基于特征选择的K-means聚类异常检测方法
2018-04-10◆樊蓉李娜
◆樊 蓉 李 娜
基于特征选择的K-means聚类异常检测方法
◆樊 蓉 李 娜
(四川大学计算机学院 四川 610065)
K-means算法是一种采用距离作为相似性评价指标的聚类算法,其快速简洁的特点在异常检测场景中有一定的应用价值。但是,传统的K-means聚类算法在选取初始中心和度量相似性上有一定缺陷。针对传统的K-means算法中存在的问题,本文对原有的方法进行了改进。第一,在初始化聚类中心时选取了一种优化的方法作为初始聚类中心,替代原有的随机选择方法以减少计算量和迭代次数。第二,采用基于信息熵属性加权的样本相似性度量来进一步精确样本差异。实验过程中,针对异常检测数据含有冗余特征,对样本数据做了冗余特征过滤,实验结果表明改进之后的方法较传统的K-means算法有更好的检测效果。
K-means算法;异常检测;聚类;冗余特征
0 引言
异常检测就是假设入侵行为异常于正常行为,如果当前行为与正常行为存在一定的偏差就认为系统受到攻击[1]。这个特点使其有能力识别未知类型的攻击,异常检测是入侵检测方面的一个研究热点。从Wenke Lee[2]使用数据挖掘方法得到属于不同数据的行为轮廓开始,聚类算法在异常检测方面广为使用。江颉[3]和Aljarah[4]针对K值选取提出的改进聚类算法,周涓等人[5]针对中心选取提出的一种多个聚类中心选择算法等。K-means聚类算法在异常检测方面有着广泛的应用和良好的效果。但是存在几个问题,一是K个中心初始位置的选取和确定,中心初始位置选择不好会导致迭代次数增多和计算量增大,严重影响聚类效果;二是样本度量问题,K-means算法采用各属性无差异的欧式距离来计算样本之间的相似性,没有考虑不同属性权重对样本的影响使得相似性度量不准确;三是冗余属性和噪音会对聚类结果产生偏离,计算时对效率影响较大。针对方法涉及的几个问题,本文提出一种基于特征选择的K-means聚类算法。首先,采用Fisher特征选择对特征重要度排序,用顺序前向最优搜索的方法快速确定所选特征数量由小到大的最优特征子集,所选的特征子集能最大程度的代表原始特征,并且去除不必要的特征和噪音。其次,采用一种优化的方法来选取初始聚类中心以减少计算量和迭代次数;最后,计算各属性的信息熵作为属性权重来度量样本之间的差异,区别不同属性对样本的贡献。本文提出的方法在异常检测方面取得不错的检测效果。
1 一种改进的K-means聚类算法
1.1 K-means聚类算法
K-means算法是一种典型的基于距离度量相似性的聚类算法,算法的主要思想是差异最小最相似,根据样本之间的相似程度划分至相应的簇内[6]。具体流程如图1所示:

图1 K-means聚类流程
1.2信息熵属性权重确定
信息熵是一种客观权重确定方法,它是在原始数据的基础上,表示信息有用程度大小的一种度量方式。具体流程如图2所示:

图2 信息熵属性权重计算
1.3改进的K-means聚类算法
传统的K-means聚类算法选择聚类中心的方法为随机选择,导致聚类迭代次数增多和计算量增大,陷入局部最优以及样本各属性的平等对待影响聚类效果。为了消除这种影响,本文提出的方法在原有的方法上进行改进,一定程度消除了以上因素的影响。具体流程如图3所示:

图3 改进k-means聚类流程图
2 基于特征选择的K-means聚类异常检测方法
2.1 Fisher特征选择
Fisher特征选择是一种基于距离度量的过滤式特征选择算法。其基本思想为将不同类样本间的距离最大化及将同类样本间的距离最小化[7]。Fisher特征选择算法流程如下图4所示:

图4 Fisher分特征排序
2.2基于特征选择的K-means聚类异常检测
首先对输入样本根据Fisher分进行特征选择,采用前向序列搜索选出能够代表样本的最优特征子集,然后基于改进的K均值算法进行聚类,方法流程如图5所示。
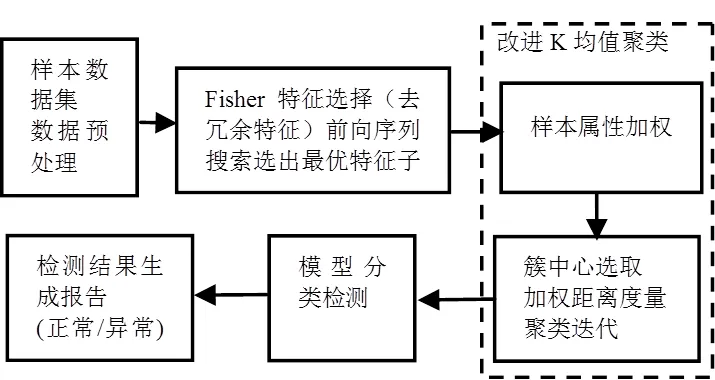
图5 基于特征选择的K-means聚类异常检测流程
3 实验测试与分析
3.1实验数据与评价指标
实验将选取10000条样本记录作为实验数据集输入,每一条样本记录由41维向量特征组成。在进行实验之前,对样本记录做标准化和归一化处理以消除样本差异及覆盖等影响。实验效果则采用检测率、误报率、检测时间为评价指标。其中,样本集来自当前入侵检测领域权威数据集KDD,实验平台为开放的数据挖掘平台weka。
3.2实验设计与结果分析
本文设置三组实验:
第一组实验的目的是证明本文的特征选择所选出的特征对于聚类检测具有可行性。实验采用Fisher分对抽样的41维数据进行排序的结果如表1所示:

表1 Fisher分对数据特征排序
为了得到最优的特征子集并且不丢失必要的特征,本文采用前向序列搜索依次加入5、3、2、1个特征进行聚类的结果如图6所示:
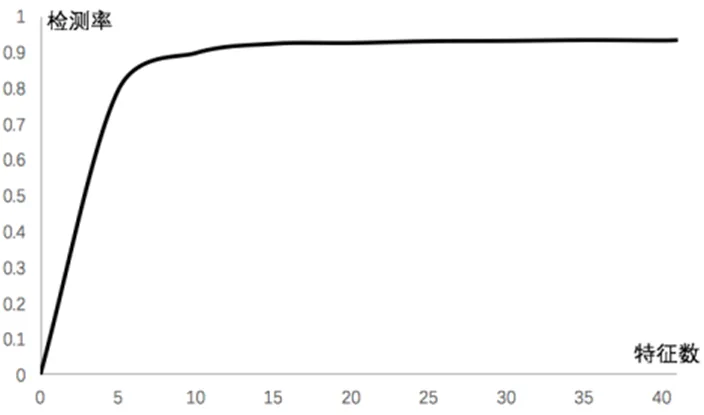
图6 特征数与聚类检测率结果
通过实验,从图中可以看出,首先加入前5个特征有较好的检测率,然后逐次加入3、2、1个特征时检测率有所提高,当所加入的特征数为11时,检测率趋于稳定,通过前向序列搜索得出最优特征子集为{23 32 24 12 3 2 33 27 34 28 4},相比于原始41维数据,得到的最优特征子集能很好的得到检测效果,与原始的数据检测率相当,有效的减少了计算资源。
第二组实验设计了2000条数据样本,分别采用本文改进的K-means聚类方法和传统方法做聚类对比实验,实验检测结果如图7所示。
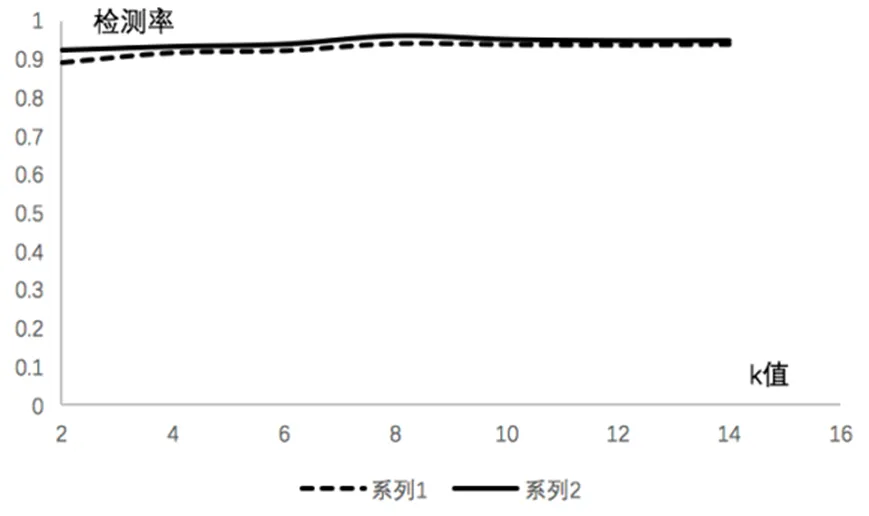
图7 传统K-means与改进K-means检测率对比
图7中序列1代表传统的K-means算法,序列2代表改进的K-means算法。实验数据分析可以得出在K取不同值情况下检测结果也会随之变化,当K取值为8时,两种方法的检测效果都达到最佳。由于改进的方法优化聚类中心的选取,采用信息熵加权的距离计算,使得检测率高于传统方法。
第三组实验的目的在于验证本文提出的方法能够取得较好的检测结果。设计两组相同数据集,采用两种方法做对比实验,重复实验10次,实验取平均值。检测结果如表2所示:

表2 传统K-means与本文方法检测结果对比
通过本组对比实验可以看到本文改进的方法在检测的误报率相当的情况下,在检测率上有一定的提高,在检测时间上也有着显著的缩减。由于采用特征选择去除不必要特征使得数据维数缩减,减少了聚类时间,去除的噪音数据也消除了对样本相似性度量的影响。同时,优化的聚类中心选取与加权的距离度量也使得检测的检确率有一定的提升。
4 结束语
本文通过Fisher进行特征选择过滤了冗余特征,大大缩减了检测时间,提高检测效率,同时采用改进的K-means算法进行聚类检测提高了检测率。经实验验证可以得到,本文提出的改进的K-means聚类异常检测方法相较于传统的方法有着较好的检测效果。
[1]卿斯汉, 蒋建春, 马恒太等.入侵检测技术研究综述[J]. 通信学报,2004 .
[2]Lee W, Stolfo S J.A framework for constructing features and models for intrusion detection systems[J].ACM Transactions on Information and System Security(TISSEC),2000.
[3]江颉, 王卓方, 陈铁明等.自适应AP聚类算法及其在入侵检测中的应用[J].通信学报, 2015.
[4]Aljarah I,Ludwig S A.Parallel particle swarm optimization clustering algorithm based on MapReduce methodology[C]/ /Proc of the 4th World Congress on Nature and Biologically Inspired Computing. [S.l.]: IEEE Press,2012.
[5]周涓, 熊忠阳, 张玉芳等.基于最大最小距离法的多中心聚类算法[J].计算机应用, 2006.
[6]李锐,李鹏,曲亚东,王斌译.Peter HARRINGTON.机器学习实战[M].北京:人民邮电出版社, 2013.
[7] 程正东,章毓晋,樊祥等.常用Fisher判别函数的判别矩阵研究[J].自动化学报,2010.
[8]CHENG Zhengdong,ZHANG Yujin,FAN Xiang,et al.Study on Discriminant Matrices of Commonly-Used Fisher Discriminant Functions [J]. SctaAutomaticaSinica,2010.
国家重点研发计划(2016yfb0800604,2016yfb0800605),国家自然科学基金项目(61572334)。
