一种多端口非阻塞纹理Cache设计与实现
2018-03-01郑新建
郑新建,龙 强,王 维
(1.航空工业西安航空计算技术研究所,陕西 西安 710068;2.集成电路与微系统设计航空科技重点实验室,陕西 西安 710068)
0 引言
计算机图形学越来越广泛地应用于游戏、电影和虚拟现实等领域[1],通过纹理映射技术可以模拟景物表面丰富的细节,提高计算机生成图形真实感[2-3]。纹理映射首先在一个纹理存储空间中制作纹理图像,然后确定三维物体表面的点与纹理空间中点的映射关系,按一定的算法将纹理空间的纹理图案映射到三维物体上。
纹理映射能用较少的计算代价获得很强的真实感,但纹理需要大量的内存存储,且贴图过程需要很高的存储访问带宽。现代图形处理器内部一般通过纹理Cache系统来解决纹理带宽问题[4]。Hakura研究了各种不同的Cache结构对于纹理过滤的局部性的利用[5],Cox等研究多级纹理Cache对纹理贴图性能的提升[6]。而现代图形处理器为提升绘图性能往往采用并行的光栅化染色流水线,对于纹理的带宽需求进一步增加,本文以HKM96设计的基于Quad的二维光栅化染色流水线设计实现了一种多端口非阻塞的高效二维纹理Cache,能够以较少的硬件资源提供染色流水线所需的纹理访问带宽。
1 相关内容研究
1.1 纹理过滤模式
纹理贴图的过程中三维图形上的像素点与纹素图像上的点位置并不是完全一致的,当纹理图像大于三维图形表面时,则需要将一个纹素映射到许多像素上,当纹理图像小于三维图形表面时,需要将多个纹素映射到一个像素上,这时需要在贴图时通过纹理过滤进行平滑处理。纹理过滤按照采样模式可以分为点采样、线性采样、双线性采样和三线性采样等[7]。
点采样一般指邻近点采样,对于每个像素点取其位置上最相近的纹素点进行贴图。当纹理图像大小与三维图形相仿时使用点采样能够取得最快的效率,如果二者大小不等,则会出现贴图的模糊。纹理坐标(s,t)计算后得到浮点型纹素地址(tx,ty)后,通过式(1)确定纹素的整数坐标(ix,iy),即
(ix,iy)=(⎣tx+0.5」,⎣ty+0.5」)。
(1)
线性采样时一个像素需要相邻的2个纹素点进行加权平均,线性采样时第1个纹素地址计算为:
(ix0,iy0)=(⎣tx」,⎣ty」),
(2)
另外一个纹素地址为(ix0+1,iy0)。
当进行二维纹理贴图时,也就是双线性采样,对靠近像素中心点的2×2的4个纹素进行加权平均。双线性采样是纹理贴图中最常用的过滤模式,一般图形处理器内部会有专门的硬件支持双线性的插值计算。双线性采样时第一个纹素地址计算为:
(ix0,iy0)=(⎣tx」,⎣ty」),
(3)
其余纹素地址分别为(ix0+1,iy0),(ix0+1,iy0+1),(ix0,iy0+1)。
当进行三维纹理贴图或Cube纹理贴图时进行线性采样,或二维纹理贴图时开启了Mipmap过滤进行线性采样时,一个像素点的纹素值需要通过8个三维空间上相邻的点或2个相邻Mip层上各4个平面相邻的点进行过滤,此时就是三线性采样模式。三线性采样时第一个纹素地址计算如式(4)所示,其中Z坐标为三维纹理深度坐标或Cube纹理的面坐标或MipMap层编号,即
(ix0,iy0,iz0)=(⎣tx」,⎣ty」,⎣tz」),
(4)
其余纹素地址分别为:
(ix0+1,iy0,iz0),(ix0+1,iy0+1,iz0),(ix0+1,iy0+1,iz0+1),(ix0+1,iy0,iz0+1),(ix0,iy0+1,iz0),(ix0,iy0+1,iz0+1),(ix0,iy0,iz0+1)。
1.2 基于Quad的染色器纹理访问
为提高性能,现代图形处理器一般采用并行的光栅化,如文献[8-9]所述基于Quad的光栅化染色,染色器同时对一个2×2的Quad进行染色,同样对于纹理贴图也是以Quad为单位进行处理的。
当进行并行纹理贴图时,纹理Cache系统需要能够同时响应多个纹理访问请求,对于纹理之间及压缩纹理之间的相关性研究是规避Cache访问冲突的基础。纹理阵列按Quad进行纹理采样,一个Quad为2×2相邻的4个像素,采用临近采样时,一个Quad的纹理请求地址如图1(a)所示,所需纹素地址为:
C0(i,j),C1(i+1,j),C3(i,j+1),C2(i+1,j+1)。
采用线性采样时,一个Quad的纹理请求地址如图1(b)所示,所需纹素地址为:
C0(i,j),C1(i+1,j),C4(i+2,j),C3(i,j+1),
C2(i+1,j+1),C5(i+2,j+1)。
采用双线性采样时,一个Quad的纹理请求地址如图1(c)所示,纹素地址为:
C6(i,j),C7(i+1,j),C8(i+2,j),C0(i,j+1),
C1(i+1,j+1),C4(i+2,j+1),C3(i,j+2),
C2(i+1,j+2),C5(i+2,j+2)。
采用三线性采样时,一个Quad的纹理请求可以按第三维坐标的不同(第三维坐标来自Z坐标或Mip层编号)划分为2次双线性采样,纹素访问如图1(d)所示。从L1 Cache的角度看来,只是接收了2次双线性采样时的Quad纹理请求,不需要特殊处理。

图1 基于Quad的纹理过滤访问地址
2 一种多端口多Bank非阻塞的二维纹理Cache
存储带宽的降低主要依靠纹理Cache及其压缩算法,纹理Cache设计时相联度、块大小和Cache容量等都影响系统的性能。通用的Cache不能很好地满足纹理采样的需求,赵国宇等提出了一种可动态配置的纹理Cache结构,在进行点采样时使用直接映射方式,进行双线性插值时使用2路相联模式,进行三线性插值时采用4路相联模式,以增加Cache的利用率[8],该方法能够一定程度地规避访问冲突,提高命中率,但作用有限。
针对纹理应用最常用的双线性纹理过滤模式进行优化,最简单的设计方式是采用一个单端口Cache,每次访问可获取一个纹素,那么1个片段的纹理过滤就需要4次Cache访问,对于按2×2的Quad进行纹理贴图的染色器来说16次纹理Cache的访问才能够获取到所需的纹素。按照带宽最优的设计是为每个纹素设计一个独立的纹理Cache,对于按2×2的Quad进行纹理贴图的染色器来说可设计4个或16个纹理Cache,一次访问可获取4个纹素或16个纹素,这种完全并行的访问可以规避纹理访问的冲突,提供最大的带宽,但由于所有纹素需要映射到多个Cache中,Cache的利用率非常低,这对于片上有限的SRAM资源来说是不可接受的[10-11]。
基于对Quad的纹素采样地址的分析,采用多端口多Bank的纹理Cache可以提供很好的存储访问高带宽,并且Cache的利用率也能达到最优。根据光栅化的特征,纹理访问可以是乱序完成的,也就是说当某一个Quad的纹素的Cache访问发生了缺失时,后续的纹素Quad可以继续进行贴图,所以纹理Cache的设计应该支持非阻塞的特性。本文设计的多端口多Bank非阻塞纹理一级Cache如图2所示。

图2 一种多端口非阻塞高效二维纹理Cache总体结构
进行双线性采样时纹理地址生成单元一次生成一个Quad的4个片段所需的16个纹素地址,由冲突检测及合并,按照二维纹理双线性访问时的纹素地址特性将16个纹素请求合并为9个请求后,送到9端口的一级纹理Cache内核进行访问,如果当前访问发生缺失则由非阻塞单元进行缺失处理,在纹理一级Cache和DDR存储器之间还增加了二级纹理Cache的设计以减轻DDR的负载,加快纹素获取速度。
2.1 纹理Cache的二维访问
纹理数据访问时的特征会极大地影响Cache的命中率,如果纹理Cache中按行线性存储一幅图像的纹素,那么Cache中会一次取进水平的一行较长的数据,当纹素访问落在同一行时会有较高的命中率,当纹素访问在多行时就会发生多次缺失。由于基于Quad的光栅化染色决定了纹理贴图时是二维上相邻纹素会被连续访问,纹理Cache采用二维格式存储。纹素图像不论是一维、二维还是三维纹素图像,在DDR中都是采用二维格式存储,对于一维纹素图像设置其存储高度为1,对于三维纹素图像则按照深度将其划分为多幅二维纹素图像存储。
采用二维格式存储的纹理Cache使用其二维坐标进行访问,如果当前纹素请求的二维坐标在纹理Cache的Tag中存储,则当前纹素发生命中,否则当纹素发生缺失时,以当前纹素的坐标为地址从下一级存储器中取回二维空间上相邻的一整块纹素数据。纹理Cache的一个Block的数据存储内容如图3所示。

图3 L1 Cache的Block及Bank划分
2.2 纹理Cache的多端口多Bank设计
为了能够同时提供4个纹理请求的16个纹素(理论上L1同时能够最大支持双线性过滤模式的4个纹理单元的16个请求),Cache设计上应该为16个端口,每个端口对应于一个纹素。但多端口的Cache设计时,每个端口都需要设计一套独立的Tag存储和比较逻辑,输出选择逻辑。端口数越多设计会越复杂。通过基于Quad的纹理过滤访问地址分析可知大多数情况下,16个请求可以合并为空间上相邻的9个纹素的请求,为了减少端口数目、简化设计,L1纹理Cache设计为9个端口,16个请求可以先进行合并后发送到9个端口进行访问,获得输出数据再根据合并情况发射到16个端口上。如果16个请求不能合并到9个端口,则需要hold住流水线先发送9个不冲突的请求,剩余请求下一拍发送。
多端口Cache是指多套的Tag及比较电路、输出控制电路,可以实现多个访问请求同时访问Cache。L1纹理Cache设计上使用9个端口设计,根据地址相关性分析,可最多对应于地址合并前的16个纹素请求。
多Bank是指Cache的DataRam分为多个物理上独立的存储体,可以分开访问以减少多端口访问时的冲突。L1纹理Cache设计为全相联结构,分为16个Bank,使用纹素地址的横坐标i和纵坐标j地址的低2 bit组成4 bit的Bank地址。纹理Cache的Block大小设定为8×8的二维纹素块大小,L1 Cache的Block及Bank划分如图3所示,可以保证同一个Quad所需的16个纹素请求落到物理上16个不同的SRAM上,不会产生Bank冲突。
2.3 纹理Cache的非阻塞设计
并行光栅化过程中,同一个纹理流水线处理的图像Quad之间处理顺序没有相关性,当某个Quad所需16个纹素中有某些纹素在Cache中发生缺失时,纹理流水线不应该空闲等待纹素更新,而是可以继续处理后面所需的16个纹素。所以需要Cache能够在更新缺失纹素的同时,支持下一个Quad纹素的获取,纹理Cache的设计应该是非阻塞的。
Cache的非阻塞通过缺失信息状态保持寄存器(MSHR)实现,标准的MSHR设计时包括:隐式寻址、显式寻址及反式寻址几种方式[12-14]。标准的MSHR中只保存请求地址及相关信息,返回数据直接更新Cache并送往CPU的寄存器中。纹理Cache设计时由于其纹素返回只有一个目标,所以可使用一种类似于反式寻址的方式实现,同时由于纹理L1 Cache为多端口多Bank设计,一次请求所需的多个纹素可能有部分命中,部分缺失,所以为每个请求保存一个MSHR寄存器,不仅保存其中请求编号、请求地址也保存请求对应的返回纹素数据及相关信息等用于组装数据。
Cache一次接收到16个地址请求后,首先将本次请求的地址和过滤信息等都存储到非阻塞部件的某个MSHR中,由于地址合并后认为Cache同时处理的请求最多为9个。当某个纹理流水线同时所需的9个纹素都命中时,将从Cache核返回的9个数据分别发送到当前MSHR的16个地址,将数据送出完成访问。如果这9个纹素访问中某些纹素发生缺失时,已命中数据都进入当前MSHR中,未命中的纹素给出缺失标识到当前MSHR。MSHR会根据发生缺失的纹素地址合并产生Cache的Block缺失地址,发送到一个请求Buffer中送去访问L2 Cache,当L2 Cache返回数据后同时更新MSHR中数据及L1 Cache中的数据,并将MSHR中16个纹素及其对应的过滤信息等一起送给输出Buffer,供纹理流水线单元进行处理。
非阻塞模块的MSHR结构如图4所示,一个MSHR寄存器保存16个请求,包括请求的有效标志、请求编号、过滤模式、三维坐标以及相应的纹素和纹素Ready标志。

图4 L1 Cache的MSHR结构
3 仿真结果分析
采用Verilog HDL对多端口非阻塞设计的纹理Cache进行描述,下载到Xilinx Vertex6系列开发板上进行综合,工作频率可以达到220 MHz,在SMIC 65 nm CMOS工艺下,采用Synopsys Design-Compiler对设计进行综合,电路工作频率达到370 MHz,可以满足设计需求。
验证时采用如图5所示的典型纹理贴图场景进行纹理过滤的测试,纹理映射过程流畅。
根据仿真结果统计Cache的命中率如表1所示。由表1可知,设计的多端口非阻塞二维纹理Cache在基于Quad的染色流水线使用临近采样或双线性采样进行纹理贴图时,命中率在85%以上,发生阻塞的概率在10%以内。

(a) 典型游戏绘制场景

(b) 简单动画场景绘制

(c) 典型游戏场景绘制
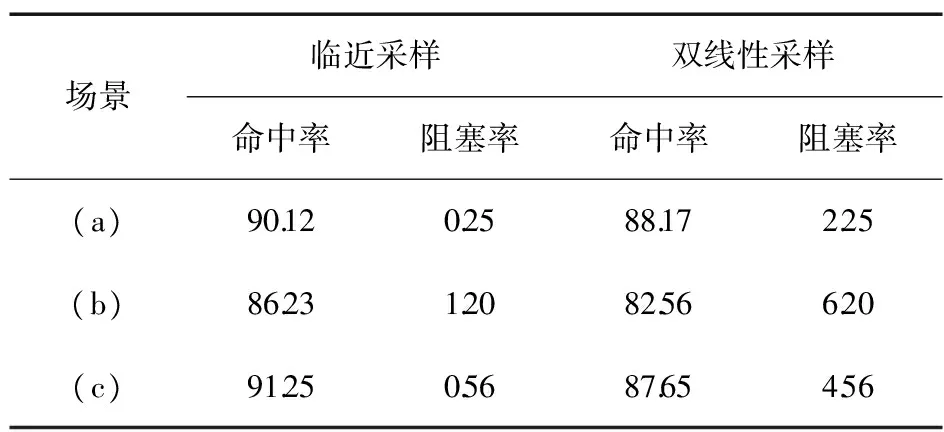
表1 典型测试场景下的纹理Cache缺失率 (%)
4 结束语
纹理访问占用了大量的图形处理器的存储带宽[15],现代图形处理器设计中通常采用层次式存储器的方法[16-17],结合不同的纹理压缩算法解决纹理带宽问题[18-19]。本文提出的多端口非阻塞纹理Cache结合基于Quad的嵌入式图形着色流水线,能够以较小的硬件代价提供较高的存储带宽,可以满足嵌入式图形处理器中高性能纹理贴图的存储带宽需求。
[1] 杨毅,郭立,史鸿声,等.面向移动设备的3D图形处理器设计[J].小型微型计算机系统,2009,30(8):1668-1674.
[2] 许庆功,刘庆伟,张永胜,等.基于硬件加速的纹理映射体绘制[J].计算机工程与应用,2009,45(26):190-192.
[3] KIM Seok Hoon,KIM Hoog Yun,KIM Young Jun,et al.A 116 fps/74 mW Heterogeneous 3D-media Processor for 3D Display Applications[J].IEEE Journal of Solid-state Circuits,2010,45(3):652-667.
[4] 程龙,郭立,史鸿声,等.一种纹理映射算法的FPGA实现[J].小型微型计算机系统,2009,30(9):1855-1859.
[5] GUPTA A,HAKURA Z S.The Design and Analysis of a Cache Architecture for Texture Mapping [J].AcmSigarch Computer Architecture News,1997,25(2):108-120.
[6] COX M,BHANDARI N,SHANTZ M.Multi-level Texture Caching for 3D Graphics Hardware[C]∥ The International Symposium on Computer Architecture,1998:86-97.
[7] WRIGHT R S,SWEET M.OpenGL 超级宝典(第4版)[M].北京:人民邮电出版社,2010.
[8] 赵国宇,郭炜,常轶松,等.一种高效纹理映射单元的硬件体系结构设计[J].计算机工程,2013,39(5):92-95.
[9] FATAHALIAN K,BOULOS S,HEGARTY J,et al.Reducing Shading on GPUs using Quad-Fragment Merging [J].ACM Trans.,2010,29(4):671-678.
[10] 许强,陈杰,刘建,等.一种适用于嵌入式图形处理器的多端口纹理Cache的设计[J].微电子学与计算机,2013,30(11):27-30.
[11] JUURLINK Ben,ANTOCHI Iosif,CRISU Dan,et al.A Framework for Low Power 3D Graphics Accelerators[J].IEEE Computer Graphics and Applications,2008,28(4):63-73.
[12] 胡孔阳,陈鹏,桑红石,等.多线程非阻塞指令Cache设计[J].微电子学与计算机,2012,29(5):143-147.
[13] 孟锐.处理器中非阻塞Cache技术的研究[J].电子设计工程,2015,23(9):85-88.
[14] 胡伟武,张福新,李祖松,等.龙芯2号处理器设计和性能分析[J].计算机研究与发展,2006,43(6):959-966.
[15] 韩俊刚,刘有耀,张晓.图形处理器的历史现状和发展趋势[J].西安邮电大学学报,2011,16(3):61-64.
[16] 田泽,张骏,许宏杰,等.图形处理器低功耗设计技术研究[J].计算机科学,2013,40(1):210-216.
[17] 焦继业,李涛,杜慧敏,等.移动图形处理器的现状、技术及其发展[J].计算机辅助设计与图形学学报,2015(6):1005-1016.
[18] 潘志刚,高鑫.针对纹理图像压缩的改进SPIHT算法[J].中国科学院大学学报,2010,27(2):222-227.
[19] 陈妍,李凤霞.基于插值矢量量化的地形金字塔纹理压缩[J].计算机工程与应用,2006,42(22):177-178.
