基于经济增长模型的中国资本存量非线性估计
2018-02-25张益明赵永亮
张益明,赵永亮
(盐城工学院 经济管理学院,江苏 盐城 224005)
0 引言
资本存量作为一个非常重要的宏观经济变量,对于研究经济增长问题至关重要。长期以来,在官方数据缺失的背景下,资本存量的推算成为研究国内宏观经济的重要话题。国内外对其的研究中,大部分文献主要采用永续盘存法,也有部分文献采用资本产出比法估算。本文采用经典的经济增长模型导出计量模型,对资本存量进行非线性估算,而非以永续盘存法为核心。这样处理可以避开使用争议较大的历史数据,以及历史年份中如何选取折旧率、设定资本产出比等问题。并且,上述好处随着时间的推移,可得数据的增加,将得到更充分的体现。而采用美国的资本存量数据进行的检验表明,本文提出的估计方法能够获得较为准确的结果。
1 资本存量估计方法的比较
1.1 基于永续盘存法的资本存量估计
永续盘存法是国内外文献采用的资本存量估计的主要方法。该方法基于一个直观的思想,即某时期的资本存量等于本期的投资加上折旧后的上期资本存量。
首先,是基期资本存量的处理。现有文献对于基期时间一般选择1952年[1-3],或1978年[4]。在基期资本存量的估计方法上,采用得最多的是资本产出比法[5]和资本增长率法[2]。
其次,折旧率的处理。早期研究中对于折旧处理形成两类观点,一类以张军和章元[1]为代表,认为可以通过数据选择回避折旧问题。另一类观点认为,折旧率必须考虑,但如何选择无法达成一致。常见的做法是选择5%的折旧率。再根据残值率进行推算[6]。此外,现有文献还尝试使用可变折旧率进行资本存量估计[3,4]。不可否认,上述处理方法各具特色。从经济实际发展过程来看,折旧率应该是可变的,但是变化过程无法直接观察,因此如何处理仍然值得深入探讨。本文采用李宾[7]的建议,利用官方折旧数据而避开折旧率的选择或计算。
再次,投资流量数据。现有研究采用的投资流量数据的选择包括四类,即固定资本形成总额、新增固定资产、全社会固定资产投资、调整了的全社会固定资产投资。其中固定资本形成总额在研究中使用最多,也被认为最合理。但李宾[7]认为,采用固定资本形成总额仅仅是稍优于全社会固定资产投资。
最后,价格指数选择。在数据可获得的情况下,现有文献一般选择固定资产投资价格指数平减当期的投资,这被认为是最好的做法。但是正如李宾[7]指出的,我国官方统计资料中最早只能获取从1991年以来的这一指标,因此涉及到之前年份时就存在数据缺失问题。对此,一般可以通过拟合或寻找替代性的指标来解决。另外,还有一些研究直接借鉴了其他文献计算的价格指数[4]。
1.2 基于投入产出表的资本存量估计
我国每5年公布一次投入产出表,因此可通过折旧率、折旧额反推资本存量[8]。该方法假设研究的时间窗口存在不变的折旧率,再通过投入产出表公布的折旧额,以及各期的投资流量和价格指数推算各期折旧率,进而得到资本存量。
1.3 上述方法与本文的差异
上述方法一般都是在永续盘存法的基础上展开的,部分文献在估计中运用了计量的方法,但是主要用于获取估计过程中的一些变量。同时不少文献对于估计的结果采用C-D函数进行了检验[7]。这些工作对本文颇多启发,与本文的工作有一定关联,但是并不相同。本文对资本存量的估计主要通过对经济增长模型的变换,得到可计量的模型,根据模型形式分别采用高斯牛顿法迭代法和直接搜索的方法进行资本存量估计。
2 资本存量的高斯牛顿法估计模型
本文从索洛模型出发,假设总产出决定于现有的资本存量与劳动力人数,即:

假设规模报酬不变,则α+β=1,式(1)两边取对数有:
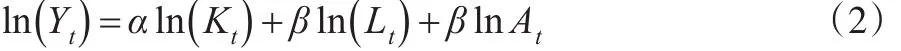
2.1 不考虑平稳性问题
式(2)由于基期资本存量无法获取难以进行直接估计,但是若不考虑数据平稳性问题,则可以进行转换后进行估计。比如可以假设基期的资本存量为K0,各期净投资为It,则式(2)可以写成:
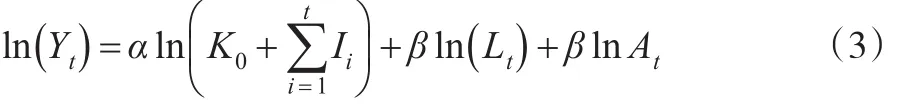
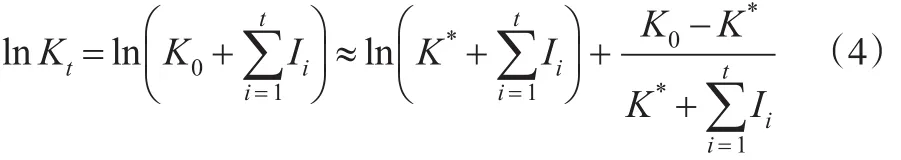
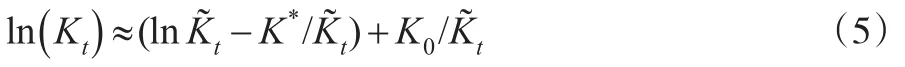
式(5)代入式(3)得到:
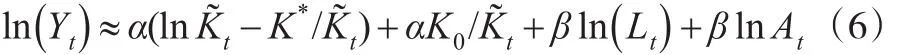
由式(6)出发,假设A为常数,则可以建立模型:
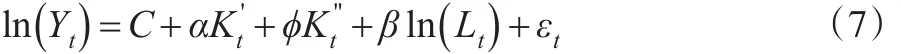
对模型(7)取初始,估计得到α和φ的估计值后,可根据α和φ的关系得到基期的资本存量K0新的估计值,再代入模型进行第二次估计,反复迭代,直到K0的估计值收敛。然而,由于时间序列的平稳性问题,上述方法需要在对数据进行处理后使用,而这也意味着估计的模型形式随之变化。并且,通过对数据的单位根检验,可以发现中国的ln(Yt)为2阶单整,而ln(Lt)则为1阶单整。这和美国情况不同,美国的GDP以及人均GDP都为1阶单整。因此无法进行协整,而必须对原模型进行差分变换。
2.2 考虑平稳性问题
ln(Yt)与其他变量的单整阶数不一致,对此建立差分模型进行估计。ln(Yt)单整阶数之所以较高主要是因为满足建模要求的时间期数不够,只有22期。实际检验1952—2015年的数据,发现为1阶单整。而对于本文来说,进行两次差分处理后虽然数据实现了平稳,但是也丢失了很多信息。并且,对于美国的数据而言,因为都是一阶单整,因此对数据进行两次差分建模也不合适。因此,下面在推导了两次差分后的回归模型后,也提供了一次差分的回归模型形式,并在实证中对两个模型都进行了估计。
假设A为常数,对式(2)进行两次差分转换为:
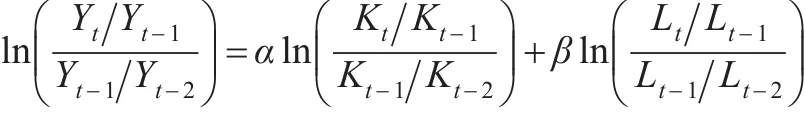
以yt、kt、lt分别表示总产出、固定资本、劳动力t时期的增长率,则有:
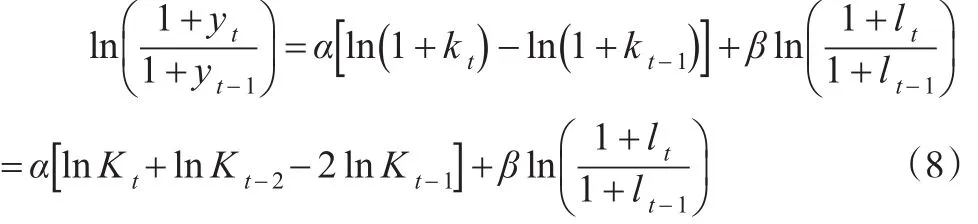
将式(4)代入式(8)得到:
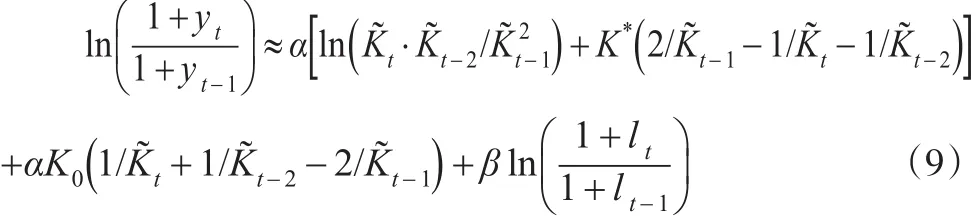
式(9)经过两次差分,解决了数据的平稳性问题。实际建立模型时,为了控制其他未纳入变量的影响,还加入被解释变量的一阶滞后项,得到:
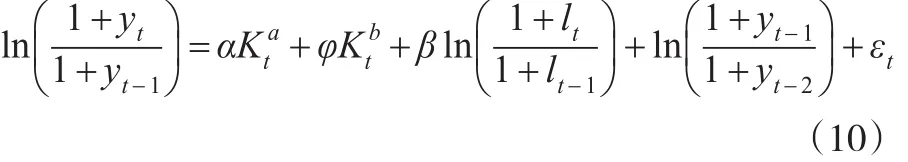
其中:
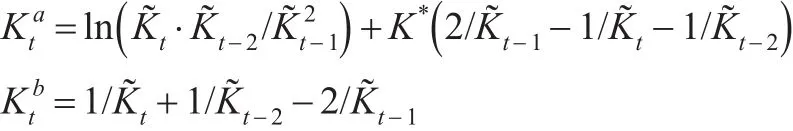
同时,考虑差分导致的信息丢失问题,另外采用一阶差分得到的回归模型:
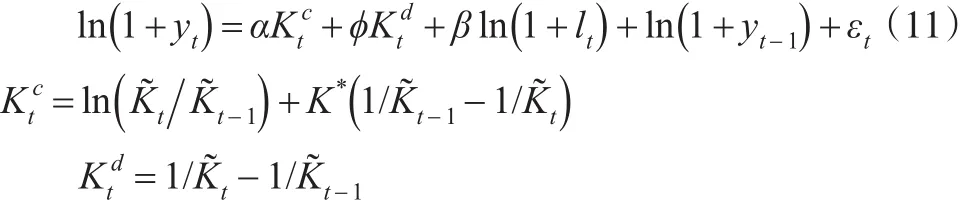
对于模型(10)和模型(11),在取K0的初始值K*后,计算出各期的以及模型中的,进行估计得到α和φ的估计值然后,根据式(9)可知因此以作为下一次迭代时K0的取值。重复上述过程,直至K0收敛。另外,在估计美国资本存量时,本文尝试在模型(11)中加入了虚拟Badyear的差分项,以反映一些年份实际GDP下降的情况,但对估计结果没有影响。Badyear在当年GDP小于上一年时取1,否则为0。对于中国1993—2015年间,未发生该情况,因此对中国资本存量的估计未加入该变量。
3 资本存量的直接搜索法估计模型
上文提出的估计方法沿用一个假设,即规模报酬不变。这对于建模而言无疑很方便,但是对于模型估计而言则可能带来一些问题,比如某些年份中因为一些外生或内生的冲击导致经济受到影响时,GDP与资本总量及劳动力的数据可能不匹配,从而对模型估计造成干扰。另外,实际估计过程中,由于计算过程较为复杂,迭代过程可能也会产生一些意想不到的变化,比如得到负的资本存量,使得无法取对数而中止迭代过程。对此,本文由增长模型中人均生产总量与人均资本的关系提出直接搜索法估计模型。
由式(1)可以得到:

假设A为常数1,则两边取对数有:
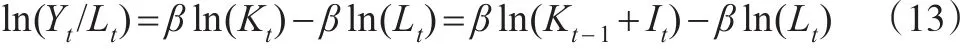
注意到式(13)右边两项的系数都是β,但是一正一负。另外,为了反映经济增长过程中的意外负面冲击,以及其他因素的影响。同样还在模型(13)的基础上加入了对数人均产出的滞后项以尽量控制其他未纳入模型的因素。而对于美国资本存量的估计还加入了虚拟变量badyear。在此基础上,差分后可以建立模型:
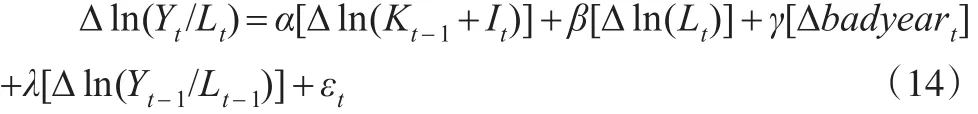
式(14)中Kt未知,可以选择不同的初始K0,根据模型(4)计算出Kt代入模型(14)进行回归。当K0选择合适时,模型(14)的回归系数α和β符号应当相反,但是绝对值接近。
除此以外,不少测算资本存量的文献中假设资本产出比为常数,由GDP推测资本存量。而美国的数据也显示,1950—2014年间,资本产出比居于2.52~3.46之间,大部分年份在3.16上下。若假设该指标确实比较稳定,则模型(12)可以写成:

假设A为常数,可以推得:
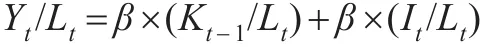
同样,在上式中加入badyear和人均产出的滞后项,再差分得到模型:
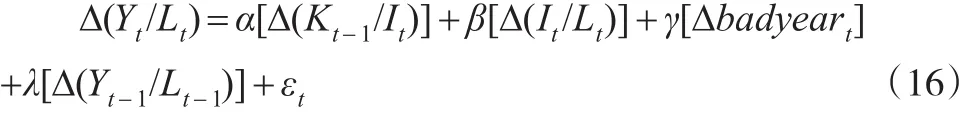
而在对中国资本存量估计时,则没有badyear的差分项。同样,当K0选择合适时,模型(16)的回归系数α和β符号应当一致,大小接近。而对于K0的选取可以采用直接搜索、格点法、最陡爬坡等方法。为了较为直观地展示整个搜索结果,本文采用了直接搜索法。
4 资本存量估计结果
4.1 数据来源
中国数据:本文估计采用的数据包括资本形成总额、投资价格指数、实际GDP、经济活动人口数、固定资产投资额、投资价格指数和折旧额。鉴于李宾[7]提供的数据被采用较多,因此2009年前上述各变量亦主要采用该文数据。而对于其后年份的数据则从相应年份的中国统计年鉴中补充。同时,对于折旧的处理也采用该文的方法,即用固定资本形成总额减去当年的折旧额。同时,由于1993年以前国家统计局未公布折旧额,基于数据的可得性,本文的时间窗口选择为1993—2015年。另外,所有变量均折算为2010年价格。
美国数据:美联储官网提供了历年的资本存量、GDP、劳工就业人数统计数据。本文选择该网站公布的按2011年价格计算的GDP、资本存量数据,劳动力数据根据所公布的按季节调整的就业人数取季度平均值作为该年份就业人数。
4.2 中国资本存量估计结果
参考现有文献1993年资本存量估计值分布,并考虑迭代过程中的数据溢出问题。模型(10)初始值选取区间为[100,3000]百亿元,选择了多个初始值,包括100亿元和2000亿元,代入模型(10)进行1000次迭代估计。迭代收敛速度视初始值大小,通常在迭代17~23次后收敛于471百亿元,与已有文献的估计差异较大。同时,区间内不同初始值的选取对于估计结果没有影响。模型(11)的初始值选取区间为[100,1500],通常在迭代70~90次后收敛。利用模型(14)和模型(16)估计时,设定搜索区间为[100,3000],步长10。结果模型(14)的估计值为1380,接近张军和章元[1]的估计值。由此计算出的资本产生比在2.6~3.7之间。并且资本产出在1993—1997年不断下降,此后至2004年缓慢上升,然后至2007年略快下降,2008开始加速上升,意味着资本产出效率的下降。而模型(16)未能给出有效估计值。同时也意味着,90年代以来在改革和金融危机的影响下,中国的资本产出比变动较明显。表1给出了中国资本存量估计结果。
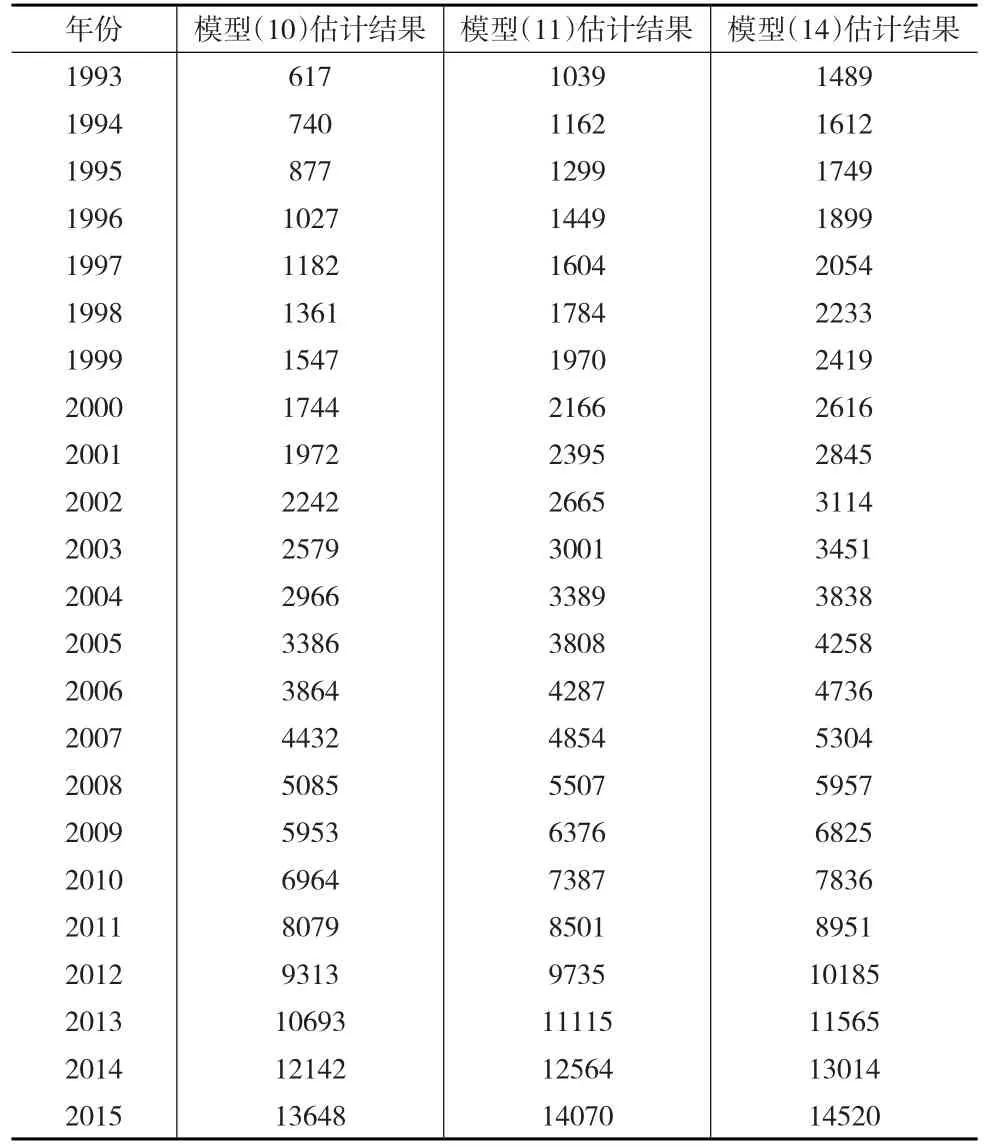
表1 中国资本存量估计所用数据及估计结果 (单位:百亿元)
4.3 稳健性检验
这里选择采用美国公布的数据来检验本文所介绍估计方法的可靠性。鉴于美国的数据都为1阶单整,因此不使用模型(10)。具体而言,先使用官方公布的按照2011年价格计算的1950—2014年的资本存量数据差分得到历年的净投资It。再依据模型(11)、模型(14)和模型(16),设定不同初始资本存量进行估计。另外,模型(11)的初始值选取区间为[1000000,7000000],通常迭代15次左右收敛于4125183百万美元。模型(14)和模型(16)的初始资本存量K0的搜索区间为[1000000,10000000],搜索步长为10000。并且,考虑模型设定可能与实际情况并不完全一致,因此模型中真实的α和β的绝对值可能并不相同。所以,实际进行搜索估计时,对于模型(14)和模型(16)分别根据(-α/β)和(α/β)选择能够使α和β最为接近的初始资本存量。
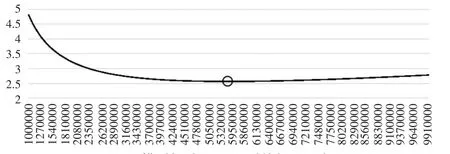
图1 模型(14)不同 K0时的(-α/β)
图1和图2给出了不同初始资本存量时,对应的(-α/β)和(α/β),并标出了极值点位置。其中模型(14)的估计显示,初始资本存量选择5480000较合理,而模型(16)的估计显示资本存量选择应为5520000,因此这两个模型估计的结果非常接近。而美国官方公布的1950年资本存量估计值为5680000。在净投资数据可得的条件下,因为资本存量估计值的差异主要在于基期资本存量,所以可以认为模型(14)和模型(16)得到的估计值较为准确。另外,与对中国资本存量估计类似的是,通过搜索得到的估计值要高于通过高斯牛顿法得到的估计值。
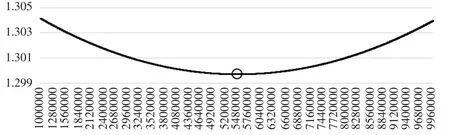
图2 模型(16)不同 K0时的α/β
5 结论
本文通过对经济增长模型的转换,提出了对中国资本存量进行非线性估计的思路和模型。根据对经济增长模型的不同处理,分别采用高斯牛顿法和直接搜索的方法进行了资本存量估计。结果发现:一阶差分后的高斯牛顿法估计值与现有文献估计值较为吻合,但是估计收敛速度较慢。而二阶差分后的估计值收敛很快,但是估计值明显低于近期文献的估计值。这种情况可能与数据质量,以及差分过程中的信息丢失有关。而采用直接搜索得到的估计值高于已有文献的估计值;另外,本文还利用美国官方公布的资本存量检验了本文提出的估计方法,发现直接搜索法能够得到比较准确的估计值,而高斯牛顿法估计值相比直接搜索得到的估值小,与对中国资本存量的估计情况一致。
