基于并行编程模型的SPECK 2n算法实现与优化
2017-10-12程雨芊
◆程雨芊
(山东大学(威海)网络与信息管理中心 山东 264200)
基于并行编程模型的SPECK 2n算法实现与优化
◆程雨芊
(山东大学(威海)网络与信息管理中心 山东 264200)
SPECK 2n算法是一种典型的轻量级分组密码算法,具有较强的灵活性和安全性,广泛应用于数据加密,以保证数据的完整性和可靠性。为了应对大数据的加密,本文提出一种基于 MPI+OpenMP的混合并行编程模型,可以充分利用分布式存储模型和共享存储模型的特点来优化加密过程,并基于山东大学(威海)超级计算中心集群进行测试。实验结果表明,优化后的并行SPECK 2n算法达到了较高的加速比,能够有效处理大数据量的实时加密,极大地提高了计算效率。
并行编程;密码算法;分布式存储模型;共享存储模型
0 引言
SPECK 2n系列密码算法是由美国国家安全局(NSA)设计,在 2013年发布的具有 Feistel结构的轻量级分组密码算法[1]。SPECK系列分组密码算法的分组长度为32、48、64、96或128比特,密钥长度为64、72、96、128、144、192或256比特,即分组长度和密钥长度可变,有利于在不同的软件平台上实现,具有很强的应用灵活性。同时 SPECK算法有较强的安全性,虽然针对 SPECK系列密码算法已经有了一些安全性分析结果,如Farzaneh Abed等人提出的飞去来器攻击和矩形攻击[2]、Alex Biryukov等人提出的差分攻击[3]以及由Itai Dinur改进的差分攻击[4]等,但目前还没有全轮数的SPECK算法安全性分析。
在大数据快速发展的形势下,如何保证大数据的安全性和可靠性,是很多数据型企业所关心的问题。SPECK 2n算法作为轻量级的分组密码算法,主要用于对数据的快速实时加密,对加密的效率有一定的要求,因此并行化的SPECK 2n算法实现逐渐受到重视。
高性能计算作为一个新兴科学,致力于研究高效能的并行计算,对于科学实验模拟计算和大数据分析等起到了推动作用。利用高性能计算可以提高计算效率,节约时间和资源,满足大数据环境下的计算需求。高性能计算的实现方式主要有两种,一种是充分利用CPU本身的资源进行并行计算,如OpenMP多线程并行、MPI多进程并行等;另一种是利用加速卡进行辅助计算,如NVIDIA公司的GPU加速卡和Intel公司的MIC加速卡等。
本文提出一种基于MPI+OpenMP并行编程模型的SPECK 2n算法实现,将待加密的明文数据进行分块,然后使用MPI进程并行和OpenMP线程并行嵌套完成加密算法。经实验验证,将多进程并行与多线程并行结合起来的层次化并行方法能够取得较好的加密效率。
1 并行编程模型介绍
并行编程模型根据内存模型的不同,主要分为共享存储模型和分布式存储模型两种。共享存储的并行编程模型具有单一内存地址、易编程、可扩展性较差等特点,适合中小规模的计算,主要实现的方式有OpenMP、PThread、X3H5等;分布式存储的并行编程模型又称为消息传递模型,具有地址空间独立、编程复杂、可扩展性较好等特点,适合大规模的并行计算,主要的实现方式有MPI、PVM等。消息传递模型与多线程编程模型组合而成的混合编程模型更适用于大数据环境下的多层次、可扩展的并行算法[5-6]。
MPI消息传递模型适合并行计算粒度大的算法,要求用户适当地分解计算数据,不同的节点之间可以进行灵活地进行数据交换。MPI主要使用函数接口实现并行环境初始化以及消息传递等功能。OpenMP多线程编程模型适合细粒度的并行算法,利用编译指导语句#pragma实现线程的Fork-Join以及参量的属性设置,共享的内存可以避免不必要的数据交换,提高算法的执行效率。因此 MPI+OpenMP并行编程模型能够同时结合分布式存储和共享存储的优势,充分利用计算集群的节点间和节点内的两级并行来进行算法实现。
2 SPECK 2n算法
2.1 SPECK 2n算法介绍
SPECK 2n系列密码算法是由Ray Beaulieu等人在2013年提出的一种轻量级分组密码算法,密钥长度和分组长度均不固定,可以根据具体的安全性要求、性能要求以及应用环境等来选择合适的分组长度和密钥长度。SPECK 2n系列密码算法的十个典型实例算法如表1,其中n表示字长,单位为比特(bit),m表示主密钥的字数,α和β表示循环移位的参量,T为加密的轮数;分组长度即为输入明文和输出密文的比特数,密钥长度为主密钥的比特数,α、β和T是加密算法函数中的参数。

表1 SPECK 2n算法的参数设置
SPECK 2n算法主要包括两个部分:加密主函数和密钥扩展函数。加密主函数用来进行明文的加密操作,输出相应的密文;密钥扩展函数将输入的主密钥扩展成T个轮密钥,用于主函数运算。加密主函数由T轮的轮函数组成,SPECK 2n算法的轮函数主要由循环移位操作、异或运算和域上的模加运算组成,第i轮加密函数为:

其中Xi和Yi是第i轮加密的输入分组,Xi+1和Yi+1是第i轮加密的输出分组,Ki表示第i轮的子密钥,长度均为n比特;>>>和<<<表示按比特位的循环右移和循环左移,表示域上的加法运⊕算, 表示按比特位的异或操作。
SPECK 2n系列密码算法的密钥扩展函数利用轮函数来生成轮密钥,输入为主密钥输出为T个轮密钥用于每一轮的加密运算。对于所有的计算ki和li的公式如下:

2.2 并行SPECK 2n算法的基本原理
根据SPECK 2n算法的轮函数结构可以看出,SPECK 2n算法先将数据进行分块,然后每个数据块分别进行对应轮数的加密计算,除了对密钥扩展函数、主密钥和轮密钥比特进行读取外,各个数据块间的加密操作互不影响,加密顺序也无依赖性。因此,对于密钥相同的待加密数据,可以进行节点内的并行加密运算;对于密钥不同的待加密数据,可以进行节点间的并行加密运算。
3 基于并行编程模型的SPECK 2n算法
单机环境下,串行的SPECK 2n算法主要采用迭代方式实现,多次读取更新密钥比特来进行不同密钥的明文数据的加密计算。算法计算的核心内容是轮函数的实现,对于所有明文数据分组,进行T轮的计算,得到密文数据分组。本文采用MPI分布式存储模型优化数据分块和轮函数,进而再结合OpenMP共享存储模型进一步改进SPECK算法。
3.1 基于MPI的并行SPECK 2n算法
根据SPECK 2n算法轮函数的特点,基于MPI的并行SPECK算法实现主要对输入数据进行分块处理,由主进程进行整体的逻辑控制,开启多个进程并发执行每个数据分组的轮函数计算。相同密钥的数据加密算法分为两个部分:第一部分是根据主密钥生成轮密钥,第二部分是使用轮密钥进行数据加密。每一部分数据加密完成后,要将明文和密文数据对应输出到文件,以便于进行算法结果的验证。
3.2 基于MPI+OpenMP的并行SPECK 2n算法
在上述基于MPI并行的SPECK 2n算法的基础之上,当同一密钥加密的数据量很大时,可以构建基于MPI和OpenMP的混合编程模型,同时实现多进程和多线程的编程。每个MPI进程内部发散出多个线程,同时对多个数据分组进行重复的轮函数运算,可以极大地提高计算效率。
计算数据分块的主要依据是加密所使用的密钥和SPECK 2n实例算法的字长等参量,对于不同密钥加密的数据,可以采用MPI多进程并行的方式;对于同一密钥加密的数据,可以采用OpenMP多线程并行,减少密钥交换次数和密钥扩展函数的使用次数。
4 测试环境与结果分析
4.1 测试环境介绍
山东大学(威海)超级计算中心集群采用 CPU+GPU+MIC 的三重异构架构,计算节点+胖节点混合的体系结构。配置了1台管理节点和1台登录节点。计算资源包括34台CPU计算节点、1台胖节点、2台GPU节点和2台MIC节点。集群总计856个CPU计算核心,CPU的计算能力为32Tflops(每秒计算32万亿次), 2台GPU节点计算能力为4.6Tflops,2台MIC节点计算能力为4.8Tflops。集群使用了全互连无阻塞的Infiniband 56Gb FDR高速计算网络和千兆的高速管理和监控网络。采用了lustre并行文件系统,并行存储裸容量为200TB。
在此计算平台上,使用 CPU计算节点进行实验测试。每个CPU节点包含1个Intel(R) Xeon(R) CPU E5-2660 v3 @ 2.60GHz处理器(20个逻辑CPU),操作系统版本为Red Hat Enterprise Linux Server release 6.5,已配置好MPI和OpenMP的并行环境,编译器为icpc version 15.0.1和impi 5.0.2.044,程序采用C++语言编写,每个节点启动一个MPI进程,每个MPI进程在OpenMP并行区域内最多启用8个OpenMP线程组。
4.2 测试结果与分析
通过对串行算法(SPECK)、基于 MPI的并行算法(MPI-SPECK)、基于 MPI+OpenMP的并行算法(MPI/OpenMP-SPECK)三种算法实现的性能进行比较,来分析多层次并行加密计算的优势和效率。
实验确定以SPECK 32/64算法为例进行测试分析,对应的参量α和β值为7和2,轮数T为22,选取了三组不同的输入明文数据量,分别为2MB、32MB和512MB,每组进行7种实验,使用的CPU节点数目为单节点、4节点和8节点,实验的详细说明如表2所列:
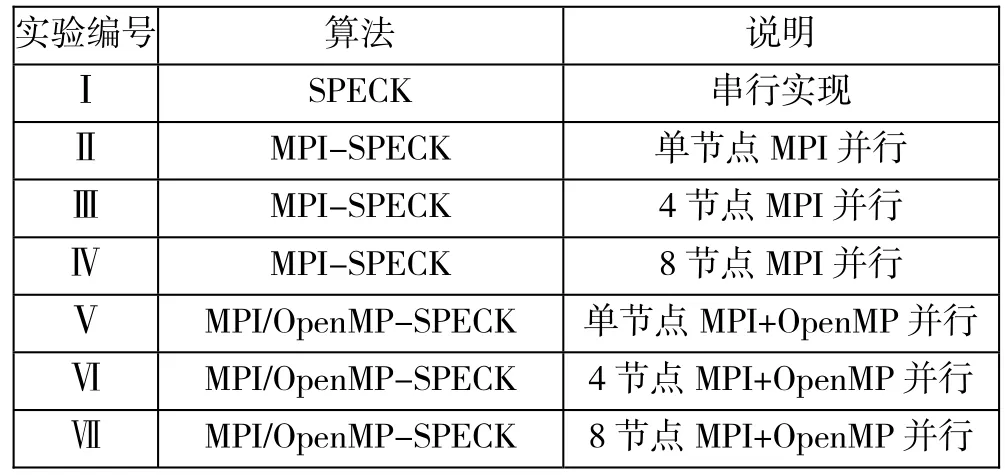
表2 实验详细说明
实验对算法运行时间进行了记录,结果如表3所列。

表3 算法运行时间(单位:s)
加速比是衡量算法并行化性能和效果的标准,加速比指的是同一个算法在单处理器系统和并行处理器系统中运行所消耗的时间的比率。根据表3列出的运行时间,可以计算出三种数据量对应的不同编程模型的加速比,结果如图1所示。
对不同数据量的明文进行加密测试实验表明,并行编程的加速比优势十分明显。从图1可以看出,基于MPI并行模型的计算时间较基于MIP+OpenMP混合并行模型的计算时间略高,这是由于算法实现中存在部分共享常量,使用OpenMP多线程并行可以避免不必要的数据交换,提高执行效率。

图1 运行时间的加速比
5 结束语
本文实现了基于MPI+OpenMP的并行SPECK 2n算法,并通过多种实验验证,基于混合编程模型的算法实现具有较高的加速比,能够充分结合分布式存储和共享存储的优势,提高计算效率。但同时层次化的并行编程模型也存在着一些问题,比如OpenMP线程在 Fork-Join时产生的系统开销问题、MPI进程间的数据传输优化问题等。最后,感谢山东大学(威海)超级计算中心的计算支持和帮助。
[1]Ray Beaulieu, Douglas Shors, Jason Smith, etc. The SIMON and SPECK Families of Lightweight Block Ciphers[R].Cryptology ePrint Archive, 2013, Report 2013/404:http://eprint.iacr.org/.
[2]Farzaneh Abed, Eik List, Jakob Wenzel, etc. Differential Cryptanalysis of round-reduced Simon and Speck[R]. Fast Software Encryption,2015.
[3]Alex Biryukov, Arnab Roy, and Vesselin Velichkov.Differential Analysis of Block Ciphers SIMON and SPECK[R].Fast Software Encryption,2015.
[4]Itai Dinur. Improved Differential Cryptanalysis of Round-Reduced Speck[R]. Selected Areas in Cryptography-SAC 2014.
[5]唐兵,Laurent BOBELIN,贺海武.基于 MPI和 OpenMP混合编程的非负矩阵分解并行算法[J].计算机科学,2017.
[6]冯云,周淑秋.MPI+OpenMP混合并行编程模型应用研究[J].计算机系统应用,2006.
[7]宋鹏,解闯,李金山等.基于 MPI+OpenMP的三维声波方程正演模拟[J].中国海洋大学学报自然科学版,2015.
[8]周文.基于众核架构的 BP神经网络算法优化[J].电子世界,2017.
