基于OLAP和聚类分析的关联规则挖掘方法
2018-05-22熊中敏朱春卫郭振辉
熊中敏 朱春卫 郭振辉 陈 明
1(上海海洋大学信息学院 上海201306) 2(农业部渔业信息重点实验室 上海 201306) 3(上海电子信息职业技术学院 上海 201411)
0 引 言
数据挖掘就是利用各种数理模型从数据库中的海量数据中抽取隐藏的某种规律的一系列过程[1]。关联规则挖掘能将数据库中项与项之间的潜在关系挖掘出来,比如利用超市的购物单发现了购买啤酒和尿布的强规则[2]。最经典的关联规则算法是 Apriori 算法[3],但它需要反复扫描事务数据库并产生大量候选集,占用内存大、运行效率低。以下出现的是一些当前关联规则挖掘急需解决的挑战性问题[4]:
(1) 面临当前海量信息,提高关联规则挖掘算法的效率常常又会导致降低了挖掘结果的可行性、新奇性。
(2) 在挖掘的过程中,大型数据库挖掘出的规则集过大,导致用户难以理解、难以选择。
(3) 关联规则算法中融合其他算法、解决单纯的关联规则算法无法解决的应用问题。好多挖掘方法看似和关联规则算法没有交集,若有机地融入算法中可扬长避短。
通过数据仓库的OLAP操作:切片、切块、旋转、上卷和下钻,用户既可以快速地察觉到宏观变化,又可以从细节上观察变化的详细因素。聚类是用户用以观察某一类具有共同特性的数据集的利器。现有的关联规则挖掘若结合OLAP和聚类分析,用户可以有预见性地选取有分析意愿的数据集,挖掘结果更符合用户的分析意愿,使得挖掘出的关联规则的数量大为减少、而用户的满意度却大大增加。本文的研究工作将部分地解决上述关联规则挖掘研究中的挑战问题,从而为数据仓库和数据挖掘技术的应用普及做出贡献。
1 相关知识
1.1 OLAP分析
用户的决策分析在关系数据库上需要经过大量的计算,显然简单的查询的结果难以满足这种决策需求。因此,E.F.Codd于1993年提出了OLAP的概念(即多维数据库和多维分析)。
定义1[5]OLAP(联机分析处理)是联机查询和分析某个具体的主题的数据,从多维度、不同综合层次上直观地将数据状态展示给使用者。
OLAP分析主要利用以下5种操作[5]:切片、切块、聚合、钻取、旋转。将多维数据集上某个维度固定为一个维度成员区间(例如取“2000年至2014年”),就得到一个切块。维度的层次结构代表了数据的综合程度,如地区维度可能由地区、省、市、区构成。综合程度越低则细节级别越高,粒度越小,数据量越大。在某个维度上将综合层次低的数据汇总到高层次数据是上卷操作。反之为下卷操作。这两种浏览数据的方式,提供给用户宏观和微观角度观察数据。旋转既可交换行和列上的维度,也可以交换维度的不同层次,从而得到用户习惯的数据展示形式。
OLAP是数据分析过程中的重要工具,它使数据分析能够在数据立方体上以用户习惯的视角迅速、一致、交互地浏览数据,以便用户能深入理解数据。
1.2 聚类分析
与传统统计分析及OLAP不同,数据挖掘采用计算机自动处理算法在数据集上进行自动挖掘,从而找到潜在、有用的知识。将个体之间的相似性作为“距离”的测度,使得相互间距离比较小归为一类而不同类的个体间距离比较大,俗称聚类。聚类反映的不仅有不同事物之间的差异性而且还有同类事物的共同性。数据集通过聚类被划分为一系列子类,从而细化了人们的客观认识,可以区分概念和偏差。当前常见的聚类算法有:划分法[6]、层次法[7]、密度法[8]、网格法[9]和模型法[10]。
K-means算法[11]是比较典型的划分法聚类算法,每个数据点唯一地分配给一个且仅一个聚类,而且需要预先指定需要划分聚类的个数,但方法简单、较容易实现。本文将采用它作为聚类方法。K-means算法流程如下所示:
1) 选定数据空间中K个对象作为初始聚类中心,每个对象代表一个类别的中心。
2) 对于样品中的数据对象,则根据它们与这些聚类中心的欧氏距离,按距离最近的准则分别将它们分配给与其最相似的聚类中心所代表的类。
3) 计算每个类别中所有对象的均值作为该类别的新聚类中心,计算所有样本到其所在类别聚类中心的距离平方和,即J(C)值。
4) 聚类中心和J(C)值是否发生改变,若是则转2),否则聚类结束。
1.3 关联规则
关联分析的目的就是为了发现数据间发生一定关联关系的规律,通常采用以下形式:(X⟹Y,支持度=s,置信度=c)。这里X称为规则的前件,Y称为规则的后件,支持度s是包含X的项在全体项集中出现的频率,置信度c是X和Y同时出现的项在出现有X的项集中所占比例。
Apriori算法是最知名的关联规则发现方法。大于最小支持度的项集称为频繁项集,利用了频繁集,Apriori算法分为两个步骤[5]:
第一步:利用大于最小支持度和“Apriori性质”找到所有频繁项集;第二步:利用大于最小置信度将第一步找到的频繁项集转换为关联规则。
算法使用迭代方法,利用“频繁项集的所有非空子集都必须是频繁的” Apriori性质由“K-项集”产生“K+1-项集”,如此下去,直到找不到后继的频繁项集为止。
2 综合OLAP和聚类分析的关联规则挖掘
2.1 OLAP分析对关联规则挖掘的影响
首先我们以一个简单的例子来说明数据集的选择对关联规则挖掘出的结果的影响。
例1假定在一个零售商品的数据库中包含两个商场A和B的购物交易数据,如表1所示。
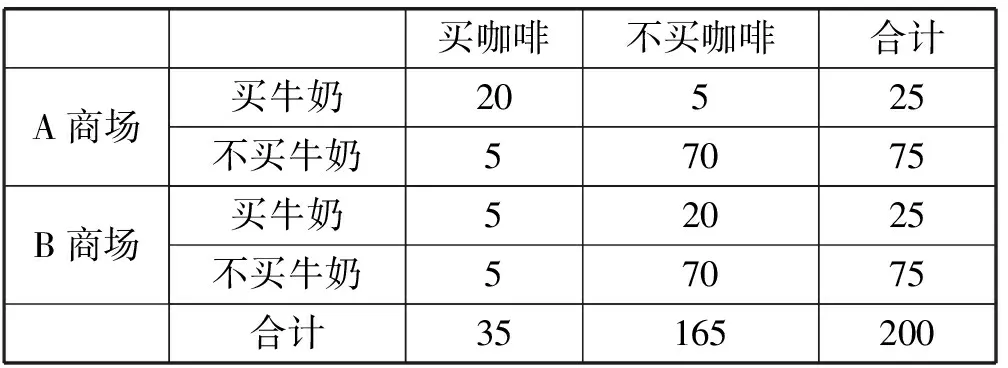
表1 交易集的分析
下面分别讨论表1中事务集对关联规则的支持度和置信度的影响。
1) 由表1可以了解到,如果设定minsupp=0.2,minconf=0.6,整个200个交易记录构成的事务集按照现有挖掘算法就可以得到如下关联规则:
买牛奶→买咖啡s=25/200=0.125 故在整个交易记录上上述规则因为不满足设定的最小支持度在计算频繁项集的时候就被舍弃。 2) 当我们设定的最小支持度的阈值可以满足,即可以有效通过频繁项集的计算,该规则仍然可能因为最小置信度不满足导致被舍弃。 例如,在这个例子中如果我们设定minsupp=0.12,minconf=0.60,整个200个交易记录构成的事务集按照现有挖掘算法就可以得到如下关联规则: 买牛奶→买咖啡s=25/200=0.125>minsupp 即在关联规则挖掘算法Apriori的第一步的频繁项集的计算当中,该规则有效地包含在频繁项集中。但在第二步生成关联规则的时候,需要计算置信度: 买牛奶→买咖啡c=25/50=0.50 故在整个交易记录上上述规则因为不满足设定的最小置信度在算法第2步生成关联规则的时候被舍弃。 3) 如果构造了一个商品销售分析的数据仓库的多维数据模型。比如在事实表中含度量值:销售金额和销售数量,将商场作为一个分析的维度,则在OLAP操作中既可通过上卷(也称之为上钻)看到整个交易集(包含了A、B两个商场)中买咖啡的总数量为35,买牛奶的数量为50。同时也能通过下钻操作分别看到A商场和B商场买咖啡的数量分别为25和10;买牛奶的数量分别为25和25。很明显买咖啡的数量集中在A商场。如果管理者有意识地需要得到咖啡销售情况的关联规则分析,只需要关注A商场的销售情况。即如果现在只是在表2所示事务集上做关联规则分析,按照现有挖掘算法就可以得到如下关联规则: 买牛奶→买咖啡s=20/100=0.2=minsupp c=20/25=0.8>minconf 表2 A商场交易集的分析 即设定minsupp=0.2,minconf=0.6,根据关联规则挖掘算法能在面向商场A的数据分析上得到有效的关联规则买牛奶→买咖啡。也就是这条关联规则针对商场A有效,但对于整个交易记录反而不成立。因为买咖啡的交易主要集中在商场A完成。 由此可见在数据仓库的多维数据集上的OLAP分析,我们能清晰地看出待挖掘的事务集中的项集在不同维度层次结构上的分布的不同,而这种数据分布的倾向性极大地影响到关联规则挖掘算法执行时生成频繁项集的支持度的计算和生成关联规则过程中置信度的计算,并导致最终能否生成用户关注的关联规则集合。 2.2 聚类分析对关联规则挖掘的影响 基于多维数据集上直接的OLAP操作能辅助用户对现有的多维数据集上的数据分布现状的理解,形成用户很清晰的数据分析对象的关注。 但上述数据理解方法仍然具有一定的局限性,从而妨碍了用户需要的关联规则的挖掘。这个问题类似如挖掘这样的关联规则:在上海浦东临港地区农工商超市现有不同类别人群的购物行为分析,或者是类似于用户张三的人群的购物行为分析。很显然,在数据仓库中没有直接的这样的购物行为的事务集,因为这是关注于用户的分析,而用户是不确定的、动态的,不像2.1节中有明显的维度成员:商场类别A和B。如果不能构建满足用户意图的事务集,而是在现有的数据仓库抽取到的整个事务集上做关联规则数据挖掘,会很明显出现和在2.1节中分析的结果一样的问题:针对特定数据分析对象的规则会因为支持度和置信度不够而不能有效地生成;而在一个大范围内产生的规则因为适用面太大而没有针对性,也就是用户真正想关注的关联规则不能有效地生成。 下面讲述如何实现本文中涉及到的基于个人信息的用户聚类分析,从而引证实现数据服务对象聚类的可行性方法。因为对用户的聚类需要用户注册的个人信息,而现在大的商场或商务网站都实行了会员制,所以用户的个人信息数据可以很方便得到。同时还有网上购物评价和相关论坛发帖,都能形成个人的信息,用于建立基于用户个性特征和购物兴趣的数据来源,从而利用现有的划分方法生成基于相似性度量的聚类。本文采用最常用的K-means方法得到聚类划分,而对于购物用户的聚类分析采用文献[12]的技术方案,只要布置好数据利用SQL SERVER2008 R2中analysis service部件自带的聚类算法,选择聚类模型为K-means即可。 本文在此仍然以一个如表3所示的简单的例子来分析在应用关联规则挖掘时出现的上述问题,并默认本例中用户已经聚类为两类。 表3 交易集的分析 下面分别讨论表3中事务集对关联规则的支持度和置信度的影响。 1) 由表3可以了解到如果设定minsupp=0.2,minconf=0.6,整个200个交易记录构成的事务集按照现有挖掘算法就可以得到如下关联规则: 买牛奶→买面包s=25/200=0.125 故在整个交易记录上上述规则因为不满足设定的最小支持度在计算频繁项集的时候就被舍弃。 2) 当我们设定的最小支持度的阈值可以满足,即可以有效通过频繁项集的计算,该规则仍然可能因为最小置信度不满足导致被舍弃。 例如,在这个例子中如果我们设定minsupp=0.12,minconf=0.60,整个200个交易记录构成的事务集按照现有挖掘算法就可以得到如下关联规则: 买牛奶→买面包s=25/200=0.125>minsupp 即在关联规则挖掘算法Apriori的第一步的频繁项集的计算当中,该规则有效地包含在频繁项集中。但在第二步生成关联规则的时候,需要计算置信度: 买牛奶→买面包c=25/50=0.50 故在整个交易记录上上述规则因为不满足设定的最小置信度在算法第2步生成关联规则的时候被舍弃。 3) 如果构造了一个商品销售分析的数据仓库的多维数据模型,比如在事实表中含度量值:销售数量,将用户作为一个分析的维度。为了挖掘这样的关联规则:类似于用户张三的人群的购物行为分析,需要事先完成用户的聚类分析。我们将具体实现用户聚类的方法留在后面详细阐述,先假定已经完成了商品销售分析中客户聚类。通过查询张三所属的用户聚类,将交易集中的用户分为“类似张三用户”,即张三所在的客户聚类,而其他客户聚类则划分为“不类似张三用户”。整个交易集(包含了类似张三用户、不类似张三用户)中买咖啡的总数量为35,买面包的数量为50,同时也能看到类似张三用户和不类似张三用户买面包的数量分别为25和10,买牛奶的数量均为25。很明显,买面包的数量集中在类似张三用户。如果管理者有意识地需要得到面包销售情况的关联规则分析,只需要关注类似张三用户的销售情况。即如果现在只是在表4所示事务集上做关联规则分析,按照现有挖掘算法就可以得到如下关联规则: 买牛奶→买面包s=20/100=0.2=minsupp c=20/25=0.8>minconf 表4 A商场交易集的分析 即设定minsupp=0.2,minconf=0.6,根据关联规则挖掘算法能在面向类似张三用户的数据分析上得到有效的关联规则买牛奶→买面包。也就是这条关联规则针对类似张三用户有效,但对于整个交易记录反而不成立。因为买面包的交易主要由类似张三用户完成。由此可见为了完成用户需要得到的具有某一类特征的数据分析对象的关联规则,需要完成具有相似特性的数据分析对象的聚类,从而才能得到有针对性的关联规则;否则,在整个事务集上的关联规则分析,得不到用户心中想得到的有针对性的分析。 2.3 综合OLAP和聚类分析的关联规则挖掘算法 由于数据仓库环境下,用户可以通过数据仓库系统特有的OLAP操作和MDX语言进行多维数据分析。特别是上卷/下钻功能可以在不同综合细节和不同维度层次结构上看到度量值的不同变化,从而用户可以通过这些操作了解到感兴趣的数据分析对象的分布状况。而感兴趣的数据分析对象集中分布的数据集通过本文的分析极大地影响到关联规则挖掘的结果。 另外,在数据仓库环境中集成了与分析主题相关的多数据源的、海量历史数据。这是一般为数据挖掘准备的数据库所不具备的有利条件,而且在数据仓库环境中已经通过抽取、转换和装载(ETL)过程使这些数据达成了一致性和完备性,形成了很高质量的数据。这些有利条件可以进一步地将用于关联规则挖掘的事务集中的数据进行聚类划分,从而可以挖掘出针对某些具有相似特征的聚类有效的关联规则。而这些关联规则常常对于整个事务集由于支持度和置信度不够而被挖掘算法过滤掉。这就导致了用户难以得到比较精确的数据分析结果,而这种有针对性的分析结果在当前提出的主动推荐技术和精准网络广告上尤其重要。 定义2[5]数据库中不可分割的最小单位信息,称为项目,用符号i表示。项的集合称为项集。设集合I={i1,i2,…,ik},项目的个数为K,则I称为K-项集。例如,集合{啤酒,尿布,牛奶}是一个3-项集。 定义3[5]若X,Y为项目集,且X∩Y=∅,蕴涵式X⟹Y称为关联规则,X和Y分别称之为X⟹Y的前提和结论。 规则X⟹Y的支持度s是含有X的记录在全体记录中所占的比率,置信度c是同时含有X和Y的记录数与含有X的记录数的比率。显然,支持度s表示规则的频度,置信度c表示规则的强度,s和c均大于给定阈值的称为强规则,数据挖掘的主要兴趣是强规则的发现。s的最小阈值记为minsupp,c的最小阈值记为minconf。 定义4将事务集中用户感兴趣的项(item)的集合称为用户兴趣项集,并记为Interest-itemset,其中的项称为用户兴趣项。 用户兴趣项一般为挖掘出的规则的后件即为分析对象,即用户想知道提高感兴趣的商品的销售量的影响因素有哪些,而这些挖掘出的关联规则的前提就是能提高作为规则后件的商品销售量的影响因子。用户兴趣项也可以不是挖掘出的关联规则的后件,即是聚类因子,是用户感兴趣的需要聚类的维度或维成员。 提出用户兴趣项的概念是为了表达用户的分析意愿,从而对关联规则的挖掘结果施加用户挖掘目的性的影响。这样不仅可以缩小待挖掘数据集的大小,提高挖掘算法的执行效率,而且可以缩小挖掘出来的关联规则的个数达到用户可理解的程度、以便用户做出自己的选择。用户兴趣项是由用户指定的,表达了用户的分析需求。在2.1节中零售管理人员想分析客户买咖啡和哪些购买项有关联,则买咖啡是用户的兴趣项,在最后的挖掘结果中作为关联规则的后件出现。在2.2节中,用户的分析意愿并没有完全表达为关联规则的后件,而是关注不同用户群的购买面包和哪些购买项相关联。这样可以针对不同用户的购买行为制定促销策略引导消费,在这里用户的意愿中买面包是待挖掘的规则后件,数据仓库中的客户维度则是聚类因子。 定义5将多维数据集中影响用户兴趣项的度量值变化比较显著的维度或维度层次上的成员值称为用户兴趣维度成员,并记为Interest-dim-Member,形成的集合记作Interest-dim-MemberSet。 在定义4的基础上,我们进一步提出了用户兴趣维度成员的概念,用户兴趣维度成员是通过OLAP的切片、切块、上卷/下卷等操作观察引起用户兴趣项的度量值变化比较显著的维度成员值或维度层次上的成员值。比如在2.1节中我们通过下钻操作发现用户兴趣项买咖啡的数量主要集中在商场维度的成员值“商场A”上;或在维度上进行维度成员的聚类划分,选取用户感兴趣的维度成员的聚类作为用户兴趣度成员。比如在2.2节中通过用户聚类后查询“类似张三用户”的用户聚类和“不类似张三用户”用户聚类,发现买面包的数量集中在“类似张三用户”群上,则“类似张三用户”的用户聚类中的客户维度成员作为用户的兴趣维度成员。 算法1综合OLAP和聚类分析的关联规则挖掘 Apriori-OLC(based on OLAP and Clusters) 输入:聚类个数K,事务集I,minsupp,minconf,用户兴趣项集Interest-itemset 输出:关联规则集Associate-ruleset Begin (1) For each i(Interest-itemset do { Ifi为用户感兴趣的关联规则的后件 then通过OLAP上卷/下钻操作或MDX语言发现与项i相关的Interest-dim-Member,并记入集合Interest-dim-MemberSet else i为用户感兴趣的聚类因子,则根据聚类个数K,调用K-平均值聚类算法划分聚类,并选择符合用户分析意愿的聚类中的维成员并入Interest-dim-MemberSet; }; For eachj(Interest-dim-MemberSetdo { Where子句中将维成员j作选择过滤条件; } 在交易数据库中编写Select选择语句,并选择上述Where子句,查询出来的结果作为交易事务集I; 根据minsupp,minconf,在事务集I上调用关联规则挖掘算法Apriori,生成的关联规则集记入Associate-ruleset; (2) Return(Associate-ruleset); END. 算法1即关联规则挖掘算法 Apriori-OLC的理论基础和对关联规则挖掘的有效性在2.1节和2.2节已有很详细的阐述。由此可见算法1可以提高关联规则挖掘结果对于用户的满意度,也改善了当前关联挖掘结果集太大而用户无所适从的应用瓶颈,使得所挖掘的结果具有针对性从而能为用户所想、亦为用户所用。 3.1 算法评价指标及分析 1) 基本评价指标包括:支持度和置信度。 这是事先人为设定的,只有满足大于最小支持度和最小置信度的规则才是最后挖掘出的强关联规则,见本文1.3节的描述。通过本文2.1节和2.2节的分析可知:与基于Apriori算法的关联规则挖掘算法比较,采用算法1通过支持用户预先设定的用户兴趣项并经过OLAP分析和聚类分析得到用户兴趣维度成员,从而精简了待挖掘的数据集,提高了用户感兴趣的规则的支持度和置信度,挖掘出用户真正感兴趣的规则。而这些规则在没有支持用户兴趣项挖掘的Apriori算法中常常因为没有大于最小支持度或最小置信度而被舍弃。 2) 定性评价指标包括:关联规则的简洁度。 关联规则的简洁度表现为规则个数和规则前件包含的项的数目。规则个数和前件中包含项的个数越少,规则越简洁,则用户越容易理解。由于算法1相对于Apriori算法支持了用户兴趣项挖掘,挖掘出的规则更简洁,不包含与用户兴趣无关的规则。 3.2 实际分析项目中的实验验证 利用SQL SERVER 2008 R2提供的SQL Server Management Studio(SSMS)部件建立实验环境下的数据仓库以及SQL Server Business Intelligence Development Studio(BIDS)部件建立一个分析项目包括多维数据模型和OLAP分析及关联规则挖掘。实验中使用的数据来源于海洋环境观测数据。运用Apriori关联规则挖掘,得到如图1所示结果。 图1 关联规则挖掘结果 挖掘出的关联规则过多,通过设置参数可以调整挖掘的个数,但用户仍然不清楚这些规则对整个数据集的针对性,难以达到辅助用户决策的目的。在多维数据集上,通过OLAP的下钻操作得到如图2所示的数据展示。 图2 OLAP的下钻操作结果 从图2的OLAP下钻操作结果,用户很容易看出影响要分析的对象“平均叶绿素浓度”的因子是月份和监测海域。因为月份在关联规则挖掘的数据集中,所以用户可以定义关于月份的一个划分,来看在这个时间段区间里影响平均叶绿素浓度的关联规则挖掘。比如可以限定监测海域=大连市近岸海域、月份=2011/1~2011/3来选择过滤数据集,则可以得到关联规则:当日期2011/1~2011/3⟹平均叶绿素浓度>1.22。由图1在SQL SERVER2008中展示的关联规则依赖关系图可知,在整个数据集上可挖掘到关联规则:当日期<2011/2/21⟹平均叶绿素浓度<0.62。 可见当用户没有通过OLAP分析对分析对象“平均叶绿素浓度”的值在不同影响因子上的分布情况有足够的理解时,根本得不到自己想要看到的关联规则。而整个数据集上挖掘的关联规则由于没有针对性,用户很难进行解读,也很难有助于用户的决策分析。 将监测海域作为聚类对象,与之相关的所在月份及监测的平均叶绿素浓度作为属性数据,采用欧式距离计算相似度并利用K-平均值进行聚类,可得到以下聚类:1) 2011/1-2011/3,大连市近岸海域;2) 2011/2-2011/4,宁波市近岸海域;3) 2011/1-2011/4,上海市近岸海域。 对属于不同聚类上的数据集分别进行关联规则挖掘,得到: 1) 2011/1-2011/3,大连市近岸海域;当日期2011/1-2011/3⟹平均叶绿素浓度>1.22。 2) 2011/2-2011/4,宁波市近岸海域;当日期2011/2-2011/4⟹平均叶绿素浓度>1.35。 3) 2011/1-2011/4,上海市近岸海域;当日期2011/1-2011/4⟹0.36<平均叶绿素浓度<1。 这些关联规则远比在整个数据集上可挖掘到关联规则(由图1可知)“当日期<2011/2/21时⟹平均叶绿素浓度<0.62”更有意义。因为这条规则针对以上任何一个聚类都没有实际指导意义,并且与规则1、规则2这两个聚类的实际相关的关联规则表达的意义刚好相反。 为了克服当前关联规则挖掘方法得到的关联规则集过大,而且因为没有针对性导致用户无法理解的现象,本文提出了用户兴趣项和用户兴趣维度成员的概念,用来表达用户对事务集中数据分析对象的关注,从而将关联规则挖掘算法和用户的分析意愿结合在一起。并进一步给出了基于数据仓库环境下OLAP操作和聚类分析的关联规则挖掘的技巧。新的关联规则挖掘技巧较现有方法可以减少挖掘出的关联规则的数量并真正挖掘出用户所关注的数据分析对象的关联规则。 参 考 文 献 [1] Agrawal R,Imieliński T,Swami A.Mining association rules between sets of items in large databases[C]//ACM SIGMOD International Conference on Management of Data.ACM,1993:207-216. [2] Agrawal R,Srikant R.Fast Algorithm for Mining Association Rules[J].Computer Engineering & Applications,1994,15(6):619-624. [3] Park J S,Chen M S,Yu P S.An effective hash-based algorithm for mining association rules[C]//SIGMOD’95 Proceedings of the 1995 ACM SIGMOD international conference on Management of data,1995:175-186. [4] 何月顺.关联规则挖掘技术的研究及应用[D].南京航空航天大学,2010. [5] 陈伟文.数据仓库与数据挖掘教程[M].北京:清华大学出版社,2011. [6] 征原,谢云.基于划分的聚类个数与初始中心的确定方法[J].计算机技术与发展,2017,27(7):76-78. [7] 余成进,赵姝,陈洁,等.复杂网络中的层次结构挖掘[J].南京大学学报(自然科学),2016,52(5):861-870. [8] 周梦熊,叶岩明,任一支,等.基于密度聚类的协作学习群组构建方法[J].计算机工程与设计,2016,37(10):2710-2716. [9] 缪裕青,高韩,刘同来,等.基于网格聚类的情感分析研究[J].中国科学技术大学学报,2016(10):874-882. [10] 魏瑾瑞.一类基于模型的聚类方法[J].统计与信息论坛,2014,29(2):19-22. [11] 李卫军.K-means聚类算法的研究综述[J].现代计算机(专业版),2014(8):31-32,36. [12] 周粉妹.聚类算法在客户细分中的应用[J].烟台职业学院学报,2006,12(2):46-49.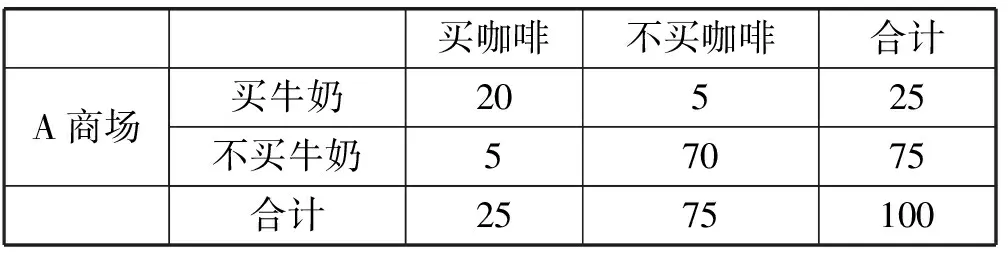

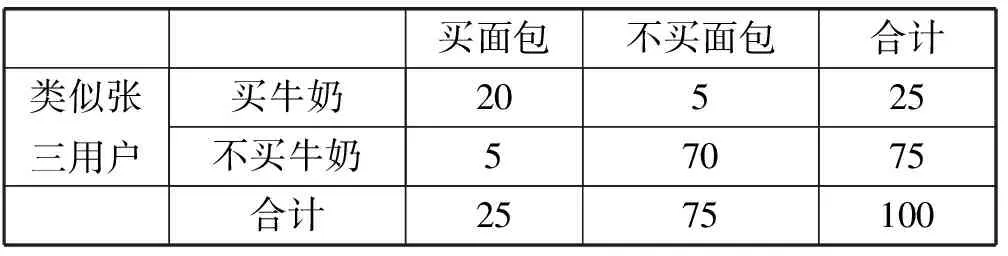
3 关联规则挖掘项目设计及实验验证分析

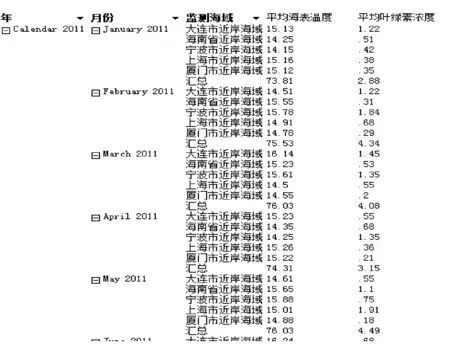
4 结 语
