Hadoop环境下医学影像存储的设计
2017-09-21郭文亮
郭文亮
邯郸市中心医院 信息科,河北 邯郸 056001
Hadoop环境下医学影像存储的设计
郭文亮
邯郸市中心医院 信息科,河北 邯郸 056001
目的医学影像在临床诊断、科学教研中发挥着越来越重要的作用,本文探讨通过云平台解决医学影像数据量剧增、检索效率低等问题的可行性。方法将传统的光纤存储局域网络集中式存储和分布式文件系统(Hadoop Distributed File System,HDFS)存储相结合,形成一种混合式存储架构。其中通过文件序列化的方式解决HDFS不适合医学影像小文件存储的问题,通过集中式存储解决医学影像实时性访问的问题。结果随着客户端数量增加,在混合式存储方式下,医学影像数据的读、写速度较传统的集中式存储都有明显的提高。结论采用Hadoop平台的混合式存储方式可以满足剧增的医学影像数据的存储要求,并且可以提高数据的读写速度。
医学影像;Hadoop;小文件存储;实时性访问;医学数字成像和通信标准
引言
近年来,医学影像技术取得了突飞猛进的发展,出现了大量的新设备,64排螺旋CT、PET/CT、超高场强磁共振等先进设备大大提高了疾病的诊断效果[1-2]。然而技术的发展也伴随一些问题:医学影像设备一次扫描产生数百幅影像,一年产生上PB级的影像,这些影像资料的保存、容灾以及备份,海量数据的检索速度、网路传输都面临很多问题。现阶段大部分三甲医院都是采用扩展服务器存储容量的方法解决数据剧增的问题,但是此方法的可靠性和扩展性较差,并且大规模的数据存储量也会严重影响检索速度。因此,本研究充分发挥Hadoop平台中分布式文件系统(Hadoop Distributed File System,HDFS)经济、可靠、可扩展以及MapRedcue计算框架高效、计算性能强等优点,可以解决医学影像数据量剧增等相关问题[3-4]。
1 Hadoop简介
Hadoop是Apache开源组织的一个分布式计算开源框架,在很多大型网站上都已经得到了应用,如Facebook、Yahoo、IBM等。以HDFS和分布式计算框架MapReduce为核心的Hadoop为用户提供了系统底层细节透明的分布式计算和分布式存储的编程环境[5-6]。
HDFS就是一种管理网络中跨多台计算机存储的分布式文件系统。它是将一个大文件分成若干个数据块,并创建多份复制保存在多个数据节点集合中,避免发生单点故障而导致的数据丢失[7-8]。因此,HDFS是一个具有高度容错性和可扩展性的分布式文件系统,可以提供高吞吐量的数据访问,很适合应用于大规模数据集上。
MapReduce是Hadoop的分布式计算编程框架,它为开发基于Hadoop平台的分布式应用提供了一个简单的模型,把传统的复杂计算抽象在Map和Reduce两个函数内,为开发者屏蔽了大量繁琐的任务调度和出错处理等底层细节问题。程序员只要做简单的编码就能够运行在由上千普通商业机器组成的集群上,并以一种可靠容错的方式并行处理大规模数据集[9-10]。
2 系统设计
Hadoop在构建医学影像存储系统时还存在着两个主要问题:第一,Hadoop的设计理念是针对大文件进行优化的,而医学影像资料中的CT、MRI的图像大小大多为512 KB左右,一次拍摄产生的图像数量大约为100~200幅,如果直接将大量的小文件存储在HDFS文件系统中,将导致HDFS主节点NameNode的内存消耗过大,集群的性能下降[11];第二,HDFS的设计理念适合大规模的数据分析等批处理应用,在数据写入的过程中,每个数据块需要复制3个副本,导致写入时延较大,不适合需要低时延的实时应用。因此不太适合需要快速从医学影像设备获取图像资料并撰写诊断报告的PACS实时操作[12-13]。
针对以上问题,首先,本研究采用Hadoop的Sequence File文件格式,将医学影像的DICOM文件序列化成Key/ Value键值对的形式,将一个病人一次检查产生的影像图片合并成一个序列化文件。这样就能够大大提高HDFS计算性能,减少了元数据服务器内存的消耗。其次,将现阶段PACS最常见的“在线-近线-离线”三级存储简化成为“在线-归档”两级存储,医院将不同时间段的影像图片存在“在线库”和“归档库”中,从而实现了一套光纤(FC)存储局域网络(Storage Area Network,SAN)集中存储和分布式HDFS存储相结合的混合式存储方式,利用FC SAN非常适合小文件的快速读写的特点弥补了HDFS的不足。
3 序列化文件
3.1 DICOM医学图像文件格式
医学数字成像和通信(Digital Imaging and Communication in Medicine,DICOM)标准是由美国放射学会(American College of Radiology,ACR)及国际电气制造业协会(National Electrical Manufacturers Association,NEMA)所形成的联合委员会于1985联合制定的关于医学数字图像格式和通讯的标准[14]。
DICOM文件是指按照DICOM标准而存储的医学文件,DICOM文件一般由一个DICOM文件头和一个DICOM数据集合组成(图1)。文件头包含了标识数据集合的相关信息,由导言与前缀组成。导言是文件前言,由128字节的00H组成。前缀是一个长度为4字节的字符串“DICM”,可以用来判断是否是一个DICOM文件。数据集由多个数据元素组成,每个数据元素对应一个IOD的属性,每个数据元素有4个域分别是标签(Tag)、值表示VR(Value Representation)、值长度(Value Length)和值域(Value Field),其中值表示是可选的[15-16]。
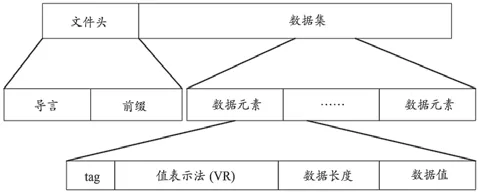
图1 DICOM文件格式图
3.2 文件合并
本研究合并小文件的主要思想是将每个DICOM文件转化成健值对(Key/Value)的形式,其中文件名称作为关键字,文件内容作为值,然后采用序列化文件方法将这些小文件合并后写入到一个单独的序列文件Sequence File中去。合并文件的交互现在由四个角色组成,分别为Client客户端,小文本合并Merge-Server,主节点NameNode和数据节点DataNode,图2为小文本合并结构。

图2 小文件合并结构图
文件合并步骤如下:
(1)对集中式存储服务器上的文件进行当前时间和小文件创建时间进行比较,把差值大于6个月的文件筛选出来。
(2)从筛选出的小文件中取出一个待合并文件信息,设置块数据结构,加入待合并队列Wait Merging Queue。
(3)从剩下的小文件中优先取和1中文件文件名相同的小文件,如果没有,取下一个待合并的小文件。
(4)设置数据结构,计算加入此文件后,合并后的大文件块的大小是否超过64 MB,超过转5,否则加入WMQ队列中,重复3。
(5)将WMQ中的小文件数据序列化写入大文件。
3.3 序列化方法的不足
这种Sequence File文件序列化方式不仅能够弥补Hadoop处理小文件效率低的弊端,还具有支持可分割,系统利用率高,支持数据压缩,有利于节省磁盘空间和加快网络传输速度等优点。但是Sequence File并不支持存储在它内部的文件的随机访问,当需要访问它内部的文件时,需要遍历整个目录文件,检索效率低。本研究参考作者所属三甲医院的医学影像查看情况,见表1。此表为各种医学影像在生成后被查看的总数表,3个月后的医学影像被查看次数可以忽略不计,因此本研究采用了这种小文件合并方式。当然根据医院规模、实际情况的需要,可以建立小文件索引,比如在Map阶段针对各个块上的小文件建立局部索引,然后在Reduce阶段将局部索引合并,形成一个全局索引。

表1 某三甲医院医学影像查看总数表 (个)
4 FC SAN和HDFS混合式存储
当前医院影像数据大部分都存储于光纤存储局域网络集中式存储服务器中[17-18],但是这样的架构存在服务器负载重、数据读写速度慢、计算能力差等缺点。基于数据读写速度、冗余性和扩展性等方面的考虑,本研究设计了FC SAN集中式存储和分布式HDFS存储相结合的存储架构。
网络架构图,见图3。医学成像设备生成DICOM格式影像,存储到集中式存储服务器上,并且在服务器上生成每个文件的索引,能够使PACS工作站以及HIS接口实时地调用影像图片。当集中式存储服务器上的影像存储大于6个月,会在Hadoop名称节点创建文件,分配存放数据的各分块的数据节点。然后,通过Sequence File文件序列化方式把影像文件合并成大文件,写入到HDFS的数据节点中,再调用MapReduce任务生成这些小文件的索引。之后,删除集中式存储器中这些影像的数据和检索信息。来自公网的外部工作站发送读文件请求,首先在集中式存储器中检索,当没有检索到相关信息后再通过MapReduce任务在NameNode节点上检索,当获得相关的数据节点信息之后,与DataNode交互读取相关文件。
5 仿真测试
5.1 基本配置
在Linux环境下,通过1台HDFS名称节点(NameNode)兼MapReduce主节点机和9台数据节点(DataNode)兼MapReduce从节点机组成一个Hadoop云集群。节点基本配置:CPU是Intel Xeon E5504;内存为8GB DDR3;硬盘为1TB SATA;操作系统为64位CentOS5.4;Hadoop版本是1.2.1。存储空间总计9 TB,Hadoop配置每个数据块在集群保存副本数为3,因此实际存储容量为3 TB。
集中式存储服务器选择IBM 3650,具体配置:Intel 4核E5630处理器,8 GB DDR3 RDIMM内存,两块1 TB硬盘,双电源,计算机操作系统为Windows 2003 Server。

图3 网络架构图
5.2 测试结果
(1)本次测试通过对5.2 GB的DICOM数据进行存储,验证了该系统设计可以通过集中式存储服务器实现医学影像的实时性读取,通过Hadoop平台实现医学影像安全、高效的存储。
(2)3个月内医学影像通过FC SAN集中式存储读取,性能与现有的PACS系统相似,因此主要测试3个月以前的医学影像的读写性能。当有1~5个客户端对系统进行读写操作的时候,本系统与原始的FC SAN集中式存储读写性能对比,见图4。图中X轴表示访问Hadoop平台的客户端数目,单位台;Y轴表示访问的随着客户端数目增加的情况下读写速度,单位M/S。结果显示,本系统的数据读写速度较原系统都有显著的提升。

图4 读写速度对比图
6 结论
医学影像对临床医生诊断和治疗病人起到重要的作用,但随着影像技术不断提高、就医人数不断增加,出现了医学影像数据剧增和访问效率低下的问题,严重影响临床医生工作效率。本研究提出了一种传统的FC SAN集中式和HDFS分布式相结合的存储方式,并对HDFS不适合小文件存储的问题,提出了文件序列化方法进行合并,为原有PACS提供了一个低成本、易扩展高效的技术方案。该系统在测试平台上初步实现了资源共享、提高读写性能、易扩展等目的,满足了区域医学影像信息化的功能和性能要求,为云计算技术真正应用到医院信息化建设中提供了理论基础。
[1] 吕国义.医院PACS系统发展趋势研究[J].中国卫生质量管理,2015,2(6):92-94.
[2] 赵凯.基于云存储的医院PACS系统存储设计[J].信息安全与技术,2012,3(4):92-93.
[3] 梁志刚,周永新,李坤成.基于PACS的远程医学影像会诊系统的初步探索[J].中国医疗设备,2013,28(6):77-78.
[4] 魏寒冰,叶少珍.基于云计算的医学影像存储与传输系统的设计[J].电子技术应用, 2013,39(12):145-148.
[5] 王敏,王建伟,刘俊.基于PACS的数字化影像资源库在医学影像学教学中的应用探讨[J].中国医疗设备,2015,30(10):132-133.
[6] Cao N,Wu ZH,Liu HZ.Improving downloading performance in hadoop distributed file system[J].J Comput Applicat, 2010,30(8):2060-2065.
[7] 高林,宋相倩.云计算及其关键技术研究[J].微型机与应用,2011,30(10):5-7.
[8] HDFS Users Guide[EB/OL].[2016-12-11].http://Hadoop. apache.org/common/docs/current/Hdfs_user_guide.html.
[9] Mackey G,Sehrish S,Wang J.Improving metadata management for small files in HDFS[A].Proceedings of 2009 IEEE International Conference on Cluster Computing and Workshops[C].New Orleans:2010:4-8.
[10] 孙永超.基于Hadoop的信息检索系统研究[J].情报探索, 2016,1(8):125-130.
[11] 李彭军,陈光杰,郭文明.基于HDFS的区域医学影像分布式存储架构设计[J].南方医科大学学报,2011,31(3):495-498.
[12] 冯贞贞,郑西川.区域医学影像信息共享的关键及实现方案[J].医疗卫生装备,2011,32(6):52-54.
[13] 方胜吉,翁苏湘.构建分布式区域医学影像存储平台关键技术的研究[J].电子技术与软件工程,2014(2):127.
[14] 张明,吕晓琪,张宝华.DICOM医学影像网络传输技术的研究与实现[J].重庆医学,2014,43(13):1657-1659
[15] 龙华飞,唐月华,陈泓伶.PACS系统中DICOM医学图像格式解析[J].中国数字医学,2014(3):29-31.
[16] 李伟,李仕红,韩中保.基于JAVA的DICOM文件格式转换与信息提取[J].医疗装备,2014,27(4):15-16.
[17] 周晟劼,袁骏毅,李波.基于Hadoop的数据中心三甲医院的探索研究[J].中国数字医学,2016,11(6):25-27.
[18] 多学松,张晶,高强.基于Hadoop的海量数据管理系统[J].微计算机信息,2010,26(5):202-203.
本文编辑 刘峰
Design of Medical Image Storage Under the Context of Hadoop
GUO Wenliang
Department of Information, Handan Central Hospital, Handan Hebei 056001, China
ObjectiveMedical image is playing a more and more important role in clinical diagnosis and scienti fic research. This paper aimed to investigate the feasibility of solving the problem of soaring medical imaging data and ineffective searching by cloud platform.MethodsThis paper proposed a hybrid storage architecture which combined the traditional fibro optical storage area network centralized storage with hadoop distributed file system (HDFS) distributed storage. Through the file serialization solution, this paper solved the problem that HDFS storage was not suitable for the small medical image. Through centralized storage the paper solved the problem of real-time access to medical image.ResultsWith the increasing of client, reading and writing speed of medical image data in the mixed storage mode was obviously improved compared with the traditional centralized storage.ConclusionThe hybrid storage mode using the Hadoop platform can meet requirement of the roaring medical image data storage, and improve the reading and writing speed of data.
medical image; hadoop; small file storage; real time access; digital imaging and communication in medicine
TP39
C
10.3969/j.issn.1674-1633.2017.09.029
1674-1633(2017)09-0115-03
2016-12-11
2016-12-23
作者邮箱:451665782@qq.com
