Spark Streaming框架下的气象自动站数据实时处理系统
2018-03-20赵文芳刘旭林
赵文芳,刘旭林
(1.北京市气象信息中心,北京 100089; 2.北京市气象探测中心,北京100176)(*通信作者电子邮箱lxulin@bjmb.gov.cn)
0 引言
目前,气象自动站实现了分钟加密观测,具有产生快、实时性强、数据量大等特点,已经成为监视天气变化、决策服务辅助支持的重要手段[1-3],不仅在天气预报、气象服务中发挥重要作用,同时也为大城市防灾减灾、适应气候变化、环境评估等提供基础的数据支撑。气象业务现代化的进展对自动站数据提出了越来越高的要求,中国气象局在“十三五”规划中明确提出了要实现自动站数据1 min内到达预报员桌面的要求;北京市气象局提出了要实现自动站数据在秒级甚至更短时间内完成各类要素实时统计的要求,以便为灾害天气的监视提供及时准确的气象服务。基于自动站的数据服务面临很大的挑战,需要在秒级甚至更短时间内完成高并发的处理存储、统计和在线共享服务,因此,实现自动站数据的快速处理、有效存储和及时服务,尽可能发挥它的应用效益,显得尤为重要。
Spark作为下一代大数据处理引擎,具有速度快、易用、通用等特点,在近几年广泛应用于多个行业的并行数据分析,得到了很多领域和科研机构的肯定。Spark Streaming是Spark提供的对实时数据进行流式计算的组件,可以进行大规模的流式数据处理,HBase是一个高可靠性、高性能、面向列的分布式数据库,适合处理实时随机读写超大规模的数据。将实时计算框架和分布式数据库系统结合起来实现对海量数据的实时处理和高效检索查询,逐步成为了大数据技术在汽车、交通、气象等行业应用的新兴研究领域[4-7]。例如,美国最权威的集汽车销售和资讯服务为一体的网站Edmunds,结合Spark Streaming技术与HBase建立了实时仪表板系统,用于显示用户的活动信息、访客ID、日志内容和页面浏览内容等。考克斯汽车公司基于Spark Streaming技术创建实时仪表状态系统,监控道路状况、汽车各项指标、驾驶者的行为数据[8]。国家气象信息中心也开展了基于HBase建立气象地面分钟数据分布式存储系统的研究,以及Hadoop在气象数据密集型领域的应用实验;广东省气象局开展了基于Hadoop实现风暴追踪算法和数值预报产品的服务应用实验等[9-16]。
本文结合北京市气象局的气象预报、决策气象与公众气象服务等业务对自动站数据的需求,尤其是实况和统计的时效要求,重点研究了Spark Streaming框架下的自动站数据流处理技术和基于HBase的存储管理技术,设计了并行的自动站流式入库、实时温度极值统计、风要素极值统计和降水量累计等算法,实现了一种分布式的自动站数据流式处理,在Cloudera环境下建立了自动站实时处理系统。
1 业务现状
目前,北京市气象局主要依托全国综合气象信息共享系统(China Integrated Meteorological Information Sharing System, CIMISS)[17]实现京津冀自动站数据的处理、入库存储与管理,通过CIMISS的气象数据统一服务接口(Meteorological Unified Service Interface Community, MUSIC)来获取实时数据。CIMISS系统中自动站数据的全流程处理平均耗时不超过1 min,基本能满足业务对实况的时效要求。然而,由于MUSIC接口没有提供自动站要素的实时统计功能,因此只能通过编写客户端程序实现,即远程调用接口服务获取某时间段内的要素值再进行计算得出结果。这种做法存在一定弊端:1)由客户端程序计算的要素统计值不能回写到CIMISS数据库中,无法实现统计功能的共享,造成很多不必要的重复性开发工作。2)由不同开发人员编写的客户端程序,可能由于算法差异导致统计结果不一致,从而降低数据的可用性。3)客户端程序需要经过多次迭代运算才能得出最终结果,耗时较长,无法在秒级甚至更短时间内实现,不能满足用户对自动站实时统计的时效需求,迫切需要改进。
2 系统设计
2.1 系统技术框架
CDH(Cloudera Distribution Hadoop)是Cloudera公司发行的Apache Hadoop项目软件包,里面包含了Hadoop和运行在其之上的各类存储计算框架,如Spark、Hive、HBase、Flume、Impala和Cloudera Search等。除了拥有开源Apache Hadoop的优势,CDH还具有以下独特的优点:1)使用Cloudera Manager可以实现CDH的自动安装,简化了Hadoop的安装部署,避免了繁杂的多节点配置工作。2)对于Hadoop及其生态系统监控都非常方便。Cloudera Manager提供一个基于Web的用户界面,可以查看群集运行状况,修改CDH相关配置以及管理CDH各种服务。
为了满足实际的业务需求,本文采用了Flume技术、Spark Streaming技术、CDH技术和HBase技术。其中,Flume技术完成自动站数据从观测台站到CDH平台的实时发送;Spark Streaming技术实现对自动站数据的流式处理和要素统计的并行化处理,以提高运算时效;HBase为系统提供数据存储服务,CDH技术为系统提供平台支撑和运行环境。
Flume是分布式的,可以同步处理到达的多个文件。Spark Streaming将输入数据流以时间片(秒级)为单位进行拆分,然后以类似批处理的方式处理每个时间片数据,使用基于内存的Spark作为执行引擎,具有高效和容错的特性,并达到秒级延迟。利用Spark Streaming进行自动站的数据处理,在几十毫秒内就能完成自动站入库和要素统计查询任务,完全能满足气象自动站数据1 min内到达预报员桌面的要求,因此,将Flume和Spark Streaming结合起来,可以实现自动站数据的实时高效处理。
本文的研究和实验均基于CDH的分布式计算框架而开展。
2.2 体系结构设计
系统体系结构设计如图1所示,主要包括4个层次:表现层、逻辑层、服务层和数据层,是一种典型的多层体系结构。表现层也是用户层,主要指客户端,可以是浏览器或者业务系统等。逻辑层对应系统的功能,包括数据查询检索、数据入库和要素统计等,由运行在Spark Streaming计算框架服务之上的功能模块实现。服务层是运行于在CDH平台上的各种服务,这里主要包括实现HBase访问接口的REST (REpresentational Sate Transfer)网关(Gateway)服务和Thrift网关(Gateway)服务以及Spark Streaming计算框架服务。数据层指应用数据的存储层,该层利用HBase存储了气象自动站实况数据和多种要素统计数据。
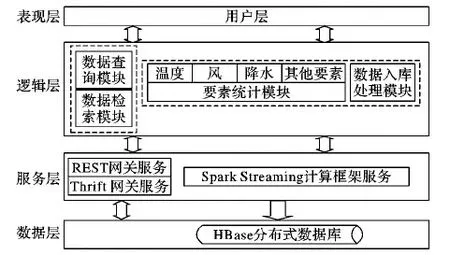
图1 系统体系结构
2.3 功能设计
从数据的处理流程来讲,系统包括数据收集、数据入库、要素统计、数据查询检索、基于MUSIC的HBase数据接口访问五大业务功能。
1)数据收集。利用CIMISS的数据收集与分发系统(Collecting and Transferring System, CTS)系统将观测数据发送到Flume的监控目录,Flume将收到的数据实时发送到Spark Streaming的监控输入目录。Flume是分布式的,可以同步处理到达的多个文件,同时它也提供了许多可调的故障恢复和容错机制,当某个节点出现故障时,数据能够被传送到其他节点上而不会丢失,从而保证数据的完整性。
2)数据入库。支持国家级自动站和区域自动站格式的解析读取,为自动站数据创建自定义的数据结构体,通过Map映射将原始的文本气象数据转为包含数据结构体的离散流(Discretized Stream, DStream)对象序列,从而写入HBase。
3)要素统计。支持自动站常规要素的各类实时统计,主要包括逐3 h、6 h、12 h、24 h的温度极值和风极值统计以及逐5 min、10 min、3 h、6 h、12 h、24 h累计降水量统计。利用Spark对数据进行转换和聚合,通过多次的迭代计算实时实现每个站点的统计结果,写入HBase的相关数据表中。
4)数据的查询检索。为自动站实况和统计提供各种条件的查询检索功能。使用Solr(Search On Lucene Replication)对查询常用字段建立辅助索引,通过Solr多条件查询快速获得符合过滤条件的Rowkey,通过指定Rowkey在HBase中查询到符合条件的结果。
5)基于MUSIC的HBase数据接口访问。HBase提供了两种接口方式获取自动站数据,包括Thrift网关(Gateway)和REST网关(Gateway)服务。其中,Thrift网关(Gateway)服务利用Thrift序列化技术用以支持C++、PHP(Hypertext Preprocessor)、Python等多种语言对HBase的访问;REST网关(Gateway)服务支持超文本传输协议(HyperText Transfer Protocol, HTTP)的应用编程接口(Application Programming Interface, API)方式访问HBase。系统通过拓展MUSIC接口功能,增加支持REST网关(Gateway)服务和Thrift网关(Gateway)服务的接口函数,实现了MUSIC接口服务对HBase的数据访问。
3 系统关键技术
3.1 基于列模式设计自动站表结构
3.1.1 Rowkey和列族的设计
Rowkey是HBase表的主键,设计合理的Rowkey有助于提高HBase的查询检索速度。自动站数据是基于时间序列的,它的查询和统计都和观测时间相关,必须将观测时间存入到Rowkey中,但是,含有观测时间的Rowkey会按时间戳的方式单调递增,很容易引起单区热点问题,从而不能将集群的整体性能发挥出来。为了避免上述问题的出现,该系统将行主键中的站号利用MD5(Message-Digest Algorithm 5)方法散列化,以便将所有的数据散列到不同的Region上。自动站表模式设计如表1所示,由行主键加两个列族构成。行主键的设计采用MD5(站号)+观测时间组合的方式,两个列族分别存放自动站观测要素和自动站要素统计值。例如,每分钟的温、压、湿、风等要素观测值对应于列族aws_data,而自动站的温度统计、风统计、降水量统计值则对应于列族aws_stat。
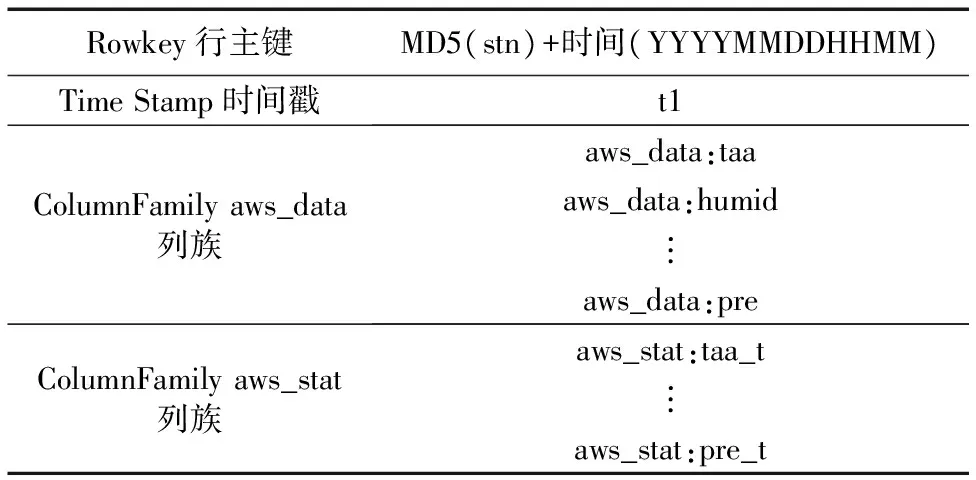
表1 自动站表结构
3.1.2 利用MD5实现对行主键Rowkey散列化
MD5是在20世纪90年代初由麻省理工学院(Massachusetts Institute of Technology, MIT)的计算科学实验室和RSA(Rivest-Shamir-Adleman) Data Security Incorporation开发的,经MD2(Message-Digest Algorithm 2)、MD3(Message-Digest Algorithm 3)和MD4(Message-Digest Algorithm 4)发展而来的,在计算机安全领域广泛使用的一种散列函数。Message-Digest泛指字节串的哈希变换,就是将一个任意长度的字节串变换成一定长的整数(128位),成为一个不可逆的字符串,这样即使用户看到源程序和算法描述,也无法将一个MD5值变换回原始的字符串,从而确保了数据的安全性[18-19]。
本文在设计自动站数据表的Rowkey时,将字符串(String)类型的观测时间转化为时间戳存为长整(Long)型,对字符串(String)类型长度为5的站号利用MD5加密,加密后的站号+Long型的观测时间,MD5(站号)+时间(YYYYMMDDHHMM)作为Rowkey。以下是创建Rowkey的Java部分代码。
String stn=cells[0];
String otime=cells[1];
String otime_long=String.format("%s%s%s%s%s",otime.substring(0,4),otime.substring(5,7),otime.substring(8,10),otime.substring(11,13),otime.substring(14,16));
Long currTime=Long.parseLong(otime_long);
byte[] userHash=Md5Utils.md5sum(stn);
byte[] timestamp=Bytes.toBytes(-1*currTime);
byte[] Rowkey_b=new byte[Md5Utils.MD5_LENGTH+timestamp.length];
int offset=0;
offset=Bytes.putBytes(Rowkey_b,offset,userHash,0,userHash.length);
Bytes.putBytes(Rowkey_b,offset,timestamp,0,timestamp.length);
Put put=new Put(Rowkey_b);
3.2 自动站流式入库和要素统计算法设计
3.2.1 流式入库算法设计
自动站流式入库算法用于将原始文本数据写入HBase表。自动站数据包括自动站号、观测时间、温度、降水、湿度、风等要素观测值,以字符串方式存储,每一行代表一个自动站记录。Spark Streaming处理的数据流DStream由一系列RDD(Resilient Distributed Datasets)组成。Spark Streaming的编程就是利用自带的接口来对DStream进行操作,因此,参照这种编程思想,该算法的关键在于自动站数据从原始文本格式到DStream的转换,需要定义一个类对象用于存储自动站要素观测值,然后生成DStream<类对象>数据集,通过map函数实现原始数据到DStream的映射转换。具体的算法步骤描述如下:
1)将原始数据读入并存为DStream
2)创建一个类对象aws_access,用于存放自动站的相关信息与数据,包括台站基本信息、观测时间、观测要素值等。定义成员变量和成员函数,支持要素观测值的获取和设置以及对原始文本数据的逐行解析。
3)自定义一个继承接口函数,用于解析原始数据并转化为aws_access对象。
4)对DStream
5)对数据集DStream
6)提交Put对象完成数据写入HBase。
自动站数据写入HBase算法流程如图2所示。

图2 自动站数据写入HBase算法流程
3.2.2 要素统计算法设计
设计合理的键值对(key,value),实现从实际数据到键值对的映射,可以很方便地实现迭代计算。
自动站逐5 min累计降水量算法步骤描述如下:
1)建立一个选择条件,用于从HBase中获取1 h内的所有站的分钟降水数据。
2)从HBase中获取相应结果并转为JavaRDD对象。
3)调用键值对转换接口函数MaptoPair将JavaRDD对象转为JavaPairRDD对象(key,value);选择站号+观测时间组合方式作为key,value为每分钟降水,如果该分钟降水值缺测,则设置为0。观测时间为5的倍数,单位为分钟,即每小时的05分、10分……。以站号为54511、观测时间2016年4月20日08时05分为例,将观测时间是01-05分(即08:00—08:05)的数据,都转为观测时间为2016年4月20日08时05分的(key,value)键值对。
4)对JavaPaieRDD对象运用groupByKey函数和Reduce函数,得出统计结果。
5)创建Put对象,根据统计结果对Put对象进行初始化,最后提交给HBase写入数据表相应的列从而完成统计过程。
逐10 min、3 h、6 h、12 h、24 h累计降水量算法与逐5 min累计降水量算法类似,温度和风要素极值统计与降水量算法步骤也类似,只是调用的迭代函数不一样。
3.2.3 动态资源池应用
动态资源池用于给YARN(Yet Another Resource Negotiator)或 Impala应用指定资源配置和策略。系统利用Cloudera Manager的Web管理功能,添加一个动态资源池用来运行Spark Streaming提交的作业任务,在YARN页面的控制面板配置权重、虚拟内核、内存大小以及正在运行的应用程序最大数量等参数。通过调整这些参数和分析对比运行Spark Streaming作业的耗时,找出作业运行的最佳参数设置方案,实现Spark Streaming运行调优。
4 实验与分析
为了检验气象自动站实时处理系统进行数据入库处理和实时统计的能力,实际部署了一套自动站实时处理系统,并进行了一系列的测试。
不同的气象业务场景对气象自动站资料的关注侧重点有所不同。在实时天气预报和气象服务中,预报员对气象自动站资料的关注重点是数据时效性,即分钟、小时和日数据能否及时到达预报员桌面以及实现要素的实时快速统计;在天气复盘推演、气候极值统计和天气过程分析等领域,预报员对气象自动站资料的关注重点是时间序列较长的30 d和90 d数据的完整性和一致性。为了满足这些需求,自动站资料至少需要保存1~3个月。分别选择1 min、1 h、1 d、30 d、90 d的京津冀自动站分钟数据作为5个测试数据集,依次编号为数据集1、数据集2、数据集3、数据集4、数据集5。京津冀总共3 802个自动站,一个站一个观测时次产生的数据大约4 kb。
4.1 系统运行环境
本文基于Apache Flume 1.5、Spark1.5、JDK(Java Development Kit) 1.7、HBase1.04实现上述系统原型,选择Cloudera 5.5作为系统的运行环境,采用YARN模式作为系统的运行方式。其中,Cloudera集群由10台实体服务器构成,每台服务器的配置为32核CPU,128 GB内存,4 TB磁盘。
在Cloudera环境下,需要将YARN、HBase、Spark、Solr服务合理地部署在不同的节点上,以便充分利用集群资源给系统运行提供更好的性能保障。选择运行Cloudera Manager服务的节点同时作为分布式文件系统(Hadoop Distributed File System, HDFS)的名字空间节点(namenode),并运行Spark Master、HMaster Server和YARN资源管理(ResourceManager) 服务,具体如图3所示。

图3 Cloudera服务部署
4.2 不同Rowkey对写入HBase操作的性能影响测试
测试主要考察在数据量以及其他系统配置不变的情况下,通过设计不同的Rowkey而引起的HBase写入耗时的变化,选择本地模式运行程序。
进行两组实验,对编号为1~3的数据集进行20次入库测试,取平均耗时作为结果。当设计Rowkey为时间(yyyymmddhhMM)+站号的方式时,3个数据集的平均入库耗时分别为14 s、144 s、498 s;当设计Rowkey为MD5(站号)+时间(yyyymmddhhMM)的方式时,3个数据集的平均入库耗时分别为4 s、24 s、121 s。结果如图4。
由图4可以看出,如果Rowkey按照时间戳的方式递增而且首字段直接是时间信息,所有的数据都会集中在HBase的一个分区服务(RegionServer)上,造成数据检索时的热点问题(hot splot),导致查询效率下降。由此可见,对于时间序列的数据集,Rowkey的设计对HBase的性能影响比较大。

图4 HBase写入性能随Rowkey变化的测试结果
4.3 HBase写入时效随Spark运行参数变化测试
进行实时场景和批量数据写入场景两种测试,选择Spark on YARN运行方式。在进行测试之前,先调整YARN服务的可用资源。在10个节点的集群中,每个节点有32个core以及128 GB的内存;其中,1个节点运行YARN资源管理(Resource Manager)服务,9个节点运行YARN节点管理(NodeManager)服务;考虑到每个节点上操作系统、Hadoop的Daemon进程以及其他组件进程的运行也需要一定资源,在该测试中分配给YARN 75%的资源,即每个节点上NodeManage可用资源为96 GB内存和24个core。
实时场景的测试使用数据集1和数据集2作为样本数据。启动Spark Streaming应用进程,结合CTS和Flume将数据发送到Spark Streaming的监控目录下,通过Web页面记录每次作业的耗时。对每个数据集进行20次测试,取平均耗时作为测试结果。测试结果表明,数据集1入库平均耗时为30.64 ms,数据集2入库平均耗时为6.37 s,完全能满足实时业务的需求。
批量数据写入HBase场景测试的主要目的是考察在数据量、任务提交方式及其他配置不变的情况下,通过改变num-executors、executor-cores和executor-memory三个运行参数而引起的时效变化。数据集3包括17 551个文件,数据总量389 MB,数据集4包括54万个文件,数据总量11.86 GB,数据集5包括159万多个文件,数据总量34.56 GB。考虑到数据集4和数据集5主要应用在非实时业务场景,而数据集3主要应用在实时业务场景,选择对数据集3进行9组实验,详细的参数配置如表2。
在实验中,num-executors从10逐渐增大到90。由图5可知,数据写入HBase的耗时随num-executors的增加呈下降趋势。当num-executors取值从[20,30),[30,40),[40,50)时,耗时并没有明显的变化。在num-executors分别设置为[60,70),[70,80),[80,90)的三组实验中,启用spark.default.parallelism参数,程序运行效率得到提升。当num-executors为70、executor-cores为3、executor-memory为4 GB、spark.default.parallelism为600时,整体性能达到最优。spark.default.parallelism参数用于设置每个stage的默认task数量。前5组实验没有启用这个参数,而Spark默认设置task为几十个,导致60%至70%的Executor进程没有task执行,因此尽管Executor参数在增大,但程序的耗时基本没有变化。由此可见,这个参数如果不设置或者设置不当会直接影响Spark作业性能。
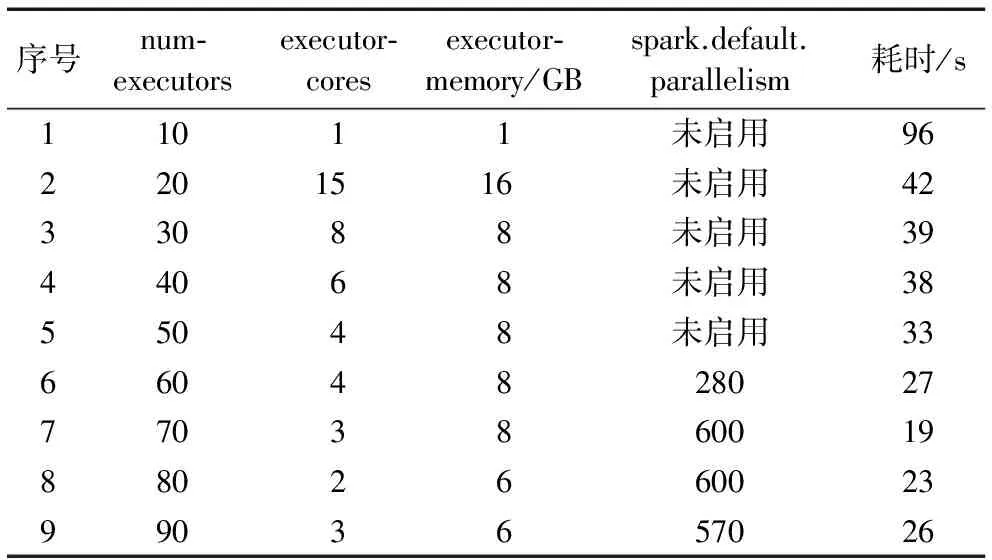
表2 Spark Streaming作业运行参数配置及耗时
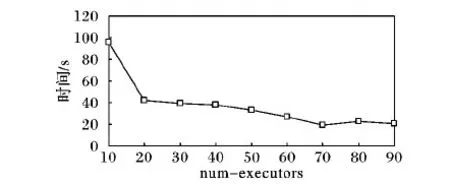
图5 耗时随num-executors参数变化测试结果
对数据集4和数据集5进行写入HBase测试。启用参数spark.default.parallelism并设置为1 000,spark运行参数按照表7中序号为7的组合参数,数据4和数据集5耗时分别为161 s和249 s;相比现有业务环境下,数据集4批量导入关系型数据库耗时196 min,数据集5批量导入关系型数据库耗时578 min,性能分别提升了73倍和139倍。
从对数据集3~5的测试结果来看,Spark作业性能与运行参数、平台分配给YARN的可用资源、spark.default.parallelism等诸多因素有关,在其他参数不变的情况下,性能与num-executors参数也不是简单的线性关系,因此,在实际运行中,需要统筹考虑这些参数的影响,选择一个最优的参数组合。此外,针对大量小文件的批量导入HBase,除了考虑spark运行参数,还可以先对原始文件进行合并和sequence序列化处理;当气象自动站小文件累计容量达到40 GB以上,可以考虑增加Cloudera集群节点,通过扩充硬件资源来提升效率。
4.4 不同查询条件下的HBase查询性能测试
进行四组查询测试,每组测试运行20次,取其平均耗时,结果如表3。从表3可以看出,当查询只以Rowkey作为唯一条件时候,不借助Solr索引查询响应比较快,达到毫秒级。当查询需要根据时间设置HBase的start key和end key时候,不借助Solr索引查询达到秒级,而借助索引后能达到毫秒级。
4.5 要素统计性能测试
对数据集进行逐日和逐时温度、风、降水量要素的统计计算,耗时结果如表4。不同类型统计运行耗时有一定差别,但都到达了秒级甚至毫秒级。然而,在现有业务平台中完成一个月逐日的要素统计需要14~16 min才能完成,由此可见利用Spark Streaming来实现自动站要素统计是完全可行的。
4.6 系统的业务应用案例
该系统投入业务化运行后,全面支持了北京市气象局的自动站数据基础业务,为预报员和其他气象工作人员提供了精准的自动站实况和要素统计数据。尤其是自动站逐5 min累计雨量的实时统计功能,为各区局的气象决策服务提供了十分方便的数据服务,同时提升了数据的综合服务能力。此外,基于Thrift网关方式的数据接口服务已经成功为市局多个业务系统提供自动站要素的统计数据支撑;在2016年7月24日和8月12日二次降水天气过程中,以REST网关方式访问系统数据的用户总数达到556,由此可见,系统在市局和各区局得到了推广应用,赢得用户一致好评。
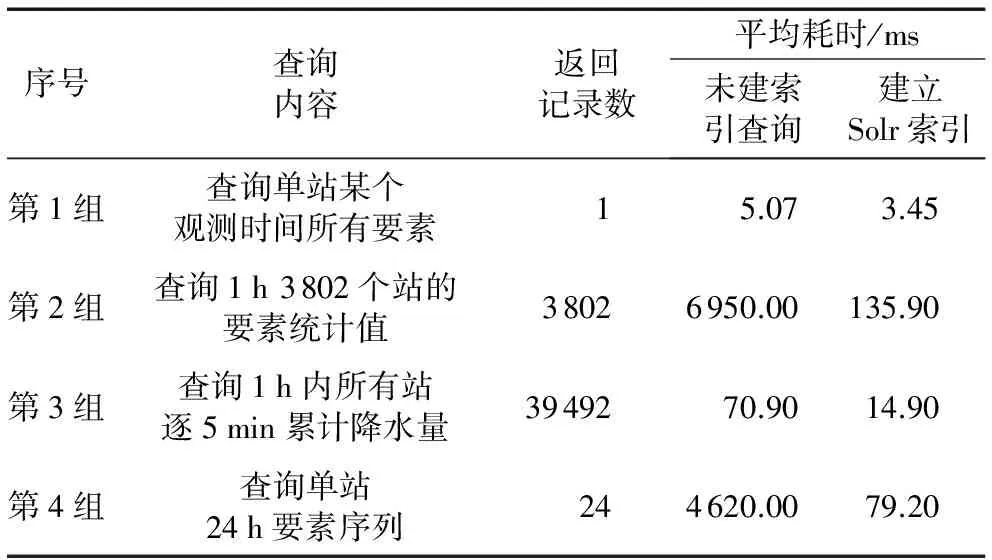
表3 查询用例

表4 自动站要素统计耗时
5 结语
本文基于Cloudera的CDH搭建了大数据平台,将Flume和Spark Streaming技术相结合,研发了基于Spark Streaming的气象自动站实时处理系统,可以快速实现自动站的要素统计和流式入库。与传统的处理方式相比,基于流式计算框架实现气象数据的入库处理和统计效率更高,处理流程也简单。可见,该系统对提升自动站数据业务的综合应用能力具有重要意义,完全具备可行性和适用性。
另外,通过拓展MUSIC接口实现对HBase的数据访问,为气象业务系统提供自动站数据的实时要素统计查询服务,既满足了业务需求,同时也克服了CIMISS要素统计功能的不足。此外,利用HBase存储自动站数据,可以作为CIMISS环境下自动站数据存储的实时备份,为气象业务提供更可靠的数据保障服务。这项工作为深入推进CIMISS本地化开发和应用提供了良好的借鉴。
在后续的研究与应用工作中,将进一步关注MUSIC的发展,研发更多的接口功能函数,通过MUSIC平台发布出来,为更多的业务系统和用户提供自动站的实时要素统计数据服务,更好发挥自动站数据的应用效益。此外,还将继续开发更多气象资料处理和统计算法,在Spark Streaming下进行算法的实现和实验。
References)
[1] 田兰,金石声,李波,等.基于XML和正则表达式的气象数据处理系统[J].计算机科学,2013,40(11A):432-435.(TIAN L, JIN S S, LI B, et al. Processing system of meteorological data based on XML and regular expression [J]. Computer Science, 2013, 40(11A): 432-435.)
[2] 李峰,秦世广,周薇,等.综合气象观测运行监控业务及系统升级设计[J].气象科技,2014,42(4):539-544.(LI F, QIN S G, ZHOU W, et al. Upgrading design of integrated atmospheric observing monitoring operation and system platform [J]. Meteorological Science and Technology, 2014, 42(4): 539-544.)
[3] 钱峥,曹艳艳,赵科科,等.私有云在市级气象业务平台的实现与应用[J].气象科技,2014,42(4):641-646.(QIAN Z, CHAO Y Y, ZHAO K K, et al. Implementation and application of private cloud in municipal-level meteorological operation platform [J]. Meteorological Science and Technology, 2014, 42(4): 641-646.)
[4] ZHAO S, YANG X, LI X, et al. A Hadoop-based visualization and diagnosis framework for earth science data [C]// Proceedings of the 2015 IEEE International Conference on Big Data. Piscataway, NJ: IEEE, 2015: 1972-1977.
[5] DUFFY D Q, SCHNASE J L, THOMPSON J H, et al. Preliminary evaluation of MapReduce for high-performance climate data analysis [EB/OL]. [2016- 04- 08]. https://ntrs.nasa.gov/archive/nasa/casi.ntrs.nasa.gov/20120009187.pdf.
[6] KARUN A K, CHITHARANJAN K. A review on Hadoop-HDFS infrastructure extensions [C]// Proceedings of the 2013 IEEE Conference on Information and Communication Technologies. Piscataway, NJ: IEEE,2013:132-137.
[7] VORA M N. Hadoop-HBase for large-scale data[C]// Proceedings of the 2011 International Conference on Computer Science and Network Technology. Piscataway, NJ: IEEE,2011: 601-605.
[8] 曾沁,李永生.基于分布式计算框架的风暴三维追踪方法[J].计算机应用,2017,37(4):941-944.(ZENG Q, LI Y S. Three dimensional storm tracking method based on distributed computing architecture [J]. Journal of Computer Applications, 2017, 37(4): 941-944.)
[9] 李英俊,韩雷.基于三维雷达图像数据的风暴体追踪算法研究[J].计算机应用,2008,28(4):1078-1080.(LI Y J, HAN L. Storm tracking algorithm development based on the three-dimensional radar image data [J]. Journal of Computer Applications, 2008, 28(4): 1078-1080.)
[10] 郑芳,许先斌,向冬冬,等.基于GPU的GRAPES数值预报系统中RRTM模块的并行化研究[J].计算机科学,2012,39(6A):370-374.(DENG F, XU X B, XIANG D D, et al. GPU-based parallel researches on RRTM module of GRAPES numerical prediction system [J]. Computer Science, 2012, 39(6A): 370-374.)
[11] 吴石磊,安虹,李小强,等.组网雷达估测降水系统并行化方案的设计与实现[J].计算机科学,2012,39(3):271-275.(WU S L, AN H, LI X Q, et al. Parallel program design and implementation on precipitation program of networking weather radar system [J]. Computer Science, 2012, 39(3): 271-275.)
[12] 杨润芝,沈文海,肖卫青,等.基于MapReduce计算模型的气象资料处理调优试验[J].应用气象学报,2014,25(5):618-627.(YANG R Z, SHEN W H, XIAO W Q, et al. A set of MapReduce tuning experiments based on meteorological operations [J].Journal of Applied Meteorological Science, 2014, 25(5): 618-627.)
[13] 陈东辉,曾乐,梁中军,等.基于HBase的气象地面分钟数据分布式存储系统[J].计算机应用,2014,34(9):2617-2621.(CHEN D H, ZENG L, LIANG Z J, et al. HBase-based distributed storage system for meteorological ground minute data [J]. Journal of Computer Applications, 2014, 34(9): 2617-2621.)
[14] 薛胜军,刘寅.基于Hadoop的气象信息数据仓库建立与测试[J].计算机测量与控制,2012,20(4):926-929.(XUE S J, LIU Y. Establishment and test of meteorological data warehouse based on Hadoop [J]. Computer Measurement and Control, 2012, 20(4): 926-929.)
[15] 薛胜军,周天波,周天杰.基于Hadoop的气象云储存与数据处理应用浅析[J].数字技术与应用,2012,15(5):82-84.(XUE S J, ZHOU T B, ZHOU T J. Analysis of meteorological cloud storage and data processing based on Hadoop [J]. Digital Technology & Application, 2012,15(5): 82-84.)
[16] 杨锋,吴华瑞,朱华吉,等.基于Hadoop的海量农业数据资源管理平台[J].计算机工程,2011,37(12):222-224.(YANG F,WU H R, ZHU H J, et al. Massive agricultural data resource management platform based on Hadoop [J]. Computer Engineering, 2011, 37(12): 222-224.)
[17] 熊安元,赵芳,王颖,等.全国综合气象信息共享系统的设计与实现[J].应用气象学报,2015,26(4):500-513.(XIONG A Y, ZHAO F, WANG Y, et al. Design and implementation of China integrated meteorological information sharing system [J]. Journal of Applied Meteorological Science, 2015, 26(4): 500-513.)
[18] BHARDWAJ A,VANRAJ, KUMAR A, et al. Big data emerging technologies: a CaseStudy with analyzing twitter data using apache hive [C]// Proceedings of the 2015 2nd International Conference on Recent Advances in Engineering & Computational Sciences. Piscataway, NJ: IEEE, 2015: 1-6.
[19] 王金柱,李元诚.MD5算法在J2EE平台下用户管理系统中的应用[J].计算机工程与设计,2008,29(18):4728-4764.(WANG J Z, LI Y C. Application of MD5 algorithm based on J2EE in user management system [J]. Computer Engineering and Design, 2008, 29(18): 4728-4764.
This work is partially supported by the Public Welfare Industry Research Funds of China Meteorological Bureau (201206031).
ZHAOWenfang, born in 1980, M. S., senior engineer. Her research interests include big data, cloud computing, machine learning, meteorological big data processing.
LIUXulin, born in 1963, M. S., research fellow. His research interests include high performance computing, software architecture, data diming, knowledge discovery.
