融合句法特征的汉—老双语词语对齐算法研究
2018-05-15李思卓周兰江周枫郭剑毅
李思卓 周兰江 周枫 郭剑毅
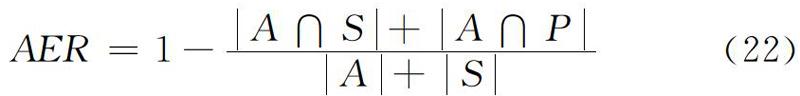


摘 要:词语对齐技术一直是自然语言处理的基础问题。为实现汉―老双语自动词对齐,首先对老挝语存在的修饰词与中心词顺序倒置、结构和位置上的差异性等特征进行了分析,通过分析筛选出一些汉―老双语特征并将这些特征融合,对其构建特征函数,以最小错误率算法为条件,在对数线性模型框架下训练模型参数,将IBM3模型作为基础比较模型,通过逐步添加特征函数从而实现与基础模型的对比。实验证明,该方法可有效提高汉-老双语词对齐质量。
关键词:汉―老双语词对齐;特征函数;最小错误率算法;对数线性模型;IBM3模型
DOIDOI:10.11907/rjdk.172624
中图分类号:TP312
文献标识码:A 文章编号:1672-7800(2018)004-0009-04
Abstract:Word alignment has been regarded as one of the basic problems in natural language processing. In order to realize Laos-Chinese bilingual automatic word alignment, this paper analyzes the features of the inverted order of modifiers and central words in sentences and the differences in structure and location of the Lao. By summarizing the above characteristics, we selecte some of the Laos-Chinese bilingual features and fused these features, constructed feature function and trained the model parameters by the minimum error rate algorithm under the framework of Log-Linear model, based on IBM Model 3. During the experiment, we achieve the contrast to the underlying model by adding feature functions to the alignment model step by step. Experimental results show that this algorithm can effectively improve the quality of the Laos-Chinese bilingual word alignment.
Key Words:Laos-Chinese bilingual word alignment; feature function; the minimum error rate algorithm; log-linear model; IBM Model
0 引言
双语词语对齐由Brown等提出,作为机器翻译的一个隐含过程。Och等在IBM的5个模型基础上开发了词对齐开源工具GIZA++;Blunsom等加入了二叉决策,基于条件随机场改进了算法搜索过程。Liu等进行了创新,在处理词对齐问题时利用对数线性模型,针对不同双语对齐语言将语法特点转化成特征模型,从而提高词对齐效果。
本文对汉-老双语的语言特点进行了深入细致分析。为实现汉―老双语自动词对齐,以汉语为标准,通过总结老挝语特征,将这些特征融合,构建特征函数,以IBM3模型为基础,提出了一种融合多种老挝语依存句法特征函数的词对齐算法,实验证明该方法可有效提高汉-老双语词对齐质量。
1 对数线性模型
本文以IBM 3为基础特征函数,在IBM3的基础上逐步增加针对老挝语语言特点设计的特征函数,从而进行效果对比。
2 汉语-老挝语词对齐特征函数
2.1 IBM模型
本文中,两种不同对齐方向的IBM3特征模型被当作不同特征:源语言和目标语言都可以是汉语或老挝语。
2.2 汉-老词对齐特征函数
2.2.1 老挝语-汉语词语定语倒置函数
与汉语相比,老挝语较为明显的特征是修饰词通常置于所修饰的中心词之后。也就是说,汉语句子成分的排列顺序为:(定语)主语+谓语+(定语)宾语,而在老挝语中顺序是:主语(定语)+谓语+宾语(定语)。例如,汉语的“他父亲开新车”的老挝语为:“(父亲)(他)(开)(车)(新)”。从上面例子可以看出,无论中心词是主语还是谓语,充当修饰功能的定语都是位于中心词之后的,本文称这种现象为修饰区间后置。因此,本文将老挝语句子分成两块,第一块由名词充当的中心词,标记为Nd;第二块由形容词充当的修饰词,标记为Ad。
2.2.2 汉语-老挝语状语末置函数
当源语言为汉语时,就可将此模型加入到以IBM3模型为基础模型的对数線性框架中,其特征函数表示为公式(16):
需要特别指出的是,该特征函数是单向的,即源语言为汉语,目标语言为老挝语。
3 参数训练及搜索
3.1 模型参数训练
3.2 搜索过程
本文通过基于栈的搜索方法,在对齐特征函数权重λ的条件下,将概率最大的双语词语对齐结果从M维词对齐空间搜索出来。
4 实验与结果分析
为了验证该词对齐方法的可行性,在由人工对齐的汉-老双语平行句对上展开实验。基础比较模型为IBM3,在实验语料上得出词对齐实验结果。实验中使用的开发集、测试集和训练集数据如表1所示。
本文使用ICTCLAS(Zhang et al.,2003)对开发集和测试集中的汉语句子进行分词和标注,老挝语使用东南亚语言信息处理平台[14]分词和标注。对开发集和测试集中的各500个句对进行人工对齐,用来优化模型参数和增益阈值。
实验以IBM 3模型作为比较对象,为了更好地体现每个特征函数对汉老双语词对齐的约束作用,将不同于以上3类特征模型按词性细分为几种特征函数,在以IBM 3模型为基础的特征函数上逐步增加前文中定义的几个特征函数。实验结果如表2所示。在同一汉-老双语语料库下,“IBM(both directions)”表示汉-老双语词对齐框架仅仅使用IBM3翻译模型作为特征函数,“+DCL”表示汉语-老挝语状语末置模型,“+USCL”表示汉语-老挝语数词对照模型,“+UDCL”表示汉语-老挝语数词倒置模型,“+PCL(ADJ)”表示在此基础上添加了汉语-老挝语方向定语倒置模型。
待评测对齐结果集合为A,人工对齐结果分为两类集合:确定性对齐集合S和不确定性对齐P,AER计算公式如下:
从表2可以看出,在相同规模的老挝语-汉语双语语料库下,逐渐增加上述特征函数后,对齐效果明显好于仅使用IBM 3模型作为特征函数的对齐模型,这说明修饰区间后置和句子主干对照特征对老挝语-汉语双语词语对齐起到了重要作用。
5 结语
本文在对数线性模型框架下,针对老挝语语言特点设计对齐特征函数,将老挝语语言相关的统计特性加入到词语对齐模型中,以最小错误率算法为条件,在对数线性模型框架下训练模型参数。以IBM 3模型为基础比较模型,提出了一种在对数线性模型基础上融合多种老挝语依存句法特征函数的词对齐算法,在实验中通过逐步添加特征函数到对齐模型,实现了与基础模型的对比。实验结果表明,针对老挝语句法特点设计的特征函数可以明显改善汉-老双语语词对齐效果。下一步会将更多的句法特征和依存句法结构加入到模型中,以进一步提高汉-老双语词对齐效果。
参考文献:
[1] SHEMTOV H.Text alignment in a tool for translating revised documents[C].Proc of the Sixth Conference of the European Chapter of the Association for Computational Linguistics, Utrecht, Netherlands,1993:449-453.
[2] WANG X Z, HE Y L, WANG D D. Non-naive bayesian classifiers for classification problems with continuous attributes[J]. Cybernetics, IEEE Transactions on,2014,44(1):21-39.
[3] RILEY D, GILDEA D. Improving the IBM alignment models using variational bayes[C].Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Short Papers-Volume 2. Association for Computational Linguistics,2012:306-310.
[4] CHERRY C, FOSTER G. Batch tuning strategies for statistical machine translation[C].Proceedings of the 2012 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics,2012:427-436.
[5] TANG J, GENTZLER E. Globalisation, networks and translation: a chinese perspective[J]. Perspectives: Studies in Translatology,2009,16(3-4):169-182.
[6] BROWN P F, PIETRA V J D, PIETRA S A D, et al. The mathematics of statistical machine translation: parameter stimation[J]. Computational linguistics,1993,19(2):263-311.
[7] OCH F J, NEY H. A systematic comparison of various statistical alignment models[J]. Computational linguistics,2003,29(1):19-51.
[8] BLUNSOM P, COHN T. Discriminative word alignment with conditional random fields[C].Proceedings of the 21st International Conference on Computational Linguistics and the 44th annual meeting of the Association for Computational Linguistics. Association for Computational Linguistics,2006:65-72.
[9] TUFID, ION R, CEAUU A, et al. Combined word alignments[C].Proceedings of the ACL Workshop on Building and Using Parallel Texts. Association for Computational Linguistics,2005:107-110.
[10] LIU Y, LIU Q, LIN S. Discriminative word alignment by linear modeling[J]. Computational Linguistics, 2010,36(3):303-339.
(責任编辑:杜能钢)
