基于时空特征的社交网络情绪传播分析与预测模型
2018-04-23熊熙乔少杰吴涛吴越韩楠张海清
熊熙 乔少杰 吴涛 吴越韩楠 张海清
情绪是一种复杂的心理体验.个体可以通过模仿其他个体的肢体动作或面部表情来传播情绪[1],同时情绪会受到各种非语言因素的影响.对情绪的研究引起了多学科的广泛关注,包括经济学、神经科学和心理学.众多研究表明人们会受到其他人的情绪影响,并且这种影响的持续时间或长或短[2].陌生人之间的短暂接触也能传播情绪,例如服务员的“微笑服务”可以提升顾客满意度进而为自己带来小费[3].社交网络特别强调用户创造内容,用户不但是信息接受者,同时也是信息的制造者、发布者和传播者,成为网络舆论形式中不可分割的一部分.在线社交网络也成为人们交流信息与情绪的主要平台.下面以一个直观的例子说明研究社交网络中情绪传播的重要性.2015年,亚马逊网站创始人杰夫·贝佐斯(Je ffBezos)曾在Twitter发布一条推文,宣称自己刚刚实现了运载火箭的软着陆.该条消息以极快的速度在网络上转发和扩散,并且其关注者表现出极大的喜悦,在Twitter上展开了热烈讨论.于此同时,嫉妒和抑郁的情绪在SpaceX公司CEO埃隆·马斯克(Elon Musk)的关注者中迅速蔓延.随后马斯克发布推文表示三年前他的火箭已经完成了六次亚轨道飞行.该条消息迅速为其关注者带来了积极的情绪.从这个例子可以看出,社交网络可以通过用户交互行为使情绪迅速扩散,并充分放大个体的情绪影响力.
本文对多层社交网络中情绪传播的研究主要基于如下几点考虑:1)因为社交网络用户情绪与用户的空间距离和时间跨度有关,所以需要从大规模网络数据中提取时空特征,进而预测情绪传播趋势;2)社交网络为用户提供了多种交互机制,使信息和情绪的传播更加便捷,同时也对情绪传播产生了多维度的影响,因此有必要研究不同用户交互行为对情绪传播的影响.3)利用多层网络分析社交网络的结构和动力学特性,可以突破传统单层网络分析的局限性.多层网络的出现实质是为了突破传统单层网络中连边同质性的限制,各层有不同的拓扑结构并且每层的节点之间不一定有对应关系.
社交网络的结构和动力学特性比随机网络、小世界网络和无标度网络等典型网络更加复杂,而且多种用户行为对情绪传播会产生重要影响.在此基础上,本文的研究主要实现以下目标:
1)在考虑多种用户行为等复杂要素的基础上构建一种社交网络中的情绪传播模型.
2)利用该模型研究社交网络中情绪传播规律,并预测其传播趋势.
本文主要贡献包括:
1)提出一种基于社交网络多种交互行为的情绪传播模型,被称为ECM模型(Emotional contagion model).利用该模型可以分析社交网络中情绪传播的过程与规律.研究发现:多层社交网络中中性情绪用户所占比例随时间逐渐增大,并且正向情绪与负向情绪比例始终接近.情绪传输率越大,用户情绪更容易受到其他用户的影响而发生变化.初始情绪越中立的用户,在演化过程中情绪波动越小,而初始情绪极性越大的用户情绪波动越大.
2)通过实验对比了本文所提模型与其他情绪传播模型,包括:基于情绪的Spreader-ignorant-stifler(ESIS)模型[4]和独立级联模型[5],实验结果表明ECM模型对社交网络中情绪传播具有较好的预测效果.
1 国内外研究现状
情绪可以看作是由许多的关键成分所组成的复杂心理现象,通常包括主观情绪体验、面部表情以及躯体行为等,同时可以利用“效价–唤醒度”的划分方法[6]将情绪分为不同类型:依据效价(Valence)将情绪分为正、负两极,位于正极的称积极情绪,通常带来愉悦感受,如快乐、爱、愉快、幸福等;位于负极的称消极情绪,通常产生不愉悦感受,如忧愁、悲伤、愤怒、紧张、焦虑、痛苦、恐惧、憎恨等;同时依据唤醒度(Arousal)区分情绪的强弱,唤醒度越大,所产生的情绪就越强烈.
不同类型情绪的传播各有特点,利用弗雷明汉心脏研究(Framingham heart study,FHS)[7]的参与者数据可以分别研究高兴、抑郁和孤独等多种情绪在社交网络中的传播过程[8],进而通过广义估计公式分析好友间情绪的关联度,最终发现各种情绪都会在社交网络中传播,并且都能产生长时间的影响.Coviello等[8−9]研究了在线交互行为对传播用户情绪的作用,以阴雨天气为例,发现下雨不仅可以直接造成人们的情绪低落,还可以通过社交网络影响另一个天气晴朗的城市的用户情绪.上述研究主要针对消息的内在特征,但未考虑用户多种行为对情绪传播的影响.
信息传播为情绪传播提供了必要的条件.现有的信息传播模型可以分为两类:图模型和传染病模型[10].图模型以网络结构为基础,主要包括独立级联模型(Independent cascade model,IC model)[5]和线性阈值模型(Linear threshold model,LT model)[11],其中独立级联模型中的用户以一定概率在节点间传递信息,线性阈值模型的每个节点受到邻点的影响力超过自身阈值就会被激活.传染病模型主要通过模拟传染病的传播过程来对信息传播过程建模,其中常见的传染病模型包括SIR(Susceptible-infected-recovered)模型[12]和SIS(Spreader-ignorant-stifler)模型[13]等.这些模型将用户分为几类,各类型用户在某些条件下可以相互转化.近年来,一些不同场景下的信息传播模型陆续被提出.Xiong等[14]提出一种信息扩散模型,该模型在SIR模型的基础上增加了一种保留状态,用于表示用户收到信息但未做出决策的状态.Wang等[4]提出了基于情绪的SIS(ESIS)模型,将情绪划分为若干细粒度类型,边权值等于用户间带有某种情绪的消息的转发数,而接收消息的概率由传播概率和转发强度共同决定.虽然上述模型总结了信息和情绪传播过程中的部分特征,但是却忽略了情绪传播的多维度时空特性.
Boccaletti等[15]将多层网络视为类似于一个由多个单层网络组成的网络集,每个单层网络构成一个网络层,以(G,C)表示整个多层网络,其中,G是由一组单层网络组成的集合,C是包含所有不同层间连边的集合,进而形成网络层内的邻接矩阵和网络层间的邻接矩阵.Kivela[16]进一步考虑多层网络中同一层的网络节点之间存在多重类型连边的情况,即同一层中网络又可进一步分为“亚层”,提出用张量分析的形式来表示这类多层网络整体的邻接矩阵.社交网络多种交互机制所构成的多层网络结构具有其特殊性,例如转发关系网是关注关系网的子网,上述抽象的多层网络分析方法无法获得满意的结论.
社交网络的多层结构使信息和情绪可以同时在多个拓扑结构中传播,增加了研究的复杂性.Yagan等[17−18]研究了在线和真实社会网络中信息的传播规律,通过数学解析与模拟仿真的方法,发现获得信息的用户比例存在阈值,当该比例大于阈值时,信息将会大范围传播,并且倾向于在同一个社区中传播.Kim等[19]研究了信息跨多个异质社交网络的扩散动力学.网络用户通过RSS订阅器或社交网络聚合器等工具,跨平台浏览各种类型的新闻,使不同社交媒体发生耦合.上述研究的不足在于:跨平台采集数据具有较大难度,即使利用社交网络聚合器等工具取得数据,仍然难以将同一个用户在不同平台中的数据对应起来.
社交网络的用户情绪更多地受用户行为的影响,例如“转发”和“提及”这两种动作会为情绪传播带来不同的影响:“提及”对单个用户的影响力较大,但影响范围不及“转发”.本文正是综合考虑不同用户行为对情绪传播的影响,构建社交网络中的情绪传播模型来分析情绪传播的特征.
2 情绪传播模型工作原理
2.1 建模过程
如图1所示,构建基于多层社交网络的情绪传播模型包括四个主要步骤:
1)从在线社交网络Twitter和新浪微博中采集一段时间的用户信息及其行为关系信息,以及在这段时间内发送的文本消息.将这些数据进行预处理以供分析使用.
2)用户的多种交互行为构成多层网络,并且用户对其好友随后的信息会产生影响.利用统计方法分析不同时间点和不同网络位置的用户情绪及其交互行为数据,以提取情绪在空间和时间上的多维度传播特征.
3)构建社交网络中的情绪传播模型,其中包含若干行为子层.每个子层根据该行为的交互历史形成不同拓扑结构,并且每个子层中拥有不同的情绪传输率.
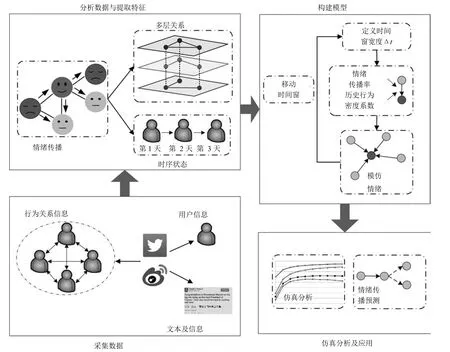
图1 社交网络中情绪传播分析及模型构建示意图Fig.1 Analysis and modeling of emotion contagion in social networks
4)基于采集的数据对该模型进行仿真实验,分析情绪的传播规律,并利用该模型预测情绪的传播趋势.
2.2 多种交互与多层网络的映射
利用文献[20]中提到的方法可以将用户不同交互机制形成的多层社交网络用G=∪Gα来表示,其中,α表示不同子层.四个子层分别为关注子层(α=F)、转发子层(α=R)、提及子层(α=M)和回复子层(α=S).每个子层中的用户都可以表示为节点.这些子层存在以下特征:
1)各子层内部的连边分别具有不同的含义:关注子层的每条边表示两个用户间存在好友关系;转发子层的每条边则表示用户转发了其他用户的消息;提及子层的每条边表示用户在自己发布的消息中提到了其他用户,该机制可以用于专门构建用户间的对话关系,或者仅仅是为了提醒某人查看该消息[21],从而使被提及用户阅读该消息的几率大大增加;回复子层中每条边表示用户回复其他用户的消息.
2)关注子层是其他子层的基础,提供了信息和情绪传播的通道,而其他每个子层的节点集合和连边集合都是关注子层相应集合的子集,因而其他子层的节点分布比关注子层稀疏,这表明用户只会主动挑选部分消息进行转发、提及或回复,而不像查看消息那样是一个被动接受的过程.其他交互行为都受到关注子层的非规则拓扑结构的影响.
3)用户的关注行为在一段时间内相对稳定,不容易发生变化,因此用户在较短时间内(1小时至10天)的交互只需要考虑转发、提及与回复这三种行为.
这三个行为子层中情绪传输效果存在较大差异,因此采用情绪传输率[20]来衡量一对用户间传播情绪的能力.情绪传输率受到用户行为的影响,即不同的行为子层拥有不同的情绪传输率.
3 基于多层社交网络的情绪传播模型
3.1 模型描述
社交网络用户间的不同交互机制构成了具有不同拓扑结构的用户关系网络,这些网络之间相互依存并相互影响.利用多层网络分析社交网络的结构和动力学特性,可以突破传统单层网络分析的局限性,多维度挖掘情绪传播的特征.多层网络的出现实质是为了突破传统单层网络中连边同质性的限制,各层有不同的拓扑结构并且每层的节点之间不一定有对应关系.
Kramer通过发现社交网络用户可以影响其好友情绪,并且影响距离最大为3(用户与其直接好友之间的距离为1),持续时间最多为3天[22].这一事实说明用户间情绪具有时间关联性和空间关联性.同时,社交网络中用户行为的多样性使情绪传播又具有特殊性.为有效分析情绪传播规律,并预测其传播趋势,本文提出基于多层社交网络的情绪传播模型(Emotional contagion model,ECM模型).
为简化模型构建,本模型基于以下假设:为方便表示情绪的传播过程,可以将连续时间轴划分为若干细小时间段,其中每个时间段称为一个时步.在一个时步中,两个节点最多完成每种交互行为各一次,并且该行为子层上的所有节点(用户)依次更新情绪状态.
如果用ρ表示关注子层的节点密度,它在整个模型演化过程中保持不变.α表示某一个行为子层,则该子层的节点密度ρα<ρ,可以表示为ρα=ργα,其中,γα称为密度系数,由[t−∆t,t]内该层中发生交互行为的用户分布决定.
α子层这两个用户之间在时步t新出现连边的概率为γα,即α子层的密度系数.假设α子层中用户i与j之间存在连边,而用户k与j之间不存在连边,则i和k分别对j采取α行为的概率为:
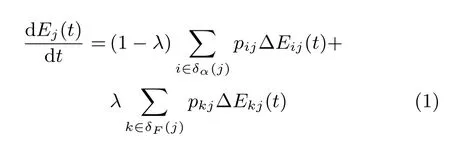
其中,∆Eij(t)和∆Ekj(t)表示节点i和k与节点j在时步t的情绪差,即 ∆Eij(t)=Ei(t)−Ej(t),∆Ekj(t)=Ek(t)−Ej(t);δα(j)和δF(j)分别表示j在α层和关注子层的邻点集合;pkj表示k与j之间新产生连边的概率,该值约等于γα,而pij则表示用户i与j之间在时步t将发生交互的概率,可以表示为下面的公式:

如果用户i对用户j在[t−∆t,t]内采取了α行为,则表示α子层中用户i和用户j之间的连边权重,可以按以下公式计算:
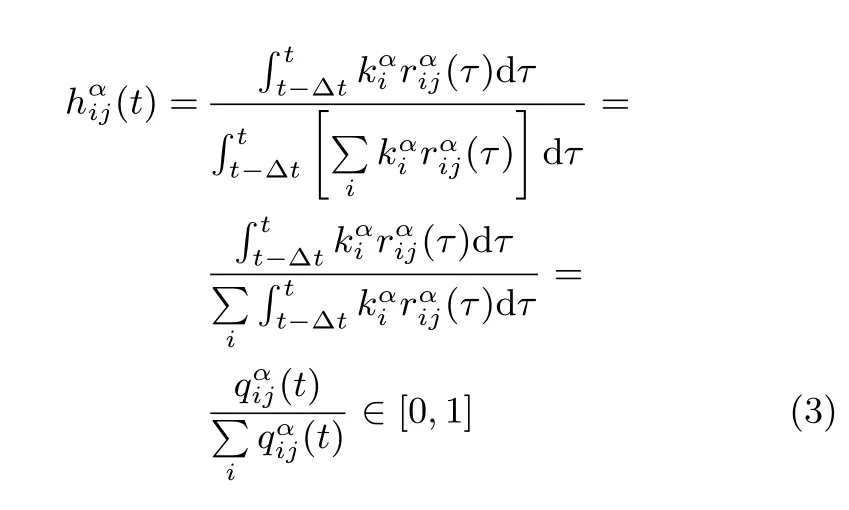

在式(3)中,分子与分母分别表示在时间区间[t−∆t,t]内,j与i之间以及j与其在α层所有邻点之间发生该行为的次数.因此,是一个基于历史行为数据的时变参数,随时间窗的移动而改变.式(1)表示用户j模仿相邻用户的情绪,即情绪从相邻用户向j扩散,因此该式可以转换为:


最后,同时考虑3个行为子层,可以得到:
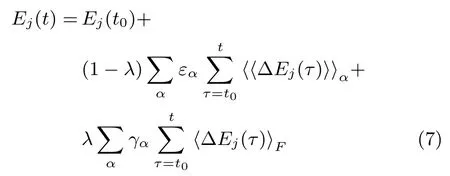
式(7)表示用户j在时步t的情绪表达式,其等于该用户与相邻用户情绪差异的时间累积和行为累积.
3.2 模型实现
本文提出一种基于多层社交网络的情绪传播模型–ECM 模型.该模型包括三个行为子层,并且每层的拓扑结构各不相同,分别由用户的交互历史决定.算法过程简单描述如下:
算法1.基于多层社交网络的情绪传播模型–ECM模型

算法共执行sn个时步(第1行),在每次循环结束时需要更新时步;每个时步的处理过程可以分为两个部分,分别用于计算[t−∆t,t]的时间段中每种行为发生的次数(第2~4行),以及更新每个用户的情绪值(第5~9行).

表1 数据集统计信息Table 1 The statistical information of the datasets
3.3 算法时间复杂度分析
为了说明ECM模型具有较好的时间性能,可用于预测情绪传播趋势,需要分析ECM模型的时间复杂性.每个时步的流程都分为两个部分,第一部分用于计算每种行为的发生次数,其时间复杂度为O(n2),第二部分用于更新用户情绪,其时间复杂度也为O(n2).综合上述步骤获取整个ECM模型的时间复杂度为O(m×n2),其中,m和n分别表示时步数和用户总数.
4 实验与分析
4.1 数据集描述
Twitter是一种基于互联网的社交网络,在世界范围受到用户的广泛欢迎.据统计,2015年Twitter的月均活跃用户量达到2.71亿,成为传播信息和情绪的有力工具.与此同时,作为国内最大的微博网站,新浪微博每天也有超过1亿条微博内容产生.目前常用的社交网络数据集主要有以下两个:
1)斯坦福大学SNAP实验室提供的Higgs网络数据集[23].欧洲核子研究组织(CERN)于2012年7月4日宣布发现Higgs玻色子,该消息引起社交网络上的广泛议论.该数据集包含7月1日~7月4日该消息在Twitter传播过程中的相关信息,其中包括好友、转发、提及和回复这四种关系分别构成的网络,以及每次行为发生的时间点.由于该数据集不包括任何文本信息,因此无法提取用户行为发生时的情绪状况,需要人为指定被传播消息的情绪值.
2)数据堂提供新浪微博数据集.其中包含用户好友关系和他们对12个主题相关信息的转发关系,但是未包含提及与回复这两种行为数据.
现有数据集具有一定局限性,无法全面分析本文模型.因此本文利用爬虫工具从Twitter和新浪微博网站重新采集了大量数据.其中Twitter数据集包括33070个用户及其关系信息,以及2016年3月间5起热门话题的相关文本内容;新采集的新浪微博数据集包括6344个用户及其关系信息,以及2017年5月间的9起热门事件的相关文本内容.表1对比了本文新采集的数据集与现有数据集的主要统计信息.
4.2 文本情绪量化
本文采用情感分析工具SentiStrength[24]对情绪传播过程进行量化分析.每条消息都同时包含正向情绪或负向情绪,因此每条消息都被同时赋予一个正向情感值S+(t)与一个负向情感值S−(t).这两个值分别取1(中性)到5(强正向和强负向)之间的一个整数值.为使用统一的度量方法来衡量消息文本的情绪,可以将情绪极化值定义为正向情绪值和负向情绪值之和,即极化值S(t)取值范围为−4(S+(t)=1,S−(t)=5)到+4(S+(t)=5,S−(t)=1).当正向和负向情绪值相同时(S+(t)=S−(t))则为中性情绪(S(t)=0).当情绪较弱时,极化值接近0,可以近似看作中性情绪.
此外,可以利用情绪极化值来定义情绪倾向.S(t)取值为−4到−2表示负向情绪倾向;S(t)取值为−1到1表示中性情绪倾向;S(t)取值为2到4则表示正向情绪倾向.如果需要在时变模型中表示情绪值,则可以使用连续情绪值,即采用θ1表示正向情绪和中性情绪的界线,θ2表示负向情绪和中性情绪的界线.如果连续情绪极性值服从[−4,4]的均匀分布,即a=−4,b=4,并且三种情绪取值区间宽度相同,则有下面公式:

利用式(8)可以求得θ1≈1.33,θ2≈−1.33.
为对比不同两个数据集的文本情感,本文仿照SentiStrength对新浪微博数据集的中文文本进行分词和情感分析,主要IKAnalyzer分词工具[25]和BosonNLP情感词典[26]对新浪微博的文本进行情感标注.
每个用户通过三种行为影响其邻居的情绪.通过对本文采集的数据进行分析,可以发现一系列特征.统计数据来自非连续三天的平均值并且每个时步定义为2个小时.在每个时步中,用户情绪的变化可以表示为各种行为出现频率以及不同行为情绪传输率的线性函数[20].利用线性回归方法分析两个数据集,可以得到置信度为95%时三个子层的情绪传输率.如表2所示,在两个数据集中,提及子层的情绪传输率都最大,表明该行为更利于情绪在网络中的扩散.并且新浪微博中情绪传播更加迅速,主要是由于新浪微博中公共消息更多,更容易受到用户的关注并形成情绪聚集.
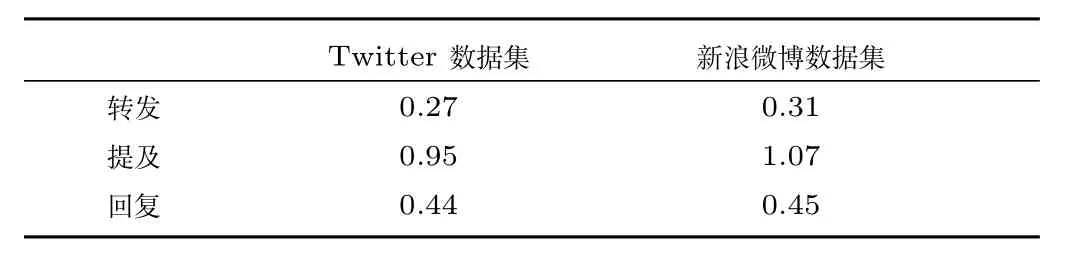
表2 两个数据集不同子层的情绪传输率Table 2 The transimisibilities on different layers in the two datasets
4.3 情绪传播特征分析
社交网络的结构和动力学特性比随机网络、小世界网络和无标度网络等典型网络更加复杂,而且各种因素都会对社交网络中的情绪传播产生重要影响.本小节将利用ECM模型分析社交网络中的情绪传播过程及其特征.由于两个数据集中的实验结果近似,因此本小节仅展示在Twitter数据集上的结果.
用户之间存在某些特殊关系,例如亲戚、朋友或拥有相同的爱好.用户通过这些现实世界的关系产生在线关注关系,情绪也会因为这些关系而在网络中传播.如图2所示,可以发现:具有某种情绪的用户在一段时间内发布的消息中都会带有该情绪倾向,并且该情绪会影响该用户的直接或间接好友.同时,情绪传播过程具有明显的局部性,例如用户一般只能影响距离在3以内的用户,并且距离越近关联度越大,而对距离大于3的用户几乎没有影响.此外还可以从数据中发现抑郁、孤独和愤怒等负向情绪比愉快、兴奋等正向情绪更容易传播.
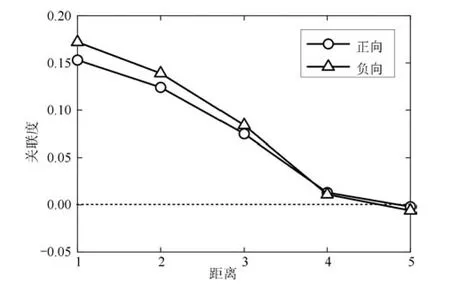
图2 用户间情绪关联度与距离之间的关系图Fig.2 Relation between emotional correlation and distances
利用ECM模型可以定量展示社交网络用户情绪的动态传播过程.如图3所示,三种情绪具有相近的初始比例,比例之差不超过4.0%.初始阶段,三种情绪同时在网络中传播,中性情绪减少,其他两种极化情绪增多.这主要是因为网络的非均衡性会产生一些中心用户,他们的极化情绪会对周围用户产生较大影响,使他们也同样“情绪化”,中性情绪与极性情绪的比例差达到10.1%.用户在与多个邻居的交互中获得了更多的信息,极化情绪用户逐渐减少,而中性情绪用户所占比例随时间逐渐增大,并且正向情绪与负向情绪比例始终接近,比例差最大仅为2.5%.在演化趋于稳定时,中性情绪处于主导地位,约占57.1%的比例,同时存在一部分用户仍然持有极性情绪.通过分析网络情绪分布,可以发现这些极化用户之间形成了多个社区,每个社区内部用户相互影响,情绪趋同,却不易随其他社区的情绪而改变.
为分析不同行为对情绪传播的影响,需要研究情绪在单一行为子层的传播过程,同时忽略其他子层的影响.图4表示情绪转换数(即情绪从一种倾向转换为另一种倾向的次数)与参数的关系,其中横坐标表示用户初始情绪与节点度的乘积的平均值.不同的子层具有不同的情绪传输率,其中提及行为的传输率最高,而转发行为的传输率最小.图4中三条曲线的关系表明情绪传输率越大,用户情绪更容易受到其他用户的影响而发生变化.对同一条曲线,初始情绪越中立,则用户情绪波动越小,例如初始平均情绪值为0时,则用户在演化过程中仅平均改变2次情绪倾向.而初始情绪极性越大,则用户情绪波动越大.横坐标为150时,平均每个用户约改变24次情绪倾向.尤其是具有较大节点度的中心用户,其极性情绪更能影响其他用户.
4.4 模型对比
为了展示ECM 模型的预测效果,可以将ECM 模型、ESIS模型和IC模型与真实数据进行对比实验.鉴于这些模型之间略有差异,因此需要对参数进行一定的调整,使它们在同一基准上进行比较,具体参数调节过程如下:
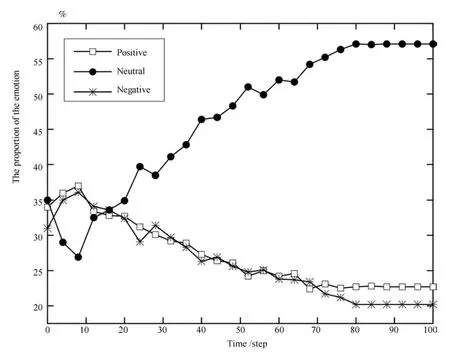
图3 ECM模型的演化规律Fig.3 Evolutionary process of ECM model

图4 情绪转换数随用户初始情绪与节点度乘积的变化Fig.4 The relation between the number of individual emotional tendency changes,the degree and the initial emotion
1)ESIS模型将情绪细分为六种.首先根据某用户转发的含有该情绪的消息数来计算该用户的该种情绪值.然后将这六种情绪归为正向、负向和中性三类:高兴是正向,惊讶是中性,而愤怒、伤心、害怕和厌恶则是负向.最后某用户在某时步内的情绪值即为他在该时步内所有消息的各情绪值之和.
2)修改IC模型,使边的权重表示用户间的影响力,而不仅仅是表示获得信息的概率,因此节点即使受到该情绪影响也不会停止演化.另外,该模型使用与ECM模型相同的情绪值计算方法:当用户收到一个消息,用户当前情绪值为该消息的情绪值与之前用户情绪值之和.
3)ESIS模型和IC模型也被看作是多层模型,只不过每层的拓扑结构相同.
4)所有演化时步都被固定为2个小时.
通过对ESIS模型和IC模型的时间分析,可以发现它们的时间复杂度均为O(m×n2),其中m和n分别表示时步数和节点数.这与ECM一致,表明三种模型拥有近似的执行时间.此外,图5展示了三种模型与真实数据在不同演化时步下的接近程度,其中纵坐标表示节点情绪值与节点度的乘积平均值.
从图5可以看出,ESIS模型比其他模型拥有更好的数据拟合性.IC模型最简单,而ESIS模型由SIS模型演化而来,可用于解释信息传播的过程.但是这两种模型偏离真实数据较多,因为它们都只考虑了情绪本身的因素,而未考虑多种网络行为对情绪传播的影响.对比实验表明,ECM模型与其他两种模型具有相同的时间复杂度,但是与真实数据的拟合度更好.此外,图5中几种曲线都具有类似的走向,先是快速上升,然后缓慢下降.这是因为热门事件通常可以在短时间内激起人们的广泛关注并出现极化情绪,随着时间的推移,人们的情绪会慢慢趋于理性和稳定.
分类算法的分类效果可以通过混淆矩阵中的准确率(Precision)、查全率(Recall)和F值(F-measure)等三个指标[27]来衡量.本文将情绪传播中正向、中性和负向三种情绪分别归属到两个分类:正向情绪为一类,中性和负向情绪为一类,则两个分类之间的界线就是θ1.θ1为典型值1.3时三种模型的分类效果如图6所示,显然ECM模型拥有更好的分类准确率.新浪微博的公众信息较多,用户易受到中心用户的影响,不易随着其他个人用户情绪而发生改变,因此分类准确率较高;而Twitter的用户通常关注了较多的个人好友,其情绪也容易受到这些好友的影响,导致分类准确率降低.
三种模型中F-1值随参数θ1的变化曲线如图7所示,可以看出ECM 模型的F-1值比其他两种模型提高了2.7%~7.8%,说明其拥有更高的分类准确率.三种模型的F-1值在θ1=1.5附近达到最大值,这是因为在情绪值均匀分布的条件下,此时三种情绪都拥有近似的用户数量.ECM模型的曲线波动较大,并且与其他两种模型的F-1之差也在θ1=1.5附近达到最大,说明ECM模型对参数θ1最为敏感.随着θ1的增大或减小,情绪分布都会发生变化,从而导致情绪预测准确率的下降.
三种模型中F-1值随用户数量的变化曲线如图8所示.可以看出,ECM模型将分类准确率提高了1.8%~6.2%.三种模型的F-1值都会随用户数的增大而增大,这是因为大规模的训练集将会提高分类准确率.ECM模型描述情绪传播特征更加充分,因此F-1值上升更加迅速,在用户数为1900时达到最大值70.5%.
5 结束语
本文提出一种基于社交网络多种交互行为的情绪传播模型,利用该模型分析社交网络中情绪传播的过程与规律.在集的社交网络数据基础上进行仿真分析,发现中性情绪用户所占比例随时间逐渐增大,并且正向情绪与负向情绪比例始终接近.情绪传输率越大,用户情绪更容易受到其他用户的影响而发生变化.初始情绪越中立的用户,在演化过程中情绪波动越小,而初始情绪极性越大的用户情绪波动越大.最后,本文还对比了该模型与其他情绪传播模型,如:基于情绪的SIS模型和独立级联模型,实验表明ECM模型对社交网络中情绪传播具有较好的预测效果,预测准确率比其他两种模型提高1.8%~7.8%.
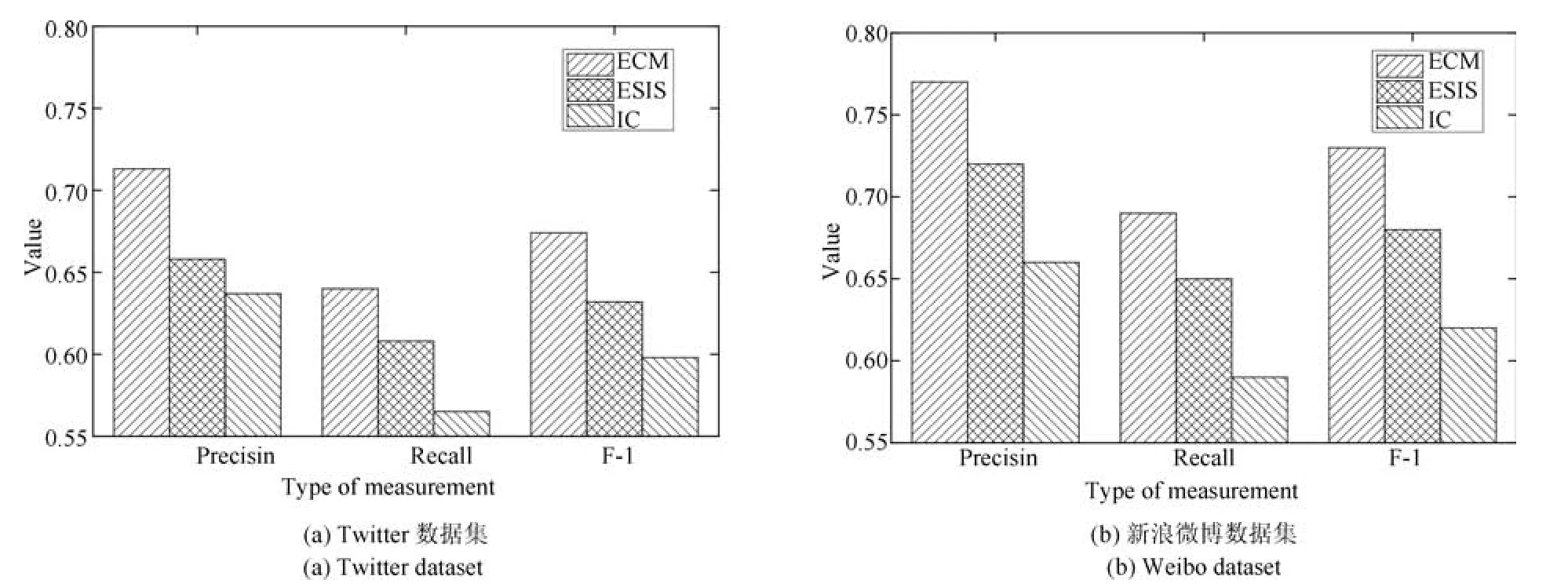
图6 三种模型分类度量值的对比Fig.6 The comparison of classification measurements of the three models
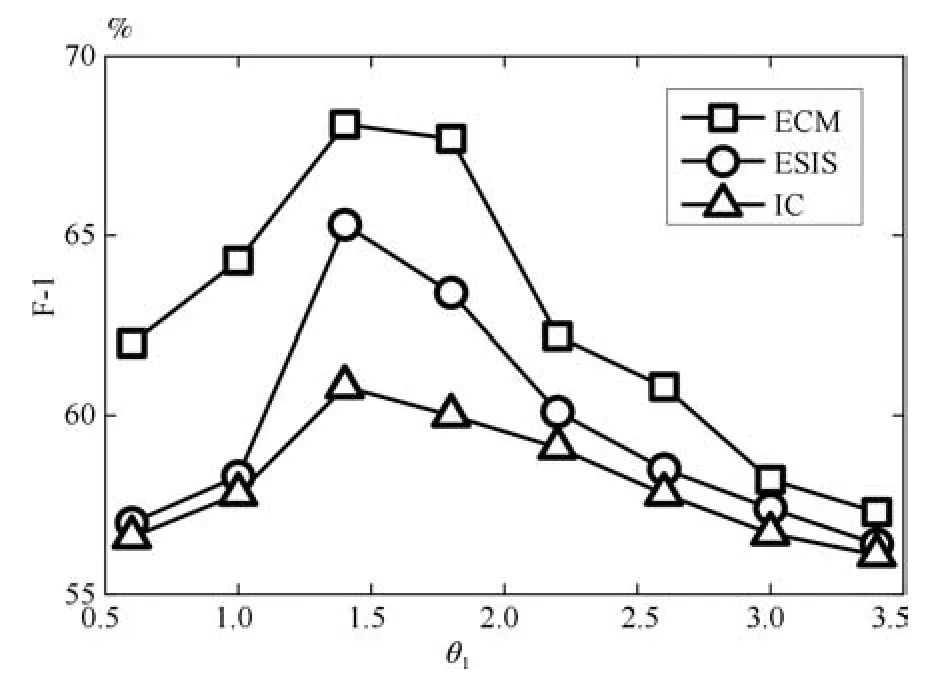
图7 三种模型中的F-1值随θ1的变化规律(Twitter数据集)Fig.7 F-1 changes withθ1for the three models(Twitter dataset)

图8 三种模型中的F-1值随用户数的变化规律(Twitter数据集)Fig.8 F-1 changes with the number of users for the three models(Twitter dataset)
本文工作仍然存在一些需要改进的地方,例如:
1)社交网络中的情绪传播是一个复杂的过程,目前很难考虑所有网络因素的影响,例如网络结构的动态演化.也就是说,用户倾向与拥有相近情绪的用户建立新的连接,而与相反情绪的用户断开连接.分析多种因素对情绪传播的影响将是未来一项有价值的工作.
2)本文的工作基于情绪分析算法,并采用了SentiStrength等工具和手段对消息文本进行分析.虽然比之前的分析方法准确,但仍然无法解析人类语言表达中的微妙情绪,例如挖苦和嘲讽,也无法很好地识别一句话中的多种情绪.情绪的这些特点都给其识别带来了困难,需要在未来进行深入研究.
