Huffman编码在不同场景中的应用研究
2018-02-09陈泓夫
陈泓夫
摘 要 文章主要针对不同场景的信源进行概率统计,并进行Huffman编码。通过编码分析得到了不同信源Huffman编码的区别,并将编码长度与香农极限进行了比较。发现在信源长度较长时,实际Huffman编码长度接近于香农极限,而在信源较短时,则与香农极限差别较大。
关键词 信源编码;Huffman编码;香农极限
中图分类号 TP3 文献标识码 A 文章编号 1674-6708(2018)204-0148-02
信源编码是将人类可以感知的机械信号转化为计算机或者数字逻辑电路可以感知的电信号,数学上表示为“01”串,是通信领域的一个重要环节。除进行信息转化,信源编码要消除信息冗余,从而提高传输效率,所以信源编码又叫信源压缩编码。
文章主要分为以下几个方面:1)统计了特定场景信源的符号特征,得到了其频率;2)把得到的频率作为概率,对该场景的信源进行了Huffman编码,并与香农极限进行了比较;3)针对不同场景的Huffman编码结果进行了分析。
本文的剩余章节安排如下:第1章介绍Huffman编码的基本原理;第2章介绍一个特定场景下的Huffman编码;第3章介绍不同场景的 Huffman编码研究分析;第4章对本文进行总结。
1 基本原理
文章主要介绍Huffman编码的基本原理。Huffman编码基于Huffman树的构造,构造过程如下:
1)统计字符序列的每种字符的频率,并为每种字符建立一个节点,节点权重为其频率;
2)初始化最小优先队列中,把上述的结点全部插入到队列中;
3)取出优先队列的前两种符号节点,并从优先队列中删除;
4)新建一个父节点,并把上述两个节点作为其左右孩子节点,父节点的权值为左右节点之和;
5)如果此时优先队列为空,则退出并返回父节点的指针。否则把父节点插入到优先队列中,重复步骤3)。
完成构造Huffman树之后,将每个父节点的左子节点编码为1(0),右子节点编码为0(1),每个字符正好是Huffman树的叶子节点,从根节点做深度优先搜索即可得到并将路径上节点的编码拼在一起即为该字符的Huffman编码。在本文中,用上下子节点来代替左右子节点。
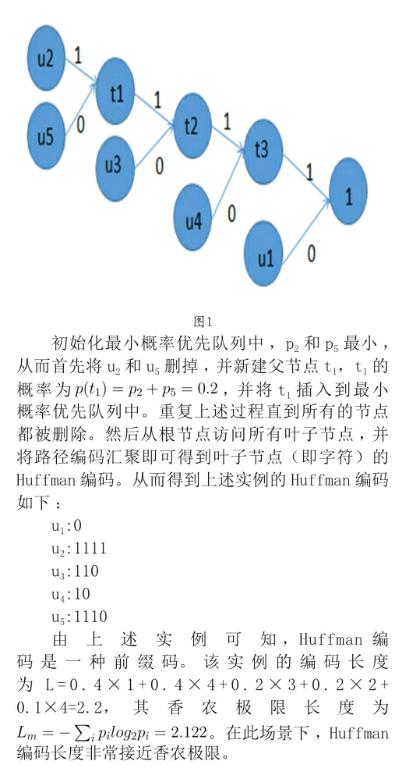
2 特定场景下的Huffman编码
文章摘取了BBC一篇新闻稿,对其Huffman编码情况进行了研究分析。首先我们统计了该新闻稿的字符频率情况(共12 524个字符),如表1所示。
将上标的字符频率作为字符概率,构建得到的Huffman树如图2所示。
3 不同场景下的Huffman编码分析
更换一个场景的信源做统计,将统计得到的频率作为概率使用,并进行Huffman编码,发现当统计字符个数较多时(如超过10 000个字符),各个字符的统计频率趋于稳定,Huffman编码长度非常接近香農极限长度,所以,Huffman编码是一种熵编码。
4 结论
文章主要介绍了Huffman编码在实际信源场景中的应用,并对不同应用场景下的编码进行了研究分析,在不同场景下,各个字符的统计频率趋于稳定,所以,Huffman编码形式趋于稳定。Huffman在实际应用中的编码长度趋近于香农极限。
参考文献
[1]Shannon C E.A mathematical theory of communica tion[J].ACM SIGMOBILE Mobile Computing and Communications Review,2001,5(1):3-55.
[2]Knuth D E.Dynamic Huffman coding[J].Journal of algorithms,1985,6(2):163-180.表1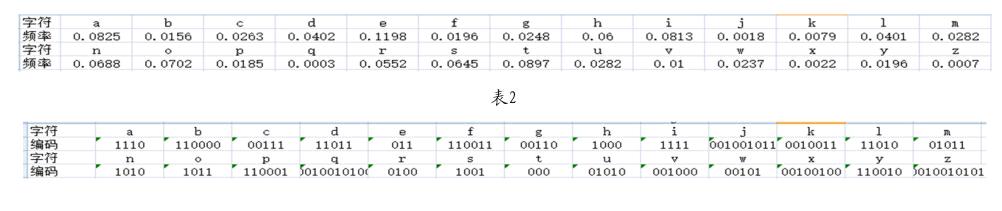 endprint
endprint
