海量病案信息的快速关联查阅算法设计与实现
2018-01-10陈皇宇陈海云
陈皇宇, 陈海云
(南京军区南京总医院,南京 210000)
海量病案信息的快速关联查阅算法设计与实现
陈皇宇, 陈海云
(南京军区南京总医院,南京 210000)
为了解决传统关联规则查阅算法,在挖掘海量病案数据过程中,存在滞后以及偏差高的缺陷,结合海量病案数据多维多层次属性,设计一种基于病案多维数据立方体的快速管理查阅算法。采用多维多层次的挖掘结构对病案数据采用关联规则,设计了OLAP的关联规则挖掘模型,解决了基于OLAP关联规则挖掘模型需要频繁扫描数据集的弊端。对挖掘获取的关联规则实施汇总和研究,得到隐藏在病案数据中病人的职业、年龄与疾病间的联系。依据基于OLAP关联规则挖掘模型获取了病案数据集。实验结果说明,所设计算法面向海量病案数据,具有较高的查阅性能,能够提高患者就诊的满意度。
海量病案; 信息快递; 关联规则; 挖掘算法
0 引言
当前由于数据库技术以及信息技术的高速发展,医院信息系统在医院中的应用价值不断提升。并且医院信息系统中的病案数据呈现爆炸式增长,采用有效方法从海量病案信息中,快速查阅出有价值数据,成为相关人员研究的重点[1]。而传统关联规则查阅算法,挖掘海量病案数据过程中,存在的滞后性以及偏差高的缺陷。面向该种问题,文章设计并实现了基于病案多维数据立方体的快速管理查阅算法,增强病案信息查阅的效率和精度。
1 基于病案多维数据立方体的查阅算法设计
2.1 海量病案数据挖掘流程设计
数据挖掘即从大量数据中通过一定的算法,提取信息的过程,而数据挖掘模块包括数据预处理、数据挖掘分析以及知识分析两个过程。具体数据挖掘流程如图1所示。
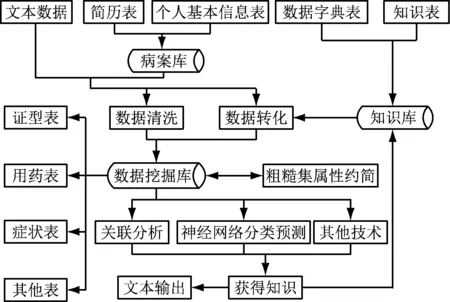
图1 数据挖掘模块流程图
(1) 数据预处理
数据预处理时,在数据库中采集数据,用数据预处理的方法对病案信息进行汇总分析以及量化分割等操作,获取有价值数据。操作如下:把选好的数据用“数据清洗”的方法,做删除缺省值和错误等处理[2];通过“数据转化”,即把医学表述的数据参照知识库中的数据字典表用SQL语句转成机器学习上能处理的数据。并且,系统可以把数据从横向转化成纵向,在数据挖掘库里保存转化后的数据,方便今后的研究使用。还有另一种数据预处理的方式,它是用粗糙集属性约简的方法,约简数据的属性:约简后的属性通过MIBARK算法被分割出来,放到数据挖掘库里。
(2) 数据挖掘和知识分析
数据挖掘知识时,筛选待挖掘知识的类别,对于进行过标准操作的,症状数据集、证型数据集、中药数据集,依次采用基于病案多维数据立方体的数据挖掘算法,挖掘出关联分析知识以及神经网络分类预测知识。关联分析知识挖掘时,通过系统封装的算法文件,从已有的支持度阀值、置信度阀值参数中得到可用的关联规则[3]。关联结果呈现出的顺序列表为“前件⟹后件支持度 置信度”。
塑造出基于OLAP的关联规则挖掘模型,预测被选择测试的样本将识别率以及识别结果输出。知识分析过程时,融合得到的挖掘知识和知识库中的知识,获取医药方剂配伍规律、症状与用药之间的联系和症状-证型的辩证辨别规律。
1.2 病案多维数据立方体的体系结构设计
塑造病案数据仓库可从医院信息系统中海量历史病案数据内获取有用信息,多维数据是分析数据仓库的基本数据单位,文章采用SQLServer2005中的Mic:osoftAnalysisServer塑造病案数据分析的维度以及多维数据集。Microsoft Analysis Server体系结构图,如图2所示。
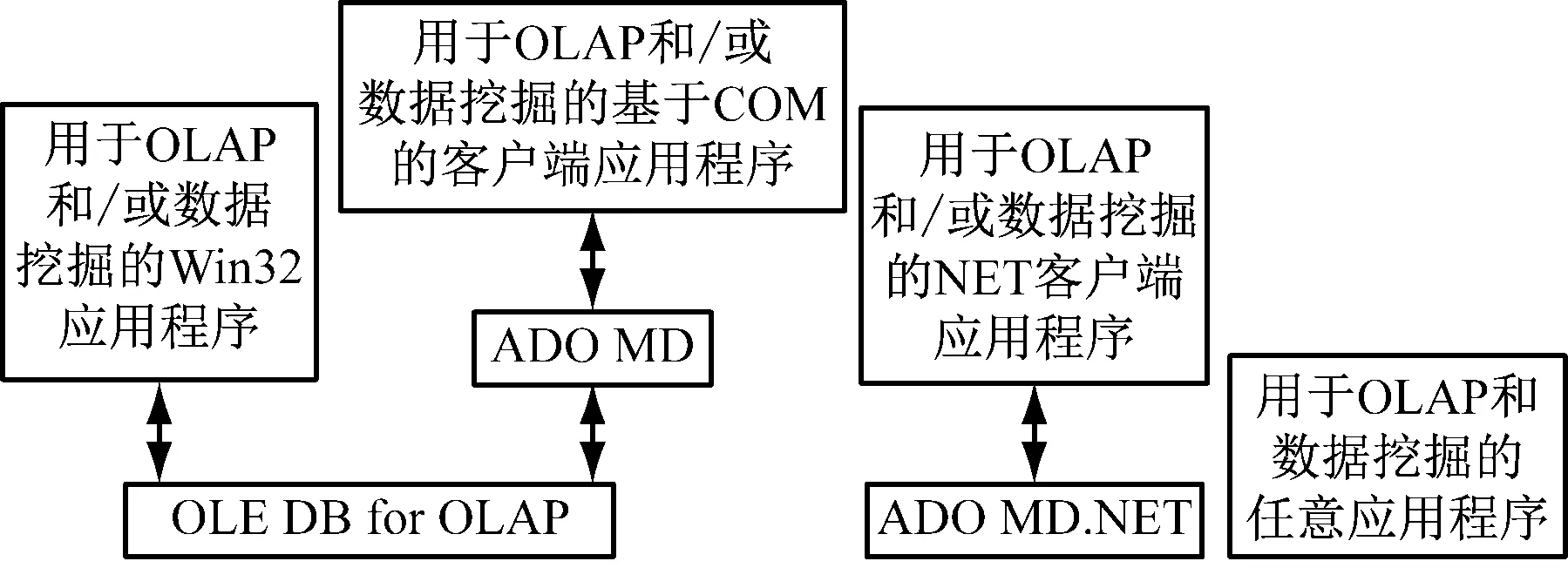

图2 Microsoft Analysis Server体系结构图
Microsoft Analysis Server系统是用于OLAP的中间层服务器,其由服务端以及客户端构成。服务端组件可对多维数据结构实施塑造以及维护,同时产生多维数据,为客户端检索提供服务。其能够对OLAP数据实施素质和控制,通过透视表(PivotTable)向客户端提供数据支撑的性能,需要从详细的依据关系型数据库的数据仓库内塑造多维数据立方体,并将其保存到多维立方体结构以及关系数据库中。关系数据库内的存储单元内保存着多维立方体结构。透视表服务是客户端的重点内容,其是应用程序访问Microsoft Analysis Server的接口,Microsoft Excel以及其它应用程序采用该接口获取服务器中的数据,并向用户程序反馈相关结果。基于透视表服务还能够塑造本地多维数据集[4],该服务可同Analysis Server连接,向用户以及客户端应用程序创造相关的接口,从服务端采集OLAP数据。Analysis Server具有较强的OLAP环境,其具有的功能是:塑造完多维层次结构后,向多维立方体中融入病案数据仓库内的数据,塑造同病案数据仓库数据源BA-DW的数据连接,基于多维层次模型塑造数据源视图,病案数据仓库内的病案事实表、病人信息表以及疾病诊断表导入对应的表格信息。不同的维表基于自身的ID号同病案事实表,塑造一定的关联性,将相关度量信息以及维表中的关键字信息存储到病案事实表中,可塑造病案多维数据集结构。数据仓库数据不断调整过程中,病案多维数据集无法对病案数据仓库的数据波动状态进行及时反应,病案数据仓库实施数据修正以及刷新后,应对多维立方体数据实施再次修正和操作。
上述塑造的病案多维数据立方体,可从不同维度以及层次对病案数据实施汇总研究,文章为了实现海量病案信息的快速并联查阅,基于病案多维数据立方体,将关联规则挖掘应用到病案数据分析,设计并实现多维多层次的关联规则挖掘模型。
1.3 基于OLAP的关联规则设计
在数据仓库中,很多的数据是在数据仓库和OLAP技术研究提高的基础上,通过整合以及预处理的。用户的需求是从数据库中筛选出各类有关联的数据,研究各种各样的细节层次,用不同方式显示知识。OLAP挖掘是能应用在不同数据集、不同的细节上的挖掘[5],因此能实施切片、切块、展开、过滤等操作。结合部分可视化的工具,数据挖掘的灵敏度以及性能得到了突飞猛进的进步。下面,对多层和多维关联规则进行阐释。
(1) 多层关联规则
因为数据分布的分散性,大多数的应用在数据最细节的层次上不容易察觉出部分强关联规则。若在高层次上实施挖掘,可导入概念层次[6]。高层次上获取的规则信息价值度较低,无法满足用户的兴趣要求。数据挖掘应有这样在多个层次上实施挖掘的性能。“支持度-可信度”的构造同样适用于多层关联规则的挖掘。
(2) 多维关联规则
上述为同字段的值间的关联的探究,例如病人所患有的疾病间的关联。单维或多维的关联规则即为多维数据库的语言,它们挖掘于交易数据库。而多维数据库中,还有一类多维的关联规则。如:
年龄(X,“40—50”)and性别(X,“女”)患有(X,“营养性贫血”)
其中提到三个维年龄、性别以及疾病的资料。若不允许维重复出现,则为维间的关联规则,若允许维在规则的左右同时出现,则为混合维关联规则,则有:
年龄(X,“40—50”)and患有(X,“营养性贫血”)⟹患有(X,“溶血性贫血”)
多维关联规则是一种混合维关联规则,对这类规则实施挖掘时应分析不同字段是连续型还是离散型。
1.3.1 病案数据关联规则挖掘模型设计
从关联规则算法的分析中得知,必须提前产生大规模的候选集和频繁的对事务数据库做扫描,是实施关联规则挖掘的阻碍,要想明显的减少频繁项集形成时间以及减少对事务数据库的扫描次数,就要把OLAP立方体中的大量聚集数据运用起来。以下通过根据病人主题域的病案多维数据立方体设计关联规则挖掘模型。
(1) 病案数据挖掘对象分析及算法选择
病人主题域的多维数据集包括病人的基本情况以及疾病分类信息等几个维度。事务表信息依据病人的基本信息塑造,病人住院时的疾病诊断都在其中,可用来研究疾病间的关系以及相应的约束程度。病人情况等维作为输入信息,建立数据挖掘模型,进而对病人的基本信息(年龄、性别、职业、出生地等)对患得疾病的干扰实施研究。依据对关联规则算法的研究得出,对事务型数据实施单层单维的布尔型关联规则挖掘可用Apriori算法,该种算法在多维多层的病案数据挖掘中使用较少[7]。文章实施病案数据挖掘所用的方法是MICrosoft关联规则算法,这种算法在对关系数据库实施关联规则挖掘时起到了重要作用。它能通过OLAP多维数据集实施多维多层次的关联规则挖掘,有效运用病案多维数据立方体中的聚集型数据,以达到快速搜索频繁项集的目的。其挖掘频繁项集时[8],为了加快频繁项集的生成效率,可依据MDX语句对病案多维数据立方体内的聚集信息实施检索,进而获取频繁项集;关联规则的阀值是在频繁项集形成的相关规则基础上,设置最小支持度(Minimum_Support)、最小置信度(Minimum_Probability)和最小兴趣度(Minimum_Importance)而形成,有灵活和准确的优点。
(2) 病案数据挖掘模型设计
关联规则挖掘的事例表能够看成是疾病诊断维表,该表的输入列为入院日期维、病人信息维和出生地维维度的信息,通过构建的OLAP病案多维数据立方体的聚集信息,实施多维多层次的关联规则挖掘。基于病人主题域的挖掘结构,塑造病人主题域的挖掘模型[9-11],如图3所示。
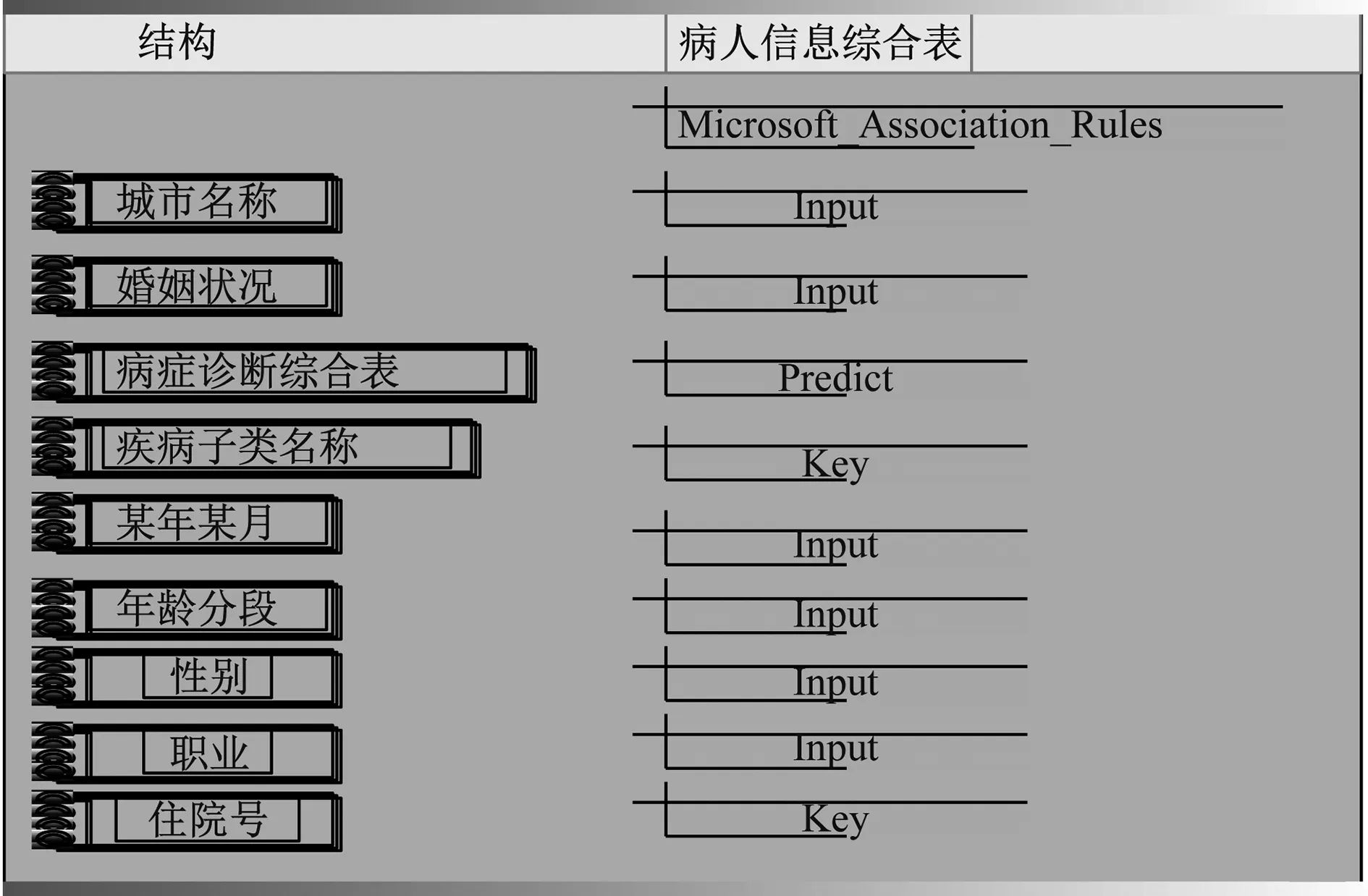
图3 病人主题域的挖掘模型图
其可能够研究病人的性别、年龄和职业等信息特点以及所患疾病,目的是研究疾病间的关系和病人的情况特点是否对疾病关系起作用[12]。
1.3.2 基于关联规则Apriori的数据挖掘算法设计
文章采用基于云计算的MapReduce模式的快速管理规则Apriori数据挖掘算法,解决基于OLAP关联规则挖掘模型需要频繁扫描病案多维数据立方体的弊端,进一步提高海量病案信息查阅的效率。
通常采用关联规则的Apriori算法挖掘海量病案数据,该算法通过逐层建设迭代受到基于K项集实施(K+1)项集的查询,对基于OLAP关联规则挖掘模型获取的病案数据集实施检索后[13],产生频繁1-项集L1,基于L1实施获取频繁项集L2,通过持续迭代受到直到频繁项集是空集。频繁项集中的任意一个子集都是频繁项集,可降低检索区域,提高频繁项集产生效率。通过K次信号检索后,海量病案数据的挖掘过程是:(1)对JOIN(连接)指令实施处理,要求Lk-1形成候选集Ck,同时实施连接处理;(2)基于Apriori性质实施支持度汇总以及剪枝处理,要求Ck形成频繁集Lk。但是该种算法对数据库实施大量检索操作,最终得到全部频繁项集,挖掘海量病案数据过程中,存在挖掘效率低以及耗能高的缺陷。因此,文章基于云计算平台的分布式运算属性,塑造Hadoop架构保存检索数据库,获取频繁项集得到的关联规则,检索处理将不同DataNode节点(病案多维数据立方体)内实施并行处理[14],得到不同运算节点中的局部频繁项集。最终通过Master获取真实的全局支持度、频繁项集汇总结果,降低挖掘时间以及能耗,极大提高了病案数据的挖掘效率。
上述描述的Apriori算法Map/Reduce化的详细过程如图4所示。
2 实验分析
实验对某医院2009—2013年期间的病案信息实施查阅检测,检测本文设计并实现的海量病案信息快速关联查阅算法的性能。
2.1 试验关联参数的设计
本文数据挖掘算法融合先验知识,采用合理的参数阀值,获取有价值的规则,主要有:
(1) 病人的职业与各类疾病之间的相互联系
患者职业同疾病间存在一定的关联性,对这些关联性实施分析,为医生实施诊断提供依据,如表1、表2所示。

图4 Map/Reduce化的Apriori挖掘算法的实现流程

置信度兴趣度规则前项规则后项0.6130.52精神以及行为障碍,呼吸系统疾病循环系统疾病0.7240.58精神以及行为障碍,内分泌,营养以及代谢疾病循环系统疾病0.6170.52精神以及行为障碍,神经系统疾病循环系统疾病0.6070.52泌尿生殖系统疾病,呼吸系统疾病循环系统疾病0.6570.54内分泌、营养以及代谢疾病,呼吸系统疾病循环系统疾病0.6870.57神经系统疾病,泌尿生殖系统疾病循环系统疾病0.640.55神经系统疾病,内分泌、营养以及代谢疾病循环系统疾病0.5860.51血液及造血器官疾病,泌尿生殖系统疾病循环系统疾病

表2 肾小球疾病患者同职业间的关联
分析表1能够看出,患有肾小球疾病的患者,受到职业的影响,其患有肾衰竭疾病的概率存在一定的差异,具体情况用表2描述,从中能够看出肾衰竭疾病同患者工作强度具有较高的关联性,劳累对肾衰竭疾病具有不利干扰。
(2) 病人年龄与各类疾病之间的相互联系
病人年龄同疾病存在一定的关联性,如表3所示。
分析表3可以看出肾衰竭病人同时患有高血压病的概率大小同年龄相关,患有肾衰疾病的老年人容易出现高血压病。

表3 肾衰竭疾病同患者年龄间的关联
2.2 原数据集大小变化时的性能
如果向实验病案信息中融入新的数据集d大小是0.2G,支持度是20%,则原病案信息发生变化时,本文算法和传统关联规则算法的查阅结果,如图5所示。
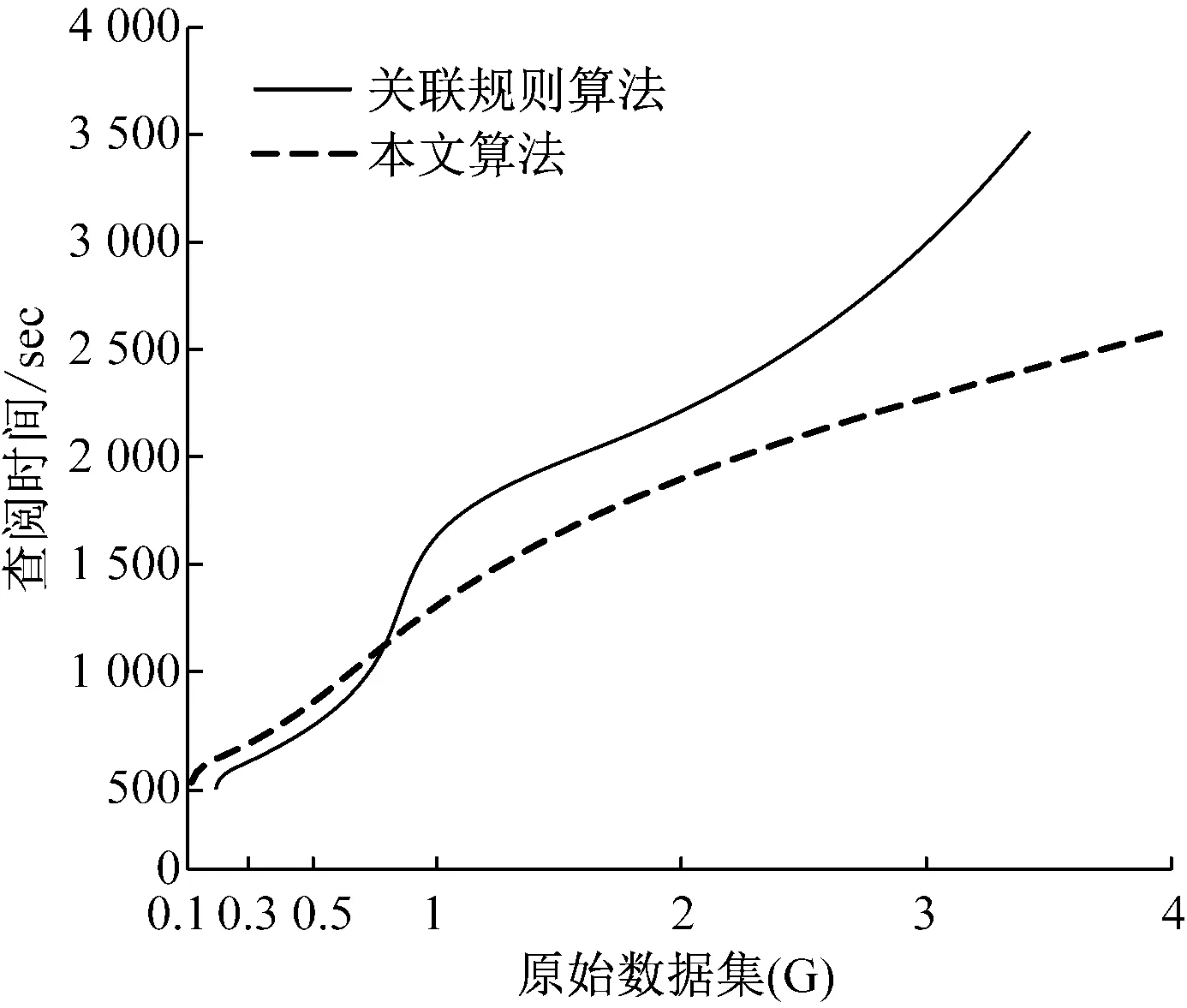
图5 原数据集波动情况下的查阅性能
分析图5可得,相同软硬件配置状态时,如果原病案信息量较低,两种算法的查阅性能基本一致,随着原病案信息量的不断提升,传统关联规则算法的性能显著降低,当病案信息量是4G时,传统关联规则算法不能完成病案信息的查阅,主要是因为此时其对内容调用失败。但是本文算法的性能随着原病案信息的提高而持续提升,其面向海量病案信息时,具有较强的查阅优势。
2.3 新增数据集大小变化时的性能
若原病案数据集D的容量是1G以及2G,支持度是20%,则当新增数据集容量不断变换时,不同算法的差异性能,如图6所示。
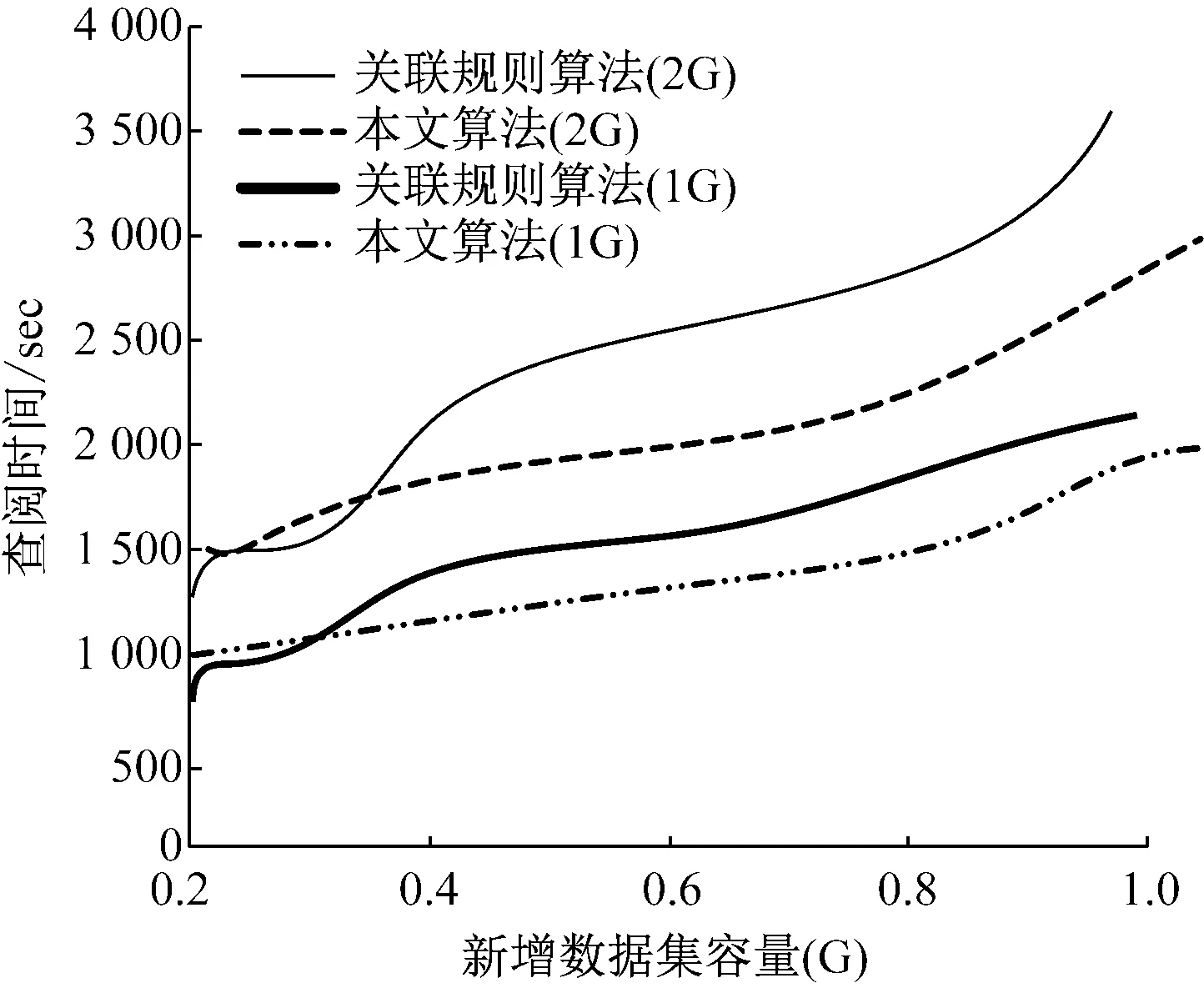
图6 新增数据集大小波动情况下的性能
分析图6能够得出,如果原病案数据集的容量是低于0.4G,传统关联规则算法比本文算法性能优,主要是因为本文算法对于大规模数据的并行运算具有较高的优势,如果病案数据集较低,本文算法需要耗费较高的调度代价,而当病案数据集容量较高情况下,本文算法耗费较低的调度代价。因此,当原病案数据集容量是0.8G,本文算法的查阅性能显著优于传统关联规则算法,当新增数据集容量是1G时,传统关联规则算法不能继续运行。因此能够看出,面向海量病案数据时,本文算法的性能优于传统关联规则算法。
2.4 完全分布环境下的性能比较
实验塑造1个DataNode、2个DataNode、3个DataNode以及4个DataNode组建的分布环境的病案信息集群,检测本文算法在这些集群中实施关联查阅,以及关联规则算法的查阅时间,结果如图7所示。

图7 关联规则算法以及本文算法集群的对比
分析图7能够得出,如果原病案数据集容量较低,则本文算法的处理效率以及传统关联规则的处理效率一致。主要是本文算法实施并行运行过程中,通过OLAP多维数据集实施多维多层次调度需耗费较多的能量,如果原病案数据集较少,耗费的能量占总体算法能耗的较高比例,使得算法处理效率降低。但是随着原病案数据集的提高,本文算法集群的运行效率显著优于传统关联规则算法。本文算法具有较高的集群并行运算性能和较强的运算能力。分析图7可得,相对于传统关联规则算法,本文算法的可伸缩性能高,随着数据集的提高,算法的运行时间呈现线性提升。
2.5 基于门诊病案的诊断关联挖掘分析
实验对2010年某省级医院门诊病案数据实施挖掘分析,通过本文算法对门诊病案实施多维多层的数据分析,获取内在问题,寻求合理的解决措辞。基于HIS的门诊挂号信息、LIS检验信息以及PACS检测信息等实施数据挖掘,基于门诊病案数据源,融合挂号信息数据集,实施病案数据关联查阅。采用本文算法频繁扫描以门诊患者为粒度的门诊数据集,将患者挂号信息同科室信息相对应。关联规则:口诊患者各科室各环节时间分析,分析不同科室平均各环境耗费时间,获取平均值以及耗时高的科室分布情况。
AVG(Sum(各环节时间))
Group By 患者挂号所在科室
不同环节耗费时间比例(%)=各环境耗费时间/就诊耗费总时间×100%
基于该关联规则,采用本文算法依据科室分类运算出各患者在就诊时不同环境耗费的时间,结果如图8所示。
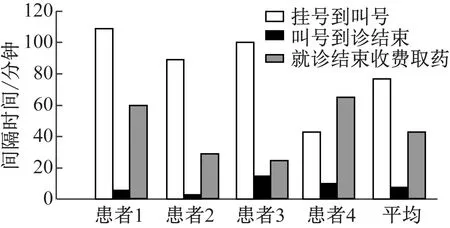
图8 就诊流程时间排列分析
采集从挂号到就诊终止耗费时间高于60分钟的患者信息,采集汇总后实施挖掘分析,获取相关的控制方案。
采用本文算法基于设置的关联规则挖掘门诊患者的就诊信息,研究患者就诊耗费的时间,实现不同资源的有效调配,并提出相关的处理措施,降低排队时间,提高患者满意度。
综合分析上述实验结果可得,采用本文设计的海量病案信息快速关联查阅算法,能够挖掘出有价值信息,对门诊病案数据实施多维度多层挖掘分析,能够获取问题根源,实时调控管理方案,提高患者就诊的满意度,具有较高的应用价值。
3 总结
文章基于病案数据多维多层次属性,设计并实现基于病案多维数据立方体的快速管理查阅算法,采用多维多层次的挖掘结构对病案数据实施关联规则挖掘,通过基于关联规则Apriori的数据挖掘算法,解决基于OLAP关联规则挖掘模型需要频繁扫描病案多维数据立方体的弊端,进一步提高海量病案信息查阅的效率。
[1] 吴晓云, 郑银雄, 冯笑玲. 基于数据库的医院病案信息SQL查询[J]. 中国卫生统计, 2014, 31(1):144-145.
[2] 黄东瑾, 谢玲珠, 郑仰纯,等. 基于病案首页数据挖掘的老年糖尿病患者住院日影响因素分析[J]. 广东医学, 2016, 37(13):1952-1956.
[3] 林媛. 非结构化网络中有价值信息数据挖掘研究[J]. 计算机仿真, 2017, 34(2):414-417.
[4] 包小源, 俞国培, 李岩. 病案首页数据分布式集成管理平台的设计与应用[J]. 中国医院管理, 2014, 34(5):30-32.
[5] Davydov D, Young T D, Steinmann P. On the adaptive finite element analysis of the Kohn-Sham equations: methods, algorithms, and implementation[J]. International Journal for Numerical Methods in Engineering, 2016, 106(11):863-888.
[6] 高武奇, 岳鑫. 基于HBase的图书借阅数据挖掘模型设计与实现[J]. 电子设计工程, 2017, 25(12):33-36.
[7] 米允龙, 米春桥, 刘文奇. 海量数据挖掘过程相关技术研究进展[J]. 计算机科学与探索, 2015, 9(6):641-659.
[8] 韩希先, 刘显敏, 李建中,等. TMS:一种新的海量数据多维选择Top-k查询算法[J]. 计算机研究与发展, 2017, 54(3):570-585.
[9] Kirchner M, Xu B, Steen H, et al. libfbi: a C++ implementation for fast box intersection and application to sparse mass spectrometry data[J]. Bioinformatics, 2014, 2014(8):1166-1167.
[10] 邓广彪. 改进的粒子群算法在云计算下的数据挖掘中的研究[J]. 科技通报, 2017, 33(4):120-124.
[11] 陈炎龙, 段红玉. 基于改进Hadoop云平台的海量文本数据挖掘[J]. 湖南师范大学自然科学学报, 2016, 39(3):84-88.
[12] 周发超, 王志坚, 叶枫,等. 关联规则挖掘算法Apriori的研究改进[J]. 计算机科学与探索, 2015, 9(9):1075-1083.
[13] 李雨童, 姚登举, 李哲,等. 基于R的医学大数据挖掘系统研究[J]. 哈尔滨理工大学学报, 2016, 21(2):38-43.
[14] Kovtoun S V. An Approach to the Design of Mass-correlated Delayed Extraction in a Linear Time-of-flight Mass Spectrometer[J]. Rapid Communications in Mass Spectrometry, 2015, 11(5):433-436.
[15] 赵艳青, 滕晶, 杨洪军. 基于数据挖掘的现代中医药治疗抑郁症用药规律分析[J]. 中国中药杂志, 2015, 40(10):2042-2046.
TheDesignandImplementationoftheFastCorrelationAlgorithmofMassCaseInformation
Chen Huangyu, Chen Haiyun
(Nanjing General Hospital of Nanjing Military Region, PLA Nanjing, Jiangsu 210002, China)
In order to solve the defects of lag and high deviation in the process of mining mass medical data by using traditional association rule, a multi-dimensional data cube algorithm with a power of quick management and access is designed by incorporating with the multi-lecvel mining structure. We perform the association rule for the medical data, design association rule mining model for OLAP. It overcomes the disadvantage of OLAP association rules mining model does not requre frequently the data set. Besides, we conduct a comprehensive stuby of the association rule and get the hiddcn information of patients, such as the occupation, the age as well as the relationship between these data and differnt diseases. Data sets are obtained by mining model based on OLAP association rule mining. The experimental results show that the proposed algorithm can improve the patient's satisfaction by looking at the data of large number of cases.
Mass diseases; Information expressing; Association rules; Mining algorithms
1007-757X(2017)12-0053-05
陈皇宇(1984-),女,本科,技师,研究方向:病案管理,医疗信息管理。
陈海云(1977-),女,本科,护师,研究方向:医保管理。
TP311.13
A
2017.10.17)
