基于膨胀运算的移动对象兴趣点检测方法
2017-11-09王清丁赤飚付琨任文娟
王清, 丁赤飚, 付琨, 任文娟
(1.中国科学院 电子学研究所, 北京 100190; 2.中国科学院 空间信息处理与应用系统技术重点实验室, 北京 100190; 3.中国科学院大学 电子电气与通信工程学院, 北京 100049)
基于膨胀运算的移动对象兴趣点检测方法
王清1,2,3, 丁赤飚1,3, 付琨1,2,3, 任文娟1,2,3
(1.中国科学院 电子学研究所, 北京 100190; 2.中国科学院 空间信息处理与应用系统技术重点实验室, 北京 100190; 3.中国科学院大学 电子电气与通信工程学院, 北京 100049)
针对传统兴趣点检测算法在准确性和效率方面的不足,提出基于膨胀运算的移动对象兴趣点检测方法(DMDO)。通过矩阵二值化操作滤除停留点噪声,提高预测准确率,并用膨胀运算替代传统方法中的聚类算法提高算法效率。将DMDO在开放空间数据集AMSA和IMIS3Days上进行仿真实验,结果表明:DMDO相比基于密度的空间聚类算法,在数据集AMSA上准确率平均提高17.94%,算法效率提高6.63倍;在数据集IMIS3Days上准确率平均提高19.98%,算法效率提高9.13倍;相比以聚类点排序结果确定聚类结构算法,DMDO在数据集AMSA上准确率平均提高20.04%,算法效率提高14.61倍;在数据集IMIS3Days上准确率平均提高16.60%,算法效率提高42.19倍;DMDO相比传统方法均表现出较高的预测准确性、较低的时间开销,适用于解决大数据背景下的移动对象兴趣点检测问题。
信息处理技术; 轨迹数据挖掘; 兴趣点检测; 膨胀运算; 开放空间
0 引言
随着通信技术、全球定位导航系统的迅猛发展,可以通过多种途径获得不同类型的轨迹数据。例如通过智能手机、车载导航系统获取行人、汽车等城市轨迹数据[1-3],通过卫星、雷达、船舶自动识别系统(AIS)等定位技术获得船舶、飞机的轨迹数据[4]。轨迹表达了移动对象一段时间内的位置信息,蕴含着移动对象的行为习惯。挖掘海量轨迹数据有助于深入了解移动对象行为习惯、感知社会需求[5]。为解决轨迹数据挖掘问题,实现位置大数据的应用价值,基于位置的服务(LBS)应运而生。研究区域中的兴趣点是指具有特殊含义的停留区域,例如城市中的教学楼、宿舍、商城,海域沿岸的港口、补给站等。一部分LBS依赖兴趣点的挖掘与检测,例如,根据用户常访兴趣点计算用户间相似度,从而进行用户社交网络的挖掘与研究;预测用户即将前往的兴趣点,从而推送相关广告信息等[6-8]。本文主要围绕如何快速、准确地挖掘兴趣点展开研究。
兴趣点检测技术主要分为两类,即静态提取和动态挖掘方法[9]。静态提取方法需要人工标注类似教学楼、商城、港口、补给站等有特殊含义的停留位置[10-11]。动态挖掘方法不需要研究区域的先验知识作为输入条件,仅根据原始轨迹数据的时空特征发现潜在兴趣点,这些时空特征包括经纬度、速度、加速度和轨迹前进方向等。
动态挖掘算法一直是国内外学者的研究重点。主要思路是首先检测大量历史轨迹的停留点,然后对停留点进行聚类,每类对应一个兴趣点。兴趣点检测主要分为两部分内容:停留点检测和停留点聚类。
在停留点检测方面,Agamennoni等[11]根据静态速度阈值检测停留点,小于速度阈值的轨迹点被认为是停留点。郑宇等[12]提出根据时间阈值和距离阈值从历史轨迹中提取停留点。罗庭等[13]根据移动对象轨迹曲折程度判断其是否低速行驶,移动对象轨迹短时间内曲折程度较高时,认为其行驶速度较低,处于“停留”状态。
在停留点聚类方面,由于不同移动对象到达同一兴趣点可能产生不同停留点,这些停留点距离很近,可利用聚类方法将停留点聚集为各个点簇,每个兴趣点用点簇表示。大量研究工作围绕采用不同的聚类方法及其改进方法展开。Ashbrook等[14]采用K均值(K-Means)聚类算法对历史轨迹数据中提取的停留点进行聚类。K-Means算法是一种划分聚类算法,需要用户预先设定兴趣点的数目K,但是从杂乱无章的轨迹中预先准确指定兴趣点个数并非易事;并且,K-Means算法抗噪能力较差,易受离群点影响。由于K-Means算法存在参数设定、抗噪性差的问题,Palma 等[15]采用一种抗噪声的基于密度的空间聚类(DBSCAN)算法对停留点进行聚类。DBSCAN算法可以避免预先设定兴趣点数目并剔除噪声点,但是需要设定数量阈值和距离阈值,并且算法时间复杂度随着数据量的增加而大幅增加,不适宜大数据量环境下的兴趣点检测问题。Zimmermann等[16]采用一种以聚类点排序结果确定聚类结构(OPTICS)的算法挖掘兴趣点。OPTICS算法属于基于密度的聚类算法,相比DBSCAN算法的改进之处在于,无需预先设定阈值,能获得任何阈值的DBSCAN聚类结果。
目前国内外挖掘兴趣点所采用的主流方法可总结为首先检测停留点,然后采用DBSCAN算法等基于密度的聚类算法对停留点进行聚类,以停留点簇表示各兴趣点。主流算法存在问题主要为兴趣点检测准确率较低、算法时间复杂度较高:首先,算法易将移动对象偶然的停留误判为停留点,在停留点检测中存在大量误判现象,影响了聚类结果,从而降低兴趣点检测的准确性;其次,以DBSCAN算法为代表的基于密度的聚类算法时间复杂度较高,数据规模较大时耗费时间长,不适用于大数据背景下的聚类问题。
针对传统方法的不足,本文提出了基于膨胀运算的移动对象兴趣点检测算法(DMDO),旨在通过矩阵二值化操作滤除误判的停留点噪声,并用膨胀运算替代聚类算法提高算法效率。
1 DMDO流程
在介绍具体算法之前,首先描述方法涉及的基本概念。
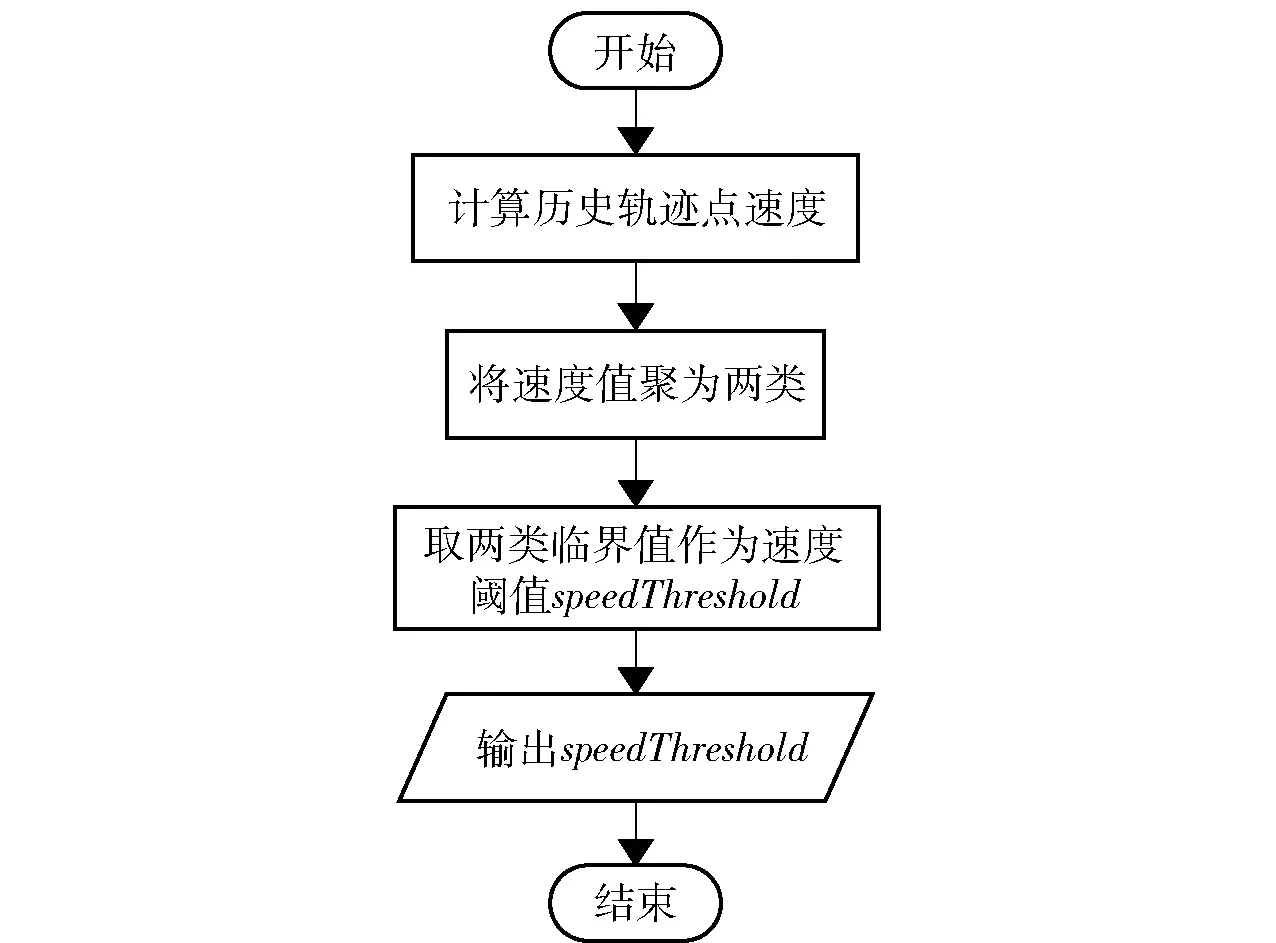
定义1停留点。移动对象的速度小于速度阈值speedThreshold时所在的具体经纬度。若对于轨迹点p,满足vp 定义2网格。将研究区域等距离划分所形成的二维规则区域。 定义3停留网格。包含停留点的数目大于一定阈值的网格。 定义4兴趣点。具有特殊含义的区域,例如教学楼、商城、港口、补给站等。本文根据停留点及停留网格挖掘兴趣点。 算法流程如图1所示。 图1 DMDO流程图Fig.1 Algorithm flow of DMDO 将研究区域离散化,均等划分为等距网格。 计算合理的速度阈值,用于历史轨迹中的检测停留点。 遍历历史轨迹集合中的轨迹点,计算其速度值,并与速度阈值speedThreshold进行比较,若轨迹点速度值小于speedThreshold,则将其判定为停留点,映射至研究区域网格中,并将相应网格的停留点计数增一。完成遍历后,形成停留点计数矩阵Matrix. 根据阈值θ二值化停留点计数矩阵Matrix,获得矩阵Matrix′. 二值化保留停留点数目较多的停留网格,滤除移动对象偶然停留所产生的误判噪声。 对矩阵Matrix′进行膨胀运算,连通空间位置较近的停留网格,形成各个连通区域。将覆盖网格数量大于w×w(w表示膨胀运算模板宽度)的连通区域作为兴趣点预测结果,将连通区域中包含停留点数目最多的网格设定为兴趣点的中心。输出兴趣点预测结果,至此,DMDO流程结束。 DMDO用膨胀运算替代DBSCAN聚类,一方面膨胀运算能够替代DBSCAN聚类实现连通、聚集的目的,另一方面,膨胀运算降低时间开销。假设停留点数目为n,停留网格数目为m(m≪n),DBSCAN聚类的时间复杂度为O(n2),膨胀运算的时间复杂度为O(m),算法效率大幅提高。 计算合理速度阈值的算法流程如图2所示。遍历历史轨迹集合中的轨迹点,根据当前点和相邻点经纬度计算其速度,然后采用K-Means算法将速度值聚为“高速”、“低速”两类,并取两类临界值作为速度阈值speedThreshold. 图2 速度阈值计算流程图Fig.2 Calculation flow of speed threshold 2.1 实验环境及数据集 实验的软硬件条件如下:CPU为酷睿i3(2核,2.50 GHz),内存4.00 GB;操作系统为32位Windows10,仿真软件为PyCharm 5.0.1. 为验证DMDO挖掘兴趣点的准确性及算法效率,本文将采用两组开放空间数据集进行实验。两组数据集均为船舶轨迹数据,特征如表1所示。 数据集1 AMSA是由澳洲海事安全局提供的2015年8月至2015年11月的澳大利亚附近海域民用船舶轨迹数据,包含3 327条轨迹,458 716个轨迹点,平均采样间隔为34.25 min. 数据集2 IMIS3Days是由IMIS Hellas S.A.公司提供的爱琴海海域民用船舶轨迹数据,包含933条轨迹,3 095 254个轨迹点,采样间隔为10 s. 表1 实验数据集特征 本文通过World Port Source网站获取两组数据集所在区域的真实兴趣点作为评估标准,用于评估算法挖掘兴趣点的准确性。两组数据集真实兴趣点的提取结果如表2所示。 表2 真实兴趣点提取结果 2.2 实验结果 本文从兴趣点检测的准确性和效率两个方面对DMDO与两种传统算法DBSCAN及OPTICS进行对比,分别采用F1值、算法运行时间T量化算法准确性和效率。传统方法DBSCAN的思路是首先通过速度阈值检测历史轨迹中的停留点,然后采用DBSCAN聚类算法对停留点进行聚类;OPTICS算法的思路是首先检测停留点,然后采用OPTICS算法根据停留点之间的距离对其进行排序,再采用自动聚类方法根据排序结果对停留点进行聚类。 2.2.1 评估指标 本文用F1值评估兴趣点检测的准确性,其计算方法为 (1) 式中:P为准确率,表征兴趣点检测的查准率,即预测出的真实兴趣点占算法预测结果总量的比率;R为召回率,表征兴趣点检测的查全率,即预测出的真实兴趣点占真实兴趣点总量的比率。若集合TD={TD1,TD2,…,TDn}表示研究区域中提前标注的真实兴趣点,集合PD={PD1,PD2,…}表示算法的兴趣点预测结果,则P和R的具体计算分别为 (2) (3) 式中:函数H(PD,TDi)表示算法预测结果是否命中真实兴趣点TDi. 若在预测结果集合PD中存在一个预测结果PDj,覆盖真实兴趣点TDi,则H(PD,TDi)=1,否则为0,即 (4) 2.2.2 实验结果及分析 DMDO涉及的两个重要参数为二值化阈值θ和膨胀运算模板宽度w. 阈值θ反映过滤停留点噪声的力度,值越大表明过滤的力度越强;模板宽度w反映相邻两个停留点连通的难易程度,值越大表明越易连通。传统DBSCAN算法中包含两个参数eps和minPts;OPTICS算法中包含一个参数minPts. 其中,minPts与阈值θ具有类似含义,eps与模板宽度w具有类似含义。d表示网格划分宽度,转换关系可近似表示为 (5) minPts=2θ. (6) 在检测出相同停留点的前提下,比较DMDO与两传统算法DBSCAN及OPTICS对于两个数据集AMSA及IMIS3Days在不同参数组合(θ,w)下的准确性F1值和运行效率T. 实验结果如图3所示,图3(a)表示采取不同参数组合时,3种算法在数据集AMSA上的F1值,图3(b)表示3种算法在数据集AMSA上的运行时间T,图3(c)和图3(d)表示3种算法在数据集IMIS3Days上的F1值及运行时间T. 对于数据集AMSA,设置二值化阈值θ取值范围为1~29,膨胀运算模板宽度w取值为1、3、5. 分析图3(a),当w为1、3、5时,DMDOF1值的变动范围分别为[0.37, 0.45]、[0.58, 0.74]、[0.78, 0.83],传统算法DBSCAN变动范围为[0.04, 0.15]、[0.42, 0.57]、[0.59, 0.77],传统算法OPTICS变动范围为[0.34, 0.51]。当参数一致时,DMDO的F1值均显著优于DBSCAN算法。原因是两种算法预测准确的兴趣点数目相近,而DBSCAN算法预测的兴趣点总数远大于DMDO,因此DMDO的准确率远高于DBSCAN算法,DMDO的F1值优势显著。当w>1时,DMDO的F1值显著优于传统算法OPTICS. 原因是OPTICS算法未对停留点连通的难易程度设置明确的阈值,仅根据停留点之间的距离自动聚类,导致挖掘结果包含较多的噪声点,预测的兴趣点数量过多,致使OPTICS算法的准确性下降。DMDO准确率的显著优势表明将停留点噪声误判为兴趣点的错误率较低,从而说明本文通过网格二值化过滤停留点噪声的处理方法更为有效,剔除噪声的力度更强。 分析图3(b),当w为1、3、5时,DMDO运行时间基本分布在1 s以内,DBSCAN算法运行时间均大于2 s,效率平均提高7.63倍,而OPTICS算法由于涉及停留点排序及停留点聚类,运行时间基本分布于10 s以上。表明DMDO效率大幅提高。 对于数据集IMIS3Days,能够获得相似的结论。设置二值化阈值θ取值范围为50~1 000,膨胀运算模板宽度w取值为1、3、5. 如图3(c)所示,DMDO的F1值优势显著,F1均值为0.67,DBSCAN算法的F1均值为0.47,OPTICS算法的F1均值为0.50,准确性大幅提高;如图3(d)所示,DMDO的运行时间平均为0.26 s,DBSCAN算法的运行时间平均为2.57 s,算法效率平均提高9.13倍,OPTICS算法的运行时间平均为10.78 s. 上述比较分析了DMDO相比两种传统算法DBSCAN及OPTICS在准确性和效率上的优势,下文将通过图3(a)和图3(c)分析参数二值化阈值θ及膨胀运算模板宽度w对DMDOF1值的影响。 当w保持不变时,随着二值化阈值θ增大,DMDO的F1值均存在先增后减的变化趋势。原因是当二值化阈值θ增大时,算法能够有效滤除移动对象偶然停留所产生的噪声,使得算法准确率增大,F1值增大;当θ持续增大,可能将真实的兴趣点当作噪声滤除,使得算法准确率、召回率均下降,F1值降低。 当二值化阈值θ不变时,随着膨胀运算模板宽度w的增大,DMDO的F1值显著增大(表现为w=5曲线在w=3曲线之上,w=3曲线在w=1曲线之上)。原因是膨胀运算模板宽度反映膨胀程度,模板越宽,表明距离较近的停留网格越易连通。当模板宽度w增大时,相邻的兴趣点连通,使得预测的兴趣点总数减少,提高预测准确率;另一方面,连通相邻兴趣点时覆盖了兴趣点之间的间隙,预测的兴趣点区域涵盖真实兴趣点的可能性更高,从而提高了召回率。准确率、召回率的提高使得F1值增大。 图3 实验结果Fig.3 Experimental results 另外,F1对参数θ的敏感程度较低,对w的敏感程度较高,也即参数w对F1的影响更为显著。 最后,讨论网格划分宽度d对算法DMDO精度和效率的影响。图4(a)和图4(b)分别表示在数据集AMSA和IMIS3Days上改变网格划分宽度d对F1值和运行时间T的影响。 图4 网格划分宽度d对实验结果的影响Fig.4 Influence of cell width d on experimental results 网格划分宽度d主要影响目的地挖掘的精细程度。调节网格划分宽度d时应相应调整二值化阈值θ和膨胀运算模板宽度w,以分别保持算法过滤停留点噪声的力度和停留点连通的难易程度基本不变。例如,当网格划分宽度d增大至原来的2倍时,网格覆盖区域的实际面积变为原来的4倍,若此时二值化阈值θ和膨胀运算模板宽度w保持不变,则网格将更易满足二值化阈值θ,更易于被判定为停留网格,从而降低了算法过滤停留点噪声的力度,并且由于网格覆盖面积增大,距离较远的停留点更容易连通,从而增大了算法连通停留点的能力。为了保持算法过滤停留点噪声的力度和停留点连通的难易程度基本不变,如图4(a)所示,当网格划分宽度d从0.1增大至原来的2倍时,二值化阈值θ也应从27增大至原来的4倍,膨胀运算模板宽度w应从9相应减小至5. 如图4(a)和图4(b)所示,当减小网格划分宽度d并相应调整其他两个参数时,算法DMDO的精度增高,算法效率降低。原因是减小网格划分宽度d时,停留点将映射至更为精细的网格,覆盖面积较小的兴趣点更易被算法检测出来,算法查全率提高,F1值增大。同时,由于网格划分更为精细,算法需要处理的网格数量增多,因而运行时间变长,算法效率降低。 两数据集兴趣点检测结果分别如图5和图6所示。从图5和图6可直观看出,DMDO挖掘兴趣点的准确性较高。 图5 数据集AMSA兴趣点标注及挖掘结果图Fig.5 Extracted and predicted results of interest points on dataset AMSA 图6 数据集IMIS3Days兴趣点标注及挖掘结果图Fig.6 Extracted and predicted results of interest points on dataset IMIS3Days 实验结果表明,本文提出的DMDO能够快速、准确挖掘出研究区域的真实兴趣点。相比DBSCAN算法,对于数据集AMSA,准确率平均提高17.94%,算法效率提高6.63倍;对于数据集IMIS3Days,准确率平均提高19.98%,算法效率提高9.13倍。相比OPTICS算法,对于数据集AMSA,准确率平均提高20.04%,算法效率提高14.61倍;对于数据集IMIS3Days,准确率平均提高16.60%,算法效率提高42.19倍。 本文旨在研究准确、高效的兴趣点检测方法。传统算法易将移动对象偶然的停留误判为停留点,兴趣点检测的准确性较低,并且对停留点聚类的时间复杂度较高,时间开销大。针对传统算法的不足,本文提出了DMDO,通过矩阵二值化操作滤除停留点噪声,提高算法准确性,并用膨胀运算替代聚类算法提高算法效率。在开放空间数据集AMSA和IMIS3Days上进行实验,得到如下结论: 1)DMDO在预测准确性方面表现出显著优势。相比DBSCAN算法,在数据集AMSA上准确率平均提高17.94%,在数据集IMIS3Days上准确率平均提高19.98%;相比OPTICS算法,在数据集AMSA上准确率平均提高20.04%,在数据集IMIS3Days上准确率平均提高16.60%. 表明本文提出的二值化操作滤除停留点噪声的力度更强。 2)DMDO在保证预测准确性的同时,大幅降低了时间开销。相比DBSCAN算法,在数据集AMSA上算法效率提高6.63倍,在数据集IMIS3Days上算法效率提高9.13倍。相比OPITCS算法,在数据集AMSA上算法效率提高14.61倍,在数据集IMIS3Days上算法效率提高42.19倍。表明算法适用于解决大数据背景下的移动对象兴趣点检测问题。 未来的研究工作包括: 1)DMDO适用于开放空间的兴趣点检测问题,应用于城市轨迹数据时,易将城市路口误判为兴趣点,在未来工作中将扩展算法的适用范围。 2)将研究区域兴趣点划分层次,例如划分为重要、较重要、非重要兴趣点等,将算法扩展为分层次检测兴趣点的方法。 References) [1] Danalet A, Farooq B, Bierlaire M. A Bayesian approach to detect pedestrian destination-sequences from WiFi signatures[J]. Transportation Research Part C: Emerging Technologies, 2014, 44: 146-170. [2] Liao L, Fox D, Kautz H. Extracting places and activities from GPS traces using hierarchical conditional random fields[J]. International Journal of Robotics Research, 2007, 26(1): 119-134. [3] Cao X, Cong G, Jensen C S. Mining significant semantic locations from GPS data[J]. Proceedings of the VLDB Endowment, 2010, 3(1): 1009-1020. [4] Qi L, Zheng Z. Trajectory prediction of vessels based on data mining and machine learning[J]. Journal of Digital Information Management, 2016, 14(1): 33-40. [5] 乔少杰, 李天瑞, 韩楠, 等. 大数据环境下移动对象自适应轨迹预测模型[J]. 软件学报, 2015, 26(11): 2869-2883. QIAO Shao-jie, LI Tian-rui, HAN Nan,et al. Self-adaptive trajectory prediction model for moving objects in big data environment[J]. Journal of Software, 2015, 26(11): 2869-2883.(in Chinese) [6] Li Y, Guo A, Liu S, et al. A location based reminder system for advertisement[C]∥Proceedings of the 18th ACM International Conference on Multimedia. NY, US: ACM, 2010: 1501-1502. [7] Chung J, Schmandt C. Going my way: a user-aware route planner[C]∥Proceedings of the SIGCHI Conference on Human Factors in Computing Systems.NY, US: ACM, 2009: 1899-1902. [8] Zheng Y, Zhang L Z, Ma Z X, et al. Recommending friends and locations based on individual location history[J]. ACM Transactions on the Web (TWEB), 2011, 5(1): 5. [9] 杨洁. 基于历史轨迹的位置预测方法研究[D]. 杭州:杭州电子科技大学, 2015. YANG Jie. The research on technologies of predicting next location based on historical trajectory[D]. Hangzhou:Hangzhou Dianzi University, 2015.(in Chinese) [10] Xie K, Deng K, Zhou X. From trajectories to activities: a spatio-temporal join approach[C]∥Proceedings of the 2009 International Workshop on Location Based Social Networks.NY, US: ACM, 2009: 25-32. [11] Agamennoni G, Nieto J, Nebot E. Mining GPS data for extracting significant places[C]∥IEEE International Conference on Robotics and Automation. NJ, US: IEEE, 2009: 855-862. [12] Zheng Y, Zhang L Z, Xie X, et al. Mining interesting locations and travel sequences from GPS trajectories[C]∥Proceedings of the 18th International Conference on World Wide Web. NY, US: ACM, 2009: 791-800. [13] Luo T, Zheng X W, Xu G L, et al. An improved DBSCAN algorithm to detect stops in individual trajectories[J]. ISPRS International Journal of Geo-Information, 2017, 6(3): 63. [14] Ashbrook D, Starner T. Using GPS to learn significant locations and predict movement across multiple users[J]. Personal and Ubiquitous Computing, 2003, 7(5): 275-286. [15] Palma A T, Bogorny V, Kuijpers B, et al. A clustering-based approach for discovering interesting places in trajectories[C]∥Proceedings of the 2008 ACM Symposium on Applied Computing. NY, US: ACM, 2008: 863-868. [16] Zimmermann M, Kirste T, Spiliopoulou M. Finding stops in error-prone trajectories of moving objects with time-based clustering[M]. Berlin, Germany: Springer, 2009: 275-286. InterestPointDetectionMethodBasedonDilationOperation WANG Qing1,2,3, DING Chi-biao1,3, FU Kun1,2,3, REN Wen-juan1,2,3 An interest point detection method based on dilation operation (DMDO) is proposed to improve the efficiency and accuracy of interest point detection, in which binarization is used to filter the noise, and the dilation operation is used to replace the clustering approach to enhance the efficiency of algorithm. DMDO is applied to two datasets of open space-AMSA and IMIS3Days. Compared to Density-Based Spatial Clustering of Applications with Noise (DBSCAN) , the accuracy of DMDO is increased by 17.94% on dataset AMSA, and by 19.98% on dataset IMIS3Days, while the efficiency is improved by 6.63 times on dataset AMSA, and by 9.13 times on dataset IMIS3Days. Compared to Ordering Point To Identify the Cluster Structure (OPTICS), the accuracy of DMDO is increased by 20.04% on dataset AMSA, and by 16.60% on dataset IMIS3Days, while the efficiency is improved by 14.61 times on dataset AMSA, and by 42.19 times on dataset IMIS3Days. Experimental results demonstrate that, compared with traditional methods, DMDO has higher accuracy with less time overhead. DMDO is applicable to detect the interest points in the era of big data. information processing technology; trajectory data mining; interest point detection; dilation operation; open space 2017-04-13 王清(1992—),女,硕士研究生。E-mail: wangqing36@126.com 丁赤飚(1969—),男,研究员,博士生导师。E-mail: cbding@mail.ie.ac.cn TP181 A 1000-1093(2017)10-2041-07 10.3969/j.issn.1000-1093.2017.10.021
2 DMDO实验结果与分析


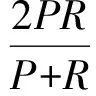
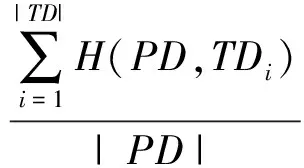

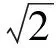




3 结论
(1.Institute of Electronics, Chinese Academy of Sciences, Beijing 100190, China; 2.Key Laboratory of Technology in GEO-Spatial Information Processing and Application System, Chinese Academy of Sciences, Beijing 100190, China; 3.School of Electronic, Electrical and Communication Engineering, University of Chinese Academy of Sciences, Beijing 100049, China)
