基于信息推荐的图书管理系统实践分析
2018-01-05雷礼群武汉城市职业学院
雷礼群/武汉城市职业学院
基于信息推荐的图书管理系统实践分析
雷礼群/武汉城市职业学院
图书馆数字化需求以及信息科技的发展导致了图书管理系统的出现,它旨在通过网络化信息管理为管理者和读者提供更好的服务,提高图书管理效率。但是,在当今大部分图书管理系统中,其基础服务较为简单,一般只能提供基础的图书管理和信息检索服务。随着馆藏日益庞大,针对每类图书都存在成千上万种版本,如何在海量的图书信息中让读者找到需要的图书已变得越来越困难。因此,为读者提供个性化信息推荐成为读者的迫切需求。
信息推荐;图书管理系统
前言:
图书管理系统是指通过计算机软件的方式,对图书进行信息化组织和管理,它使得管理人员能够高效地管理海量图书,并能让用户快速搜索和定位图书,从而为两者都提供快捷、方便的信息化服务。这种服务模式具有传统人工管理方式不可比拟的优势。因此,实现对图书进行智能化管理和服务是当前一个必然的趋势。
一、图书馆个性推荐概念及原理
(一)图书馆个性推荐的概念
图书馆个性推荐是指以读者的个人背景、专业、习惯、爱好和提出的特别要求等为依据,对每一位读者提供个性化推荐服务。
(二)个性化推荐原理
个性化推荐是信息的重组过程,是信息资源的再分配,是一种基于用户需求的个性化信息服务模式。其原理是以充分挖掘用户的个性化需求信息为前提,主动组织信息资源,并向用户推送其感兴趣的信息资源和信息服务。一方面是社会进步与图书馆自身发展的需要,有利于提高图书馆的科技能力与服务水平。另一方面节省用户获取有效文献信息时间,激发读者阅读兴趣,提高图书的使用效率,提高用户的满意度。
二、现有图书推荐算法
(一)基于数据挖掘的推荐
数据挖掘中的关联规则方法,通过已经评分或用户的借阅记录向用户推荐新的图书。基于概念分层的方法定义人口统计学属性,人口统计学属性再把用户特征化。根据分类法把图书分为不同的类别,特定类别的用户对特定类别的图书感兴趣,这种方法称为knowledge generalized profile association rules。针对协同过滤推荐的数据稀疏性、冷启动问题,将关联规则应用到图书推荐系统。利用聚类算法对图书进行聚类,得到同一簇内图书的相似性较高,不同簇相似性低,再结合余弦相似性计算用户的相似性,得到目标用户的最终图书推荐。
(二)基于模糊语言学的推荐
模糊语言学在推荐系统得到广泛的应用。等基于模糊语言学,提出了多规则的推荐系统,并应用于大学图书馆。该系统为专门领域的研究人员推荐专门的资源,发现协同的可能性,并形成多规则群体。但表示用户的兴趣偏好需要大量复杂的信息,因而获取用户概貌比较难。研发模糊语言学的推荐系统,帮助研究人员和公司自动获取信息。不需要用户直接提供用户特征概貌的兴趣偏好向量,而是通过计算用户的不完整模糊语言兴趣偏好关系,得到用户的兴趣偏好。
(三)协同过滤推荐
协同过滤分为基于用户、基于项目、基于模型的算法。大致推荐过程为:
(1)建立m*n的用户-评价模型。
(2)由皮尔森相关系数、余弦相似性或修正的余弦相似性等公式,计算目标用户与其他用户的相似性,得到目标用户的最近邻居N u=N1,N2…,N i。
(3)由最近邻居计算目标用户对目标项目的预测评分,将预测评分最高的TOP-N项目推荐给用户。在有足够的用户数据的时候,可向具有相同兴趣偏好的用户推送受欢迎的推荐。但数据往往是稀疏的。针对此问题,研究人员提出基于链接预测的协同过滤、评价矩阵列向量的协同过滤,结合心理学的遗忘规律及用户年龄、专业、职业、学历、性别等特征向量,改进了基于用户的协同过滤。
(四)基于内容的推荐
基于内容的推荐,在没有足够的数据下,可以向具有不同兴趣偏好的用户推荐非流行的项目。LIBRA是很早的基于内容的图书推荐系统,由每位用户提供的训练例子,使用贝叶斯学习算法,从Web提取图书的标题等信息,推荐图书。
(五)基于云计算的推荐
云模型是我国著名的李德毅院士提出的。云由期望值、熵、超熵表示,云模型转换了定性概念和数值表示的不确定。一个云包含很多个云滴。云的整体形状反映定性概念的特征。利用云计算模型计算项目间的相似性,解决数据稀疏性和算法的扩展性问题,有效提高基于项目协同过滤推荐算法的推荐质量。利用云模型计算知识层面的用户相似性,有效克服传统基于向量计算用户相似性的缺点。
三、图书智能推荐系统框架设计
如图1所示
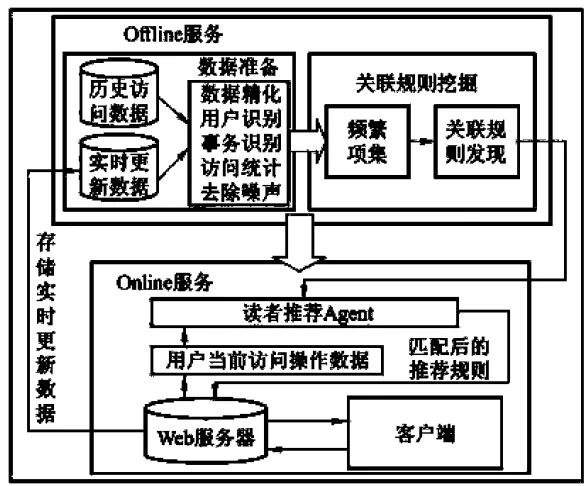
图1 图书智能推荐系统框
(一)Offline部分
这一部分是通过关联规则的挖掘和数据的准备来完成的。关联规则的挖掘是由频繁项集的扫描和关联规则生成这两部分组成,而数据准备则是将图书馆的web服务器实时用户文件和借阅历史进行扫描并生成相应文件。
首先进行的是数据准备工作,这一工作过程中会对数据进行必要的预先处理,规则挖掘的正确度和效率也受这一结果的影响。另外由于图书的历史数据和实时数据都存在大量冗余,也需要对数据进行必要的去噪和整理。之后进行的是关联规则的挖掘,这里会利用关联模式来发现用户浏览模式,通过对模式的分析得到读者的借阅规则,存储之后为后面的online部分服务。
(二)Online部分
Online部分运用Offline部分生成关联规则的集合,并且在同一时间内记录和检测用户的浏览过程,动态地为用户推荐相应的链接或者书目操作等服务。由读者推荐和图书馆服务器组成,服务器记录用户的操作数据,读者推荐服务通过匹配读者行为数据和Offline部分产生的有趣规则,给用户进行图书推荐服务。
四、结语
随着数字图书馆朝着越来越智能化的方向发展,图书馆需要提供给读者更加有针对性的图书自动推荐服务。通过本文的研究能够得到,作为图书智能推荐系统技术,可以提高图书馆的服务水平和质量,为图书馆管理提供数据支持。在今后的研究中还需要进一步深入研究,以期能够更好的改进图书馆的服务质量和效率。
[1]陈宇亮,沈奎林.基于读者评论的图书推荐系统研究[J].图书情报导刊,2016(9):6-9.
[2]栾旭伦.大数据环境下高校图书馆个性化信息服务系统研究[J].图书馆学刊,2014(8):118-121.
[3]曾子明,陈贝贝.融合情境下智慧图书馆个性化服务研究[J].图书馆论坛,2016(1):57-63
