基于事件图的在线事件检索
2017-10-11杨文静邱泳钦李思旭
杨文静,邱泳钦,李思旭,李 锐,王 斌
(1. 中国科学院 信息工程研究所,北京 100093;2. 中国科学院大学,北京 100093)
基于事件图的在线事件检索
杨文静1,2,邱泳钦1,2,李思旭1,2,李 锐1,王 斌1
(1. 中国科学院 信息工程研究所,北京 100093;2. 中国科学院大学,北京 100093)
在线事件检索是针对事件查询,按时间序迭代返回小批量数据集中事件相关文档的检索任务。其目标是在时间轴上不断收集新鲜的事件文档,是进行一系列事件相关工作的重要基础。面对此任务,传统方法采用先进的检索模型来提升检索精度,然而却没有考虑事件本身的特性。针对这一问题,该文尝试使用两类图(事件关键词共现图、融合事件类型的二部图)对事件建模,提出了一种基于事件图的在线检索框架。案例分析与在两个公开的TREC数据集上的实验结果表明,该文方法显著提升了事件检索精度(P@10最高增幅达30%,平均增幅5.85%),且能自适应在线检索环境,支持事件的演变分析。
事件图;在线事件检索;事件查询模型;事件演变
Abstract: Online Event Retrieval is a retrieval task for event queries, which returns important event-related documents from mini-batch data sets iteratively in chronological order. This paper propose san online event retrieval framework based on two kinds of graphs: event key-words co-occurrence graph and bipartite graph incorporated with event type. Case study and experiments on two pubic TREC corpus indicate that our approach improves the event retrieval precision significantly (maximum increase reaches 30%, average reaches 5.85% in metric P@10).
Key words: event graph; online event-based retrieval; event query model; event development
1 引言
事件是指在特定时间、特定地点发生的事情[1]。如今,现实生活中一旦发生重大公共事件(如地震、暴乱、恐怖袭击等),人们立即被源源不断的来自新闻媒体的相关报道、各大社交平台的有关评论所湮没。事件检索[2]是面向事件查询(常以事件名称为查询,如“汶川大地震”)的检索任务。事件在时间轴上不 停 演 变,事 件 查 询 的 信
息需求是动态的,使得相同事件在不同时刻的相关文档集合及集合内部排序并非一成不变。在线事件检索(online event-based retrieval,OER)便是针对特定事件,按时间序迭代地在每个时间单元的小批量数据集中进行事件检索,得到每个时间间隔的重要相关信息。
OER与信息检索(information retrieval,IR)、信息过滤(information filtering,IF)及事件追踪(event tracking,ET)对应的问题都非常相似,但在数据的到来方式、输入与输出等方面都存在一定的差异,研究重点及应用场景也不尽相同,如表1所示。OER与ET皆以演变的事件为研究对象,因此在事件表示、自适应事件模型等方面存在共通技术。OER侧重研究自适应的事件模型如何作用于检索的各个阶段(索引构建,查询重构,相关反馈,相似性度量,结果重排等)以提升演变事件的检索精度。ET侧重自适应过滤。从应用场景来说,OER提供演变事件的最新检索结果,可用于新闻事件的实时搜索,也可为后续事件分析(事件摘要、事件演变分析)提供当前最相关的文档输入。而ET从数据流中过滤得到所有事件相关文档,进行事件模型的维护与分析。

表1 OER与相似任务的对比
针对上述任务,传统方案是采用state-of-the-art的检索模型,但在事件检索、在线自适应方面存在缺陷。本文在分析传统检索方法缺陷的基础上,提出了一种基于事件图的在线事件检索框架。其核心思想是使用图的方式对事件进行建模,通过在图中累积历史检索结果中事件相关知识作为反馈,当新批量数据到来时,将事件的先验信息融入到检索过程。经实验证实,本方法具有如下优点: (1)提升事件检索精度; (2)自适应在线环境; (3)事件图可支持事件的演变分析。
如图1所示,框架共包含三个重要步骤: (1)估计事件查询模型; (2)检索事件相关文档; (3)更新事件图。本文组织形式如下,第二节介绍相关工作;第三节介绍事件查询模型的估计及检索过程,即步骤(1)、(2);第四节介绍事件图的更新并对框架进行总结;第五节案例分析;第六节介绍实验设置、评价,并进行实验结果分析;第七节结论。
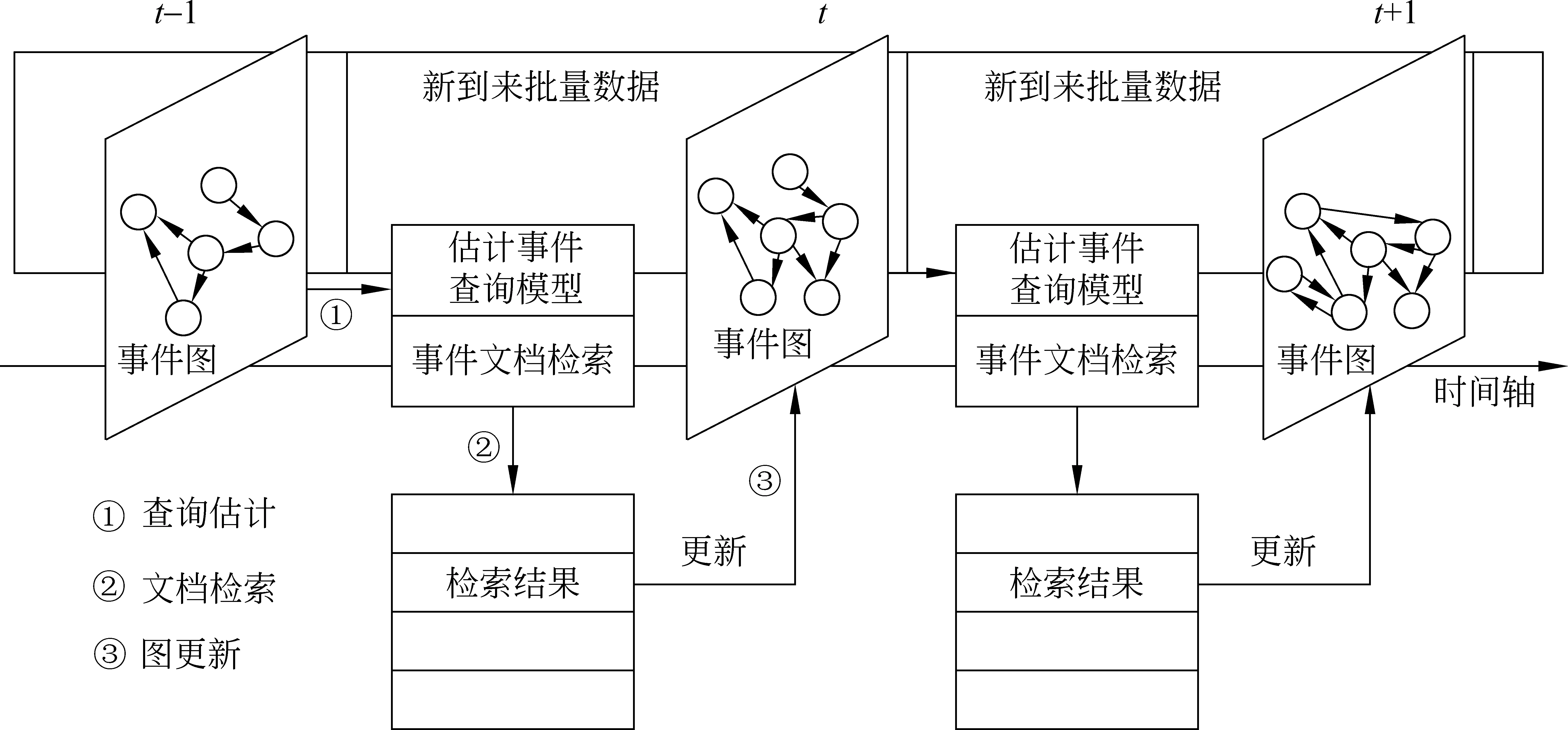
图1 基于事件图的在线事件检索框架
2 相关工作
在已有的少量事件检索研究中,有借助于NLP工具对事件进行语义角色标注[2],也有将查询与文档用图表达,使用graph kernel计算二者相似性[3]。但上述方法都较复杂,可行性差。在大多数事件检索场景下,最为常用的方式依然是使用通用检索模型结合伪相关反馈的方式。
清晰地表达信息需求(information need)是精准检索的重要前提。查询模型最早在研究[4]中提出,其目标是在基于语言模型的检索方法中更好地将用户查询上下文、反馈信息等融入到查询中。已有的查询模型估计方法,如Relevance Model[5-6]、Divergence Minimization Model[7]、Mixture Model[5]、Marchov Chain[4]等以不同的原理都试图从伪相关反馈文档集合中抽取出与查询相关的重要词汇,对原始查询模型进行重新估计。但上述方法在事件检索中表现不佳,主要原因在于查询中缺乏事件信息,使得首次检索过程生成的伪相关反馈文档集合存在大量非事件相关的噪声,使得用于重新估计查询模型的信息不够可靠。
针对此问题,我们通过对事件建模,并将事件模型融入到查询中来进行探索研究。在(EDT)(event detection and tracking)的相关研究中,基于图的事件建模方法广泛使用。Sayyadi[8]等使用KeyGraph捕获关键词的共现信息,Weng[9]等使用小波变化将词语共现转化为信号并计算信号的cross-correlation关系图,最后基于图使用community detection算法得到各个子簇表示不同事件。Fukumoto[10]等基于KeyGraph研究事件追踪过程中的话题漂移现象。上述建模方法皆基于图分割算法发掘子簇对事件进行表达,然而图分割算法十分费时,难以应用于在线环境。本文将事件建模成为一元语言模型,并基于两类事件图进行简单的模型估计,可得到较为准确的事件描述。
3 估计事件查询模型
3.1 事件图
3.1.1 事件关键词共现关系图 事件可由具有事件区分力的单词聚集在一起来共同刻画。将出现在原始事件查询中的词语视为种子词汇,基于关联假设[11]: “如果一个词语具有区分相关与非相关文档的能力,那么它的近邻词汇都可能擅长于此。”所以可挑选与种子词汇相邻共现的候选词对关系图进行更新。事件关键词共现的事件图(event graph based on co-occurrence,简称EG_co或共现图)是一个有向图,如图2(a)所示。EG_co=G
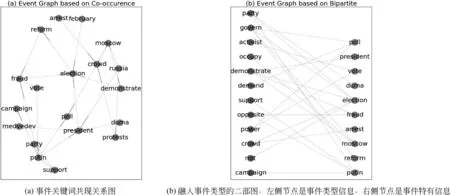
图2 “Russia Protests”事件图
3.1.2 融入事件类型的二部图
事件可由两部分信息共同刻画,事件特有信息(时间、地点、起因等)和事件类型信息(一类事件共有的属性)。如事件“Russia Protests”,在表达这一特定事件时,“demonstrate”“opposite”等关键词描述的是抗议类事件的共有特征。而该事件特有信息来自于“election”“fraud”等关键词,表明抗议与俄罗斯作弊选举相关。据此,我们将事件建模成一个二部图,EG_bi=(U,V,E),融入事件类型的二部图(event graph based on bipartite,简称EG_bi或二部图),如图2(b)所示,拥有两种节点类别U、V,分别表示事件特有信息和事件类型信息,以及连接两部分节点的边E。u∈U,v∈Veuv=1表明节点u和v共现于同一句子中。类似3.1.1节所述,其每一条边也具有同上的两个属性。
3.2 事件模型
假设每个特定事件都存在一个精确的一元语言模型θE。准确估计p(w|θE)的困难在于无法获取足够多的训练语料。为了近似估计p(w|θE),我们从另一个角度假设事件模型是一个混合模型,具有事件区分力的词语以高概率与背景模型融合而得,并希望融合后的概率分布能显著地描述特定事件。混合模型由背景部分θBG和事件部分组成,θBG可从语料中统计得到,事件部分所需信息可从上文提及的事件图获取,如式(1)所示。
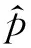
(1)
显然,估计p(w|θE)的关键步骤在于如何基于事件图估计p(w|θEG)。
3.2.1p(w|θEG)——基于事件关键词共现关系图的概率估计 考虑到需要融入节点的相互依赖关系,我们使用PageRank的方法来估计p(w|θEG)。在事件关键词共现关系图中生成的稳态概率能较准确地反映各关键词对于事件的重要程度。形式化如下,
(2)
其中节点间的转移概率puw=α1×cu.w/odu=α1×wu,w,α1是继续游走概率(walk continuation probability),p{ξn=w}是n时刻随机游走止于节点w的概率。πw是随机游走的稳态概率,存在∑wπw=1。
3.2.2p(w|θEG)——基于融入事件类型二部图的概率估计 事件的准确描述离不开二部图中的两个部分,事件特有信息(eventspecificinformation,ES)及事件类型信息(eventtypeinformation,ET)。固有:
p(w|θEG)=λp(w|θES)+(1-λ)p(w|θET)
(3)
θET可通过收集统计同一事件类型的语料得到。估计θES,首先采用“资源-分配”的方式[12]将二部图投影到ES集合上,根据协同思想,ES与ET两部分的关系能映射为ES集合中任意两点间的关联。如式(4)所示。
(4)
其中wu,k=cu,k/odu是边权重,式(4)的物理意义在于,ES中任意两点通过ET能够相互分享到更多资源,两点关系就越紧密。基于式(4)能得到ES集合内任意两点间的权重矩阵。类似地,根据式(2),便能得到WS集合中各点的稳态概率值,即p(w|θES)的估计值。
3.3 事件查询模型
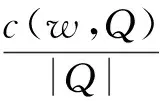
(5)
在概率距离检索框架[4]下,式(6)计算两个概率分布θQ和θD的负KL距离(Kullback-Leibler divergence)来衡量文档与查询的相似程度。在事件查询模型中,大量事件信息融入到查询中使得事件相关的文档排序靠前,从而提升了事件检索的精度。
(6)
4 在线事件检索框架
在第三节阐述了图1框架中①、②两个步骤。本节提出事件图在事件轴上的更新算法,并对在线事件检索框架进行总结。
4.1 事件图更新
在线环境下,我们假设在历史检索单元中得到的检索结果是事件相关的,如算法1,在时刻t,使用t-1时刻的检索结果对事件图扩充并适当裁剪。事件种子词集合(original kernel set,OKS)由原查询词及它们的同义词构成。经去停用词、Porter算法词干还原后,至少包含一个种子词汇的句子被挑选用于事件图扩充。节点使用中心性度量进行裁剪。每一条边具有生命周期,自创建时刻起在图中的生存长度为定值,即对事件图的观察窗口大小(observation window size,OWS),一旦过时,则将被移除,此即PruningEdges函数的功能。
算法1 事件图更新算法
输入: 上一时刻检索结果Rt-1, 事件查询Q, 上一时刻事件图Gt-1,节点中心性阈值NODE_THRESHOD, 观察窗口大小 OWS,
输出: 当前时刻事件图Gt
1. IFt=1 THEN
2.G1,OKS=initialed withQ
3. ELSE
4. FORdocbelong toRt-1
5. FORsentbelong todocIF termInOKS(sent) is ture
6.Gt=Gt-1.EnrichWith(sent);
7. END FOR
8. END FOR
9.Gt.PruningEdges(OWS);
10.Gt.PruningNodes(NODE_THRESHOD);
11.Gt.NormalizingWeight();
12. RETURN Gt
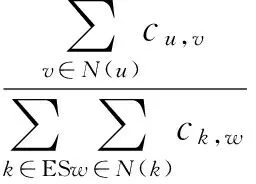
4.2 在线事件检索框架
2.3.4 稳定性 取精密度试验配制的样品溶液,放入样品盘后,按色谱方法,样品盘设置温度为15℃,于15 min、30 min、60 min、3 h、5 h、7 h测定峰面积,考察各目标物的稳定性。结果表明:各目标物峰面积并未明显减少,说明各目标物经强酸处理后,由于溶液中大部分酶被灭活,低温环境下溶液相对稳定。结果如图2所示。
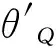
k是观察窗口的大小,φ函数使用历史检索结果更新事件图。Rt(t>0)是t时间间隔的检索结果,由检索函数φ生成。R0是无意义的,为了统一表达,设定R0=Q。在此框架下,当前时刻的检索过程,借助事件图这一信息容器,间接地使用到了历史k个时间间隔的信息反馈。
5 案例分析
本节以事件查询哥斯达协和号(Costa Concordia)*http: //en.wikipedia.org/wiki/Costa_Concordia_disaster”为例,从查询模型、检索结果两个方面进行分析,并进一步展示事件图在时间轴上捕获事件的演变。
5.1 查询模型对比
图3展示了事件查询“Costa Concordia”在时间间隔2012-01-14-11(约时间发生后的13个小时)中的RM1,EM_co,EM_bi和背景语料(Background,简称为BG)的语言模型。取背景语料的前300个词,皆以logp(w|θBG)降序排列。在图3上子图中曲线即为背景语言模型,下子图中分别对应绘制了RM1,EM_co,EM_bi。在背景模型曲线上散布的点,是EM与RM1的差异点。这些点在EM中,分配了足够的概率,但在RM1中却未被足够看重。
通过对图3的分析,我们可以得出以下两点观察: (1)EM曲线图相对于RM1的曲线变化更剧烈,同时与背景模型差异也更大,具有低歧义的特点; (2)差异点皆为具有事件区分力的关键词语,EM更具事件显著的特点。研究[13]表明,低歧义与事件显著的查询模型更可能取得较好的检索效果。
为了进一步地证实本文提出的EQM优于RM3,一种更为直接的方式是对比两种方法的检索结果。表2~4分别列出了RM3、EM_co、EM_bi三种查询模型在时刻2012-01-14-11下的Top 10检索结果列表。两名标注者根据文档中事件相关信息的密度及质量共同对结果集合的每一篇文档的事件相关度进行等级评定。使用NDCG作为综合量化评价指标。RM3返回较多仅部分内容相关的混合文档。表3和表4排序靠前的文章几乎都是事件相关的详细报道。综上,我们得出如下结论: 本文提出的事件查询模型,提升了查询对事件的表达能力,清晰的查询意图大幅提升了检索效果。
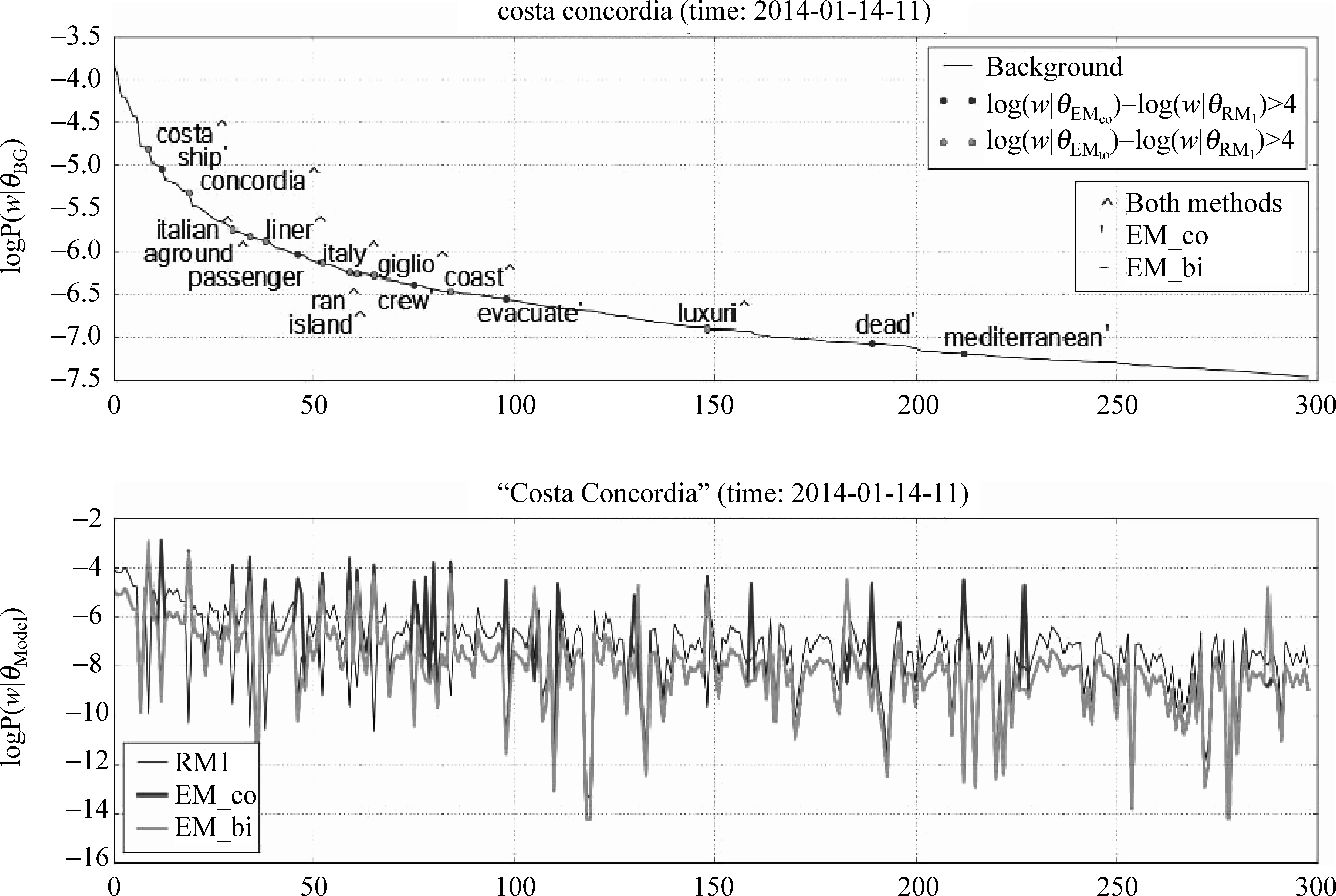
图3 “Costa Concordia”查询模型对比图

编号相关度摘要评价者备注1mediumCostaConcordiaranagroundofftheislandofGiglioPartialrelevance2highThreedeadinCostaCruiseshipincidentDetailreport3highThreedeadinCostaCruiseshipincidentDetailreport4mediumCruiseShipRunsAground,3BodiesFoundpartialrelevance5mediumSome30UkrainianswereonboardIndirectlydescription6lowCruiseCriticistheworld'slargestcommunityofpeoplewholovetocruise.Noise7lowSomeothernewsNoise8highItalianrescuersworktoremove3rdsurvivorfromcruiseshipthatranagroundDetailreport9mediumSixdeadascruiseshiprunsagroundoffItaliancoastPartialrelevance10mediumSixdeadascruiseshiprunsagroundoffItaliancoastPartialrelevanceNDCG@100.495
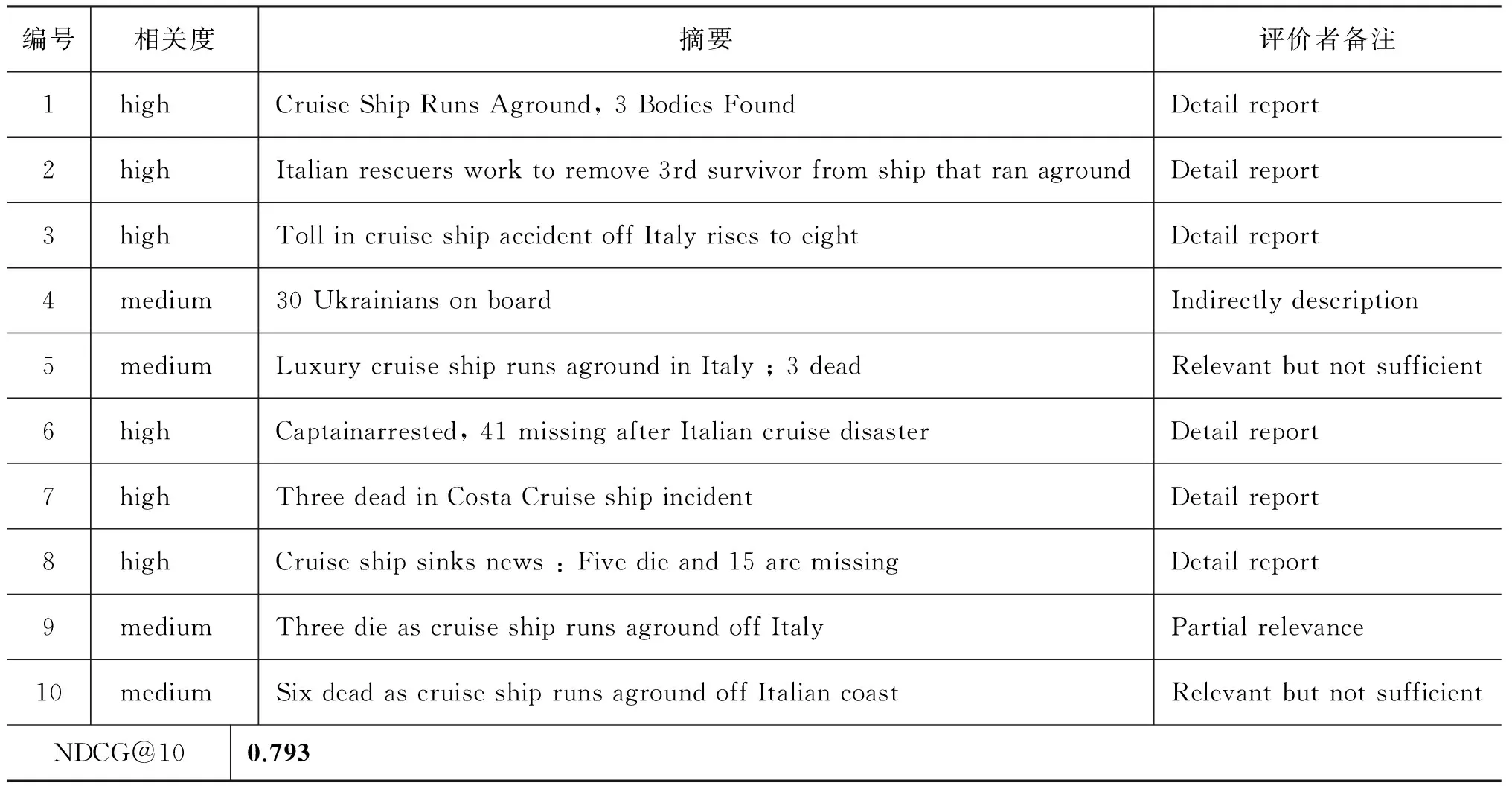
表3 EQM(基于共现图的事件查询模型)检索结果
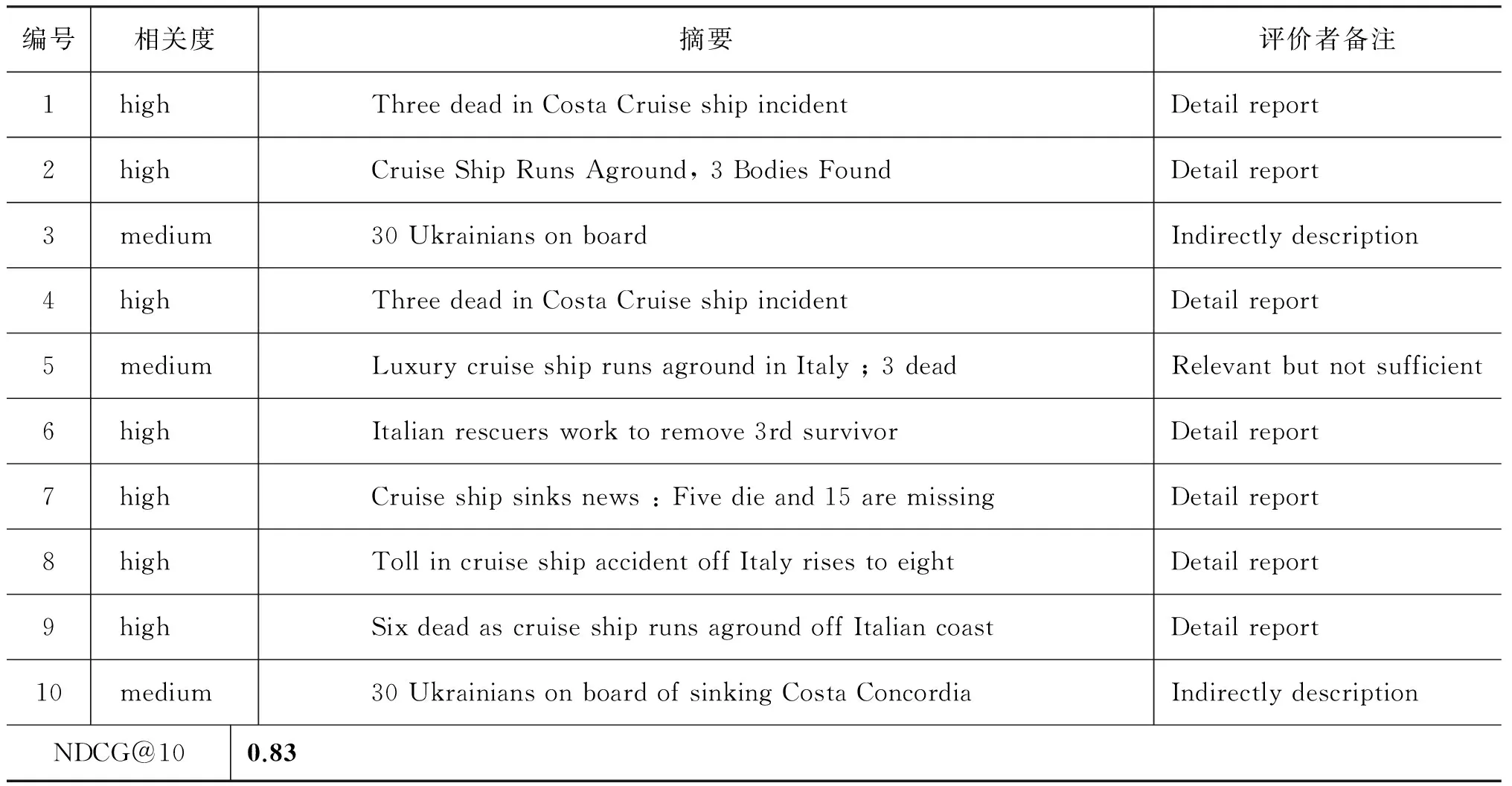
表4 EQM(基于二部图的事件查询模型)检索结果
5.2 事件图演化
在本文提出的检索框架中,事件图起到了最为核心的作用。其能稳定工作的关键前提在于: (1)需捕获事件的关键信息; (2)需随着事件演变而更新。为了证实事件图捕获关键信息的能力,及在时间轴上的信息变化,以“Costa Concordia”事件为例。事件初期的报道集中于事故基本信 息,哥 斯 达
协和号在Giglio岛触礁搁浅倾覆。紧急救援结束后,调查表明事故原因是船长Schettino的操作失误。事故后期,游轮所属公司发布了针对乘客和船员(大量菲律宾籍)的赔偿细节。在阅读维基百科该事件页面之后,了解到上述事件梗概各自对应的重要时刻(皆取上午11点)的事件图,得到事件模型的Top 10单词。如表5所示,可以看出,事件图很好地捕获到了事件关键信息,且及时地随着事件演变而变化。

表5 事件图演变
6 实验
6.1 数据集 据我们所知,目前在线事件检索任务暂无公开标准测试数据,传统TREC检索数据集缺乏事件在时间轴上的持续相关信息,不满足需求。本文采用标准公开的TREC时序摘要(temporal summarization,TREC-TS)任务[13]2013、2014两个数据集。数据包含了来自新闻媒体、社交网络、博客评论等数十种数据源。数据集相关统计信息如表6所示。针对每一个事件,给出了相应的查询、事件类型及事件起止时间戳。事件类型包括灾难、爆炸、人质等八种类型。针对每种事件类型,我们在维基百科中人工收集了20个该类型下的典型事件,用于统计生成二部图中事件类型模型。

表6 实验数据集基本信息
6.2 评价方式
针对每一个小时内的检索结果,人工判定文档的事件相关性,计算P@10、P@15。然而,仅TREC-TS 2014数据集便含有近3 000个小时的检索结果,人工评价如此庞大的结果集合几乎不可能。我们通过采样计算近似结果。采样过程如下,针对每个事件,大量噪声可能存在于事件起止端的检索结果,截断事件首尾(3%×该事件总持续小时数)后,均匀采样10个小时的数据作为待评价数据。在TREC-TS 2013、TREC-TS 2014数据集上,对8种检索方法生成的结果进行pooling(共约6 000篇文档),三名评价者独立地对数据池中所有事件的待评价数据进行相关性判定。对于每个事件查询,计算检索精度如式(10)所示,S为采样小时数(S=10),N为每次检索返回文档数(N=10或N=15)。
(10)
6.3 实验结果
本文实现了八种检索方法,其中EQM_co,EQM_bi分别是本文提出的基于共现图和二部图的方法,其余六种对比方法皆为带伪相关反馈的方法,其中基于语言模型的方法是RM3、RM4、Divergence Minimization Model(简称DivMin)、Mixture Model(简称Mixture),另外两种为TFIDF+feedback、BM25+feedback。为了对比的公平,本文方法和其他对比方法涉及的共有参数都采用相同设置。使用Dirichlet作为文档平滑方法,μ=1 000。原始查询模型插值参数α=0.5。伪反馈文档数目为10,选取反馈词数目为30。本文基于事件图的方法中,OWS=72,即3天,与背景语料模型插值系数β=0.7。共现图中NODE_THRESHOLD=0.03, 二部图中NODE_THRESHOLD=0.1,ES与ET插值系数λ=0.6。在Okapi BM25中,k1=1.2,b=0.75,k3=7。
如表7所示,EQM_co在TREC-TS 2014数据的P@10指标上,以0.434的效果超过位于第二名BM25方法约5.85%,EQM_bi以0.424超越BM25约3.4%。在P@15指标上,EQM_co以0.393居首,EQM_bi和TDIDF以0.384次之。在TREC-TS 2013集合上,EQM的方法P@10稍优于其他所有对比方法,在P@15上以0.185次优于RM4和DivMin。本文尝试的两种事件建模方法中,基于共现图的EQM_co是朴素且有效的,在TREC-TS 2014上EQM_bi的表现不及EQM_co,可能原因在于训练事件类型模型的语料不够充足,使事件模型估计有所偏差。
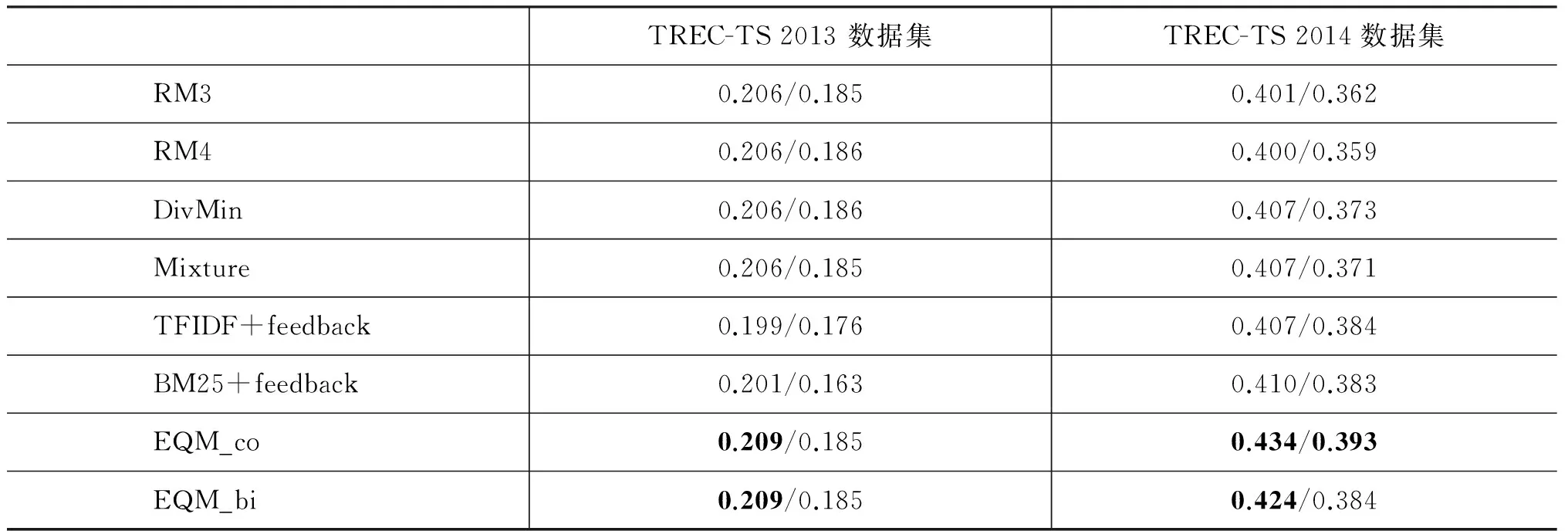
表7 检索方法在两个数据集的检索精度对比(P@10/P@15)
通过深入观察表现优异的查询在时间轴上的10次采样结果,得出另一重要结论: 在线事件检索框架中形成的前向正反馈提升了事件整体的检索精度。以TREC-TS 2014中的事件查询“Southern California Shooting”为例,10次采样结果如图4所示。较最优基准方法的P@10=0.34,EQM_co和EQM_bi在此查询的检索精度分别为0.46、0.41,分别提升了35.3%、20.6%。原因在于,EQM在事件后期其他方法效果急剧下降时,仍能保持较高的准确率。该现象能够通过前向正反馈加以解释。在其他方法中,各个时刻的检索相互独立,无前向反馈形成。在本文的检索框架中,倘若前几个历史时刻的检索结果精度较高,通过事件图的方式将正反馈知识前向传递到了当前时刻,使得此时的检索结果不至严重震荡。
同时我们也分析了另一类本文方法无优势的查询。大致有两种情形,第一种是数据集中存在极少的事件相关文档(在评价池中,相关文档占比不足1/10)。在此情形下,本文方法难以形成前向正反馈,事件图裁剪噪声困难,整体检索效果下降。另一种情况是数据集中存在充足的事件相关文档(在评价池中,相关文档占比超过8/10)。简单说来,检索方法几乎都能得到较高P@10。从数据集的角度分析,本文方法更适用于存在适量噪声的数据集。在现实应用场景中,这类居中的情形是占大多数的,即本文方法是普遍适用的。
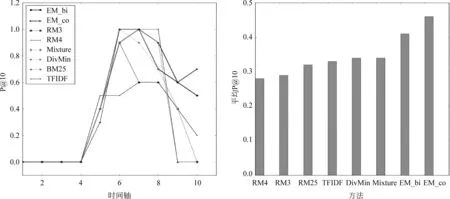
图4 查询“Southern California Shooting”采样点的检索精度
7 结论
在线事件检索是一项面向事件查询,在时间轴上迭代地检索出事件相关文档的任务。该任务能够为事件监测与事件研究提供有力的数据支撑。针对该任务,我们提出了一种基于图的在线事件检索框架。重点研究了基于事件关键词共现图和融合事件类型的二部图两类事件建模方法,并将事件模型融合到查询模型中,通过提升查询的事件区分力来提升单次事件检索的精度,并借助事件图在事件检索框架中构成前向正反馈,以提升整个时间轴的事件检索精度。案例分析表明: (1)本文的事件查询模型具有低歧义、事件显著的特点,相对于RM3,得到了更加精确的事件检索结果; (2)事件图能够随事件演变而变化。在两个公开实验数据集上的实验结果表明,本文方法针对事件查询,特别是模糊的事件查询,能够显著提升检索精度。
[1] Allan J, Papka R, Lavrenko V. On-line new event detection and tracking[C]//Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 1998: 37-45.
[2] Lin C H, Yen C W, Hong J S, et al. Event-based textual document retrieval by using semantic role labeling and coreference resolution[C]//Proceedings of IADIS International Conference WWW/Internet 2007, 2007.
[3] Glava G, Nnajder J. Event-centered information retrieval using kernels on event graphs[J]. Graph-Based Methods for Natural Language Processing, 2013: 1.
[4] Lafferty J, Zhai C. Document language models, query models, and risk minimization for information retrieval[C]//Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 2001: 111-119.
[5] Lavrenko V, Croft W B. Relevance based language models[C]//Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 2001: 120-127.
[6] Lv Y, Zhai C X. Positional relevance model for pseudo-relevance feedback[C]//Proceedings of the 33rd International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 2010: 579-586.
[7] Zhai C, Lafferty J. Model-based feedback in the language modeling approach to information retrieval[C]//Proceedings of the 10th International Conference on Information and Knowledge Management. ACM, 2001: 403-410.
[8] Sayyadi H, Hurst M, Maykov A. Event detection and tracking in social streams[C]//Proceedings of ICWSM, 2009.
[9] Weng J, Lee B S. Event detection in Twitter[J]. ICWSM, 2011(11): 401-408.
[10] Fukumoto F, Suzuki Y. Using graph-based indexing to identify subject-shift in topic tracking[M]//Human Language Technology. Challenges of the Information Society. Springer Berlin Heidelberg, 2007: 392-404.
[11] van Rijsbergen C J. A theoretical basis for the use of co-occurrence data in information retrieval[J]. Journal of Documentation, 1977, 33(2): 106-119.
[12] Zhou T, Ren J, Medo M, et al. Bipartite network projection and personal recommendation[J]. Physical Review E, 2007, 76(4): 046115.
[13] Aslam J, Diaz F, Ekstrand-Abueg M, et al. TREC 2014 temporal summarization track overview[R]. National Inst of Standards and Technology Gaithersburg MD, 2015.

杨文静(1992—),硕士研究生,主要研究领域为信息检索,自然语言处理。
E-mail: yangwenjing1992@163.com

邱泳钦(1983—),博士研究生,助理研究员,主要研究领域为社交网络分析。
E-mail: qiuyongqin@iie.ac.cn

李思旭(1990—),硕士研究生,主要研究领域为机器学习。
E-mail: lisixu_job@163.com
Online Event Retrieval Based on Event Graph
YANG Wenjing1,2, QIU Yongqin1,2, LI Sixu1,2,LI Rui1,WANG Bin1
(1. Institute of Information Engineering, Chinese Academy of Sciences, Beijing 100093, China;2. University of Chinese Academy of Sciences, Beijing 100093, China)
1003-0077(2008)04-0154-11
TP391
A
2015-12-01 定稿日期: 2016-04-07
国家自然科学基金(6157050517);科技部重点专项子课题(2016YFB0801003)
① 本文将event-based retrieval翻译为事件检索,特指document retrieval w.r.t event queries。而非以关键词检索返回事件列表的任务。
