基于生物医学文献的化学物质致病关系抽取
2018-01-12李智恒桂颖溢杨志豪林鸿飞
李智恒 桂颖溢 杨志豪 林鸿飞 王 健
1(大连理工大学计算机科学与技术学院 辽宁大连 116024)
2(北京理工大学光电学院 北京 100081)
(zhihengli@mail.dlut.edu.cn)
当前,生物医学文献数目大幅度增长,但是大量生物医学知识仍然隐藏在文献中,例如PubMed摘要.与其他主题相比,全球的PubMed用户对化学物质、疾病以及二者之间关系的检索频率最高[1-2],这也反映出它们在生物医学研究和卫生保健领域的重要意义[3].因此,一些生物医学数据库,如CTD (comparative toxicogenomics database)[4],通过人工标注的方式,将非结构化文本中的化学物质-疾病关系(chemical-disease relation, CDR)标注成结构化知识,从而鉴定化学物质的潜在毒性.但是,由于人工标注CDR耗费大量时间和精力,并且很难满足生物医学文献迅速增长的需求[3],因此,自动地从生物医学文献中抽取CDR信息成为一个重要的研究领域.
此前,一些研究已涉足药物副作用关系抽取领域.Xu等人[5]提出一个知识驱动的模式学习方法,该方法与支持向量机(support vector machine, SVM)和基于共现方法相比,准确率和F值有显著提高,但是召回率有所下降.Kang等人[6]提出基于知识的药物副作用事件抽取系统,该系统与基于机器学习的方法相比,能够利用小规模训练集数据取得较好效果.Gurulingappa等人[7]提出一个基于SVM的统计关系抽取系统用于从医疗病例报告中识别潜在药物副作用事件.
2015年,BioCreative V组织一个从生物医学文献中自动抽取化学物质致病(chemical-induced disease, CID)关系的评测任务.该任务旨在支持新药发现和药物安全性检测[3,8].参加评测的系统以原始PubMed文章摘要作为系统输入,并被要求从摘要文本中抽取CID关系,返回关系排序列表,并为每一个抽取出的CID关系赋予置信分数.在评测任务中,UTH-CCB组[9]分别训练句子级别和文档级别的SVM分类器,并将其合并以便抽取CID关系.由Erasmus MC 组设计的RELigator系统[10]利用丰富的特征进行训练,包括含有先验知识的图形数据库、语言学和统计学特征.尽管有以上很多尝试,基于生物医学文献的CDR抽取仍然处于初级阶段,并且系统性能仍有很大提升空间.例如,在BioCreative V CDR任务中,性能最好的系统取得的F值为57.03%[9].
本文提出一个化学物质-疾病关系抽取系统——CDRExtractor,用于从生物医学文献中抽取CID关系.CDRExtractor包括句子级别SVM分类器(CS)和文档级别SVM分类器(CD).第1阶段,利用CS抽取句子中共现的化学物质和疾病之间的CID关系.首先,我们人工标注了句子级别的训练集.由于人工标注费时费力且效率很低,标注的训练语料有限,因此我们利用Co-training算法[11]扩展未标注语料,将特征核和图核[12]特征看作2个独立的视图进行训练.第2阶段,利用CD抽取不在同一句子中共现的化学物质和疾病之间的CID关系,即跨句子的CID关系.CD充分利用摘要中的化学物质和疾病特征,并返回文档级别CID关系.最后,我们利用规则将CS和CD的输出进行整合,得到最终输出结果.
1 任务及系统简介
CDR任务组织者发布了用于进行CID关系抽取的语料,其中包含1 500篇PubMed摘要(训练集、开发集、测试集各500篇),并标出4 409个化学物质、5 818个疾病和3 116个CID关系[8].如图1所示,标注者人工标出文中的实体,并用实体的医学主题词概念标识符(medical subject headings concept identifiers,MeSH®IDs)[3]进行标准化.CID关系均在文档级别标注,即并未指明关系所在的具体句子.图1中,第1个实例为句子中共现的CID关系,第2个实例为跨句子CID关系.
图2所示为CDRExtractor系统结构图.CDRExtractor包含句子级别SVM分类器(CS)和文档级别SVM分类器(CD).将特征核和图核特征看作2个独立的视图,利用Co-training算法训练CS;根据文档级别信息,利用特征核训练CD.最终通过规则将2个分类器的分类结果整合输出.

Fig. 1 Samples from the CDR corpus图1 CDR语料中的实例

Fig. 2 Architecture of the CDRExtractor system图2 CDRExtractor系统结构图
2 句子级别关系抽取
2.1 语料预处理
本文利用BioCreative V CDR任务提供的训练集和开发集(各500篇PubMed摘要)训练句子级别SVM分类器CS.由于语料集是在文档级别进行标注的,标注出的CID关系具体来自哪个句子是未知的,因此需要构造句子级别的语料集.
首先对文本进行预处理:1)用实体的MeSH®ID代替文中实体名称;2)过滤少于2种实体的句子.之后,我们抽取所有包含化学物质-疾病(chemical-disease)实体对的句子并人工标注是否含有CID关系——句子中明确指出化学物质和疾病之间含有CID关系的实例被标注为正例,其他实例均为负例.表1为本文中标注的训练集和开发集中句子级别实例数.

Table 1 The Statistics of the Labeled Datasets at Sentence Level
本文对标注的一致性进行评估,每位标注者之间的Cohen’s kappa[13]分值为0.806,内容分析的研究人员普遍认为,Cohen’s kappa的得分超过0.8即为可靠性好[13].
2.2 句子级别分类器
对于句子中共现的chemical-disease实体对,本文利用2个基于核的方法训练句子级别的SVM分类器进行分类.一个核可以被看作是对象的近似函数[14].不同的核从不同的角度计算2个句子的相似度.我们结合特征核和图核2种核分别从语义特征和句法特征2个角度对句子级别的CID关系进行抽取,利用Co-training方法引入大量未标注语料扩充训练集从而使分类器主动学习特征,进一步抽取句子级别的CID关系,提升系统性能.
2.3 特征核
下列特征被用于特征核的训练:
1) 词特征.利用chemical-disease实体对之间及前后各M个词作为特征计算相似度.本文系统中,M=4.
2)N元词特征.二元和三元词.
3) 实体距离特征.实体之间的距离在一定程度上影响2个实体之间的关系.因此,实体间的距离也被看作一个特征[14].例如:若chemical-disease实体对间的距离小于3,则该特征被标记为“DISLess-ThanThree”.
4) 关键词特征.某些词,如“induced”,若出现在chemical-disease实体对附近,则句子中很可能存在CID关系.为识别类似关键词,我们建立了1个包括动词和短语在内共200个词条的关键词表.除关键词本身外,句子中是否存在关键词也被看作1个二值特征.
5) 基于知识的特征.本文抽取了CTD数据库[4]中未被标为“therapeutic”的所有chemical-disease关系对.CTD是一个健壮的、公开数据库,提供了人工标注的化学物质-基因/蛋白质关系、化学物质-疾病关系和基因-疾病关系.chemical-disease实体对是否存在于CTD中也被看作一个特征,因为大部分CID关系存在于CTD中.
2.4 图 核
图核方法中,用语法树表示句子的图形结构,通过比较图中的公共节点来计算2个图之间的相似度.本文利用含有2个非联通子图的全路径图核,分别表示句子的依存结构和词语的线性序列[12],如图3所示.本文采取简单权重模式,所有最短路径上的边的权重均为0.9,其他边权重为0.3;第2个子图上的每条边的权重均为0.9.

Fig. 3 Graph kernel representation图3 句子的图核
表示2个输入图的相似度通过矩阵G来计算:
(1)
其中,A是边的矩阵,Ai j表示连接节点Vi和Vj的边的权重;L为标签矩阵,Li j=1表示节点Vj包含标签i.对于输入图矩阵G和G′,图核K(G,G′)定义为
(2)
2.5 Co-training算法
人工构建大规模语料费时费力.然而,有限的标注语料很难使分类器获得令人满意的泛化能力.因此,本文引入半监督学习方法——Co-training算法[11],扩充大量未标注语料来提升分类器性能.
我们从PubMed网站*http://www.ncbi.nlm.nih.gov/pubmed/检索“chemical-induced disease”,得到3 000篇MedLine摘要作为未标注语料.之后利用PubTator[15]工具(网页工具,利用已有文本挖掘技术进行命名实体识别和关系抽取)对这些摘要中的化学物质和疾病实体进行识别和标准化.经过预处理,共得到7 868个未标注句子.
Co-training算法如下:1)我们利用少量标注训练集分别训练基于特征核和图核的分类器;2)利用2个分类器分别标注一定数量的未标注实例,其中被2个分类器标注一致的实例会被加入训练集中形成下一次迭代的训练集.
算法1. Co-training算法.
输入:标注训练集D、未标注数据集U;初始化训练集Df,Dg(Df=Dg=D);充足冗余的视图Vf,Vg;迭代次数I;
输出:特征核分类器hf和图核分类器hg.
步骤:
① 从U中随机选择实例形成未标注集合u,U=U-u;
② 在视图Vf中利用Df训练分类器hf;在视图Vg中利用Dg训练分类器hg;
③ 利用hf,hg标注u中的实例;
④ 选择标注一致的p个正例和q个负例加入训练集,从U中选择相同数量的实例代替加入训练集的实例,补充到u中;
⑤ 循环: 步骤②~④ 直到未标注语料U=∅或者u中的实例数少于某特定值,或者I=0;
⑥ 输出分类器hf,hg.
由于不同的分类器计算2个句子相似度的角度不同,结合2个分类器的相似度有助于减少重要特征的丢失[16],提高整体性能.文中分别给予特征核和图核分类器的权重为0.7和0.3,用于整合2个分类器对同一实例给出的分值.
2.6 文档级别结果整合
本文利用2条规则将句子级别的结果整合到文档级别:
1) 若提取的CID关系来自文章题目,置信分值加0.3分.因为题目是文章的核心,其中的CID关系更为重要.
2) 若1篇文章中提取的某一CID关系超过1次,那么该CID关系的分值将相应提升.因为多次提取出来的CID关系比其他关系更重要.
CID关系的置信分值score_f的计算为

(3)
其中,score_h表示CID关系获得的最高分值;f,fC,fD分别表示抽取的CID关系、化学物质和疾病频率.上述参数的取值均为实验获得.
最终,利用阈值对CID关系进行过滤,得到文档级别输出.
3 文档级别关系抽取
本文利用文档级别分类器CD对跨句子的CID关系进行抽取.CD分类器在训练集和开发集上用特征核进行训练,其特征包括:
1) 实体特征.化学物质和疾病实体出现的频次和先后顺序,是否为第1次或最后一次出现,其间是否有其他实体.上述特征很有可能与文章主题相关,而文档级别的关系很大程度上与文章的主题相关.
2) 词特征.chemical-disease实体之间的一元、二元词以及其前后M个词.在本文系统中,M=5.
3) 知识特征.chemical-disease实体对是否在CTD中.
CD利用上述特征对文档级别CID关系进行抽取,抽取出的结果与CS的结果进行合并,之后利用如下规则进一步处理,以提高系统性能:
1) 若一篇摘要中抽取的CID关系数目超过4个,则过滤掉既不出现在题目中,分值又低于0.7的关系.因为一篇文章通常集中讨论的CID 关系有限,出现在题目中的化学物质或疾病是文章的主题.若返回的关系中的实体均不出现在题目中,则全部保留.
2) 对于无结果返回的文章,包含题目中出现过的化学物质的chemical-disease实体对作为返回关系输出.
3) 用CTD数据库过滤.经过人工标注CTD数据库中的CID关系可以认为是可靠的关系,因此可以提高系统的准确率.
4 结果与讨论
BioCreative V CDR评测任务提供的训练集、开发集和测试集各包含PubMed文摘500篇,其中的CID关系数分别为1038,1012,1066.本文在训练集和开发集上训练分类模型,利用测试集进行测试.
4.1 句子级别抽取结果
首先利用Co-training算法训练模型抽取句子级别CID关系,每个模型的性能如表2所示,Co-training之后,模型的召回率明显提高,但是准确率相应下降.因为Co-training过程加入模型标注的实例,在添加更多信息的同时也加入一些噪音,影响准确率.然而,召回率提升明显高于对准确率的影响,因此,F值有所提升.当迭代次数过多时,引入过多噪音,导致F值下降.事实上,半监督学习方法并不稳定,因为在学习过程中未标注实例经常被错误标注[17].特征核和图核模型的F值在迭代次数为1和4的时候达到峰值.
经过合并之后,2个模型共同作用结果F值达到58.89%,明显高于任何一个模型.这说明特征核和图核从不同角度计算2个句子的相似度,并有所互补.
另外,句子级别结果映射到文档级别需要根据式(3)计算分值,之后通过阈值进行过滤.图4(a)为准确率(P)、召回率(R)和F值随阈值增加的变化情况,阈值越大,准确率越高、召回率越低.当阈值取0.1时,F值达到峰值58.89%.图4(b)展示了CD分类器性能随阈值变化情况,阈值取-0.4时F值达到峰值66.48%.

Table 2 Results at Sentence Level表2 句子级别结果

Fig. 4 Relationship between performance and thresholds of CS and CD图4 CS和CD性能随阈值变化情况
4.2 文档级别抽取结果
表3展示了不同的CID关系抽取系统在测试集上的性能.基于实体共现方法在句子级别和文档级别的F值分别为34.46%和27.05%[3].RELigator系统利用先验知识、语言学和统计学信息,获得52.56%的F值[10],在评测的18组(46组结果)中排名第2.该系统利用自己的工具识别疾病实体(性能未知),利用评测机构提供的工具tmChem[18](F值为92%)识别化学物质.
评测中,UTH-CCB组系统结合2个SVM分类器,F值达到57.03%[9],位列第1.随后,UTH-CCB组提出系统CD-REST[19],其性能如表3所示,在标准实体标注的情况下,F值达到67.16%.CD-REST融合大量生物医学知识(MeSH,MEDI[20],SIDER[21],CTD)作为特征,对性能的提升作出很大贡献,未利用生物医学资源的情况下准确率、召回率和F值分别下降到59.60%,44%,50.73%(准确率、召回率和F值分别下降6.2%,24.57%,16.43%).另外,利用识别工具对实体进行识别之后,F值降低约9%(化学物质和疾病识别的F值分别为90.72%和84.43%).这说明实体识别的准确性对关系抽取性能影响很大.
在标准实体标注情况下,首先,CDRExtractor利用Co-training方法,从大量未标注语料中学习有用信息,大幅度减少人为的特征设计,F值达到58.89%;之后利用文档级别分类器,抽取跨句子的CID关系,大幅度提升系统性能(召回率和F值分别提升14.91%和7.59%,而准确率仅降低1.59%);最后利用规则对得到的抽取结果进行整合,召回率又提升9.10%,F值达到67.72%,这说明后处理规则具有一定效果.另外,我们利用CD-REST的命名实体识别工具对测试集中实体进行识别并测试了CDRExtractor的性能,其结果如表3所示.利用工具识别后的抽取结果,F值比标准实体标注下的F值降低8.57%,再次说明,实体识别的性能对关系抽取性能影响很大.
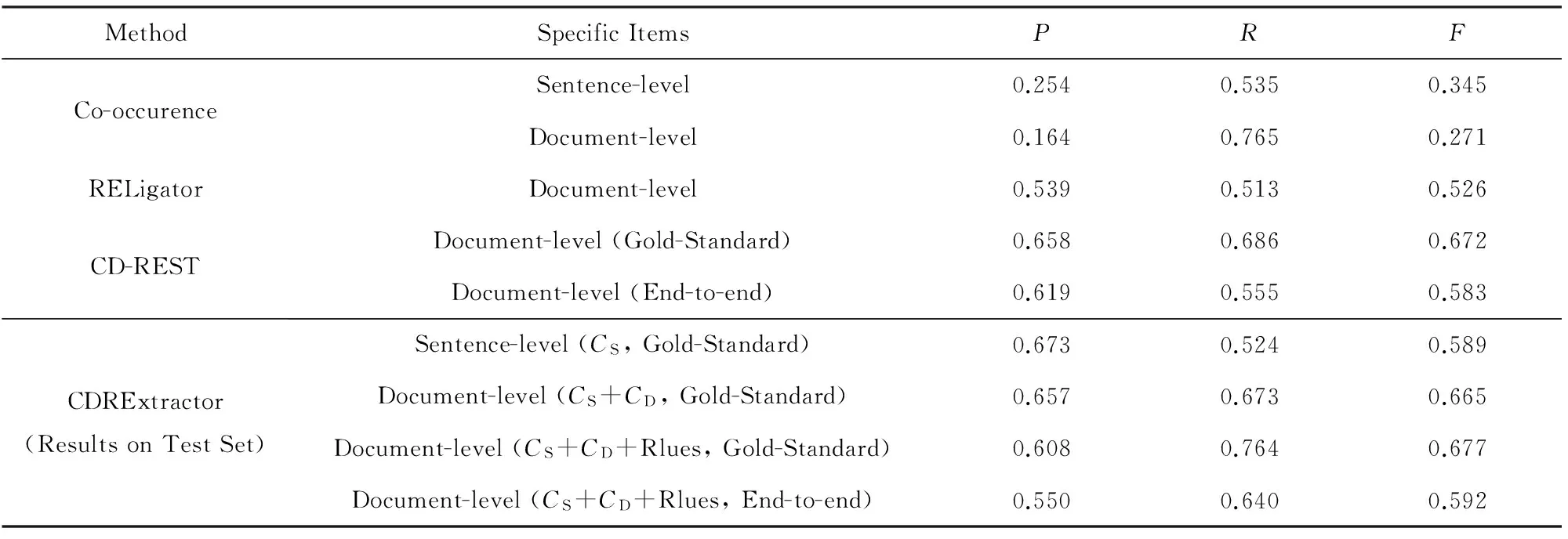
Table 3 Relation Extraction Performance for Different Systems表3 不同系统的关系抽取性能
与CD-REST相比,CDRExtractor是利用Co-training方法,使系统从语义特征和语法特征2个角度主动学习到未标注语料中的特征,并利用CD与CS互补抽取跨句子的CID关系,从而大幅度提升分类器的召回率;而CD-REST则是利用大量已有知识,人为地设计特征用于分类(CD-REST系统共利用11种知识特征、12种实体和上下文特征信息),其中包括MeSH,MEDI,SIDER,CTD数据库.相比之下,CDRExtractor只应用CTD数据库信息,仍然达到更好的性能.
5 错误分析
5.1 准确率错误分析
从生物医学文献中抽取CID关系是一个新颖的任务,其性能仍有待提高.表4为CDRExtractor系统在测试集的100篇文章中的准确率错误类型分析.
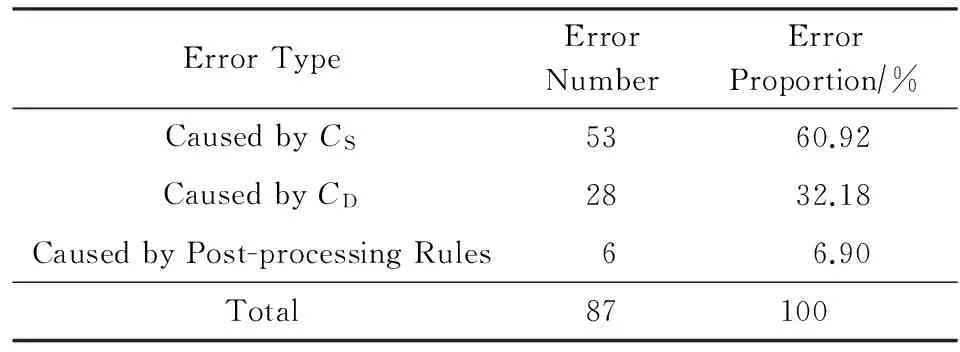
Table 4 Analysis of the System Precision Error Types表4 系统准确率错误类型分析
表4显示,超过半数的准确率错误来自CS,自然语言表达的复杂性是此类错误的主要原因.例如:句子“CONCLUSION: C_D019808 reduces the rate of progression of C_D004317-induced D_D005923 to D_D007676 in SHR”中,系统错误地认为“C_D004317”和“D_D007676”之间存在CID关系.
另外,32.18%的错误来自CD,主要原因(22/28)是系统调低了CD的阈值以得到更高的召回率,从而导致了假阳性实例的增加.另外6.90%的错误来源于规则中对未返回结果的文档进行的处理.事实上,这些规则很难定义,因为它对准确率和召回率的影响是相反的.
5.2 召回率错误分析
表5为DRExtractor系统在测试集的100篇文章中的召回率错误类型分析.

Table 5 Analysis of the System Recall Error Types表5 系统召回率错误类型分析
大部分未被返回的CID关系存在于跨句子关系中.由于跨句子实体对之间的自然语言表达情况过于复杂,选取有效的特征成为难题.因此CD未返回的关系成为召回率错误的主要原因(61.25%).对于句子中共现的实体对,召回率错误的主要原因仍然是自然语言表达太过复杂.例如句子中包含过多的实体、修饰成分和从句等.这部分原因(38.75%)导致CS无法判断实体之间是否存在关系.
另外,正如之前提到的,实体识别和标准化过程也会影响CID关系抽取的最终性能.例如CD-REST系统的实体识别工具(化学物质和疾病识别的F值分别为90.72%和84.43%)进行标注的情况下与标准实体情况下相比,系统F值降低8.83%;本文系统CDRExtractor利用CD-REST系统工具进行实体识别的情况下与标准实体情况下相比,F值降低8.57%.
6 结 论
从生物医学文献中自动抽取CID关系可以利用到新药发现和药物安全性检测中[3,8].本文提出一个CID关系抽取系统——CDRExtractor,能够从句子和文档级别抽取CID关系,并经过后处理规则将2部分结果融合,形成最终输出.
句子级别分类器的训练阶段,经过人工标注得到训练集.然而,人工标注的CID关系费时费力且无法满足大量增长的文献数目的需求[3],因此我们利用Co-Training算法将特征核和图核特征相结合,引入大量未标注语料对训练集进行扩充,减少人为的知识特征设计工作.之后CDRExtractor利用文档级别分类器抽取跨句子的CID关系,从而显著提高系统召回率.最后,利用后处理规则形成最终文档级别的CID关系,过滤不可靠关系,得到更好性能.
另外,我们发现CTD数据库等先验知识能够使抽取结果更加准确.从文章主旨的角度来看,题目中的实体更为重要.对CDRExtractor的准确率和召回率错误分析中可知,自然语言表达的复杂性是造成准确率错误的主要原因,而CD未能抽取的跨句子CID关系是召回率错误产生的原因.
现阶段,从生物医学文献中自动抽取CDR仍然有很大的提升空间.在未来的工作中,句子级别的CID关系抽取性能需要进一步提高,因为从句子中抽取的CID 关系更为准确.另一方面,对于跨句子的关系,需要设计更为有效的文档级别特征.另外,指代消解方法可能会对跨句子的关系识别有所助益.
[3] Wei Chih-Hsuan, Peng Yifan, Leaman R, et al. Overview of the BioCreative V chemical disease relation (CDR) task[C/OL] //Proc of the 5th BioCreative Challenge Evaluation Workshop. 2015: 154-166[2015-12-30]. http://www.biocreative.org/media/store/files/2015/BC5CDR_overview.final.pdf
[4] Davis A P, Grondin C J, Lennon-Hopkins K, et al. The comparative toxicogenomics database’s 10th year anniversary: Update 2015[J]. Nucleic Acids Research, 2015, 43(D1): D914-D920
[5] Xu Rong, Wang Quanqiu. Automatic construction of a large-scale and accurate drug-side-effect association knowledge base from biomedical literature[J]. Journal of Biomedical Informatics, 2014, 51: 191-199
[6] Kang Ning, Singh B, Bui C, et al. Knowledge-based extraction of adverse drug events from biomedical text[J]. BMC Bioinformatics, 2014, 15(1): 64
[7] Gurulingappa H, Mateen-Rajpu A, Toldo L. Extraction of potential adverse drug events from medical case reports[J]. Journal of Biomedical Semantics, 2012, 3(1): 15
[8] Li Jiao, Sun Yueping, Johnson R, et al. Annotating chemicals, diseases, and their interactions in biomedical literature[C/OL] //Proc of the 5th BioCreative Challenge Evaluation Workshop. 2015: 173-182 [2015-12-30]. http://www.biocreative.org/media/store/files/2015/BC5CDRcorpus.pdf
[9] Xu Jun, Wu Yonghui, Zhang Yaoyun, et al. UTH-CCB@ BioCreative V CDR task: Identifying chemical-induced disease relations in biomedical text[C/OL] //Proc of the 5th BioCreative Challenge Evaluation Workshop. 2015: 254-259[2015-12-30]. http://www.biocreative.org/media/store/files/2015/BCV2015_paper_38n.pdf
[10] Pons E, Becker B, Akhondi S A, et al. RELigator: Chemical-disease relation extraction using prior knowledge and textual information[C/OL] //Proc of the 5th BioCreative Challenge Evaluation Workshop. 2015: 247-253[2015-12-30]. http://www.biocreative.org/media/store/files/2015/BCV2015_paper_37.pdf
[11] Wang Wei, Zhou Zhihua. Analyzing co-training style algorithms[C] //Proc of the European Conf on Machine Learning. Berlin: Springer, 2007: 454-465
[12] Airola A, Pyysalo S, Björne J, et al. All-paths graph kernel for protein-protein interaction extraction with evaluation of cross-corpus learning[J]. BMC Bioinformatics, 2008, 9(11): S2
[13] Carletta J. Assessing agreement on classification tasks: The kappa statistic[J]. Computational Linguistics, 1996, 22(2): 249-254
[14] Cristianini N, Shawe-Taylor J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods[M]. Cambridge, UK: Cambridge University Press, 2000
[15] Wei Chih-Hsuan, Kao Hung-Yu, Lu Zhiyong. PubTator: A Web-based text mining tool for assisting biocuration.[J]. Nucleic Acids Research, 2013, 41 (W1): W518-W522
[16] Yang Zhihao, Zhao Zhehuan, Li Yanpeng, et al. PPIExtractor: A protein interaction extraction and visualization system for biomedical literature[J]. IEEE Trans on Nanobioscience, 2013, 12(3): 173-181
[17] Zhou Zhihua, Li Ming. Tri-training: Exploiting unlabeled data using three classifiers[J]. IEEE Trans on Knowledge and Data Engineering, 2005, 17(11): 1529-1541
[18] Leaman R, Wei Chih-Hsuan, Lu Zhiyong. tmChem: A high performance approach for chemical named entity recognition and normalization[J]. Journal of Cheminformatics, 2015, 7(1): S3
[19] Xu Jun, Wu Yonghui, Zhang Yaoyun, et al. CD-REST: A system for extracting chemical-induced disease relation in literature[J/OL]. Database, 2016[2016-04-13].https://academic.oup.com/database/article/doi/10.1093/database/baw036/2630291/CD-REST-a-system-for-extracting-chemical-induced
[20] Wei Weiqi, Cronin R M, Xu Hua, et al. Development and evaluation of an ensemble resource linking medications to their indications[J]. Journal of the American Medical Informatics Association, 2013, 20(5): 954-961
[21] Kuhn M, Campillos M, Letunic I, et al. A side effect resource to capture phenotypic effects of drugs[J]. Molecular Systems Biology, 2010, 6(1): 343
