基于隐马尔可夫模型的web异常检测案例分析
2017-12-07朱骊安
朱骊安
(北京邮电大学理学院,北京 100876)
基于隐马尔可夫模型的web异常检测案例分析
朱骊安
(北京邮电大学理学院,北京 100876)
如何将数据科学在网络安全领域内应用一直是一个火热的话题,本文介绍了如何用隐马尔可夫模型(HMM)建立web参数模型,检测注入类的web攻击。以及这种方法在某航空公司的实施情况,准确率最终达到约80%。
隐马尔可夫模型;异常检测;隐含序列;概率模型;web威胁
0 引言
随着互联网的发展,企业的传统网络边界在逐渐消失。工业界特别是大型互联网公司,平均每日活跃用户上千万,每个应用系统的日志都会高达几百G甚至上T字节。同时,以灰产,黑产为代表的恶意访问占比依然居高不下,并且攻击手段在不断推陈出新。传统web入侵检测技术,无论是Firewall、Web应用防火墙(WAF)、入侵防御系统、入侵防御系统(IPS)还是入侵检测系统(IDS)本质上都是依据白名单或已发现攻击总结出的规则,通过维护规则集对入侵访问进行拦截。一方面,硬规则在灵活的黑客面前,很容易被绕过,且基于以往知识的规则集难以应对攻击;另一方面,攻防对抗水涨船高,防守方规则的构造和维护门槛高、成本大。
基于机器学习技术的新一代web入侵检测技术有望弥补传统规则集方法的不足,为web对抗的防守端带来新的发展和突破。Web异常检测归根结底还是基于日志文本的分析,因而可以借鉴自然语言处理中的一些方法思路,进行文本分析建模。基于隐马尔科夫模型(HMM)的参数值异常检测,就是借助自然语言处理的方法,发现web日志中的异常序列,从而在线检测出未知异常行为。
1 模型原理
1.1 隐马尔可夫模型
隐马尔可夫模型(HMM)是马尔可夫链的一种,它的状态不能直接观察到,但能通过观测向量序列观察到,每一个观测向量是由一个具有相应概率密度分布的状态序列产生。
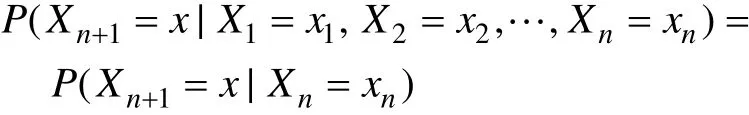
这里x为过程中的某个状态。上面这个恒等式可以被看作是马尔可夫性质[1]。
随机过程是一连串随机事件动态关系的定量描述。马尔科夫过程是一种随机过程,简单地说,已知现在、将来与过去无关(条件独立),则称此过程为马尔科夫过程[2]。
HMM 主要有以下三类应用:解码问题,根据模型参数和观测序列,找出该观测序列最优的隐含状态序列;评估问题,根据模型参数和观测序列,计算该观测序列是由该模型生成的概率;学习问题,根据一系列观测序列,建立对应该系列序列最优的HMM 模型。这里我们只用得到后两个。在训练阶段,对应学习问题,用大量正常的参数值训练出站点下的参数id的HMM模型;在检测阶段,对应评估问题,待检测的参数值带入模型检测是否是正常。
1.2 参数异常模型
Web威胁中的几大类攻击,SQL、XSS、RCE等虽然攻击方式各不相同,但基本都有一个通用的模式,即通过对参数进行注入payload来进行攻击,参数可能是出现在GET、POST、COOKIE、PATH等等位置。所以对于异常模型,能覆盖掉参数中出现的异常,就能覆盖掉很大一部分的常见的Web攻击[3]。
假设有这样一条url:www.xxx.com/index.php?id=123。通过对url的所有访问记录分析,不难发现:普通用户的正常请求虽然不一定完全相同,但总是彼此相似;攻击者的异常请求总是彼此各有不同,同时又明显不同于正常请求。如下数据所示:
User: www.xxx.com/index.php?userid=admin123
www.xxx.com/index.php?userid=root
www.xxx.com/index.php?userid=hzq_2017
Attacker: www.xxx.com/index.php?userid= mai06’union select xxx from xxx
www.xxx.com/index.php?userid=%3Cscript%3E alert(‘XSS’)%3C
www.xxx.com/index.php?userid=125$%7B@prin t(md5(123))%7D
如果我们能够搜集大量参数 id的正常的参数值,建立起一个能表达所有正常值的正常模型。由于,正常总是基本相似,异常却各有各的异常。基于这样一条观测经验,如果我们能够搜集大量参数id的正常的参数值,建立起一个能表达所有正常值的正常模型,那么一切不满足于该正常模型的参数值,即为异常。
2 工程实现
2.1 系统架构--组件选择与模块关系
模型训练过程我们需要大量的正常历史数据进行训练、数据量会达千万级别以上,因此我们需要一个大数据处理引擎;此外,检测过程中我们希望能够实时的检测数据,及时的发现攻击,这是一个流(streaming)计算过程,需要一个流计算引擎。综合考虑,我们选择 spark作为统一的数据处理引擎,即可以实现批处理,也可以使用spark streaming实现近实时的计算。
系统架构如下图,需要在spark上运行三个任务:

图1 系统架构图Fig.1 Sy stem architecture diagram
①sparkstreaming将kafka中的数据实时的存入HDFS;
②训练算法定期加载批量数据进行模型训练,并将模型参数保存到HDFS;
③检测算法加载模型,检测实时数据,并将告警保存到ElasticSearch。
在我们的系统中,模型训练算法是在 spark上开发完成的。用HDFS来存储HTTP请求数据和模型数据。ElasticSearch在我们的系统架构中主要用来存储、检索、展示告警数据。
2.2 数据的采集与储存
获取http请求数据通常有两种方式,第一种从web应用中采集日志,使用 logstash从日志文件中提取日志并泛化,写入 Kafka;第二种可以从网络流量中抓包提取http信息。我这里使用第二种,用python结合Tcpflow采集http数据,在数据量不大的情况下可稳定运行。
与 Tcpdump以包单位保存数据不同,Tcpflow是以流为单位保存数据内容,分析 http数据使用tcpflow会更便捷。Tcpflow在linux下可以监控网卡流量,将 tcp流保存到文件中,因此可以用 python的pyinotify模块监控流文件,当流文件写入结束后提取 http数据,写入 Kafka。这样数据的采集就完成了,下面开始数据的储存。
开启一个 SparkStreaming任务,从 kafka消费数据写入Hdfs,Dstream的python API没有好的入库接口,需要将Dstream的RDD转成DataFrame进行保存,保存为json文件。
2.3 数据的清洗与泛化
抽取器实现原始数据的参数提取和数据泛化,传入一条json格式的http请求数据,可以返回所有参数的 id、参数类型、参数名、参数的观察状态序列 p_list。
2.3.1 拆解数据生成参数
将http请求数据用“请求的URL路径”和“GET、POST的请求参数以及参数名本身”两种方式进行拆解,提取相应的参数值。例如:提取源IP、目的IP、host[4]。这一步的难点在于如何正确的识别编码方式并解码。不同的参数,正常的值不同。同时,有参数传递的地方,就有可能发生参数注入型攻击。所以,需要对站点下所有路径下,所有GET、POST、PATH中的所有参数都训练各自的正常模型。另外,对参数名本身,也训练其正常的模型。
针对这些情况将参数分成三类:第一类,uri,将每条 uri的每一个参数对应的参数值泛化后做为p_state。第二类,uri_pname,将每条数据的所有的参数名拼接起来泛化作为p_state。第三类,uri_path,将每条数据的uri里面的路径泛化作为p_state。
2.3.2 参数泛化
如果我们把参数 id的每个参数值看作一个序列,那么参数值中的每个字符就是这个序列中的一个状态。同时,对于一个序列,为 123或者 345,其背后所表达的安全上的解释都是:数字 数字 数字,我们用N来表示数字,这样就得到了对应的隐含序列,取字符的unicode数值作为观察序列[5]。泛化的方法如下:
1. 大小写英文字母泛化为“A”,对应的unicode数值为65。2. 数字泛化为“N”,对应的unicode数值为78。3. 中文或中文字符泛化为“C”,对应的unicode数值为67。
4. 特殊字符和其他字符集的编码不作泛化,直接取unicode数值。
5. 参数值为空的取0。
2.4 训练任务
一个参数对应一条数据,其中包括:一个p_id与一个 p_state。这样就得到了对应的隐含序列。Spark训练任务抽取所有 http请求数据的参数,并按照参数ID(p_id)分组,分别进行训练,将训练模型保存到Hdfs。
2.4.1 得到模型输入
我们需要对经过清洗与泛化(Extractor)后的数据进行分组,并存为字典p_dict。key值为参数ID,将 key值相同的数据的 p_state作为其 value值。p_dict的 key值有:p_id,p_name,p_type,p_state。由于模型的输入规则,我们只需要参数ID(p_id)和隐含序列(p_State)。故将每个 p_dict中的 p_id和p_state抽取出来得到模型的输入数据。
2.4.2 计算基线并保存--训练器(Trainer)
传入参数的所有观察序列,训练器完成对参数的训练,返回训练好的模型profile[6]。其中,HMM模型使用python下的hmmlearn模块,profile取观察序列的最小得分。由于我们假定进入模型的数据是正常数据,建立的是一个能表达所有正常值的正常模型,那么一切不满足于该正常模型的参数值,即为异常。所以,profile取得是所有score的最小值。再将基线结果profile值保存起来[7-9]。
2.5 检测任务
Spark Streaming检测任务实时获取kafka流数据,抽取出数据的参数,如果参数有训练模型,就计算参数得分,小于基线输出告警到Elasticsearch。将得分与基线相比较,低于基线的报警。
3 模型应用案例分析
3.1 背景
某航空公司门户网站发现有不少攻击尝试行为,偶尔会发现有些网页正常用户在常规访问的过程中会发现无法访问的现象。经初步判定,很可能是攻击用户的异常请求造成的。为了进一步分析,航空公司运维人员提供了为期一个月的web访问日志,需要把访问日志中的异常行为数据筛选出来。
3.2 研究过程
3.2.1 数据情况
运维人员提供的是 IIS日志,对应的日志关键属性如表1所示。
3.2.2 数据处理与建模
以第一周七天的数据作为训练数据,一周数据大概1G左右,我们选择通过spark程序把数据处理成我们建模需要的json格式,存入HDFS中。数据预处理完成后,我们执行训练任务,建立模型。建模结果部分截图如表2所示。
3.2.3 检测与结果分析
由于目前拿到的数据都是历史数据,所以我们对实时检测程序HmmDetectionJob作了修改,修改sparkstreaming代码为spark代码,把数据源从kafka读数据修改为从HDFS读数据。
为了测试模型的准确性及程序的稳定性,我们选取第8天的数据为研究对象,用第8天数据进行检测。第8天一共13万条web日志,经过检测告警的有50天,其中30条为有威胁数据,检测准确率为60%。

表1 IIS 日志Tab.1 IIS Logs
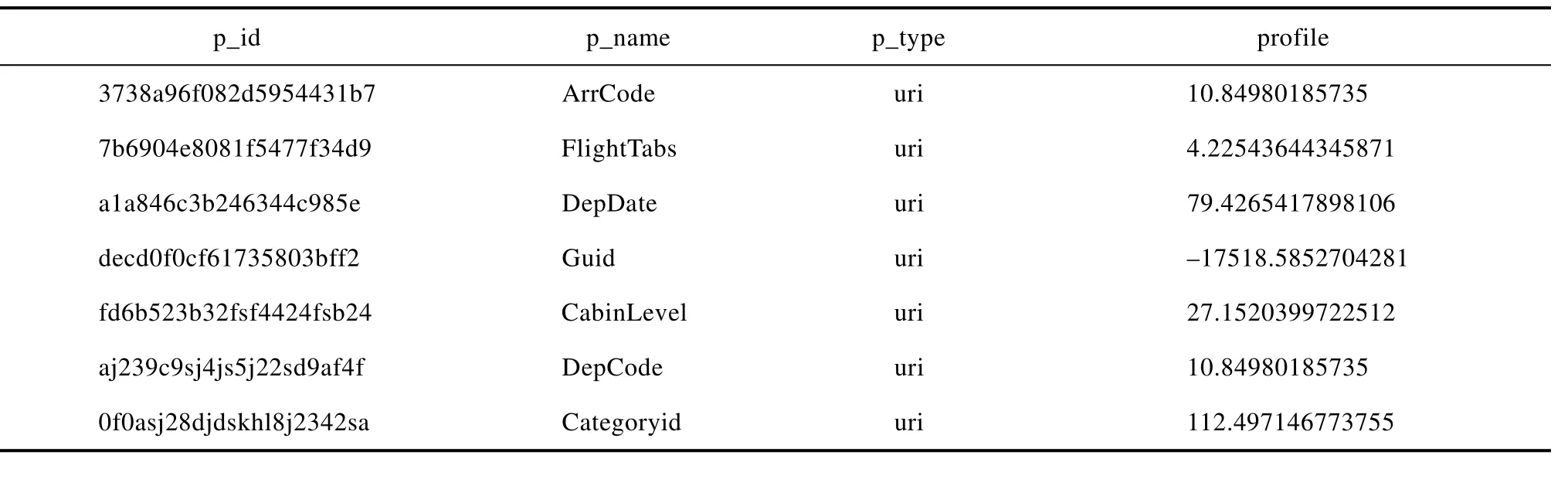
表2 建模结果Tab.2 Modeling results
3.2.4 问题与解决方案
通过对检测结果与模型的对比分析,我们发现检出准确率还有进一步提升的空间,主要原因是建模结果的准确率缺失造成的[10-12],原因如下:
1、样本量偏小
隐马尔可夫模型是一个概率模型,样本量越大、涵盖的url数据类型越多,模型的准确度越高。而我们这里只用了一周的web日志作为训练数据,样本量偏小,需要提高训练模型的数据量。
2、训练数据中有异常数据
通过对模型中基线分值异常偏低的模型结果所对应的训练数据进一步分析,发现训练数据中混入一些异常数据,主要有以下三种情况:少量未被认为筛选出的攻击行为数据;中文乱码数据;无法处理的加密数据。建模前我们需要设计一个过滤模块,对这些异常数据进行过滤。
3、缺少避免模型基线过度偏小的修正模块
在对模型基线值profile进行训练的过程中,只是简单的把正常数据中评分最低的值当做 profile,而在建模中并没有加入修正过程。
通过对相同p_id所对应score的分析,我们发现score服从正态分布,利用正态分布的特性,我们profile 距离score分布的期望3倍方差以内为判断条件,当不满足时,剔除profile 对应的score重新训练,直到满足条件。
通过对以上问题的解决,我们最终把检测准确率提高了85%以上,并准确的筛选出大量攻击行为数据,部分数据截图如表3所示。

表3 攻击数据Table 3 Attact Data
[1] 施仁杰. 马尔科夫链基础及其应用[J]. 西安电子科技大学出版社, 1992.
[2] 李裕奇, 刘赪编. 随机过程(第3版)习题解答[M]. 国防工业出版社,2014.09.
[3] 谢逸, 余顺. 争基于Web用户浏览行为的统计异常检测[J].软件学报, 2007, 18(4):967-977
[4] DH Schneck, S Cherry,D Goodman.Web interface and method for accessing and displaying directory information[M].US, 2001.
[5] I Corona, D Ariu, G Giacinto. HMM-web: a framework for the detection of attacks against web applications[J]. IEEE International Conference on Communications , 2009 , 15 (1):747-752.
[6] 何强, 毛士艺, 张有为.多观察序列连续隐含马尔柯夫模型的无溢出参数重估[J].电子学报, 2000, 28(10): 98-101.[7] 岳峰, 左旺孟. 基于马尔可夫随机场的弹性掌纹匹配[J].新型工业化, 2012, 2(2): 52-61.
[8] 朱靖波, 肖桐. 句法统计机器翻译的一些问题分析[J]. 新型工业化, 2012, 2(1): 1-11.
[9] 张元青, 聂兰顺. 一种BPMN到JPDL的模型转换方法[J].新型工业化, 2012, 2(1): 23-31.
[10] 张彦. 动态Web 技术在实时监测系统中的实现[J]. 软件,2013, 34(12): 265.
[11] 刘晓婉, 胡燕祝, 艾新波. 开源中文分词器在web搜索引擎中的应用[J]. 软件, 2013, 34(3): 80-83.
[12] 黄炳良, 张忠琳. 预测市场技术在机器学习中的应用[J].软件, 2014, 35(11): 31-35.
Case Analysis of Web Anomaly Detection Based on Hidden Markov Model
ZHU Li-an
(1. Beijing University of Posts and Telecommunications, Beijing 100876, China;
How to apply data science in the field of network security has been a hot topic, This paper describes how to use the hidden Markov model (HMM) to establish a web parameter model to detect injection attacks. As well as the implementation of this method in an airline, the accuracy rate eventually reached about 80%.
Hidden markov model; Anomaly detection; Implicit sequence; Probability model; Web threat
TP181
A
10.3969/j.issn.1003-6970.2017.11.022
本文著录格式:朱骊安. 基于隐马尔可夫模型的web异常检测案例分析[J]. 软件,2017,38(11):114-118
朱骊安(1992-),女,研究生,主要研究方向:随机排队网络、物流供应链管理。
