图像语义相似性网络的文本描述方法
2018-02-27周向东施伯乐
刘 畅 周向东 施伯乐
(复旦大学计算机科学技术学院 上海 200433)
0 引 言
图像的文本化描述是指根据一幅图像自动的生成一句描述性的文字。由于互联网上的大部分的数据是图像等非结构数据,图像的文本化描述有助于人们从海量图像中进行数据挖掘、分析和检索,是横跨计算机视觉领域和自然语言处理领域的新兴的研究方向。该任务是从图像中学习自然语言,面临着克服语义鸿沟、图像文本对齐、训练模型收敛等挑战。图像具有多通道、高维度的特点,并且受到光照、分辨率、环境和噪声的影响。自然语言具有结构,语法多样规范,词汇灵活多变,建立图像和文本之间的对应关系是一项极具挑战的任务。近年来图像的文本化描述研究引起了愈来愈多的关注。
解决图像的文本化描述问题,常用的方法分为基于检索和基于语言模型两种。基于检索的方法是对图像和文本分别进行语义分割,利用马尔科夫随机场MRF(Markov Random Field)[1]或者典型关联分析CCA(Canonical Correlation Analysis)[2]等方法,把图像和文本投影到同一空间,建立对应关系,从数据库中找到与图像最匹配的文本。基于语言模型的方法可以生成全新的语句,例如使用条件随机场提取图像中的物体、场景和关系,然后采用模板生成语句。文献[3-4]提取图像的卷积神经网络CNN(Convolutional Neural Network)特征[5]作为特殊的视觉单词,采用递归神经网络RNN(Recurrent Neural Network)[6]建立语言模型。基于检索的方法生成的语句更加自然,依赖大规模有标注的数据库。基于语言模型的方法可以灵活的生成全新的语句。目前神经网络方法在该任务的实验效果较好,利用在ImageNet数据集上训练好的CNN网络,提取图像的全连接层特征[7]。RNN网络按照时间展开,可以直接处理时序数据和构建语言模型[4],隐层节点一般选用LSTM[8]或GRU[9]。采用CNN网络和RNN网络结合的方法,可以直接得到图像和文本的对应关系,不需要进行目标检测、句法分析和模板填充等步骤,是一个端到端的模型。
传统方法仅考虑图像和文本之间的转换过程,由于存在语义鸿沟和缺乏大规模数据集,模型训练困难,预测的文本与图像内容可能存在较大差异。受到图像检索的视觉相似性的启发[4],本文考虑数据间的相似程度,用相似图像的语义信息作为补充构造语义相似性神经网络进行预训练,深入挖掘图像间和对应文本描述间的相似性信息,并与递归神经网络语言模型相互配合。用图像CNN特征的余弦距离和BLEU[14]等机器翻译指标分别衡量图像间的视觉相似度和语义相似度。把视觉相似度与RNN网络生成的文本串联,作为全连接网络的输入,拟合得到语义相似度。通过引入数据间的相似性信息,在预测阶段保持相似图像的有效语义,从而获得更好的文本描述。另外,为提高语言模型学习能力,增加栈式隐层和普通隐层的深度,最终得到接近人类语言的通顺语句。在这种背景下,本文提出图像语义相似性神经网络。Flickr30k数据集[19]和MSCOCO数据集[20]的实验结果表明,本文方法在BLEU、ROUGE[15]、METEOR[16]和CIDEr[17]等多数机器翻译评价指标上超过了Google NIC[3]和log Bilinear[21]等目前主流的方法。
1 相关工作
Farhadi等提出图像的文本化描述任务[1],把图像和文本投影到<对象,动作,场景>的三元组空间,利用马尔科夫随机场对图像进行投影,用句法解析对文本进行投影,然后计算相似性。Kulkarni等利用条件随机场对图像的对象、属性和空间关系进行标注[10],采用模板生成方法产生全新的语句。Gong等采用典型关联分析方法[2],建立图像和文本之间的对应关系。图像采用卷积神经网络特征,文本采用词袋特征,同时用大量弱标注的图像文本数据集进行辅助学习。Karpathy和Vinyals等提出使用神经网络构造端到端的语言模型[3-4],提取图像的CNN特征作为视觉单词,采用三层递归神经网络训练语言模型,可以直接得到图像到文本的映射关系。Johnson等提出全卷积定位网络[11],不仅能生成整幅图像的描述,也能生成图像内部区域的描述。Xu等提出的网络模型可以学习图像内部区域和单词的对应关系[12]。Tang等提出一种基于深度递归神经网络的方法[13],把图像特征输入到递归神经网络的每一个时刻。
2 模型架构
本文提出图像语义相似性神经网络模型,由两个共享参数的多层递归神经网络和一个全连接网络构成。首先对图像语义相似性网络预训练,学习相似图像的语义信息,然后在递归神经网络上继续训练语言模型。多层递归神经网络能够增强模型的学习能力,有助于理解图像的高级语义信息。
2.1 图像语义相似性网络
图像语义相似性神经网络模型如图1所示,能够学习图像之间的视觉相似性和对应文本描述的语义相似性,进而提升网络的泛化能力。其主要思想是,当模型学习图像的文本描述时,应当受到相似图像语义的约束,在预测阶段,通过联想相似图像的语义信息进而提升文本描述的质量。该方法可以应用到现有的递归神经网络语言模型。
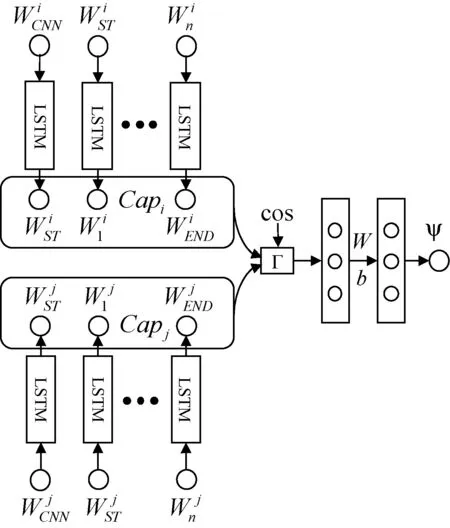
图1 图像语义相似性神经网络
为了衡量图像的视觉相似性,首先提取图像的卷积神经网络特征[24],然后计算两个特征的余弦距离:
(1)

为了衡量文本描述的语义相似性,本文采用BLEU,ROUGE,METEOR和CIDEr等机器翻译的评价指标。由于数据集中每幅图像都有多句文本描述,因此可以直接计算文本的机器翻译得分作为语义相似性。
(2)

(3)
集合Z={BLEU-1, BLEU-2, BLEU-3, BLEU-4, METEOR, CIDEr, ROUGE},表示7种评价指标。t表示图像的独立描述语句的个数,n表示具体一种评价指标的类型。构造图像文本相似性四元组数据集,按CNN特征的余弦距离对图像聚类,在每个类里选择两幅图像计算余弦距离cos和文本的语义相似性ψ组成四元组,再从不同的类中选择图像组成相同数量的四元组,共同构成四元组数据集:
(imgi,imgj,cos,ψ)
(4)
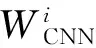
(5)
o1=σ(Γ·W1+b1)
(6)
o2=σ(o1·W2+b2)
(7)
式中:Wi、bi和oi是第i个全连接层的权重、偏置和输出。其中,σ是sigmoid函数,是全连接层的激活函数:
(8)
全连接网络用来拟合输入向量Γ和文本相似性得分Ψ的映射关系。损失函数采用均方误差损失:
(9)
2.2 递归神经网络语言模型
图像语义相似性神经网络中的RNN网络采用图2中的结构。把图像的卷积神经网络特征WCNN和单词的词向量特征Wi投影到p维空间。递归神经网络的各个时刻的输入是Xi=[WCNN,WST,W1,…,Wn]∈R(n+2)×p,输出是Xo=[WST,W1,W2,…,WEND]∈R(n+2)×p。WST和WEND表示语句的特殊起始词和终止词,语句的最大长度是n。由于传统的浅层RNN网络学习能力较弱,为了学习图像的复杂语义信息,本文从以下三个方面增加网络深度:
1) 栈式隐层(ST层):可以接受上一时刻隐层状态输入的层,增强多尺度时间序列记忆。
2) 普通隐层(CH层):除去栈式隐层之外的隐层,增强当前时刻网络深度。
3) 输出层(MO层):在隐层节点和最后的输出层节点之间添加层,把隐层的输出投影到输出空间。

图2 递归神经网络语言模型
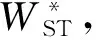
Xi=[WCNN,WST,W1,…,Wn]
(10)
(11)
Xo=[WST,W1,W2,…,WEND]
(12)
采用交叉熵损失函数训练RNN网络。在预测阶段,采用束搜索算法预测语句。语句的搜索空间是一个有向无环图,WST是起始节点,WEND是终止节点,每层的大小是束(beam),表示该层单词的搜索空间,束越大,搜索结果越接近全局最优,计算复杂度是O(beamn)。
sentence=argmaxsP(s|image)
(13)
s表示递归神经网络预测的语句。首先对图像语义相似性神经网络进行预训练,然后在数据集上继续训练RNN网络语言模型。引入相似图像的语义信息和增强语言模型的学习能力,有利于生成符合图像内容的通顺的语句。
3 实验结果和分析
3.1 数据集和预处理
本文采用Flickr30K数据集[19]和MSCOCO数据集[20],每幅图像均有5个独立的标注语句。Flickr30K数据集包含31 783幅图像,训练集、验证集和测试集大小分别是29 783、1 000和1 000。MSCOCO数据集包含123 287幅图像,训练集、验证集和测试集大小分别是113 287、5 000和5 000。
经典的卷积神经网络模型包括AlexNet[23]、VGGNet[24]、GoogleNet[25]和ResNet[26]等,本文采用16层的VGGNet提取图像特征。图像尺寸缩放为224×224,采用均值归一化,使得RGB通道的像素均值为0。人工标注的语句长度不固定,大于16的语句分布超过90%,长度阈值取16。大于阈值的语句,多余单词截断,小于阈值的语句,末尾用终止字符WEND补全。数据集中出现频率小于阈值5的单词为停止词,去除停止词后的Flickr30K数据集和MSCOCO数据集的单词表大小分别为8 625和9 566。
3.2 评价方法和对比方法
本文采用BLEU[14],ROUGE[15],METEOR[16]和CIDEr[17]指标评价图像的文本化描述效果。原理是比较机器翻译结果(candidate)和人工翻译结果(reference)的相似度。BLEU准则比较candidate和reference的n-gram匹配的数量,可以评价生成文本的充分性、保真性和流畅程度。ROUGE准则定义最长公共子序列来计算相似度,序列要求有顺序不一定连续。METEROR准则采用精确匹配、词根词干匹配和同义词匹配三种方式计算相似度。CIDEr准则首先计算n-gram的项频反向文档频率TFIDF(Term Frequency-Inverse Document Frequency)[18],然后计算candidate和reference的余弦距离。
本文方法和GoogleNIC[3]、BRNN[4]、Log Bilinear[21]、LRCN[22]、Semantic Attention[27]、Memory Cells[13]、Hard-Attention[12]等方法的实验结果进行对比。GoogleNIC和BRNN方法均采用三层递归神经网络语言模型,分别用GoogleNet和VGGNet提取图像特征。Log Bilinear方法采用多模态LBL语言模型学习图像到文字的映射关系。Semantic Attention方法首先识别图像属性,然后输入到递归神经网络。LRCN方法是一种融合递归神经网络和卷积神经网络的深度网络,能够学习图像和视频的文本描述。Memory Cell方法把图像特征输入到递归神经网络的每一个时刻。Hard Attention方法采用图像的卷积层特征,建立图像子区域和文本单词的对应关系。
3.3 结果分析
本文分别在Flickr30k数据集和MSCOCO数据集进行实验。首先训练图像语义相似性神经网络,如图1,然后训练递归神经网络语言模型,如图2。分析不同的栈式隐层、普通隐层和输出层的组合对生成文本质量的影响,结果如表1和表2,然后和最新的方法进行对比,结果如表3和表4,最后举例说明本文模型生成文本的效果。
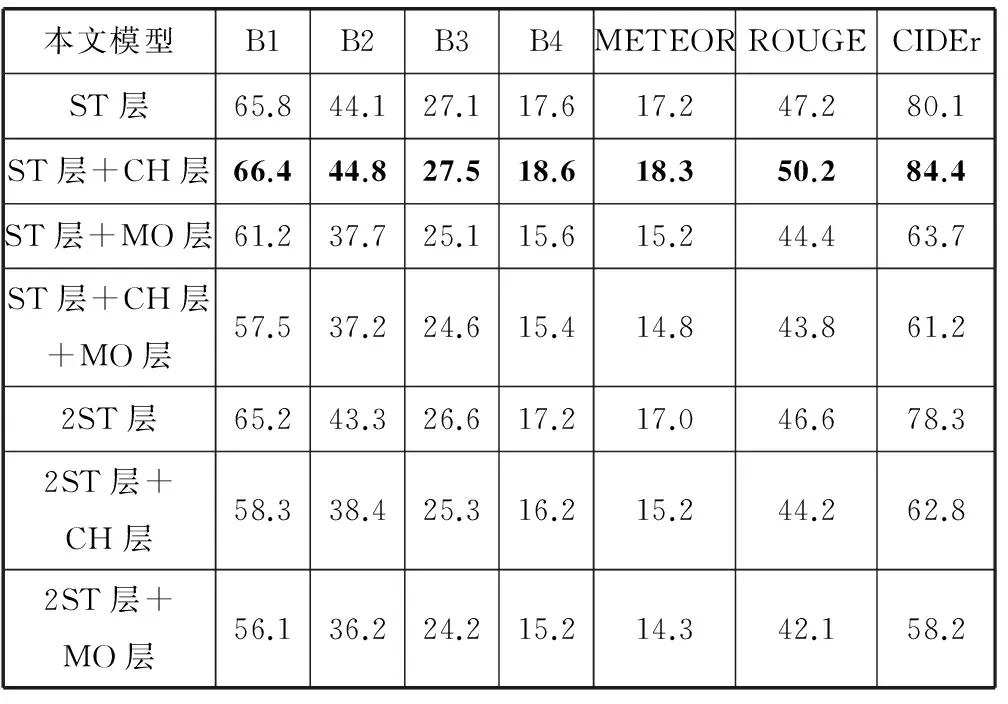
表1 Flickr30k数据集的实验结果(BLEU-i简写为Bi)
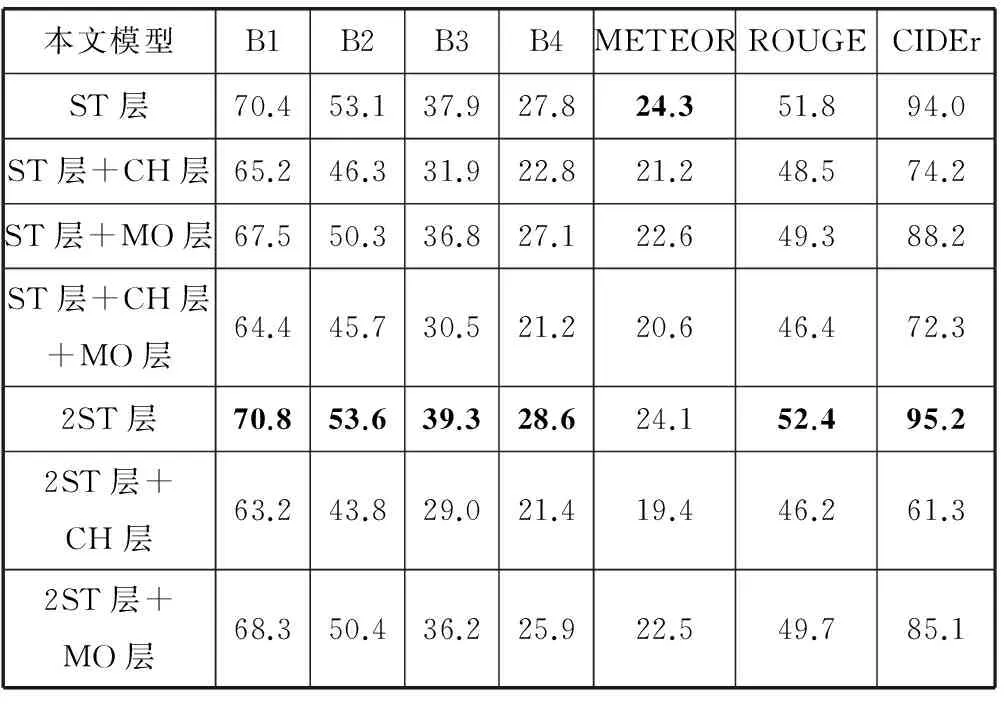
表2 MSCOCO数据集的实验结果(BLEU-i简写为Bi)

表3 本文方法和其他方法在Flickr30k数据集实验结果对比(BLEU-i简写为Bi)
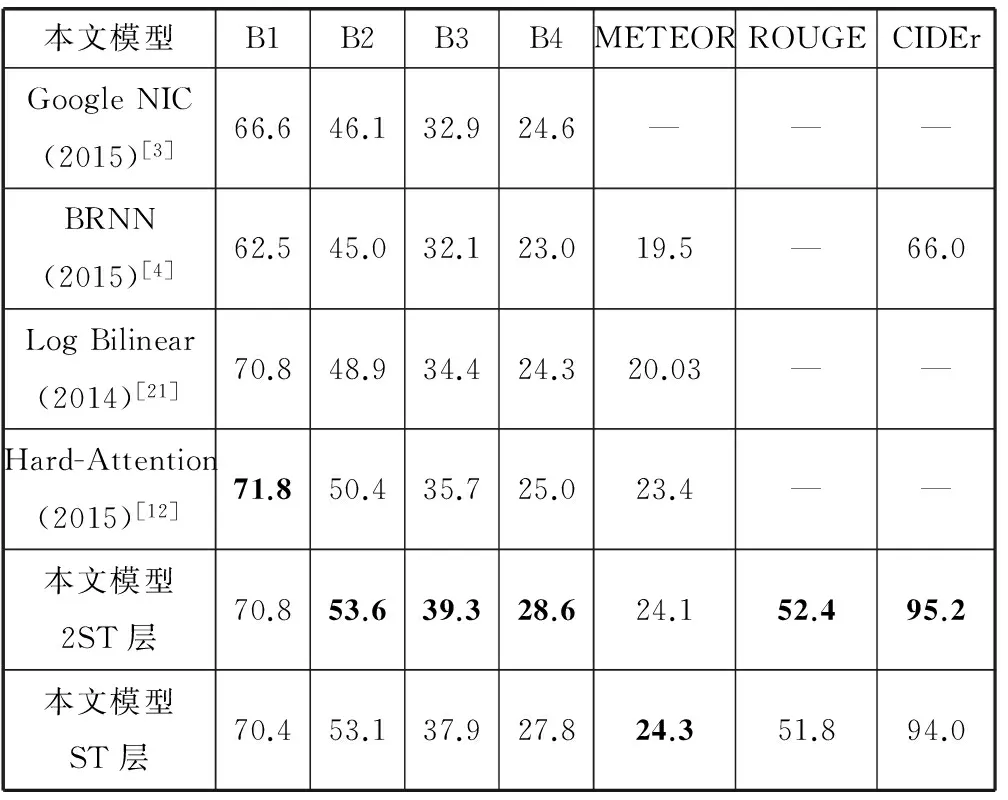
表4 本文方法和其他方法在MSCOCO数据集实验结果对比(BLEU-i简写为Bi)
表1和表2的结果表明,Flickr30k数据集训练的“模型ST层+CH层”和MSCOCO数据集训练的“模型2ST层”效果最好,说明增加递归神经网络栈式隐层和普通隐层的深度能够提高生成文本的质量。栈式隐层负责把信息传递到下一时刻,对语言模型生成文本起到关键作用。普通隐层只能在当前时刻传递信息,适当增加普通隐层能够提升模型复杂度和学习能力。增加输出层深度会降低实验效果。同时隐层总深度不宜太大,否则导致模型复杂度过高和模型训练困难,降低生成文本的质量。
表3和表4的结果表明,Flickr30k数据集上,本文方法的BLEU-1、ROUGE和CIDEr的得分最高,其他指标略低于Semantic Attention方法。Semantic Attention方法在BLEU-2、BLEU-3、BLEU-4指标较高是因为提取图像的属性标签加入RNN结构中,有利于生成多词匹配较高的语句。MSCOCO数据集上,“模型ST层”的各项指标超过GoogleNIC和BRNN等方法,“模型ST层”和“模型2ST层”的多项指标均达到最高,其中BLEU-2、BLEU-3、BLEU-4的得分达到53.6、39.3和28.6,显著超过其他方法,说明了图像语义相似性网络可以提供相似图像的有效语义信息,进而改善文本描述的质量。“模型2ST层”的多项指标均超过“模型ST层”,表明增加隐层深度可以提升语言模型的学习能力,有利于生成更加通顺的语句。Hard Attention方法的BLEU-1得分最高,因为考虑单词和图像子区域的对应关系,而文本描述的通顺程度更加依赖于多词匹配数量。
图3是本文方法生成的图像文本化描述的示例。第一行是错误的描述。图3(a)描述的是两个人站在飞机旁边,但是生成的文本是“a man standing next to a plane on a field”,仅仅识别出了一个人。图3(b)描述的是一个人坐在街道旁,但是生成的文本是“a man sitting on a bench talking on a cell phone”,错误的认为一个男人拿着手机。第二行是正确的描述,生成的文本分别是“a cow is standing in a field of grass”和“a man riding a motorcycle down a street”。图3(a)和图3(b)生成了错误的描述,可能是由于训练集中缺乏相关类型的数据,并且图像分辨率较低,阴影部分的内容较难识别。由于图像语义相似性网络能够通过相似图像的文本描述作为补充信息,因此正确的识别了图中的主体,例如“man”“plane”,以及动作,例如“standing”“sitting”。

图3 本文方法的图像文本化标注示例
4 结 语
本文提出图像语义相似性神经网络的图像文本化描述模型,采用多层复合递归神经网络语言模型。能够学习到相似图像的有效语义信息,并通过增加递归神经网络的深度,提高网络的学习能力,进而提升图像的文本描述的质量。实验结果表明,该方法在多个评价指标上均取得很好效果,超过目前的主流方法。
[1] Farhadi A,Hejrati M,Sadeghi M A,et al.Every picture tells a story:Generating sentences from images[C]//European Conference on Computer Vision.Springer Berlin Heidelberg,2010:15-29.
[2] Gong Y,Wang L,Hodosh M,et al.Improving image-sentence embeddings using large weakly annotated photo collections[C]//European Conference on Computer Vision.Springer International Publishing,2014:529-545.
[3] Vinyals O,Toshev A,Bengio S,et al.Show and tell:A neural image caption generator[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2015:3156-3164.
[4] Karpathy A,Fei-Fei L.Deep visual-semantic alignments for generating image descriptions[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2015:3128-3137.
[5] Krizhevsky A,Sutskever I,Hinton G E.Imagenet classification with deep convolutional neural networks[C]//Advances in neural information processing systems,2012:1097-1105.
[6] Lee Giles C,Kuhn G M,Williams R J.Dynamic recurrent neural networks:Theory and applications[J].IEEE Transactions on Neural Networks,1994,5(2):153-156.
[7] Donahue J,Jia Y,Vinyals O,et al.DeCAF:A Deep Convolutional Activation Feature for Generic Visual Recognition[C]//ICML.2014:647-655.
[8] Hochreiter S,Schmidhuber J.Long short-term memory[J].Neural computation,1997,9(8):1735-1780.
[9] Cho K,Van Merri⊇nboer B,Gulcehre C,et al.Learning phrase representations using RNN encoder-decoder for statistical machine translation[DB].arXiv preprint arXiv:1406.1078,2014.
[10] Kulkarni G,Premraj V,Ordonez V,et al.Babytalk:Understanding and generating simple image descriptions[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(12):2891-2903.
[11] Johnson J,Karpathy A,Fei-Fei L.Densecap:Fully convolutional localization networks for dense captioning[DB].arXiv preprint arXiv:1511.07571,2015.
[12] Xu K,Ba J,Kiros R,et al.Show,attend and tell:Neural image caption generation with visual attention[DB].arXiv preprint arXiv:1502.03044,2015.
[13] Tang S,Han S.Generate Image Descriptions based on Deep RNN and Memory Cells for Images Features[DB].arXiv preprint arXiv:1602.01895,2016.
[14] Papineni K,Roukos S,Ward T,et al.BLEU:a method for automatic evaluation of machine translation[C]//Association for Computational Linguistics,2002:311-318.
[15] Lin C Y.ROUGE:A package for automatic evaluation of summaries[C]//Text summarization branches out:Proceedings of the ACL-04 workshop.2004.
[16] Denkowski M,Lavie A.Meteor Universal:Language Specific Translation Evaluation for Any Target Language[C]//The Workshop on Statistical Machine Translation.2014:376-380.
[17] Vedantam R,Lawrence Zitnick C,Parikh D.Cider:Consensus-based image description evaluation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.2015:4566-4575.
[18] Robertson S.Understanding inverse document frequency:on theoretical arguments for IDF[J].Journal of documentation,2004,60(5):503-520.
[19] Young P,Lai A,Hodosh M,et al.From image descriptions to visual denotations:New similarity metrics for semantic inference over event descriptions[J].Transactions of the Association for Computational Linguistics (TACL),2014,2(4):67-78.
[20] Lin T Y,Maire M,Belongie S,et al.Microsoft coco:Common objects in context[C]//European Conference on Computer Vision.Springer International Publishing,2014:740-755.
[21] Kiros R,Salakhutdinov R,Zemel R S.Multimodal neural language models[C]//ICML’14 Proceedings of the 31st International Conference on International Conference on Machine Learning,2014:595-603.
[22] Donahue J,Hendricks L A,Guadarrama S,et al.Long-term recurrent convolutional networks for visual recognition and description[C]//Computer Vision and Pattern Recognition.IEEE,2015:677-691.
[23] Krizhevsky A,Sutskever I,Hinton G E.ImageNet classification with deep convolutional neural networks[J].Communications of the ACM,2017,60(2):2012.
[24] Simonyan K,Zisserman A.Very deep convolutional networks for large-scale image recognition[DB].arXiv preprint arXiv:1409.1556,2014.
[25] Szegedy C,Liu W,Jia Y,et al.Going deeper with convolutions[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.2015:1-9.
[26] He K,Zhang X,Ren S,et al.Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.2016:770-778.
[27] You Q,Jin H,Wang Z,et al.Image captioning with semantic attention[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.2016:4651-4659.
[28] Tang S,Han S.Generate Image Descriptions based on Deep RNN and Memory Cells for Images Features[DB].arXiv preprint arXiv:1602.01895,2016.
