文化基因算法优化PID神经网络系统辨识
2018-03-27,,,,
,, ,,
(1.中北大学 机电工程学院,太原 030051; 2.豫西工业集团有限公司,河南 南阳 473000)
0 引言
PID神经网络是一种包含比例、积分、微分元的神经网络模型,是一种特殊的BP神经网络模型。它具备任意函数逼近能力,结构简单规范。其具体结构形式仅由辨识对象输入和输出参数个数决定。网络结构中包含的积分元与微分元使其具备动态映射能力,特别适合于动态系统的辨识[1-3]。
PID神经网络采用的向后传播算法(BP),是一种局部优化算法,其寻优结果一般在初始位置附近,所以算法对初值比较敏感,这导致网络权值初值难以确定,容易使辨识结果陷入局部极小,这限制了该模型在控制系统中的应用。现有理论优化BP神经网络辨识,多为优化网络结构与权值,从而改善网络学习性能。如文献[4-5]中,采用遗传算法等群智能优化算法,对网络权值和隐含层神经元个数选取进行优化,使网络有较好的辨识精度。但是,这类优化问题往往维数较高,单一的全局优化算法难以获得较优解。而且,PIDNN泛化能力对权值分布较为敏感,在采用群智能优化算法时容易得到拟合精度较高,但是泛化性能较低的神经网络模型。现有方法在采用全局优化方法优化网络的过程中,未对权值进行约束,导致在优化过程中可能得到部分使网络泛化能力下降的,无进一步优化潜力解[3,6]。
引入一种基于差分进化的文化基因算法(Memetic-DE),对隐含层结构固定的PID神经网权值进行优化,在优化过程中,采用L1正则项对网络权值进行约束。通过辨识一多输入-多输出非线性复杂系统验证其有效性。
1 PID神经网络系统辨识模型
1.1 MPIDNN网络结构
多输出PID神经网络(MPIDNN)由多个单输出PID神经网络(SPIDNN)交叉并联组成。SPIDNN的结构固定,所以针对不同辨识对象,MPIDNN的具体结构仅由输入与输出参数个数决定。若辨识对象的输入和输出参数有两个时,神经网络辨识器,所对应的MPIDNN模型结构如图1所示。从图中可知,若辨识对象有m个输入和n个输出,则MPIDNN就需要m个子网交叉并联,且其输出层含有n神经元,即输入参数决定输入层和隐含层结构,输出层神经元个数由输出参数个数决定[3]。
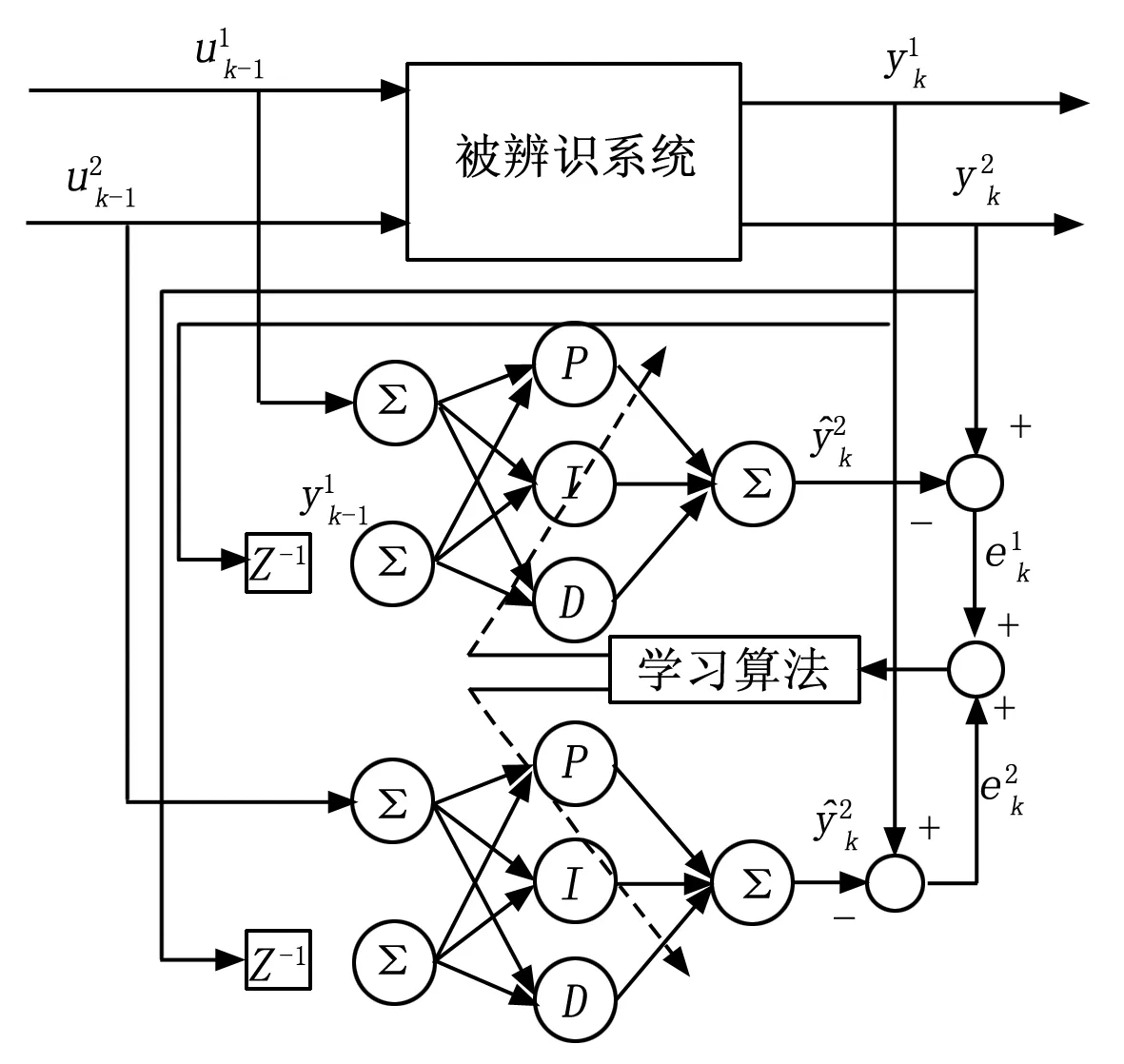
图1 MPIDNN模型结构示意图
1.2 MPIDNN前向算法
MPIDNN的输入层有2m个相同的神经元,在采样时间k时刻神经元状态为:神经元输出分别:
usi(k)=∂1netsi(k)
(1)
输入层神经元输出为:
(2)
在式(1)和式(2)中,s为子网序号(s=1,2,…,n);i为子网输入层序号(i=1,2);usi为神经元输入值;xsi为输入层神经元输出值;q′为输出阈值;∂1为比例系数。
MPIDNN的隐含层由3m个神经元组成,隐含层神经元包含比例、积分和微分元,其神经元节点输入表示为:
(3)
隐含层中比例元、积分元和微分元中包含相应的状态转换方程,其表达式为:
(4)
隐含层中各个神经元输出可表示为:
(5)
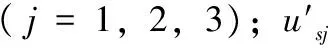
MPIDNN的输出层含有n个神经元。输出层的节点输入;神经元状态转换函数;以及输出层神经元输出表达式如式(6)~式(8)所示:
(6)
(7)

(8)
神经网络模型的辨识输出为:
(9)
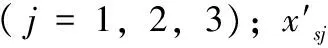
2 文化基因优化PIDNN系统辨识
优化PIDNN模型权值是一类有较高维数的优化问题,单纯采用全局优化算法进行优化,会遇到搜索停滞与早熟收敛等问题,难以进一步开发权值解空间。针对高维优化问题难以开发和探索解空间的问题,国内外学者提出了诸如自适应差分进化等, 许多改进算法。其中文化基因优化算法是将全局优化算法与局部搜索方法相结合的混合算法,能够在解空间的探索和开发方面实现较好的平衡。采用一种基于差分进化算法的文化基因算法,在每代全局寻优的基础上,利用混沌局部搜索在当代最优值附近,进一步开发解空间,所得的最优解与对应个体通过B和L协作学习机制,决定是否参与到下一次进化中[7]。
2.1 标准差分进化算法[7]
采用差分进化算法作为文化基因算法中的全局搜索算法。算法首先在解空间内产生随机初始种群:xi=(xi,1,xi,2,…xi,D),i=1,2,…,NP,其中,D为问题维数,NP为种群规模,xi代表第0代第i个个体。之后采用DE/best/2变异策略,对种群内个体进行扰动,生成变异向量,其扰动方程为:
vi,g=xbest,g+F·(xr1,g-xr2,g)+F·(xr3,g-xr4,g)
(10)
其中:r1≠r2≠r3≠r4≠i,即必须为4个相异的个体参与扰动,F为缩放因子。变异之后采用二项式交叉策略,对变异向量和目标向量进行交叉操作,其表达式为:
(11)
式中,j=1,2,…,D,jrand为[1,D]内随机选择的整数,CR∈(0,1)为交叉率。最后根据目标向量xi,g和实验向量ui,g的适应值f(·)来选择最优个体。假设优化问题为最小化问题,则选择操作的原则如式(12)所示,即保留适应值较小的个体,对种群进行更新。
(12)
式中,xi,g+1为下一代的目标向量。种群中最优适应值对应向量,应为本代最优向量xbest,g+1。
2.2 混沌局部搜索
采用混沌局部搜索算法作为文化基因算法中的局部优化算法,在差分进化算法优化结果的基础上,进一步开发优化权值解附近的权值解空间。其中,采用Logistic混沌迭代方程产生混沌序列,迭代方程表达式为[8]:
βj∈(0,1),βj≠0.25,0.5,0.75
(13)

(14)
式中,ε为一个小于1的小整数。新序列的概率分布如图2(b)所示。新混沌序列高概率分布集中在解空间的中心,这样有利于提高算法的开发能力。采用上述方法产生扰动向量,对当代最优个体进行扰动,到达进一步局部优化的目的。局部优化的搜索公式表示为:
(15)

图2 混沌序列概率分布
2.3 正则化方法
PID神经网络有别于一般神经网络,网络中的比例、积分和微分神经元产生不同的映射作用,所以若权值服从某些分布规律,会使优化的网络模型泛化能力下降。在训练样本集质量与数量一定的情况下,为了保证网络模型有较强的泛化能力,权值需要满足一定的分布规律。文化基因(Memetic)算法是一种全局搜索与局部搜索混合算法,具有较强的全局搜索能力,在保证网络辨识结果有较高精度的前提下,能搜索到符合多种分布规则的权值解向量。所以在优化网络权值的过程中,需要根据已有的先验知识,加入一定的约束条件限制更新权值大小,否则容易得到使神经网络模型泛化性能下降的优化解[9]。
神经网络正则化方法是一种简单有效的,保证神经网络泛化能力的方法。采用正则化方法对优化过程中更新权值大小进行约束,需要在目标函数中加入对应分布规律的正则项,并设定相应大小的正则化系数,其具体形式如式(16)所示。
E(w)=S(w)+a*R(w)
(16)
其中:S(w)一般为网络输出与样本集的均方差,a为正则化系数,R(w)为正则项。常用的正则项形式与网络权值先验分布对应关系如下[9]:
(Gauss分布),
(Laplace分布),
(Cauchy分布),
式中,D1为要约束权值格式,T为中等大小的常数。
2.4 系统辨识优化的实现
将神经网络中需要优化的权值向量作为优化问题的个体,通过Memetic-DE算法进行种群个体更新,使神经网络模型输出的估计值与被辨识对象输出真值的均方误差最小化,并在目标函数后加入对权值大小进行约束的正则项:
*S(w)
(17)
其中:l为采样点个数,n为输出层神经元个数。神经网络系统辨识的优化过程如下:
步骤1:设置种群数量NP,变异缩放因子F,交叉率CR,最大进化代数Gmax,混沌搜索次数N,变异系数μ,确定权值范围的上界H和下界L,优化问题的维数D为需要约束的网络权值个数。产生D维的随机向量,作为产生Logistic混沌映射矩阵的初值向量,通过2.2节方法迭代产生混沌序列,将混沌序列映射到权值解空间得到文化基因算法的初始种群:
xk,0=L+βk(H-L)
(18)
其中:xk,0为第0代第k个个体;βk为初值向量迭代k次后所得向量。
步骤2:通过差分进化算法对网络权值进行优化,优化过程中根据式(17)计算个体适应值,根据2.1节方法得到当代种群和最优个体xbest,g,通过文献[7] 中介绍的B—学习和L—学习协作方法,计算混合前的CV1值。
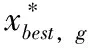
步骤4:计算混合后的CV2值,根据B学习和L学习协作机制,确定局部优化所得最优个体是否参与后续进化。
不断重复步骤2~步骤4,直到达到最大进化代数Gmax,或最优适应值达到设定值Emin,中止计算。
3 仿真校验
3.1 被辨识对象与参数给定
被辨识对象离散数学模型如式(19)所示。根据文献[4]中的训练与测试激励信号方程,产生训练样本集与测试样本集,样本集数为200。
(19)

3.2 仿真结果与分析
通过人工尝试的方法,获得神经网络权值的初值。通过BP算法对网络权值进行更新,获得一组可得到较优神经网络模型的权值解,网络相应的辨识结果如图3(a)所示。图中y1和y2训练样本集,y′1和y′2为训练后神经网络辨识输出。图3(b)所示为在BP算法训练下,网络目标函数衰减曲线。从辨识结果可知,由BP算法训练1 000步后,网络辨识输出与训练样本集的均方误差达到0.011 6,可以看出此时神经网络辨识精度较差。易知此时网络学习陷入局部极小。多次调试BP算法的学习步长,辨识结果均方差无明显减小。尝试调节初始权值,但是,因为神经网络权值较多,调试难度较大,经过多次调整辨识结果依然无明显改善。

图3 BP神经网络辨识结果
采用文化基因算法对神经网络权值进行优化。在优化过程中采用两种目标函数,即采用正则算子正则化的目标函数,和未正则化的目标函数。采用不同的正则项对目标函数正则化,经过多次仿真验证,加入L1正则项后,网络模型有较好的拟合精度和泛化精度,所以选用L1正则项,即符合Laplace分布的R(w),对权值进行约束。通过多次仿真实验发现,若将所有权值都加入正则项进行约束,容易出现欠拟合的情况。经过不断的尝试,发现仅将积分元对应的输入层至隐含层、隐含层至输出层权值加入正则项时,多次训练所得神经网络模型的辨识精度和泛化精度较高,基本没有欠拟合的情况发生。辨识结果如图4所示。

图4 文化基因优化神经网络辨识结果
图中y1和y2为测试点集,y′1和y′2是网络测试响应输出。E1是未正则化神经网络的目标函数变化曲线,E2为正则化后神经网络目标函数变化曲线。图中辨识结果为多次仿真后,所取最优结果。易知采用文化基因算法优化后的网络辨识精度较高。采用正则化目标函数的神经网络辨识均方差达到0.002 1。未正则化目标函数辨识均方差则达到了0.001 8。可知,未正则化的神经网络对训练样本集的辨识精度更高。

图5 神经网络测试集响应输出
对训练好的神经网络模型输入测试样本集,采用网络输出与测试集的均方差,作为泛化误差的衡量标准,网络仿真结果如图5所示。从仿真结果可以看出,采用未正则化目标函数训练的神经网络,泛化误差急剧增大。采用正则化目标函数训练的神经网络,其泛化误差为0.002,如图5(b)所示,与网络对训练集的辨识精度相当,可知网络有较好的泛化性能。此
外,采用正则化目标函数优化的网络权值,还可以通过BP算法进行更新,进一步提高辨识精度。
4 结论
由于PIDNN结构简单、固定,所以针对不同的复杂系统,仅需根据输入与输出参数个数就可确定结构,便于实现对复杂系统的辨识。但是,PID神经网络依然具有传统BP神经网络的缺点,网络辨识结果对网络权值初值敏感,容易陷入局部极小。所以采用Memetic-DE算法,对网络权值进行优化,从而达到较高的辨识精度。由于进化算法的随机特性,单纯采用差分进化算法进行训练,会导致算法种群多样性得不到保证,不能保证搜索到较优的网络权值。采用多种学习机制协作的办法有效维持了种群多样性,保证了系统辨识精度。同时,采用正则化方法对网络权值进行约束,防止搜索到无潜力解,保证辨识结果精度的前提下,有效避免网络的泛化能力下降。经过仿真验证,采用新方法优化的PID神经网络,有较好的系统辨识精度和泛化能力。
[1] 窦立谦,宗 群,刘文静.面向控制的系统辨识研究进展[J].系统工程与电子技术,2009,31(1):158-164.
[2] 茹 菲,李铁鹰.人工神经网络系统辨识综述[J]. 软件导刊,2011,10(3):134-135.
[3] 舒 华,舒怀林.基于PID神经网络的多变量非线性动态系统辨识[J].计算机工程与应用,2006,42(12):47-49.
[4] 李 目,何怡刚,谭 文. 基于差分进化小波神经网络的多维非线性系统辨识[J].电子测量与仪器学报,2010,24(7):599-604.
[5] 梁艳春,吴春国,时小虎,等.群智能优化算法理论及应用[M].北京:科学出版社,2009.
[6] 刘浩然,赵翠香,李 轩,等. 一种基于改进遗传算法的神经网络优化算法研究[J]. 仪器仪表学报,2016,37(7):1573-1580.
[7] 张春美.差分进化算法理论与应用[M].北京:北京理工大学出版社,2014.
[8] 谭 跃,谭冠政,邓曙光.基于遗传交叉和多混沌策略改进的粒子群优化算法[J]. 计算机应用研究,2016,33(12):3643-3647.
[9] 魏海坤,徐嗣鑫,宋文忠. 神经网络的泛化理论和泛化方法[J]. 自动化学报,2001(6):806-815.
