权重随机正交化的极速非线性判别分析网络
2018-01-23谢群辉
谢群辉,田 青
(1.南京航空航天大学 计算机科学与技术学院,江苏 南京 211106;2.南京信息工程大学 计算机与软件学院,江苏 南京 210044)
1 概 述
极速学习机(Extreme Learning Machines,ELM)[1]以其训练速度快,易实现,泛化性能好等优点受到广泛关注。相关研究证明,ELM具有很好的万能逼近能力(Universal Approximation Capability)[2]。相比SVM等机器学习分类方法,ELM具有更好的分类泛化性和学习快速性[3],并在特征学习、分类、回归和聚类等方面获得了一系列拓展[4-6]。例如,极速非线性判别分析方法(Extreme Nonlinear Discriminant Analysis,ENDA)就是在ELM基础上提出的,通过随机初始化输入权重取代了传统的前馈神经网络迭代训练,提高了计算效率;利用LDA进行特征提取并能获得全局最优,避免了神经网络局部最小的问题;通过对线性不可分数据进行非线性化特征选择,在高维空间中进行LDA降维和特征判别分析,并且获得可视化效果,非常有利于后续的分类。
非线性化方法主要包含神经网络方法和核方法两大类,其中神经网络非线性化方法又包含深度学习和浅层网络(ELM)两大类。文献[6-7]表明,随机初始化正交权重,可以改善其泛化性能。权重的正交化方法更适用于高维的图像聚类或分类。在处理小样本、高维度的数据时,权重正交化的设计可以去除特征以外的噪声,提高模型的计算效率。通过初始化正交权重,避免传统深度学习的反向迭代计算权重,达到优化非线性组合的目的。文献[8-10]表明,正交性在深度网络学习中至关重要,正交权重层通常被设计成滤波器组,实现更完备特征的提取,达到非常好的无监督特征分类学习效果,给高维大数据学习正交化提供理论依据。在MATLAB环境下实现卷积神经网络(Convolutional Neural Networks)的深度集成化[11],其中滤波器模块利用权重正交化约束的设计。通过权重的随机正交化可以过滤冗余信息,以达到快速训练深度神经网络权重的目的。这种权重正交层被称为施蒂费尔(Stiefel Layer),在很多BP网络中被广泛应用,它的作用是降维和特征提取。文献[7]提出的传统的深度学习,不仅学习速度缓慢,而且在计算资源上花费巨大。为解决这一问题,通过极速学习机自动编码(ELM-AE)代替传统的BP梯度下降算法,大大提高了计算速度,节省了计算成本。ELM-AE正是通过随机正交初始化权重、偏置以及输出权重达到子空间约束的目的。利用多层正交化ELM网络组成多层神经网络,在计算速度上要比传统的深度学习快很多。考虑到深度学习计算的时效性问题,核方法显然比深度的神经网络方法要快,而有关核方法的权重正交设计方法[12-13]相继被提出,这足以说明,在学习理论中正交概念是至关重要的。
在机器学习中,由于多层网络训练困难,核方法又受到核函数隐节点线性与样本数的限制,当样本数很大时,核方法计算花费大。而只有一层隐含层的浅层模型备受欢迎,作为机器学习的重要发展方向-极速化的浅层学习,ELM正是这种浅层学习代表。在此基础上,文中提出了正交约束设计特征选择方法(O-ENDA)。受ELM-AE的启发,将原有浅层神经网络ENDA改造成O-ENDA,不仅能过滤图像的冗余信息,而且与前面提到的深度学习对比充分发挥了浅层神经网络计算速度快的优势,在保证分类性能的基础上,O-ENDA比深度学习和核方法更容易实现极速化。在保证数据结构化多样化特性的前提下,对输入权重正交化强制约束,能够提取结构特征效果,正交后输入权重映射在保持多样性的基础上同样可以提高计算效率。考虑到隐层的节点数与数据维度空间问题,从而实现降维(或者升维)作用,在保证数据原有多样化特性的情况下,降低了数据的冗余信息,提取数据特征。
2 正交特征映射
2.1 极速学习机
极速学习机是由黄广斌提出的快速求解单隐层神经网络的快速学习算法。与传统的Back-Propagation(BP)算法不同的是,利用权重的随机初始化设置输入权重和偏差,代替传统的梯度下降的权重学习。假设网络层输入为x,目标输出为T,估计输出为y。
随机初始化隐层节点,给定一个训练集{(xi,ti)|xi∈n,ti∈m,i=1,2,…,N},xi为特征输入向量,ti为对应的输出目标向量,L为隐节点个数。ELM代价函数最小的目的是最小化训练误差,最小化输出权重:
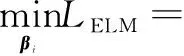
(1)
其中,H为隐层输出矩阵。

(2)
T为训练数据目标矩阵。

(3)
ELM训练算法流程如下:
步骤2:计算隐层输出矩阵H。
步骤3:获得输出权重向量。
β†=H†T
(4)
当T=[t1,t2,…,tN]T∈N×m,H†为H的Moore-Penrose广义逆矩阵。
考虑到ELM优化方法中更好的泛化性能,解得:

(5)
对应的ELM输出函数表示为:
(6)
2.2 权重随机初始化
回顾ENDA的训练过程,其网络结构为输入层、隐层和输出层三层网络,共分为两个步骤。第一步,随机生成输入层的连接权重和偏置,对输入进行随机特征映射;第二步,计算LDA层投影权重,将隐层输出作为LDA输入数据,同时输出层可用于可视化,如图1所示。由于第一层为随机生成权重,所以只需计算第二层的投影权重,整个模型计算简单、有效。

图1 O-ENDA网络结构
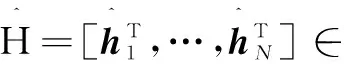
(7)
(8)

样本总类内散度矩阵Sb和类间散度矩阵Sw分别定义为:
(9)
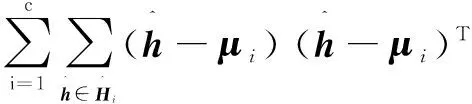
(10)

(11)
然后对其进行求解,最大化J(W)等价于求解如下广义特征问题:
SbW=λSwW
(12)
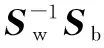
2.3 正交特征选择
正交特征选择通过优化算法选择出有利于分类的特征子集[6],为避免“维数灾难”,处理高维数据,提出权重正交试验设计,从而选出数据中有代表的特征向量,在保留完备和均匀特征信息的条件下,减少了计算复杂度。假设样本空间xi=[x1,x2,…,xN],xj∈n,对应的标签T=[tj1,tj2,…,tjm]∈m,将样本投影权重矩阵B到隐层,从而得到特征子空间H。
首先讨论隐层节点参数L构建不同的或者相等的维度空间,L与样本维度n的关系:当n=L时,属于平等维度表示;当n>L时,属于压缩表示(降维);当n
(13)
其中,E为高斯扰动;g(·)为Sigmoid激励函数。
正交化后必须保持子空间的基不变,等效优化效果。ATA=I的约束条件是A∈{RW},R∈{RRT=RTR=IP}等效优化效果,A是正交的,通过计算经验误差度量学习效果。O-ENDA模型的经验损失如下:
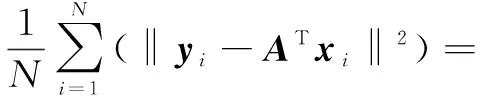
(14)
O-ENDA算法步骤如下:
步骤1:对数据进行预处理;

步骤3:计算O-ENDA的隐层输出hi(通过式(13));

步骤5:对输出层结果进行分类。
3 实 验
仿真环境如下:MATLAB R2015a,Intel(R) CoreTMi5-3470 CPU @3.20 GHz,16.0 GB内存,64位Win10专业版操作系统。采用UCI机器学习数据库CNAE-9数据、手写数字MNIST数据和CIFAR10数据分别进行实验。实验中完整的数据集被划分为10部分,训练和测试数据集使用了10重交叉验证方法。对输出层采用KNN算法进行分类,比较原ENDA和正交化改进后的O-ENDA的分类性能,三种数据如表1所示。分别为文本、手写数字、图片的数据,冗余信息较多,维度逐渐加大,对于了解正交化改进后的效果有一定代表性。
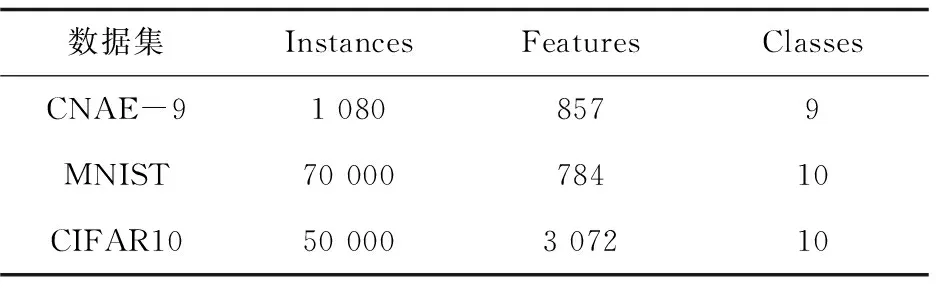
表1 数据集
3.1 UCI数据
CNAE-9数据集包含1 080个文档的自由文本,共分为9个类。从原始文本进行预处理获得当前数据集。每个文档被表示为一个向量,每个词的权重是它在文档中出现的频率。其中,高斯扰动参数设置均值μ为0,方差σ2为1。
调整隐节点参数获得重复20次实验平均值和方差,在CNAE-9数据集上的表现如图2所示。实验结果表明,在维度较大的情况下,ENDA和O-ENDA的分类效果都很明显,O-ENDA分类的性能更稳定。
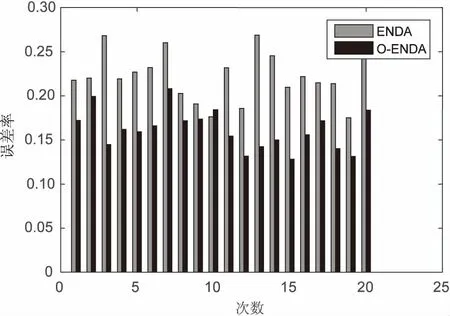
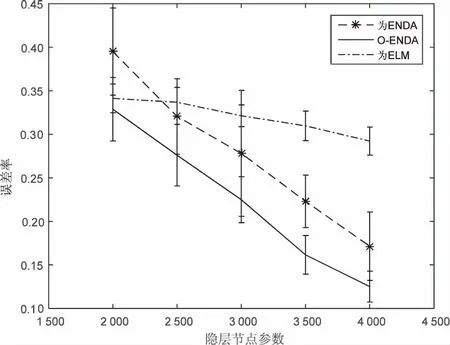
从O-ENDA和ENDA的误差率来看,O-ENDA分类效果更好。讨论了隐节点参数L与数据原有维度n的关系,当L>n时,都正交化需要调整权重矩阵,与L 图2 CNAE-9数据集误差率对比曲线 该数据为手写数字MNIST字体库,包含70 000个样本。要对0至9手写数字图像进行识别,每一个手写数字样本是一个28*28像素的图像,因此对于每一个样本,其输入信息就是每一个像素对应的灰度,总共有784(28*28)个像素,也就是数据中包含784个特征,实验前需对转换成普通的图像格式进行预处理。 手写数字识别大多来源于邮政编码以及银行业务自动识别,由于字体变化大,识别要求高,在多数情况下通常采用多网络的深度学习来提高识别率,主要利用神经网络非线性化学习能力和快速并行来提高识别率。目的在于验证浅层的O-ENDA可以通过正交过滤器消除冗余信息来解决此类问题。其中,高斯扰动参数设置均值μ为0,方差σ2为0.1。 从图3可以看出,ENDA具有很好的分类精度,而且O-ENDA的误差率平均值比ENDA还要小,这充分表明,在MNIST数据特征维度到隐层维度,实际上是进行了非线性化升维再进行判别分析。O-EDNA去除了更多冗余信息,更加易于分类,保留特征具有线性独立的特点,因为正交的随机权重分布更均匀,提取特征更加完备,无论是从分类精度还是标准差上,O-ENDA都要优于原来ENDA。 图3 MNIST数据集误差率对比曲线 CIFAR10数据显示的每一行存储32×32的彩色图像,共50 000个数据集,第1 024项包含红色通道值,1 024绿色,最后1 024蓝色。标签范围为0~9,10个类别每个类图片5 000张。随机采集10 000个样本为10 000×3 072的矩阵进行实验。 比较MNIST数据和UCI数据,CIFAR10维度更大,权重正交化效果更明显。从误差率比较ENDA和O-ENDA,结果如图4所示。其中,高斯扰动参数设置均值μ为0,方差σ2为0.1。 从图4(重复20次实验)可以看出,当L=3 500时,O-ENDA权重正交化的误差性能更加稳定。当隐节点参数在2 000~4 000范围变化时,与数据维度3 072相比,分别进行了降维、等维和升维三种情况的表示。如图5所示,可以得到CIFAR10数据集20次误差率平均值和节点参数关系图,从图中可以看到,正交化O-ENDA使得物体更加线性独立和易于分类。 图4 隐节点参数3 500时的误差率直方图 图5 CIFAR10数据集误差率对比曲线 从三个数据集上的实验结果表明,对较高维度的数据进行分类时,O-ENDA比ENDA分类效果更好,特别是在CIFAR10数据集作用更加明显。由于图像数据冗余信息越多,权重正交化取得分类效果就越明显,O-ENDA算法分类性能越好,且隐层更能代表原样本数据多样性特征,充分验证了正交作为神经网络一种重要的特征提取方法的有效性,从而也开启了浅层神经网络对高维度正交提取完备特征,能有效防止“维数灾难”。 在极速非线性化判别分析网络基础上提出正交约束。权重Gram-Schmidt正交化方法作为神经网络一种重要的优化方法,与传统神经网络方法和核方法相比,具有速度和可伸缩性两方面的优势。权重正交的对象为高维度小样本数据集,通过正交化局部保持投影的度量学习分析,正交的随机权重分布使得特征之间均匀更加线性独立,一方面降低了数据的冗余信息,利于后续分类;另一方面提取更为完备的特征,整体上提高了模型泛化性能。实验表明正交优化能提高算法的性能。 集成学习能够对模型比较独立的样本进行训练,然后把结果整合起来进行整体的投票决策。对于随机映射每个不同的基分类器集成[14],这是一种非常有效的方法。计算机的并行化和批量扩展能力更加适合集成学习的未来发展,这也是下一步研究的方向。 [1] HUANG G B,ZHU Q Y,SIEW C K.Extreme learning machine:a new learning scheme of feedforward neural networks[C]//International joint conference on neural networks.[s.l.]:IEEE,2004:985-990. [2] HUANG G B,CHEN L,SIEW C K.Universal approximation using incremental constructive feedforward networks with random hidden nodes[J].IEEE Transactions on Neural Networks,2006,17(4):879-892. [3] HUANG G B,ZHOU H,DING X,et al.Extreme learning machine for regression and multiclass classification[J].IEEE Transactions on Systems,Man,and Cybernetics,Part B,2012,42(2):513-529. [4] HUANG G B,BAI Z,KASUN L L C, et al. Local receptive fields based extreme learning machine[J].IEEE Computational Intelligence Magazine,2015,10(2):18-29. [5] WIDROW B,GREENBLATT A,KIM Y,et al.The no-prop algorithm:a new learning algorithm for multilayer neural networks[J].Neural Networks,2013,37(1):182-188. [6] ONETO L,BISIO F,CAMBRIA E,et al.Statistical learning theory and ELM for big social data analysis[J].IEEE Computational Intelligence Magazine,2016,11(3):45-55. [7] KASUNL L C,ZHOU H,HUANG G B,et al.Representational learning with ELMs for big data[J].IEEE Intelligent Systems,2013,28(6):31-34. [8] TURK M,PENTLAND A.Eigenfaces for recognition[J].Journal of Cognitive Neuroscience,1991,3(1):71-86. [9] HYVARINEN A.Fast and robust fixed-point algorithms for independent component analysis[J].IEEE Transactions on Neural Networks,1999,10(3):626-634. [10] CAI D,HE X,HAN J,et al.Orthogonal laplacianfaces for face recognition[J].IEEE Transactions on Image Processing,2006,15(11):3608-3614. [11] VEDALDI A,LENC K.Matconvnet:convolutional neural networks for matlab[C]//Proceedings of the 23rd ACM international conference on multimedia.[s.l.]:ACM,2015:689-692. [12] 黄金杰,常英丽.基于支持向量机和正交设计的特征选择方法[J].计算机工程与应用,2008,44(17):135-137. [13] 金 一,阮秋琦.基于核的正交局部保持投影的人脸识别[J].电子与信息学报,2009,31(2):283-287. [14] YIN X C,HUANG K,YANG C,et al.Convex ensemble learning with sparsity and diversity[J].Information Fusion,2014,20:49-59.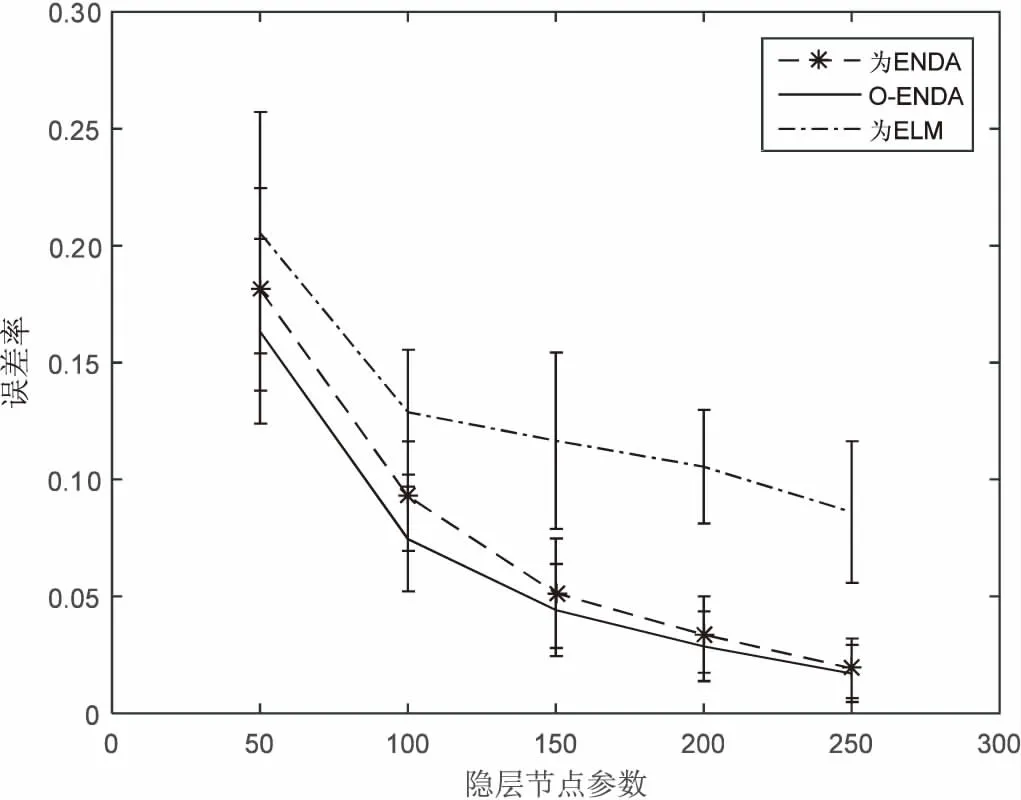
3.2 MNIST数据

3.3 CIFAR10数据
3.4 实验结果分析
4 结束语
