基于CloudSim的分类负载均衡调度模型
2018-03-27,,
,,
(中国电子科技集团公司 第五十四研究所,石家庄 050081)
0 引言
负载均衡技术是集群工作的关键技术,负载均衡算法是影响集群效率的决定性因素, 因此研究并提出一个性能良好的负载均衡调度算法对提高集群工作具有重要意义。
对于软件负载均衡调度技术,研究学者一般重点解决节点数据倾斜问题以及数据分类问题[1-3],采用改进算法对资源进行分类以实现“合适的资源服务于合适的任务”这一原则[4-5],通过反馈机制实现负载的实时监测以更精确表示节点负载情况[6-7]。
本论文将节点负载的研究和资源分配的研究结合起来,通过区分不同的任务请求,使得同一类型的请求分派到同一类型的服务器节点上处理,以此实现资源分配最优,效率最大化实现,系统也达到更好的均衡效果。
1 分类负载均衡模型
根据集群任务调度的过程,本文抽象出一种负载均衡模型,即分类负载均衡调度模型(CLBM)。该模型共分为三层:应用层、任务层和资源层。应用层由获取数据模块构成,包括提交请求和用户登录;任务层由请求分类模块和任务调度模块构成,请求分类模块包括接受用户请求和算法分类,任务调度模块包括任务指派和任务调度;资源层由资源分类模块和返回模块构成,资源分类模块包括服务器预分类(降维)和模糊关联聚类,返回模块包括服务器处理请求和返回用户请求。该模型各模块具体功能如下。
获取数据模块:该模块主要功能是统计提交的用户请求。用户登录系统并提交请求,用户提交的请求就作为下一步分类的数据来源。
请求分类模块:该模块的主要功能是请求任务的分类。服务器间隔固定的时间统一接收用户请求,分析任务请求的属性特征,构建指标体系,根据请求分类算法对请求分类。
任务调度模块:该模块的主要功能是请求任务的调度。将分好类别的任务请求分派到对应类别的任务指派器上,然后顺序选择服务器对任务请求进行任务调度。
资源分类模块:该模块主要功能是对服务器进行两次分类。首先,对服务器功能特性对服务器进行预分类,以减少冗余,降低后续工作的复杂度;然后根据服务器特征参数对其进行模糊关联聚类,使得服务器具有清晰的划分。
返回模块:该模块主要功能是处理请求任务。首先属于某一类别的服务器处理对应类别的任务请求,并将处理结果反馈给用户。
因此,在该模型下,负载均衡调度的全过程如下:首先登录系统并提交请求,作为下一步分类的数据来源;服务器间隔固定的时间统一接收用户请求,分析任务请求的属性特征,构建指标体系,根据请求分类算法对请求分类;将分好类别的任务请求分派到对应类别的任务指派器上,使得访问同一类型的请求对应相应类型的服务器,然后顺序选择服务器对任务请求进行任务调度;最后,属于某一类别的服务器处理对应类别的任务请求,并将处理结果反馈给用户。分类负载均衡模型如图1所示。
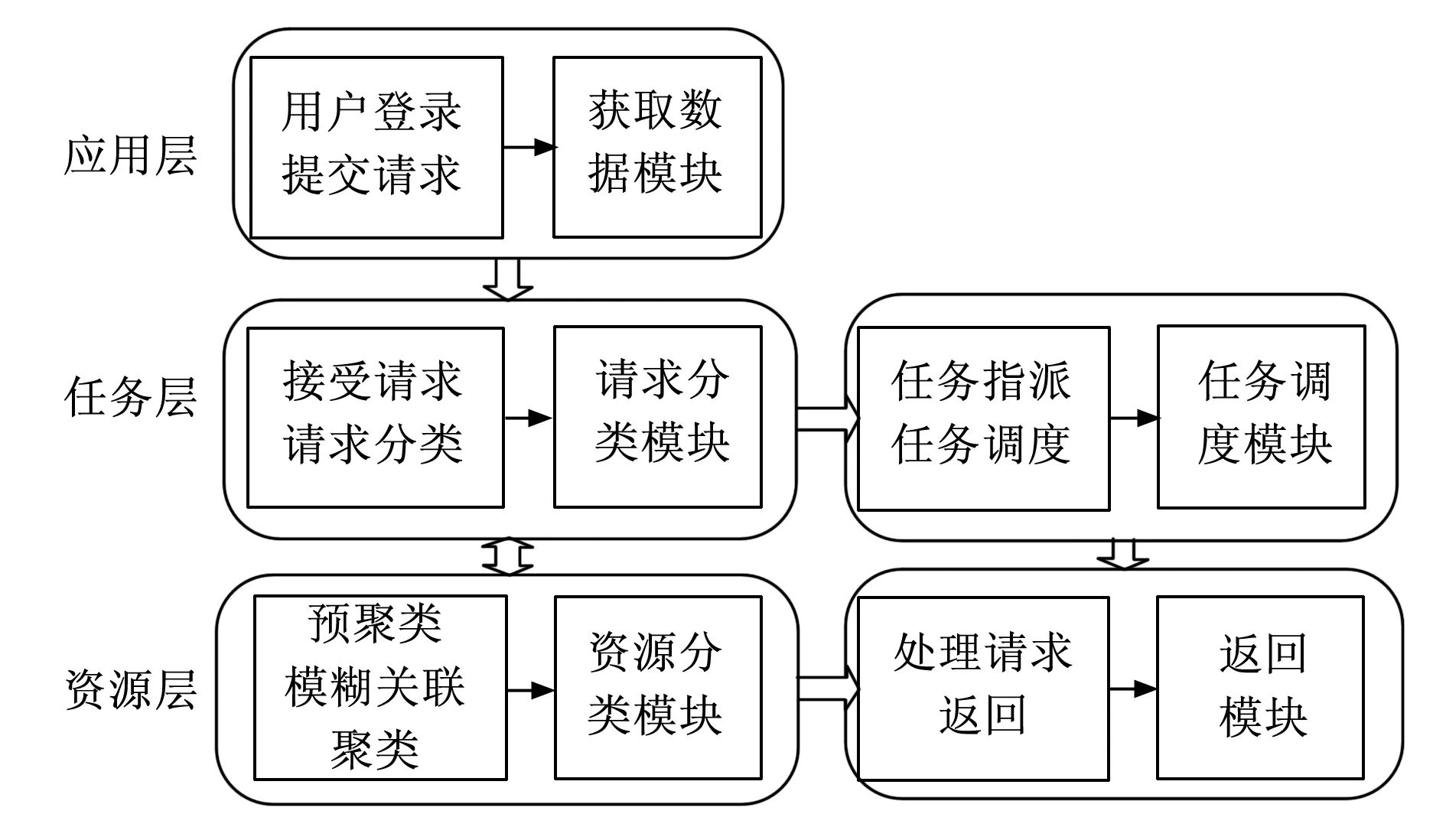
图1 分类负载均衡模型
根据上述分类负载均衡模型各个模块的主要实现功能,该模型主要实现构建指标体系、对请求分类、对服务器分类三大功能。
构建指标体系:确定任务请求的主要特征属性,并根据这些属性确定任务请求的指标体系,作为下一步对请求分类的数据来源与数据依据。
对请求分类:按照由任务请求属性构建的指标体系,采用某种有效的数学算法,对请求进行分类。
对服务器分类:按照服务器的特征参数,对服务器进行分类,并与对请求的分类形成呼应。使得同一类大小的请求负载对应同一类处理能力的服务器。
因此,对分类负载均衡模型建模过程如下:
设Web集群服务器由一个分配器和M个后台服务器RS1,RS2,...,RSM组成,服务器按照处理负载能力大小分为c类。我们将用户请求x={x1,x2,...,xn}按照任务量大小划分为c个不相交的区间{[s0=0,s1],[s1,s2],...,[sN-1,sC]=∞},并且让第i(1≤i≤c)类服务器仅仅服务请求大小落在第i个区间[si-1,si]的请求,即实现访问同一类型的请求分配到同一类型的服务器处理的初衷。
2 分类负载均衡模型的实现
2.1 构建指标体系
针对某项目系统,用户基本操作主要有以下4种:登录、增删改查、提交和GPU计算。一般操作对象为视频和文档,针对某系统现状,主要操作对象为文档。传统的调度算法只考虑了请求文档的大小,忽略了文档的其他属性。比如请求文档的紧急程度,文档的是否涉密等。而实际应用中,忽略这些属性往往会产生较大的误差,造成资源分配不合理,请求响应时间增加,不满足用户需求。这里我们定义文档属性为文档大小、紧急程度、涉密程度。因此本论文中我们定义4个指标:视频/文档、大小、紧急程度和涉密程度。
定义4个指标为请求数据的4个属性,为了便于分析,我们将指标量化数值表示优先级高低,如表1所示。将属性进行加权求和,请求的任务量大小用每个请求的属性加权和来表示,根据量化数据的加权和来划分分类范围。

表1 数据指标的属性及量化值
2.2 对任务请求分类
任务请求到达的方式有很多种,我们假定是在访问量稳定的情况下。以时间片为单位,将在某时间片内的所有请求进行分类。因此,请求的分类需要高频随时进行,需要选用相对简单复杂度低的算法,且算法运行时间要短,这里我们选择模糊C均值(FCM)聚类算法。
利用最小支撑树(MST)算法可以得到请求数据的初始聚类中心,算法原理是在数据密集区选择密度最大数据节点作为第一个类的初始中心,然后在距离第一个初始中心足够远的区域内选择数据密集区最大的数据节点作为第二个类初始中心,以此类推[8]。
我们对MST算法进行改进,得到改进的最小支撑树算法(IMST),该算法降低最小支撑树算法(MST)的计算复杂度,解决了MST算法初始点选取的冗余问题。现给出如下两个定义:
定义一:用加权属性和之差来定义两节点的距离。即:
(1)
其中:dik表示节点xk到聚类中心vi的距离,m为属性的个数,w属性值大小。
定义二:定义所在节点的度与分离度之积为该节点的稀疏度,分离度指两节点间的距离。即:
Sk=nk×dik
(2)
其中:Sk为节点xk相对于聚类中心vi的稀疏度,nk为节点xk的度,dik为节点xk到聚类中心vi的距离。
实际计算中,我们无须将所有节点都作为初始聚类中心的候选点,为减少计算量,我们选择节点的度大于平均值的点作为候选点[9]。
这里采用类间最小距离原则:首先选取节点中度最大的值作为第一个初始聚类中心,然后更新候选点集合,去掉距离第一个聚类初始化中心为0的候选点,计算新候选点集合到第一个初始聚类中心的分离度,选择分离度最大的点作为第二个初始聚类中心,继续更新候选点集合,去掉距离第一、二初始聚类中心为0的候选点,然后从新候选点集合中选取分离度最大的点作为第三个初始聚类中心,如此反复直至候选点集合为空。此时得到准初始聚类中心集合。根据有效测度指标确定最佳聚类数,由此确定最终的初始聚类中心点。
算法1:IMST算法
输入:请求数据Data
输出:初始聚类中心
Step1:利用请求数据,以数据为节点,两节点间距离作权值,构造最小支撑树;
Step2:求各请求节点的度nk及平均度navg,若nk>navg,则xk∈N(N为候选中心集合);
Step3:利用类间最小距离原则:取nmax的节点作为p01(p0i表示第i个初始聚类中心),然后更新N(为避免重复,去掉d1k=0的节点),计算更新后N中元素到p01的稀疏度S1,取Smax1对应的节点作为第二个初始中心p02;
Step4:重复Step3直至N为空集,输出初始聚类中心;
Step5:算法停止。
针对FCM算法提出了很多有效性指标,使用以下有效性测度指标来确定其聚类个数,定义如下:
(3)
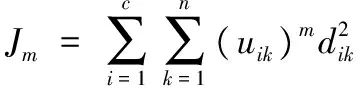
BP神经网络算法比较实际输出与理想输出的差值反向修改神经元之间的权值来实现反馈迭代,因此算法具有较强的适应性和学习能力,这弥补了FCM聚类算法因其模糊性造成的适应能力差的缺陷,将BP算法应用于FCM聚类算法可以增加其学习能力并提高准确识别率。在FCM的输出数据中,选取距离最佳聚类中心稀疏程度最小的部分数据作为BP算法的训练输入数据,使网络具有对输入请求分类的能力,然后用训练好的BP神经网络预测请求所属类别。其算法流程图如图2所示。
算法2:模糊神经网络算法(MBFCM算法)
输入:待分类请求数据Data,FCM停止阈值emps,模糊指数m,BP停止阈值e,BP算法学习速率η。
输出:最佳聚类数c,正确识别率h。
Step1:输入待分类请求数据Data,根据MSTZ算法求得初始聚类中心集合;
Step2:根据有效性测度确定初始分类中心v0和最佳分类个数c;
Step3:运行从指定中心开始的模糊C均值(MFCM)聚类算法,得到最佳聚类中心v;
Step4:计算个体到聚类中心的分离度并选择稀疏度程度最小的部分数据进行网络训练;
Step5:网络预测与结果统计,得到正确识别率h。

图2 MBFCM算法流程图
2.3 对服务器分类
根据服务器结构描述,现对服务器进行两次分类。首先对服务器进行预聚类(功能分类),从而避免因服务器属性过于复杂导致算法计算复杂度过高,并且有效提高任务调度的精准性;紧接着运用模糊关联聚类算法对服务器进行性能分类,然后F统计量确定服务器分类个数,并用编网法获取最佳聚类划分。使同一类别的请求分派到后台对应类别的服务器上处理,避免小任务排在大任务后面受到巨大的响应延时。
因服务器特征参数复杂繁琐,且变化幅度较大,其分类个数用F统计量来获取。F统计量根据样本空间中数据的特征来划分类别,通过类间距离和类内距离比值量化分类效果的好坏,显然,类与类之间的距离越大,类内样本数据之间的距离越小,同一类别的数据分布越稠密,不同类别的数据越分散,分类效果就越好[10]。
F统计量公式如下:
(4)

基于模糊等价关系的聚类算法基本原理是:首先对请求数据构建数据矩阵并利用某种方法对数据矩阵建立模糊相似矩阵,然后对模糊相似矩阵作水平截集,通过改变截距的大小获得不同精度的聚类划分。
3 云仿真调度模型验证与结果分析
CloudSim是一款可以模拟实际仿真调度的工具,本章将使用CloudSim工具对分类负载均衡模型做实验验证。开发人员通过扩展或者修改CloudSim中的基础类,来优化或者实现不同的调度算法,比如顺序分配策略和贪心策略,将算法原理加入DataCenterBroker类中,然后调度分配算法,实现算法仿真。
用CloudSim模拟用户数量为3,服务器数量为5的集群调度过程,如图3所示,用户列表为User1,User2,User3;虚拟机列表为Vm0,Vm1,Vm2,Vm3,Vm4;请求的任务列表为Task1,Task2,…Taskn;实际模拟过程中,数据中心并不直接参与调度,而是由数据代理管理和调度任务列表中的请求任务,分发给虚拟机处理,完成数据中心和虚拟机之间的交互。本文的仿真环境设置和实验参数设置表1所示。

图3 CloudSim模拟集群调度过程
在相同实验环境及实验参数下分别运行顺序选择策略、贪心策略和分类负载均衡策略,比较3种调度策略的性能优劣。
在DataCenterBroker类中加入本文算法:
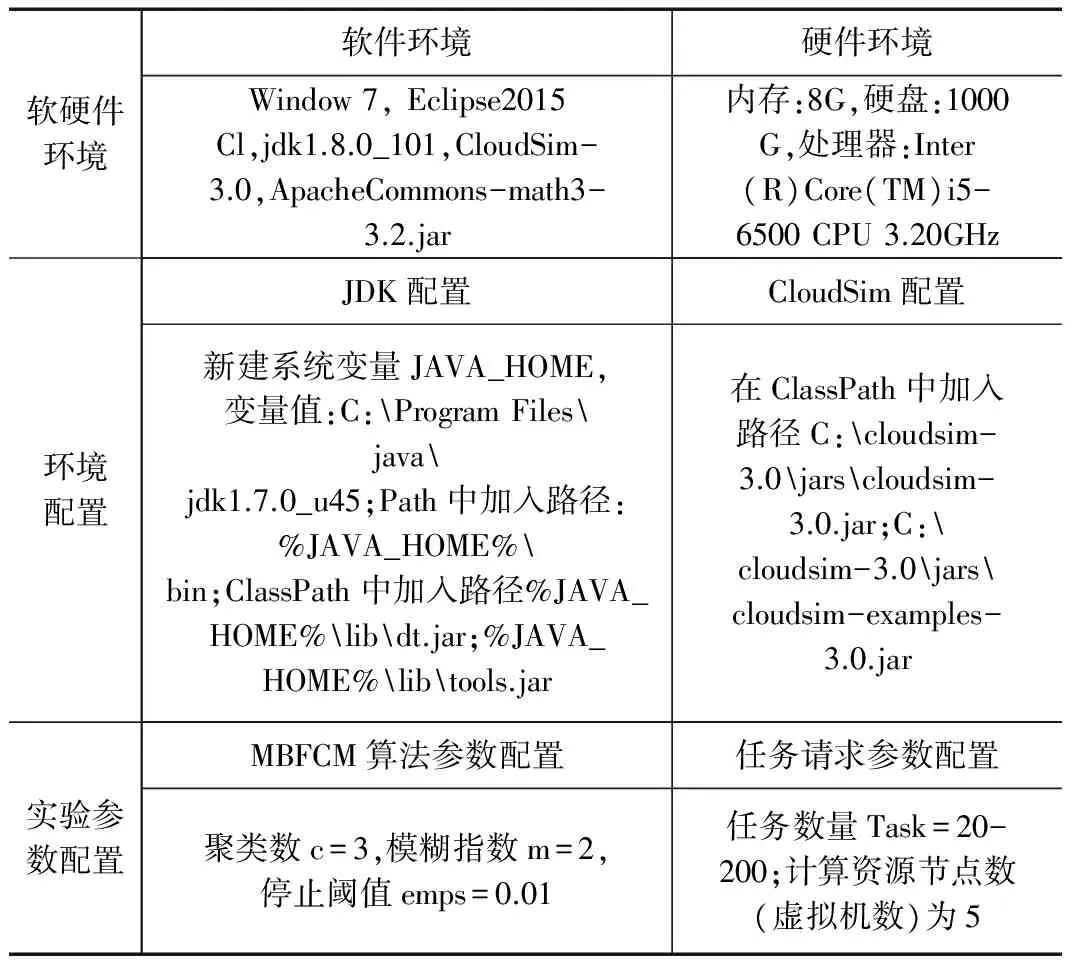
表1 实验软硬件仿真环境
broker.bindCloudletsToVmsMBFCM-CLBM;//分类负载均衡调度算法
通过逐步增加任务请求个数来验证分类负载均衡调度策略的有效性。现设计3种场景对3种算法进行仿真调度实验,对比其最大运行时间和资源利用率的变化情况。
1)针对高负载任务的实验仿真,任务的指令长度远大于服务器的处理速度。
对于场景(1),针对只有高负载任务的请求场景,如图4~5所示,顺序策略的最大运行时间最长,贪心策略和CLBM策略的最大运行时间相接近;顺序选择策略的资源利用率最低,在任务量较小时,贪心策略的资源利用率要高于CLBM策略,随着任务量的增加,两者资源利用率逐渐接近。因此,针对高负载任务场景,CLBM策略的性能和贪心策略的性能基本接近,且远大于顺序选择策略的性能。
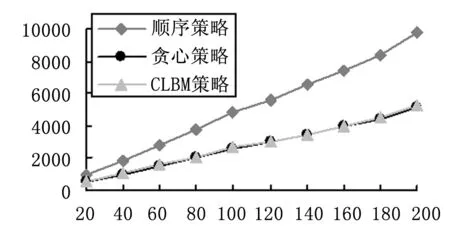
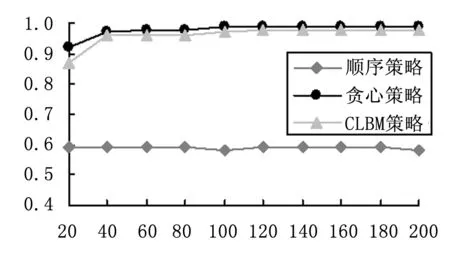
图5 资源利用率随请求个数变化图
图4 最大运行时间随请求个数变化图
2)针对低负载任务,服务器在单位时间内就可以处理完成,任务的指令长度小于服务器单位时间处理速度。
对于场景(2),针对低负载的任务请求场景,如图6~7所示,顺序策略的最大运行时间大于贪心策略最大运行时间,贪心策略最大运行时间稍高于CLBM策略的最大运行时间;顺序选择策略的资源利用率最低,随着任务量增加,CLBM策略的资源利用率远大于贪心策略的资源利用率。说明,针对低负载的请求场景,CLBM策略的性能高于贪心策略的性能。
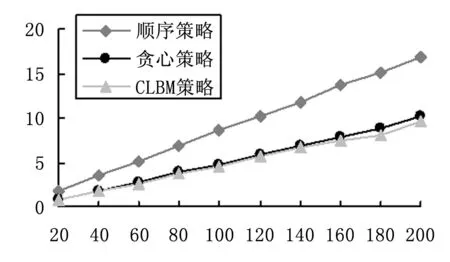
图6 最大运行时间随请求个数变化图
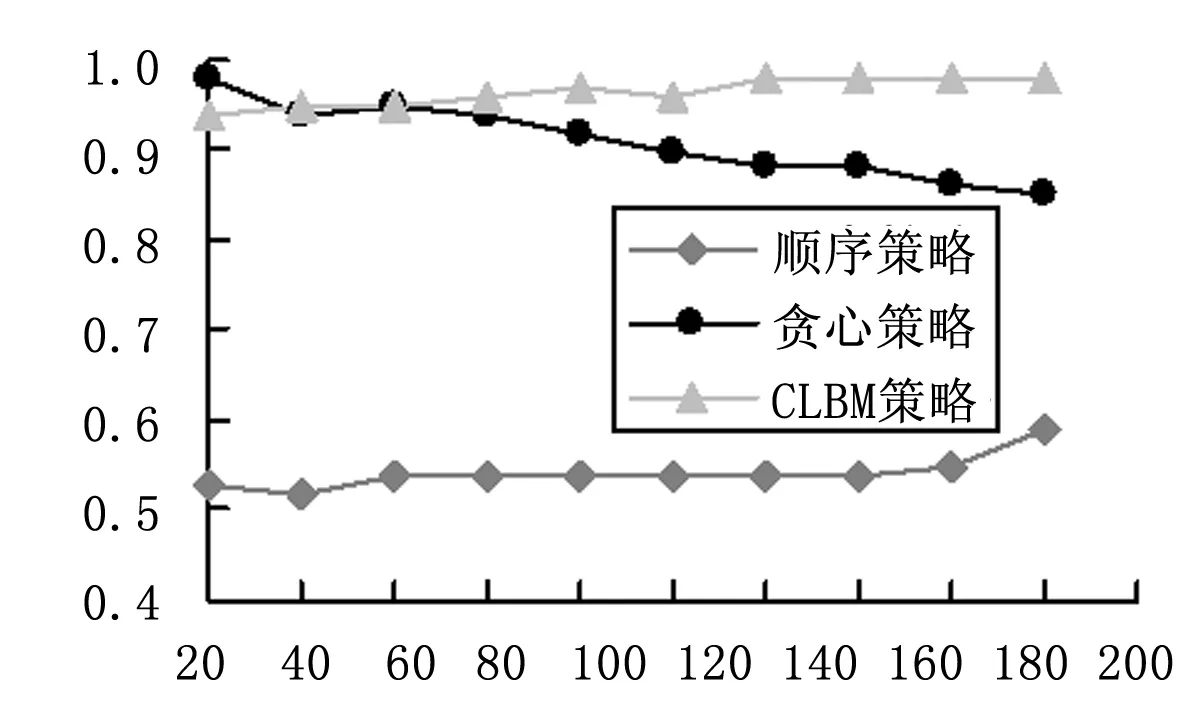
图7 资源利用率随请求个数变化图
3)针对高负载任务和低负载任务混合调度,其中,高负载任务请求个数:低负载任务请求个数=1:1 。
对于场景(3),针对既有高负载又有低负载的请求场景,根据图8~9所示,随着任务量的增加,顺序选择策略的最大运行时间远大于其他两种策略,贪心策略的最大运行时间稍比CLBM策略的最大运行时间稍高;顺序选择策略的资源利用率最低,CLBM策略的资源利用率高于贪心策略的资源利用率,说明CLBM策略的调度性能高于贪心策略的调度性能。
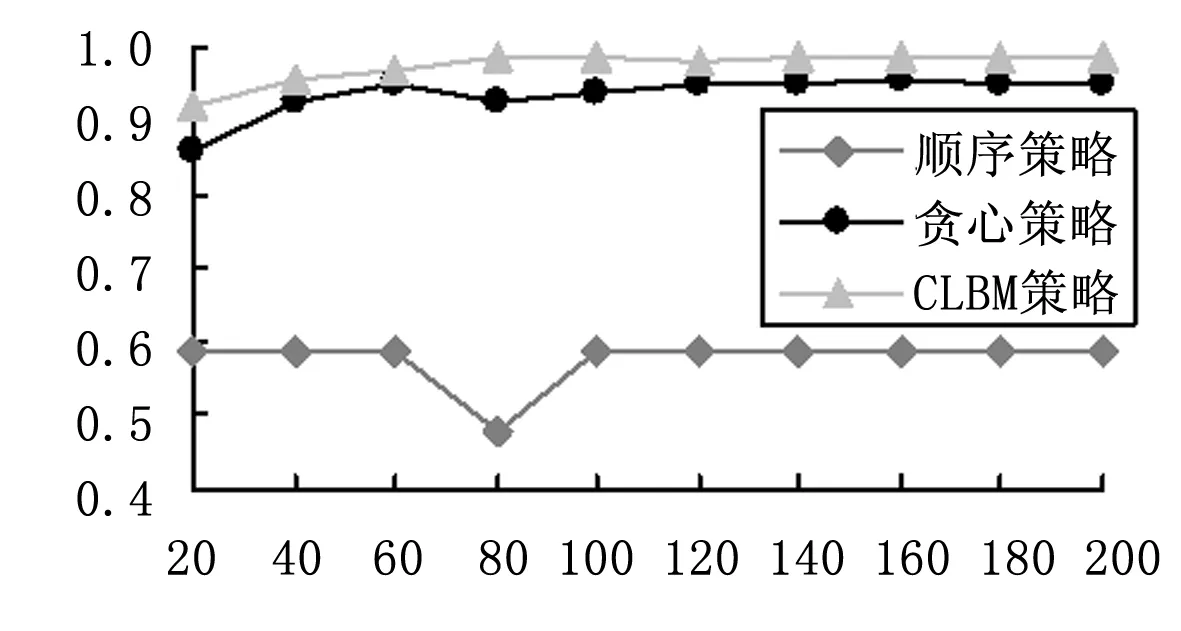
图9 资源利用率随请求个数变化图
观察并分析上述实验结果:顺序分配策略不考虑任务的大小以及虚拟机的处理能力,仅仅以每个虚拟机上运行任务数量作为衡量标准,为实现负载均衡,尽量满足每个虚拟机上运行任务数量相同,原理简单,易于实现,但实际上不同的任务请求具有不同的负载大小,并且服务器的处理能力也不尽相同,因此顺序选择策略的调度性能很差。
相比于顺序选择策略,贪心策略加入任务的指令长度(MI)和虚拟机的执行速度(MIPS)这两个性能参数,将某任务在某虚拟机上的执行时间(T)定义为指令长度与执行速度的比值,即T=MI/MIPS[11],该算法思想为指令长度越大的任务需要执行速度越快的虚拟机处理,其目的是令所有任务的完成时间接近最短。
但是贪心策略仅仅以所有任务的完成时间作为衡量标准,没有考虑资源的使用情况。本文提出的分类负载均衡策略同时考虑执行时间和资源使用情况两大性能,即将任务的完成时间和资源利用率作为衡量调度性能的标准,客观全面地反映调度的性能,算法的最大运行时间最短,资源利用率最高,最高可达99%。
综上以上分析,理论和实验皆证明本文提出的分类负载均衡调度算法适用性更强,性能更好。
4 结束语
本文基于模糊聚类算法,提出一种分类负载均衡调度模型,分别对用户请求和后台服务器分类。用改进的最小支撑树算法获取初始中心,F测度确定最佳聚类数,通过BP神经网络算法提高FCM算法的学习能力,预聚类以及模糊关联聚类算法对资源有效分类。最后CloudSim下的仿真环境模拟,在3种场景下对比传统算法和本文算法,具有更强的适应性和更好的调度性能。实验表明该模型在作业调度和资源分配上有实际的指导意义。
[1] 李明阳,严 华. 改进粒子群算法在云计算负载均衡中的应用研究[J]. 计算机测量与控制, 2016,24(10):219-221.
[2] I Konstantinou,D Tsoumakos, N Koziris. Fast and cost-effective online load balancing in diatributed range-queriable systems[J]. IEEE Transactions on Parallel and Distributed Syst. 2011,22(8):1350-1364.
[3] Wang X J,Wang Y,Hao Z,et al.The Research on Resource Scheduling Based on Fuzzy Clustering in Cloud Computing[A]. ICICTA 2015:2015 8th International Conference on Intelligent Computation Technology and Automation[C].2015:1025-1028.
[4] 曹鸿强,卢锡城. 多机服务器任务调度的经济学方法[J]. 计算机工程与科学,2001,23(2):4-9.
[5] 李春鸽,刘欣然, 张哲宇,等. 虚拟计算环境下一种基于模糊聚类的资源匹配模型[C].VARA 2013:The sixth Session of Information Security Vulnerability Analysis and Risk Assessment,2013:365-378.
[6] Wang Y,Wang J K,Wang G R,et al.Utility optimization strategy of resoutce scheduling in cloud computing[A].CCC 2016:Control Conference[C].2016 35th Chinese:5235-5238.
[7] 刘 健,徐 磊,张维明. 基于动态反馈的负载均衡算法[J]. 计算机工程与科学. 2003,25(5):65-68.
[8] 李春生.模糊聚类的组合方法及其应用研究[D].长春:吉林大学,2010, 8.
[9] 李荣荣,孙纪敏. A Fuzzy Clustering Algorithm Based on Complex Synaptic Neural Network[A].2017 17th IEEE International Conference on Communication Technology(ICCT 2017)[C].China, 2017,1291-1295.
[10] 曲福恒,崔广才,李岩芳,等.模糊聚类算法及应用[M].北京:国防工业出版社,2011.
[11] 刘 鹏.云计算(第二版)[M].北京:电子工业出版社,2012.
