混合加密的宋词载体文本信息隐藏技术
2018-01-23刘彦辰屈琪锋
刘彦辰,王 箭,屈琪锋
(南京航空航天大学 计算机科学与技术学院,江苏 南京 210016)
0 引 言
信息隐藏和加密作为保障信息安全的两种重要技术,一个可以隐藏秘密信息的存在,而另一个则变换了消息本身,在国防军事、隐私保护、电子商务等领域应用广泛[1]。与图像、视频等大容量信息隐藏载体相比,文本载体可提供冗余很少,不便嵌入隐藏信息[2]。但由于文本具有应用广泛、处理便捷等特点,如何设计出更好的文本信息隐藏方案则备受学界关注[3-4]。加密技术针对信息本身进行操作,其传输载体和传输信息是相同的[5]。加密后的密文在信道中以乱码的形式存在并通过密文截取进行破译或篡改[6-7]。信息隐藏处理的信息和传输载体是不同的,从传输载体的外观看并不具有任何实际意义,隐藏在载体内的隐写信息很难引起攻击者注意,从而降低了被攻击的风险。
现有的一些文本信息隐藏技术可分为基于文本排版[8-10]、语法内容[11-12]和语义生成[13]三类,尚未有将加密技术与文本信息隐藏相结合的方案。2009年余振山等[14]在同义词替换基础上提出了利用一首宋词词牌作为模板的信息隐藏算法“Ci-Steg”,生成了一篇符合该词牌名的宋词,但该方法使用单一模板并提取每个位置的词语作为词典库,仅能在模板容量限度内嵌入很少信息。现有的文本信息隐藏方法的安全性和载体隐蔽性较低,已不能满足现今的应用需求。
传统的文本信息隐藏系统很难隐藏大量的原始信息,几种结合加密与信息隐藏的方案大多是以图像为载体进行信息嵌入。王丽君等[15]提出基于DES加密与图像载体信息隐藏的算法。程显毅等[16]将DES加密与RSA公钥加密算法相结合,应用在基于语义水印的数字签名算法中。这两种加密算法缺点较为明显:一是加密系统安全性和加密效率有待提高,DES算法密钥长度短,保存和分配困难,容易被攻击并破解;RSA算法密钥长度过长,运算代价高、速度慢。二是很难在文本载体中嵌入大量内容。
文中提出了一种基于“AES-ECC”混合加密的宋词载体文本信息隐藏方案(SCSA)。将传输的原始信息通过混合加密工具进行加密后再将这些信息和加密密钥通过宋词文本信息隐藏系统进行隐藏。加密后的原始信息在宋词载体文本信息隐藏中进行隐蔽传输,具有安全性和隐蔽性双重安全保障。相比文献[14],词典容量进一步增大,设计的信息隐藏和提取方法更为灵活,进一步提升了信息嵌入率。相比文献[15],在加密效率和加密信息安全性上更优。相比文献[16],本方案提供了更为适合进行隐藏信息嵌入的宋词作为载体,嵌入率得到较大提升,并且从安全性和隐蔽性两方面弥补了文献[16]的不足。此外,针对较长的信息输入,提出两种宋词载体下的随机格律模板选择算法和指定格律模板算法,使信息隐藏模式更加灵活多变,不容易被攻击者找到规律。
1 宋词载体文本信息隐藏简介
国内外主流文本信息隐藏工具如Nicetext[17]、T-lex等,通过人工制定生成的风格模板和词典生成的载体文本具有生硬、逻辑性差、词典容量低和极易被识别和攻击等缺点,嵌入率最高仅1.5%左右。对此,引入宋词作为文本隐写载体。
宋词作为我国古代一种新体诗歌,具有代表音乐性的词牌,如《满江红》《沁园春》《水调歌头》等。宋词提供天然的生成模板供信息嵌入使用。该方案首先对全部宋词进行预处理,根据不同词牌韵律特点制定对应的格律模板,并依据模板对某一词牌下的全部宋词进行拆分处理得到词典,词典容量超过30 000词。
1.1 宋词格律模板制定
宋词词牌都有固定韵律划分,分为“平”“仄”“中”三声,“平”声调长,“仄”分为“上、入、去”三声,声调短,“中”则代表平仄均可。根据每篇词牌的平仄规律和分句特点,通过人工的方式进行模板制定,将宋词中的词语结合诗词韵律进行划分,划成二词或者三词的韵律块,对应原句保留标点符号,生成宋词词牌对应的格律模板。以《虞美人》为例,人工制定的模板与原始宋词对照见表1。
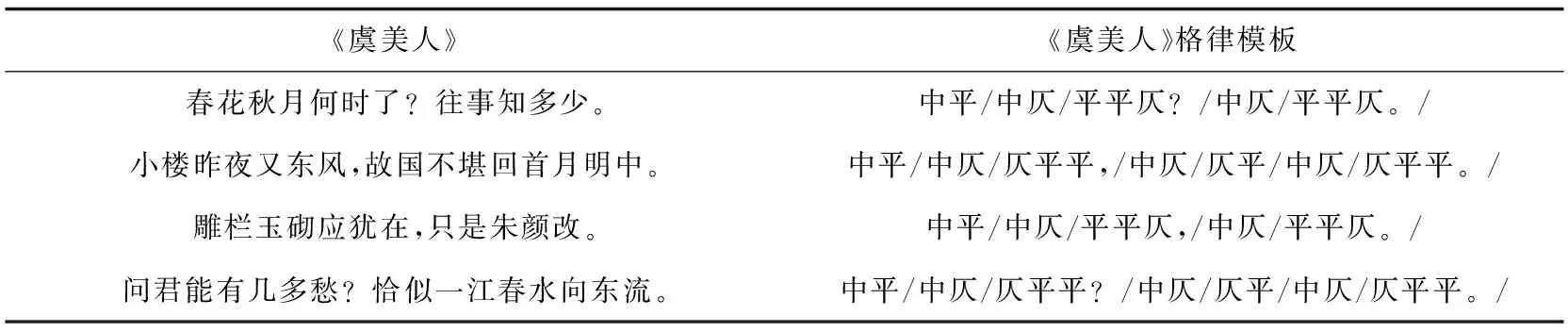
表1 宋词格律模板制定表
1.2 宋词的拆分与韵律词典生成
根据格律模板集合,将一篇词牌下符合指定格律模板Ti的宋词记为CTi,每个词牌下有多首宋词符合该模板,符合该模板的宋词集合记为CTi={Ak|k=1,2,…,poemsnum}。如《虞美人》中包含113首宋词,poemsnum=113。从表1知,符号“/”将宋词的每一句划分成长度为二词和三词的韵律块,使用blocknum表示韵律块划分数量。根据宋词的韵律规律,将每个二词或三词的韵律块如“中平”、“中仄”、“平平仄”用韵律块集合R={Rj|j=1,2,…,rhythmnum}表示,Rj表示任意韵律块。通过宋词拆分算法,将宋词集合CTi中的每一首宋词Ak拆分成词语序列(wkR1,wkR2,…,wkRrhythmnum),将符合同一韵律块Rj的词语wkRj存入韵律词典Dj中,拆分得到韵律词典。以《虞美人》为例,对poemsnum=113首宋词进行拆分,可以得到“中平”、“平仄”等韵律块。宋词拆分与词典生成的算法描述如下:
算法1:宋词拆分与词典生成算法。
步骤1:将140篇宋词词牌对应的全部首宋词进行格式处理,去除标点符号和换行符以便机器读取。
步骤2:初始化位置参数k为零,以及词典集合D。对每首宋词和对应格调模板进行操作,如果第i个模板的词牌名与待处理宋词词牌名相同,则将位置信息i存入k中。
步骤3:依次对格律模板的每个位置进行处理,如位置为j的词语word[j]对应格律模板中同一位置的韵律为rhythm,则将该词语存入词典D[rhythm]中。
步骤4:依次处理其余宋词,将划分得到的词语存入词典,运行并集运算去除重复词语,按照词典序排列得到完整词典,得到“平平”等36个韵律块。
步骤5:使用哈希函数对词典内全部词语进行散列处理,以文件流形式写入到词典的每个位置。
2 基于混合加密的宋词载体文本信息隐藏算法
2.1 系统工作原理
传输双方共同持有格律模板T和词典D,传输方将原始信息通过混合加密工具AES进行加密,使用ECC对AES密钥进行加密,生成数字信封与密文通过隐写器以随机生成模板或者指定模板方式进行隐藏,隐藏后的隐写信息在隐蔽信道中传输。接收方首先使用提取器进行还原操作,得到数字信封和密文两个文件。在解密过程中,使用ECC私钥解密数字信封得到的AES密钥,进行AES解密操作后得到原始信息。
2.2 生成模板选择
在格律模板集合T={Ti|i=1,2,…,n}中,共有140个模板可用于生成宋词,用户可以根据实际情况,选择单一模板生成多篇宋词和随机选择多个模板生成多篇宋词两种方案。由1.2节可知,不同的格律模板Ti包含了blocknum个划分块,以《虞美人》为例,共有24个划分块。将划分块按读写顺序编号,对于每一个划分块Kp,其集合可以表示为:{Kp|p=1,2,…,blocknum}。
其位置上的韵律块Rj对应的词典行Dj内共有Wj个词语,计算得到每个划分块位置Kp可以容纳的二进制信息长度计算公式:
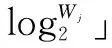
(1)
在格律模板《虞美人》中,整首词可容纳的信息量可表示为:
(2)
由词典D内的韵律词库Dj容量知,“中平”包含2 712个词(11 bit),“中仄”包含5 328个词(12 bit),“平平仄”包含1 567个词(10 bit),“仄平平”包含2 711个词(11 bit),“仄平”包含2 253个词(11 bit),经计算整首词容量达到270 bit。
2.2.1 指定格律模板生成
选择格律模板库中任一词牌模板Ti进行隐写生成。模板库中模板可嵌入信息量与模板对应的宋词风格各不相同,长度较短的模板如“捣练子”、“潇湘神”,通篇仅35字,模板容量分别为119 bit和115 bit。较长的模板如“重楼叠月”,通篇有390字,模板容量可达1 537 bit。设传输数据量长度L为1 000 bit,需要用到4篇长度为270 bit的《虞美人》进行生成,多余的模板位置进行补零操作以增加冗余。算法2对此过程进行了简要描述。
算法2:指定格律模板生成算法。
输入:需要隐写的秘密信息长度L,隐藏信息的模板Ti;
输出:倍增的模板放在TEMPLETE.txt。
While(L>0)
L=L-T.length;
put T into template;
end while;
return S;
算法优点在于通信双方可根据传输信息长短进行人工选择,选取嵌入率高的模板进行生成,在遇到紧急情况时可以更换传输模板,从而避免被敌手攻击。
2.2.2 随机选择不同格律模板生成

算法3:随机格律模板选择算法。
输入:需要隐写的秘密信息长度L,140篇已经预处理(按容量升序排序)的模板Ti;
输出:生成的模板文件TEMPLETE.txt。
while(L>500)//如果超过500则可以至少放两个模板,随机选一个新的模板放入
k=rand(T.length);//从T.length首词的模板中随机选一个
put T[k] into template;
L=L-k;//除去对应编号
end while;
l=1;//二分查找下界是1
r=T.length;//二分查找上界为模板的数量
while(l mid=(l+r)/2;//二分查找中间模板的长度 if(mid==L) {l=mid;break};//如果长度刚好,则选取中间值 if(mid>L) r=mid+1;//如长度较短,则选取较大的一段区间 if(mid end if; end if; end if; end while; put T[l] into template;//将编号为l的模板存入模板文件 通过信息隐藏算法对加密后的信息进行隐藏以生成隐写宋词。以1.2节给出的《虞美人》为例,格律模板第一行为“中平/中仄/平平仄?/中仄/平平仄。/”,结合韵律词库Dj对词典进行编码。为方便举例,对选词数量取2的整数倍进行表示,假设“中仄”含有16个词,即可以表示4位。词典编码如表2所示。 表2 词典编码 接收到的加密信息转换成二进制编码:“01101011011001010”,将这段编码按照格律模板中每个位置的容量划分为“3/4/3,4/3”后,将编码按照位置容量进行划分,得到划分后的编码串“011”、“0101”、“101”、“1001”、“010”。在韵律词典中找到对应的词语,分别是“青枝”、“柳雨”、“何人见”、“细雨”、“烟云起”。将词语填入格律模板对应的位置,就可以得到改写的《虞美人》第一句:“青枝柳雨和人见?细雨烟云起”。在这句中嵌入了17 bit信息,若使用已生成的完整词库,可嵌入的容量可表示为: (3) 设词典库容量进一步扩大,可嵌入的信息量会进一步增大。算法4对加密信息隐藏过程进行了描述。 算法4:加密信息隐写算法。 输入:待隐写的加密信息,宋词模板库文件TEMPLETE.txt; 输出:包含隐写信息的多篇完整宋词S。 m’=0; Len=0; m’=strToBinstr(m); For the input secret message m, all converted to binary coded m;’//对于输入秘密消息m,全部转换为二进制编码m’ if(m’.getLength() rsta();//重新生成模板 end if; if(m’.getLength( ) end if; for each block∈tido Len=log(Wj); B=the next Len binary number in m’; n=binToDec(B);//将B由二进制编码转换成十进制编码存入n; word[i]=n;//word[i];表示这个韵律下词典里面的第i个词 S.add(word[i]); //将每个词填入宋词S的每个位置 end for; return S; 接收方收到含有隐藏信息的宋词后,通过词典D和宋词格律模板库T,以提取算法经还原得到秘密信息m'。由上一节所示,接收到的隐写宋词一句为“青枝柳雨和人见?细雨烟云起。”根据这句对应的词牌《虞美人》在对应位置的格律模板“中平/中仄/平平仄?/中仄/平平仄。/”将这句词划分为“青枝”、“柳雨”、“何人见”、“细雨”、“烟云起”的词语序列,由表3可以进一步得到秘密信息m'=“01101011011 001010”。算法5对隐写信息提取过程进行了描述。 算法5:秘密信息提取算法(Extract)。 输入:宋词模板T,生成的包含秘密信息的隐写宋词S; 输出:加密消息m。 m’=null;for eachblock∈tido //对多篇宋词每篇按照格律的划分进行操作 for each word∈D[rhythm] do //对于每个划分块进行操作 if(word[i]==blockword) //第i个词和这个位置的词对应 k=i; 将位置信息i记录为k break; end if; end for; Len=log(Wj); k’=decToBin(k); m’=m’.add(k’);//迭代生成二进制秘密信息m’ end for; m=binToStr(m’);//将二进制下的秘密信息m’进行还原returnm; 该方案提出的隐藏算法使用了宋词这种天然生成模板进行生成,隐写宋词在长短、句式、韵律以及词牌等语言要素上与原始宋词毫无区别,攻击者得到了隐写宋词后无法通过机器进行检测和分析。同时,由于经混合加密操作后生成的密文信息是一串不具有任何意义的乱码,相当于对原始信息人为地加入了随机噪声,无形中为原始信息增加了另一重安全。 该系统使用的AES-ECC混合加密工具和隐写提取算法,选取10个长度为100字的中文文本样本,对加密、隐藏、提取和解密过程时长进行测试,采用的实验平台为Visual Stdio2013,运行环境为Windows 10,64位操作系统,基于Core(TM) i5-3230 M,2.6 GHz的处理器,4 GB内存。时耗对比如图1所示。 图1 SCSA运行过程耗时对比 在对宋词的预处理中,得到了《暗香》等140个格律模板作为生成模板以及来自《全宋词》2 538首宋词经拆分后,删除了生僻汉字且经过去重和哈希重置后容量达30 278词的词典。混合加密工具和隐写算法对输入的信息语种无要求,在隐写过程中会将加密信息转换为二进制来表示。当输入的待传信息为1 024 bit的毛泽东七律诗《长征》时,使用随机选择模板算法密文文件和数字信封进行隐写,生成的隐写宋词如图2所示。 《夜游宫》梦燕均欢见也,庆岁岁懒携相继。挂也山亭算未有。酒消磨谩赢得欺贺晏。归魂年华占,料带角飘红无觅。尽了柔条几心酌。六千场纪今辰想当时。《鹧鸪天》更祝论长翠岩屏,寒猿睡魂怕春知。年时天竺漂流处,风骨欢离何处娇。唱新词,更何疑。骨清番做步溪桥。风寒暮暮流云碎,相和回惶度管弦。《望远行》葡萄梦惊,江南雨,归路林泉入觐。晚蝉镇护,树色桃源,梦去星横桥畔。独步琼珠,开口屡更深掩,消得茂林凝皓。满疏篱,林表葡萄每临。清和,宫女影凝日下,瞻圣主,阳台俄顷。何逊身世,屡更称少,欢伯宴游政尔。启母杨花,张绪弄凉如人道,恨远慧刀临流。步月来爇白,璿枢爇白。 图2 生成的隐写宋词 当输入1 024 bit信息经混合加密工具处理后,生成AES加密后的1 024 bit密文和长为160 bit的AES密钥文件(数字信封),使用随机模板选择算法将生成4篇不同词牌宋词。可见混合加密并未带来过高的通信压力,反之对系统安全性的提升非常显著,也避免了通信双方进行密钥协商所带来的不便。 本节将对文中方案的两种隐写宋词生成方法嵌入率进行分析以及和当前Nicetext以及Ci-steg等主流文本信息隐藏方案进行对比。 使用的140篇宋词格律模板长短不一,较长的模板如298个字的《莺啼序》,244字的《哨遍》;较短的模板如43字的《相见欢》。经实验得知,模板提供的信息嵌入率与模板长度无关,较短的模板也可以提供很高的嵌入率。如138字的《过秦楼》,嵌入率可达到28.13%,60字的《河渎神》,嵌入率也达到了27.5%,反之《莺啼序》只有26.5%,嵌入率最低的模板《渔歌子》也达到了20.15%。故而模板的嵌入率与每个划分块的韵律词典容量相关,包含大容量韵律词典的模板可以提供较高的嵌入率,进一步增大词典容量是提高嵌入率的一种途径。在实验中,当输入1 024 bit的10个加密信息样本后,使用随机模板生成算法与指定单一模板(《念奴娇》等)算法生成隐写宋词,得到的嵌入率对比如图3所示。 由图3可见,随机模板生成算法在运行10次时得到的平均嵌入率达到了24.2%,虽然不如一些指定模板,但因其每次均能生成不同词牌宋词,可以动态找寻长短较为匹配的模板,模板利用率较高,生成方式更为灵活,令攻击者无规律可寻,安全性较强。 同时,将本方案SCSA(单一模板STSA与随机模板RTSA)和Ci-steg[14]、Nicetext的信息嵌入率进行比较,分别输入1 024 bit的10个不同样本数据。不同方案的嵌入率对比如图4所示。 图3 SCSA两种生成方案的嵌入率对比 图4 SCSA方案与其他方案的嵌入率对比 由图4可见,STSA因选择模板不同,嵌入率保持在20.15%~28.13%;RTSA嵌入率平均在24.2%,Ci-steg维持在16.1%,而Nicetext仅为1.5%左右。相比现有方案,文中方案在嵌入率和安全性上有了大幅提升,且性能更好。 文中提出了一种全新的文本信息隐藏算法,结合AES算法和ECC算法设计了一种混合加密工具,应用于宋词载体文本信息隐藏系统中。与现有隐写工具相比,具有嵌入率高、隐蔽性强的特点。后期将加以改进,如将唐诗、现代题材诗词中符合平仄韵律的词语加入词典库以提高词典容量,提高载体的嵌入率;对词典进行处理,将不同词性的词语进行分类,在生成宋词时按照词性加以区分,可使生成的宋词连贯性更强,从而提高信息隐藏系统的隐蔽性。 [1] 付 敏,戴祖旭,胡文涛.一种文本信息隐藏中的语法检测算法[J].科学技术与工程,2015,15(21):142-145. [2] 周继军,杨 著,钮心忻,等.文本信息隐藏检测算法研究[J].通信学报,2004,25(12):97-101. [3] COX I J,KALKER T,PAKURA G,et al.Information transmission and steganography[M]//Digital watermarking.Berlin:Springer,2005. [4] COX I J,MILLER M L.The first 50 years of electronic watermarking[J].EURASIP Journal on Advances in Signal Processing,2002,2002(2):126-132. [5] 李丽娟,熊淑华.基于文本的信息隐藏技术研究[J].现代电子技术,2006,29(5):67-69. [6] PETITCOLAS F A P,ANDERSON R J,KUHN M G.Information hiding-a survey[J].Proceedings of the IEEE,1999,87(7):1062-1078. [7] KATZENBEISSER S,PETITCOLAS F A.Information hiding techniques for steganography and digital watermarking[M].Norwood,MA,USA:Artech House,Inc,2000. [8] MAXEMCHUK N F.Electronic document distribution[J].AT&T Technical Journal,1994,73(5):73-80. [9] BRASSIL J,O’GORMAN L.Watermarking document images with bounding box expansion[C]//Information hiding.London,UK:Springer-Verlag,1996:227-235. [10] 崔光明,洪 星,袁 翔,等.基于不可见字符替换的信息隐藏方法研究[J].计算机应用与软件,2016,33(4):277-280. [11] ATALLAH M J,RASKIN V,HEMPELMANN C F,et al.Natural language watermarking and tamperproofing[C]//Information hiding.London,UK:Springer-Verlag,2002:196-212. [12] CHAPMAN M,DAVIDA G I,RENNHARD M.A practical and effective approach to large-scale automated linguistic steganography[M]//Information security.Berlin:Springer,2001. [13] LIU Yuling,SUN Xingming,GEN Can,et al.An efficient linguistic steganography for Chinese text[C]//IEEE international conference on multimedia and expo.[s.l.]:IEEE,2007:2094-2097. [14] 余振山,黄刘生,陈志立,等.用宋词实现高嵌入率文本信息隐藏[J].中文信息学报,2009,23(4):55-62. [15] 王丽君,周萍萍.基于真彩色图像的信息隐藏算法[J].光电子技术与信息,2005,18(6):44-48. [16] 程显毅,张启杰,耿 飙.基于语义水印的数字签名算法[J].计算机应用研究,2009,26(10):3914-3917. [17] CHIANG Y L,CHANG L P,HSIEH W T,et al.Natural language watermarking using semantic substitution for Chinese text[C]//International workshop on digital watermarking.Berlin:Springer,2003:129-140.2.3 加密信息隐写
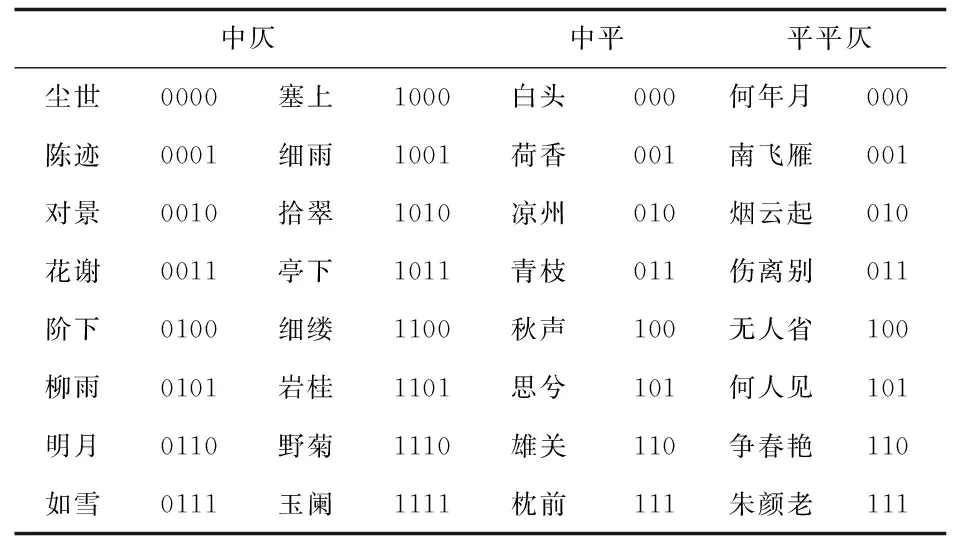
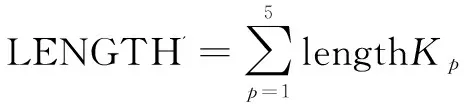
2.4 隐写信息提取
3 安全性分析与性能分析
3.1 安全性分析
3.2 性能分析
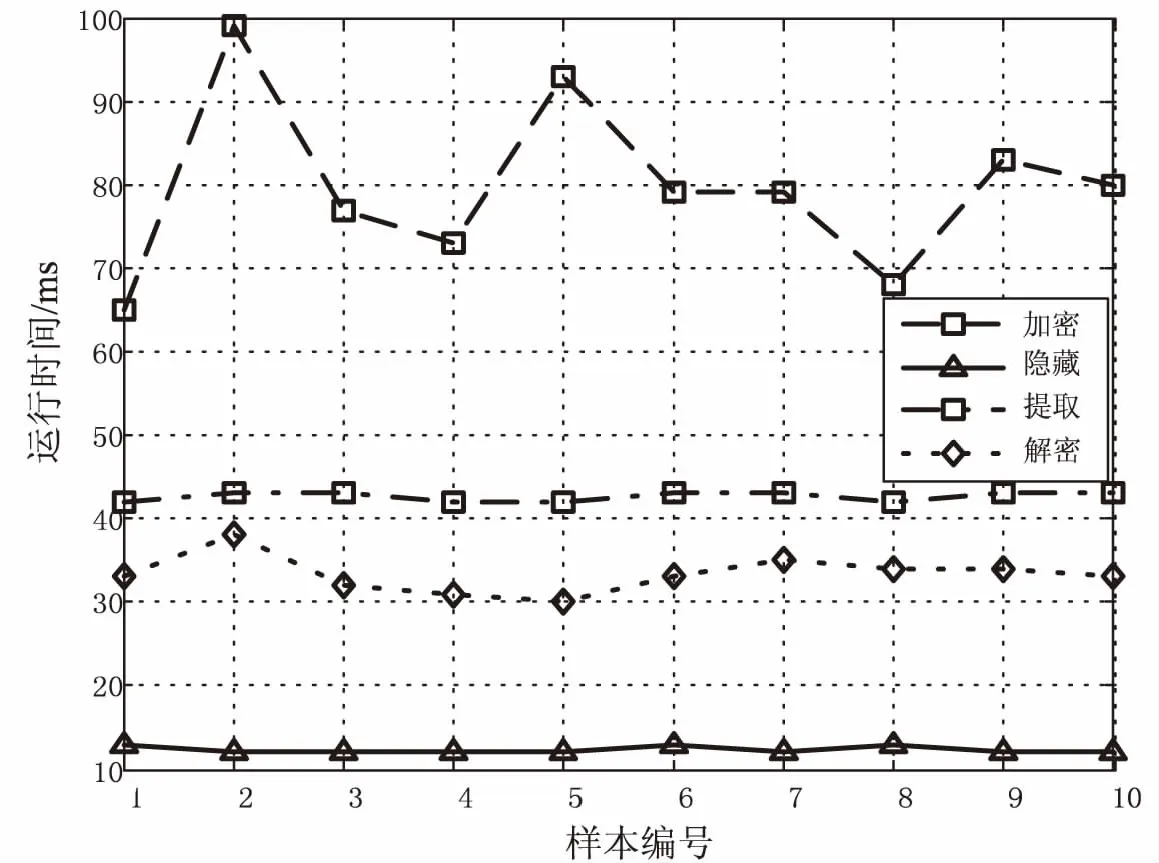
4 实 验
4.1 实验结果

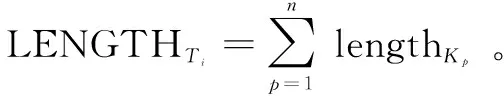
4.2 对比分析


5 结束语
