪声数据。
在数据对象分布不均匀的情况下,对任意一个数据对象,将距离该数据对象最近的多个数据对象的距离平均值作为该对象处的密度衡量标准。符合聚类需要的距离平均值将是需要获取的Eps参数值。设输入数据集D={P1,P2,…,Pn}。Pi为D中任意一个数据对象,计算数据对象Pi到D的子集S={P1,P2,…,Pi-1,Pi+1,…,Pn}中所有数据对象之间的距离。将距离按递增排序后存入集合R={r1,r2,…,rk-1,rk,rk+1,…,rn-1}。其中,rk被称为K-距离即数据对象Pi到除自身外所有数据对象之间距离第k近的距离。数据对象Pi到其他数据对象之间距离的平均值为:
(1)
Canopy算法是一种快速简单但是并不准确的聚类算法,多用于数据集的粗划分[17-18]。本文使用该算法进行数据集的粗聚类,根据粗聚类结果获取合适的Eps值。Canopy算法使用之初要定义两个距离值T1和T2,为了确定这两个距离值,首先要在输入数据集D中任选一个数据对象记为P,并将其移出数据集D。计算数据对象P的K-距离集合并求平均值。根据计算结果做如下设定:
(2)
然后按照K-距离集合将数据集D中所有距离小于T1的数据对象加入以P为中心的canopy类,将距离小于T2的所有数据对象移除数据集D。执行完一次后重新选择一个数据对象,T1和T2不变,重复上述步骤,直至数据集D为空。
上述步骤执行完成后会获得多个canopy类,这些类中会出现部分数据重叠的现象。因此Canopy算法的划分是不准确的,但是分布杂乱的数据对象经过大致划分可以确定数据密度分布情况。对多个canopy类按数据对象数目进行排序,数目最多的canopy类的数据密度相比较其他类更接近数据集的最大密度。在该类中任选一个数据对象,计算其K-距离平均值,该值即为所求Eps参数值。
2.2 邻域密度阈值确定方法
在参数Eps已经确定的情况下,参数MinPts选择越大,聚类结果中簇的密度越高,但是会减少核心点的数量,将完整的自然簇分割。参数MinPts选择较小会使大量数据对象被错误的标记为核心点,导致噪声数据无法正确标识。本文通过统计数据集D中所有数据对象在其Eps邻域内的数据对象的个数,并通过求数学期望得到MinPts参数值表示为:
(3)
式中:Qi表示数据对象Pi其Eps邻域内的数据对象的个数。
综上,本文在对DBSCAN算法及其各类改进算法的研究基础上,结合对铁塔数据集统计分析,使用Canopy算法粗聚类确定算法所需参数Eps值,根据统计学方法确定参数MinPts值,使得算法可根据不同数据集自适应确定参数,解决了DBSCAN算法的参数敏感问题。将计算所得参数Eps和MinPts值代入DBSCAN算法进行聚类计算,所得聚类结果按照密度大小进行排序,选择密度最高的聚类簇计算簇中心即为稳定状态下铁塔中心偏移值。其余聚类簇为铁塔在火车共振等外力影响下的偏移中心,等同于噪声数据。
3 实验设备
本文中采用的实验设备如图1所示,左侧仪器是串口输出型双轴倾角传感器,内置高精度16 bit A/D 差分转换器,通过5 阶滤波算法,最终输出双方向的倾角值,分别是水平方向X轴的倾角值和Y轴的倾角值。图1右侧仪器为推动装置用于检测传感器是否准确。
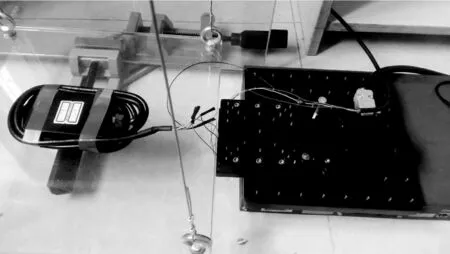
图1 实验设备图
倾角传感器输出的水平方向X轴的倾角值和Y轴的倾角值是角度偏移值,并不能直接为DBSCAN算法所用,需要将倾角转换为偏离X轴方向的实际距离值和偏移Y轴方向的实际距离值,方便DBSCAN算法按照密度聚类,具体计算模型如图2所示。
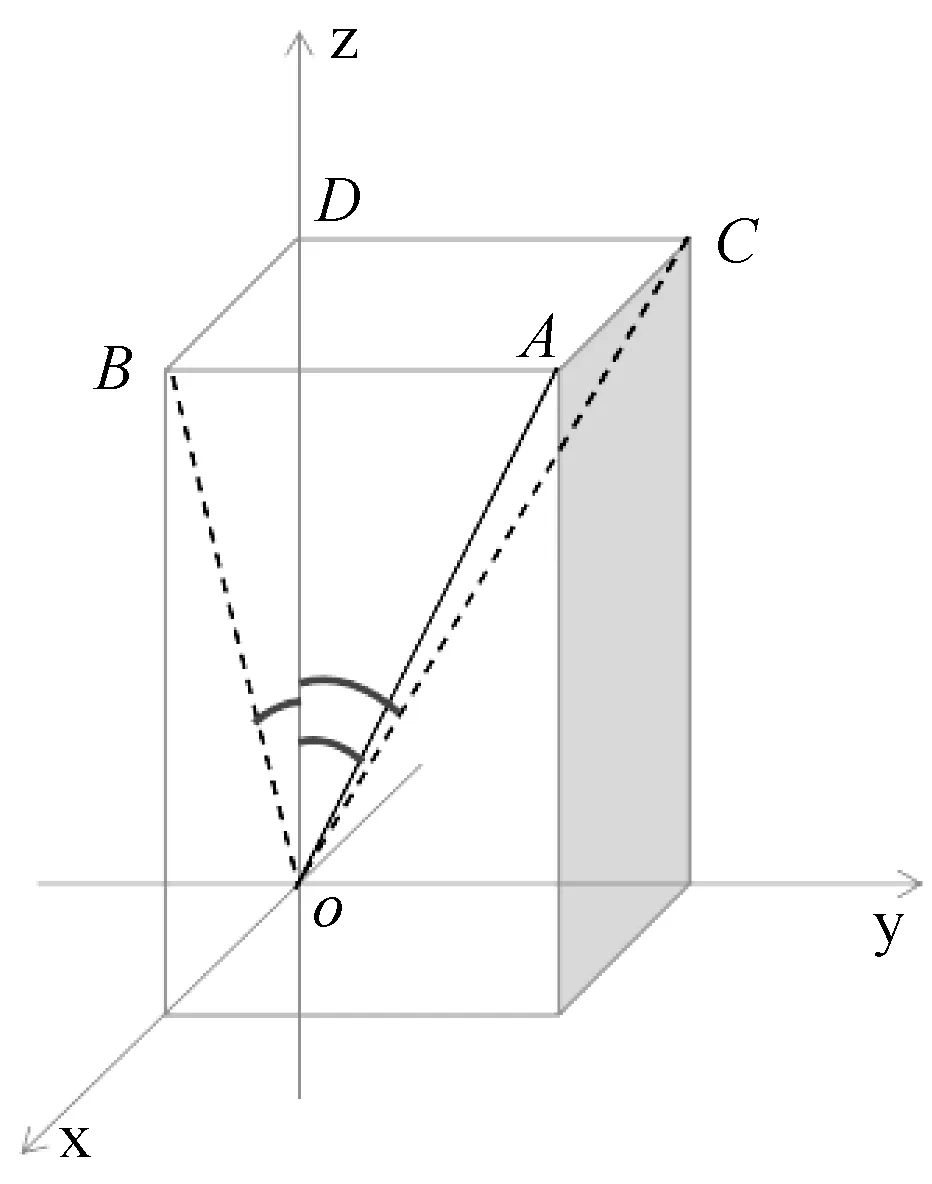
图2 角度转换距离计算模型
在计算过程中设塔高为h,指塔顶到铁塔底座中心的距离。在图2中,铁塔底座中心为点O,塔顶为A,OA之间距离为塔高h。α为X轴方向倾斜角度即∠AOB,β为Y轴方向倾斜角度即∠AOC,θ为垂直方向实际倾斜角度即∠AOD,则有:
(4)
X轴方向偏移距离为:
x=h·cosθ·tanα
(5)
Y轴方向偏移距离为:
y=h·cosθ·tanβ
(6)
经过上述计算将得出塔顶的具体偏移位置即为塔顶的实际距离坐标(x,y),垂直状态下坐标为(0,0)。将倾角传感器采集角度值全部转换为距离值后使用优化后的DBSCAN算法对倾角传感器在稳定状态下采集的数据进行聚类计算,求得具体的铁塔中心距离偏移值,最后将铁塔中心的距离偏移值转换成角度偏移值对倾角传感器进行校准。
4 实验结果分析
本文所使用所有数据均是使用图1所示倾角传感器在四个采集点采集到的实际数据。四个采集点分别为4097号铁塔(济南西)、4099号铁塔(曲阜东)、4100号铁塔(滕州东)和4101号铁塔(枣庄)。数据采集信息如表1所示,传感器每250 ms采集一次数据。数据集包含时间、风速、风向、X轴倾角和Y轴倾角等信息。

表1 总数据集基本信息
本文首先使用优化后的DBSCAN算法分别对以上四个数据集中全部零级风数据计算铁塔中心角度偏移值,计算结果如表2所示。通过比较计算结果发现4 099号数据集的DBSCAN算法计算所得铁塔中心角度偏移值与平均值计算结果差距较大,其他数据集计算结果差距相对较小,其中4101号数据集计算结果差距最小。通过对数据集分析发现4099号数据集在2016年6月21日风速变化较大,下午5时最大风级达8级(最大风速17.3 m/s),根据规定已达到大风预警条件,数据集中零级风总数最少且受大风影响噪声数据较多。而4101号数据集全天风速相对稳定,且最大风级不超过3级(最大风速5.4 m/s),数据集中零级风数据较多且噪声数据最少。上述结论表明,噪声数据会对中心角度偏移值的计算产生较大影响,需要进一步验证DBSCAN算法分离噪声数据的能力。

表2 总数据集计算结果
为了确定改进DBSCAN算法能有效分离噪声数据求得准确铁塔中心角度偏移值,本文人工从数据集中分离出最大风级不超过2级(最大风速3.3 m/s)的5个小时的连续数据,人工排除了受大风影响偏移较大的噪声数据,节选数据集信息如表3所示。分别使用改进DBSCAN算法和平均值计算法对节选数据进行计算,计算结果如表4所示。通过比较计算结果发现改进DBSCAN算法计算所得铁塔中心角度偏移值与表2计算结果差距较小,最大偏差为0.029°。而平均值计算所得结果与表2相比仍有比较大的差距,最大偏差已超过0.567°,根据《铁路通信铁塔监测系统技术条件》规定铁塔中心偏移超过0.567°将会产生提示告警,因此可以证明平均值计算法易受噪声数据影响,不能准确计算出铁塔中心角度偏移值容易产生误差告警。此外,表4平均值计算结果更接近于改进DBSCAN算法计算所得结果。综上所述,改进DBSCAN算法受噪声数据影响较小,能够根据不同数据集自适应确定合适的参数Eps值和MinPts值,分离出绝大部分噪声数据,求得相对准确的铁塔中心角度偏移值对倾角传感器进行校正。
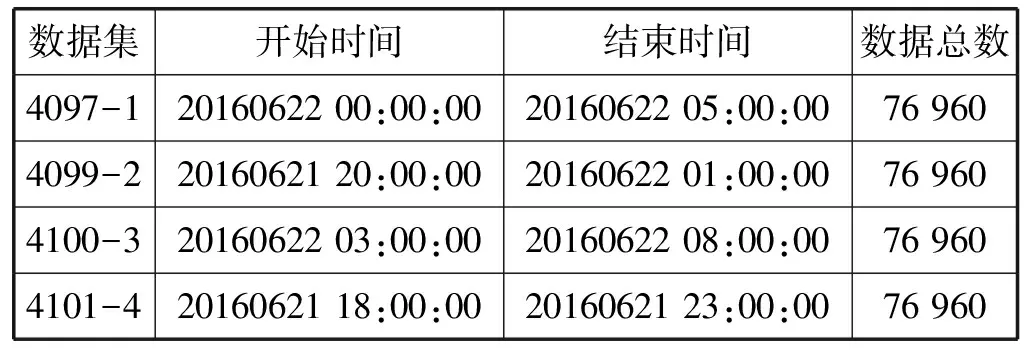
表3 节选数据集基本信息

表4 节选数据集计算结果
5 结 语
GSM-R铁塔监测系统保证了铁路通信铁塔的正常使用,其中倾角传感器的监测结果直接反映了铁塔的倾斜状态。为了避免倾角传感器受到人工安装误差的影响,本文提出使用DBSCAN算法代替平均值计算法进行倾角传感器的校正。通过研究DBSCAN算法的基本原理,结合其他学者的研究工作解决了该算法的参数敏感问题,使其适用于GSM-R铁塔监测系统的使用需要。实际数据测试结果表明,优化后的DBSCAN算法能根据不同数据集自适应确定所需参数,不受噪声数据的影响,同时并未增加算法的处理时间,计算结果与全站仪所测实际数据对比准确率可达98.57%,适用于倾角传感器校正需要。
参考文献
[1] Dharni C, Bnasal M. An improvement of DBSCAN Algorithm to analyze cluster for large datasets[C]// Innovation and Technology in Education. IEEE, 2013:42-46.
[2] Rodriguez A, Laio A. Machine learning. Clustering by fast search and find of density peaks[J]. Science, 2014, 344(6191):1492.
[3] 孙吉贵, 刘杰, 赵连宇. 聚类算法研究[J]. 软件学报, 2008, 19(1):48-61.
[4] Smiti A, Eloudi Z. Soft DBSCAN: Improving DBSCAN clustering method using fuzzy set theory[C]// The, International Conference on Human System Interaction. IEEE, 2013:380-385.
[5] 车颜泽. 高速铁路GSM-R无线通信系统简介[J]. 华东科技:学术版, 2016(7):307-307.
[6] Tokody D, Maros D, Schuster G, et al. Communication-based intelligent railway- Implementation of GSM-R system in Hungary[C]// IEEE, International Symposium on Applied Machine Intelligence and Informatics. IEEE, 2016:99-104.
[7] 江文丹, 李春, 吴宏松. GSM-R综合监测系统在高铁中的应用研究[J]. 铁道通信信号, 2015, 51(S1):70-72.
[8] Ester M, Kriegel H P, Sander J, et al. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise[C]// International Conference on Knowledge Discovery and Data Mining. AAAI Press, 1996:226-231.
[9] Borah B, Bhattacharyya D K. An improved sampling-based DBSCAN for large spatial databases[C]// International Conference on Intelligent Sensing and Information Processing. IEEE, 2004:92-96.
[10] 冯少荣, 肖文俊. 基于密度的DBSCAN聚类算法的研究及应用[J]. 计算机工程与应用, 2007, 43(20):216-221.
[11] 潘峰, 李显鑫, 侯中伟,等. 1000kV特高压山区单回路输电塔风振特性研究[J]. 电力建设, 2013, 34(8):64-68.
[12] Ankerst M, Breunig M M, Kriegel H P, et al. OPTICS: ordering points to identify the clustering structure[J]. Acm Sigmod Record, 1999, 28(2):49-60.
[13] Jahirabadkar S, Kulkarni P. Algorithm to determine ε -distance parameter in density based clustering[J]. Expert Systems with Applications, 2014, 41(6):2939-2946.
[14] 李阳, 马骊, 樊锁海. 基于动态近邻的DBSCAN算法[J]. 计算机工程与应用, 2016, 52(20):80-85.
[15] 范敏, 李泽明, 石欣. 一种基于区域中心点的聚类算法[J]. 计算机工程与科学, 2014, 36(9):1817-1822.
[16] 夏鲁宁, 荆继武. SA-DBSCAN:一种自适应基于密度聚类算法[J]. 中国科学院大学学报, 2009, 26(4):530-538.
[17] 赵庆. 基于Hadoop平台下的Canopy-Kmeans高效算法[J]. 电子科技, 2014, 27(2):29-31.
[18] 余长俊, 张燃. 云环境下基于Canopy聚类的FCM算法研究[J]. 计算机科学, 2014, 41(S2):316-319.
