探索商业银行在大数据挖掘技术领域的应用
2017-09-23罗素文孙元浩
罗素文 韩 路 许 勤 孙元浩
1(中国银行股份有限公司上海市分行 上海 200233)2(星环信息科技(上海)有限公司 上海 200233)
探索商业银行在大数据挖掘技术领域的应用
罗素文1韩 路1许 勤1孙元浩2
1(中国银行股份有限公司上海市分行 上海 200233)2(星环信息科技(上海)有限公司 上海 200233)
由于大数据的快速发展,传统的以业务经验模式进行的数据库营销面临极大挑战。针对这种情况,提出基于大数据的数据挖掘技术方法。首先了解业务需求,根据业务目标设计模型,接着进行数据整合、数据清洗等,最后建立模型、对模型结果进行评估。实验结果表明,应用大数据挖掘技术能有效提高精准营销的成功率,进行风险防控以及运营优化管理。
大数据 数据挖掘 精准营销 风险防控 运营优化
0 引 言
随着大数据时代的到来,商业银行数据资产的价值也愈发重要。为此,探索数据的应用场景和商业模式,建立技术平台,推动商业银行从传统数据库营销到数据化运营,最终到运营数据的转变,成为各家商业银行重点工作。笔者所在的银行依托分行大数据平台,致力于大数据+人工智能+数据挖掘的探索与研究。从2014年就启动了数据挖掘的相关工作,开发了卡分期模型、信用卡疑似套现评分模型、信用卡客户流失预警模型、信用卡逾期预警模型、网点选址优化模型、大额存单交叉营销模型、中高端客户流失预警模型等。下面就精准营销、风险预警、运营优化三个主要应用场景介绍近三年运用大数据挖掘技术建模实践的成效。
1 精准营销
我行基于大数据平台丰富的数据来源及高效的分布式计算技术,通过逻辑回归、决策树、神经网络、支持向量机等机器学习算法,结合业务目标进行分析挖掘、构建模型、制定精准营销方案与策略。下面以大额存单交叉销售模型和信用卡账单分期模型为例简要介绍建模方法及收效。
1.1 大额存单交叉销售模型
个人大额存单产品自推广以来,维持了较高的存款贡献与客户层级上升贡献,是分行应对同业竞争、拓展存款和客户的技术手段和措施。为更好地推动大额存单客户群的维护与拓展,争揽客户行外资金,亟需通过该交叉销售模型找出高响应的客户进行大额存单精准营销活动。
1.1.1 建模样本及目标变量定义
建模样本定义为资产5万~100万的客户,模型的目标变量定义为首次购买大额存单的客户。时间窗口定义:观察期,6个月,表现期,3个月,经统计分析,样本的目标变量过少。为此,我们将两个观察期和表现期的数据分布叠加起来,重新整合样本后进行建模。
1.1.2 数据预处理
源数据来自客户基础属性、客户持有产品、客户交易行为、客户基础属性变化、客户持有产品变化、贷款信息、代发薪信息、跨行转账信息等数据。数据预处理主要包括变量衍生、异常值检验及处理、缺失值检验及处理三个部分组成。
变量衍生:指根据业务的一些经验值和数据分析结果,主要针对客户交易行为衍生了分渠道、分产品每月的交易金额最大值、均值、最小值及每个产品和渠道对应的交易趋势等变量。
异常值检验及处理:异常值是指一个变量的值非常极端或者出现频率非常低。对于一般的数值型变量根据盖帽原则,将最大值cap值P99分位数;有业务实际意义的,根据业务逻辑来处理。对应字符型变量通过查看其分布来检验,并根据业务逻辑来处理异常值。
缺失值检验及处理:对缺失值处理同样要分数值型和字符型两部分,对应数值型变量缺失值的填充方法有总体均值填充、类均值填充、回归预测填充等,本次模型主要采用总体均值填充的方法和业务实际来填充。对字符型变量的缺失值我们用N来填充。
1.1.3 分析建模
变量首次筛选:由于源变量较多,首次筛选去掉那些对目标变量影响不大的变量将会减少后续工作量。结合变量的IV值和单个变量进入逻辑回归模型的结果,筛选出相对重要的变量。
变量分组:由于LOGISTIC回归只能对数值型变量进行建模,对字符型变量需要预处理或分组衍生出哑变量,同样,对数值型变量也做了分组处理。我们在目标变量的监督下,对变量进行分组处理。并将分组结果转换为变量对应的woe值。
变量二次筛选:对转换为woe值后的变量做共线性诊断,剔除相关性较强的变量。
模型开发:首先将建模样本分为训练集和验证集,采用逐步回归的方法进行LOGISTIC回归的开发。基于此模型结果我们可以预测出资产5~100万的客户首次购买大额存单的可能性的大小。根据模型的评分结果,给定营销组A、B和对照组C、D,其中A和C是响应率前10%的客户,B和D组是响应率后90%的客户。前10%的客户提升度为5倍,营销组A的成功率约为对照组D的9倍。
我行业务部门开展了为期1个月的大额存单交叉营销活动,最终大额存单销售量为近500位客户,购买大额存单近600笔,认购总金额2亿多元,人均认购金额超过50万元。购买客户中,AUM月均较上月新增的客户近400位,占比约78%,AUM提升金额近5 000万元,高于中高端客户平均增幅,带动了分行开门红个人存款及客户发展工作。
1.2 信用卡账单分期
1.2.1建模样本及目标变量定义
针对最近两年有消费的信用卡客户,筛选当月账单余额绝对值>1 111且账单月内消费金额>1 111的客户,预测其在未来一个月分期的可能性的大小。
1.2.2 数据预处理
源数据包括每日卡信息表、中银卡新发卡数据表、中银卡关系表、中银卡客户信息数据、中银卡账户迟缴数据、中银卡交易数据、账单客户信息表。数据预处理主要包括变量衍生、异常值检验及处理、缺失值检验及处理三个部分组成。
变量衍生:针对客户的消费行为衍生了客户近6个月消费金额、最大消费金额、月均消费金额、分期金额、分期次数、利息次数等变量。
异常值检验及处理:数值型变量通过查看其分位数来检验,根据盖帽原则将最大值cap值P99分位数,当P99分位数为0,但最大值不为0时,将P99分位数以上的值设为1;字符型变量通过查看其分布来检验,并根据业务逻辑来处理异常值。
缺失值检验及处理:对缺失值处理同样要分数值型和字符型两部分,对应数值型变量缺失值的填充方法有总体均值填充、类均值填充、回归预测填充等,本次模型主要采用总体均值填充的方法和业务实际来填充。对字符型变量的缺失值用N来填充。
分析建模流程同大额存单交叉销售模型一致。根据模型结果,可预测出信用卡客户账单分期的可能性的大小,业务人员通过模型打分的筛选结果进行精准营销,取得了良好的业务成效。根据模型结果拨打账单分期响应率高的前60%的客户基本可覆盖98%的分期客户。通过近10个月电话外呼对每月符合账单分期的客户进行卡户分期营销,项目期间卡户分期累计新增交易额近7亿元,同比增长20.5%,实现手续费收入近4 000万元,同比增长24%,手续费贡献占比37.7%。
2 风险预警
随着互联网金融迅速崛起,各家商业银行纷纷研究大数据风控的应用场景,本文结合大数据、人工智能、银行风险防控等技术,为银行加强金融风险管控,保护客户资金安全提供保障。
2.1 中高端客户流失预警模型
我行2016年一季度中高端客户降级流失率为20%左右,中高端客户的流失导致的损失是比较严重的。为预测中高端客户流失的可能性,需找出潜在的流失客户,支撑客户经理的维护工作,定制差异化的产品、服务和营销策略来挽留客户,以防客户流失。
经过对历史数据的分析验证,建模样本及目标变量的定义为:当前6个月资产月日均20万以上,且相对前6个月资产减少不超过50%的客户,未来6个月任意月份资产月日均减少90%以上的可能性的大小。
数据预处理及分析建模流程同大额存单交叉销售模型一致。模型上线后的样本外数据验证结果前10%客户提升度为3倍,同建模结果基本一致。经过模型评分的数据支持,近半年分行客户降级流失率减少5%,挽回近5 000万的资产。
此模型的结果同时部署到分行大数据平台midas工具中,利用大数据平台的分布式计算能力,能够实时得到模型打分结果,并将客户的一些影响流失的重要指标情况实时反馈给客户经理。下一步,我们将基于此建模方法利用大数据平台的midas进行机器学习,不断地对模型结果进行迭代优化,形成客户流失预警模型的闭环营销流程。
2.2 信用卡疑似套现评分模型
信用卡套现行为给银行带来了呆坏账的风险,需要通过系统智能化的识别,根据持卡人及商户的交易行为特征,建立疑似套现模型,提高疑似套现卡片的甄别率及工作效率的同时,降低银行风险敞口。
通过分析客户最近6个月的消费情况,对客户是否存在套现给定一个评分,该模型是一个经验模型。
为此引入两个概念,客户在某商户的大额交易:客户在商户交易单笔金额大于3 000元;客户在某商户的可疑金额:最近6个月,客户在某商户大额交易笔数至少3笔,且累计交易金额大于等于50 000元。
信用卡套现主要从客户角度和商户角度入手,如果商户涉嫌套现,那么商户消费金额中有很大比重来自套现,再引入商户可疑度指标,设为ε,商户可疑度=所有客户在该商户的可疑消费金额/该商户的所有消费金额。涉嫌套现的商户一般不正规、不知名、手续费较低。
对商户信息进行清洗和分类,引入白名单,在知名商户的消费不计入套现。不可疑商户标准:普通商户可疑度<0.25;房车商户可疑度<0.3;第三方支付商户可疑度<0.1;批发类商户可疑度<0.15。
如果客户涉嫌套现,其在可疑商户消费金额的比重就较大,引入指标α、β、γ,定义M为客户的总消费金额,Mi为客户在某商户的可疑金额,Mj为客户在某商户的可疑金额2,即最近6个月内,客户在某商户至少5个月有大额交易,且累计交易金额≥5万元。Mx为客户的可疑金额,定义为客户在所有商户的可疑金额之和。
(1)
(2)
(3)
这样,我们初步得到评分公式:
0.2(log10Mx-5)
(4)
同时经过分析我们发现,取现越多和在知名商户的消费越多,客户套现的概率越低,最后我们得到优化的评分公式:

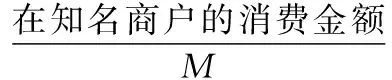
(5)
n1:最近6个月内,客户在可疑商户每笔消费3 000元以上的次数。
n2:最近6个月内,客户在可疑商户每笔消费9 900元以上的次数。
模型应用于信用卡高额度客户排查、套现排查、套取积分等排查工作中,按模型提供数据,已开展对套现评分最高的500张卡片进行排查,共处置近90张卡片,成功率为业务经验排查的6倍,为分行优化信用卡资产结构及客户质量、有效遏制不良资产的新增提供有效的决策支持。
3 运营优化
在构建了网点选址优化模型后,对其中四家支行的选址进行了对比分析。该模型主要基于客户位置、属性及商圈经济等数据的人流分析、潜在客户分析、位置画像分析、人群画像分析和应用偏好分析,提供金融网点评估建议,作为网点选址优化的依据。
3.1 人流分析
分析人流密度及分布,主要评估人口类型是居住人口、工作人口还是流动人口。
3.2 潜在客户分析
分析客户的活动区域分布、客户的基本属性信息、消费信息等数据。通过look-alike相似人群扩展机器学习算法,将高PA客户群作为种子用户,作为机器学习的正样本,剩下的客户则为负样本,从而将上述问题转化为一个二分类的模型,正负样本组成学习的样本。经过对模型的训练,利用模型结构对客户进行打分,最终得到我们想要的潜在高PA客户群,即根据相似人群的扩大,寻找出符合业务的潜在客群。
3.3 位置画像分析
通过对周边资源的分析,以及金融同业的分析,评估周边交通便利层度。
3.4 人群画像分析
主要分析客户的年龄、性别、学历、职业、婚育状况、车辆情况、应用使用偏好、消费品位、消费品类等多维度。
3.5 应用偏好分析
本文着重分析客户对金融类APP的偏好,主要包括金融同业、互联网金融机构等消费倾向的分析。
四家支行从上述五个方面对比分析发现:四家支行的定位差别很大,支行1处于核心区域,位置环境优越,人群质量和业务都占优,潜在客户群大,各方面都具有明显的优势;支行2和支行3处于人口密集区,中国银行手机银行APP安装率较高,说明老客群体相对较多,50岁以上人群在四个支行中人群占比最高;支行4相对于其他三个支行劣势较多。
4 结 语
大数据挖掘可让金融机构更加了解客户,在一段时间内,大数据在金融应用中还将以营销、风控和运营为主要场景。未来,金融机构在合规的前提下,将引入更多维度的外部数据。在大数据分析挖掘取得成效的基础上,一方面丰富数据指标体系,进行模型的优化工作,全口径掌握客户使用银行产品和服务的状态,以及与其他客户的关系,对客户进行全视角的风险评估;另一方面,充分利用大数据平台计算架构的优势,基于大数据平台的分布式计算能力进行机器学习,为业务发展提供实时的决策与支持。
[1] 霍魁.大数据时代下数据挖掘技术在银行中的应用[J].商,2015(26):191-192.
[2] 彭爽.商业银行转型升级的大数据战略分析[J].中国商论,2016(1):71-73.
[3] 宋志德.论我国商业银行业务创新[J].商业文化,2015(6):96-97.
[4] 王雅轩,顼聪.数据挖掘技术的综述[J].电子技术与软件工程,2015(8):204-205.
[5] 崔冬梅.大数据时代之统计数据挖掘实证[J].统计与决策,2016(4):180-182.
[6] 刘凤艳.基于聚类分析的证券业客户分层实证研究[J].赤峰学院学报(自然科学版),2016(8):99-101.
[7] 曹凌雁,曹慧,刘向荣.基于数据挖掘技术的信用卡透支影响因素研究[J].知识经济,2015(2):87-88.
[8] 张觉文,张心蓓.我国电子银行业务现状及发展趋势[J].统计与管理,2015(7):60-61.
[9] 许佳馨,刘晓星,崇章.大数据对商业银行的影响分析[J].农业发展与金融,2016(5):51-52.
[10] 南楠.基于关联规则的银行潜在客户挖掘研究[J].电子商务,2016(8):48-50.
EXPLORETHEAPPLICATIONOFBIGDATAMININGINCOMMERCIALBANKS
Luo Suwen1Han Lu1Xu Qin1Sun Yuanhao21
(BankofChinaShanghaiBranch,Shanghai200233,China)2(TranswarpTechnology(Shanghai)Co.,Ltd,Shanghai200233,China)
Due to the rapid development of big data, the traditional database management with business experience model is facing great challenge. In view of this, we propose a data mining technology based on big data. We first understand the business requirements, design the model according to the business goal, then carry on the data integration and the data cleaning, finally establish the model and evaluate the model results. The experimental results show that the application of big data mining can effectively improve the success rate of precision marketing, risk prevention and control and operational optimization management.
Big data Data mining Precision marketing Risk prevention and control Operation optimization
TP311
A
10.3969/j.issn.1000-386x.2017.09.009
2017-06-02。罗素文,硕士,主研领域:数据挖掘,机器学习。韩路,硕士。许勤,高工。孙元浩,硕士。
