基于Hbase的大数据查询优化
2017-09-18朱明王志瑞
朱明++王志瑞
摘要: Hbase有着先天的优势和先天的劣势,而劣势就是其较差的数据定位能力,也就是数据查询能力。因为面向列的特点,Hbase只能单单地以rowkey为主键作查询,而无法对表进行多维查询和join操作,并且查询通常都是全表扫描,耗费资源较大,查询效率较低。类比于传统型数据库里的一些查询方式,本文对Hbase的存储原理进行了研究,借助分布式计算框架Mapreduce在Hbase上构建了二级索引,就可以对表进行有针对性的定位和高效率的查找,同时也减轻zookeeper服务对资源调度的压力。
关键词: Hbase; 大数据处理; Secondary Indexing
中图分类号:TP311
文献标志码:A
文章编号:2095-2163(2017)04-0059-03
0引言
随着企业在发展过程中积累数据的日益递增,关于大量业务数据的存储和处理即已成为关涉企业运营效率的热点研究问题之一,此时则需对自身的数据库作出调整。而Google公司关于BigTable的开源实现,更为非传统型数据库探讨研发提供了高端设计可能。作为非传统型数据库的优秀代表,Hbase就因具备的高可靠性、高性能、面向列、可伸缩的特点,已然成为企业在面临大量数据处理时的基础实效应用设计模式。本文即针对这一内容展开如下研究论述。
1Hbase体系架构
Hbase技术来源于 Fay Chang 所撰写的Google论文“Bigtable”关于一个结构化数据的“分布式存储系统”。是和Hadoop分布式文件系统对应的一个分布式数据库的概念。具体地,Hbase是一个分布式、面向列开源数据库。而且也不同于一般的关系数据库,Hbase是一个适合于非结构化数据存储的数据库。进一步地,Hbase是基于列的而非基于行的模式,这就与传统型数据库呈现出显著差别。Hbase是Apache的Hadoop项目的顶级项目。综上可知,Hbase就是建立在HDFS上的分布式列存储系统。
2Hbase存储原理
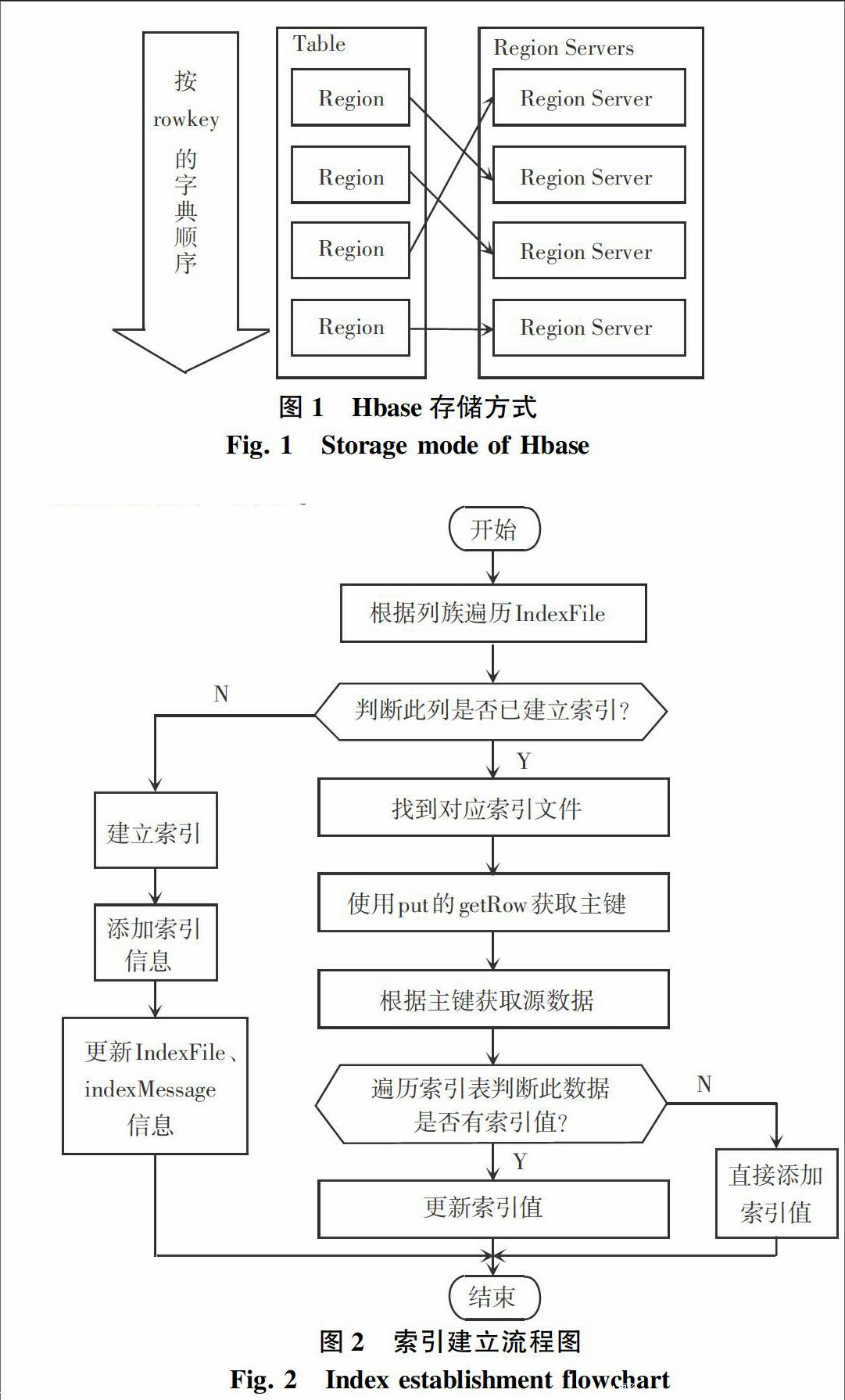
Hbase所有的行数据都是按照rowkey的字典展开排序的,所以查询Hbase表的任何一行数据都要从rowkey的第一行开始扫描,依次向下,直至找到相关的行为止,如此可知查询的效率将会很低,但这只是从第一层查询效率来考虑的,也就是研究中表明的Hbase的一级索引(就是以rowkey字典排序的方式查询数据)。
如图1所示,Hbase表中的数据,都是存放在region里面的,原本一张表中只有一个region,随着行数的不断增多,region包含的数据资源也会不断增多,当达到一个阈值时(默认为256 M),这个region即会分成2个同样大小的region,重复这一过程,当插入的数据越多,这个表的region就越多。region是由regionserver管理的,通常情况下,一个regionserver可以管理多個region。
针对Hbase查询的特点,分析可知Hbase都是通过Rowkey的方式全盘扫描表的,因此效率较慢,并且,Hbase表并不支持非主键查询,和连接查询、join操作的。
[JP3]如果能够采用传统型数据库的索引方式来对Hbase建立索引,本次研究则拟将获得更高效率。显然,索引表仅需包含一个列值,因此索引表的大小要比原表小很多,所以索引表的一个region要比原表包含更多的记录。研究可以通过mapreduce构建一个二级索引,其主体思想可表述为:通过分布式计算框架[JP4]mapreduce构建一个二级索引的方法。对此,将重点给出阐释如下:[JP]
1)Map阶段。将Hbase中的相关表遍历rowkey值,根据rowkey读出维度值,再通过维度值读出value值,并将对应的rowkey-value输出。
2)Reduce阶段。取出rowkey和value,将两值取反,即将value值作为行键,行健作为value值存入Hbase。
4研发设计流程
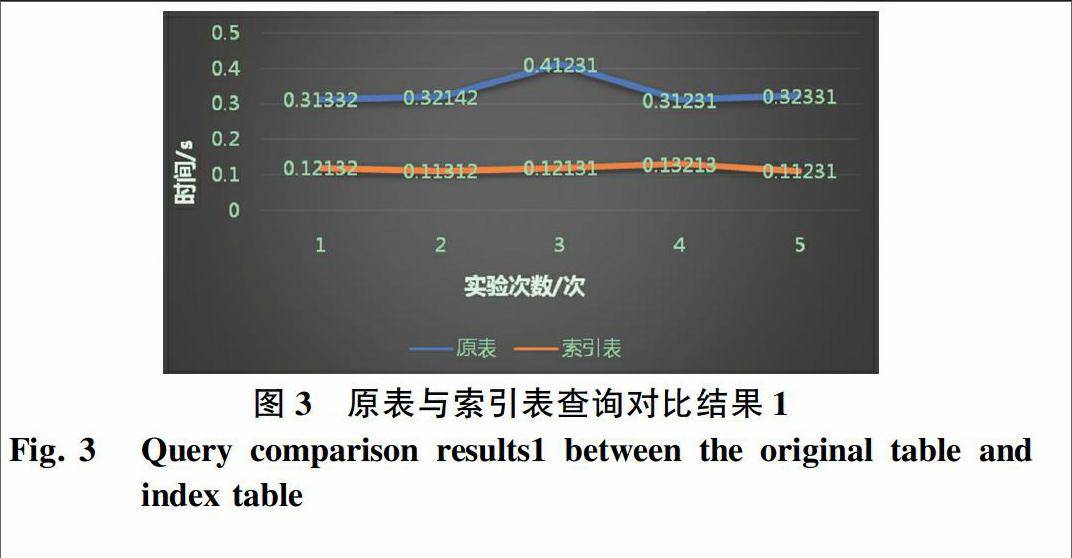
综合前文研究所述,这里将得出在Hbase中的操作实现流程可如图2所示。
throws IOException, InterruptedException
{
Set
for (byte[] k : keys)
{
[JP3]ImmutableBytesWritable indexTableName = indexes.get(k);[JP]
[JP4]byte[] val = value.getValue(Bytes.toBytes(columnFamily),k);[JP]
[JP3]Put put = new Put(val); // 索引表的rowkey为原始表的值[JP]
put.add(Bytes.toBytes("f1"), Bytes.toBytes("id"), key.get()); // 索引表的内容为原始表的rowkey
context.write(indexTableName, put);}
}
}
protected void setup(Context context) throws IOException,InterruptedException
{
Configuration conf = context.getConfiguration();
String tableName = conf.get("tableName");
columnFamily = conf.get("columnFamily");
String[] qualifiers = conf.getStrings("qualifiers"); // indexes的key为列名,value为索引表名
for (String q : qualifiers)
{
indexes.put(Bytes.toBytes(q),newImmutableBytesWritable(Bytes.toBytes(tableName+ "-" + q)));
}
}[HJ]
6实验数据比较
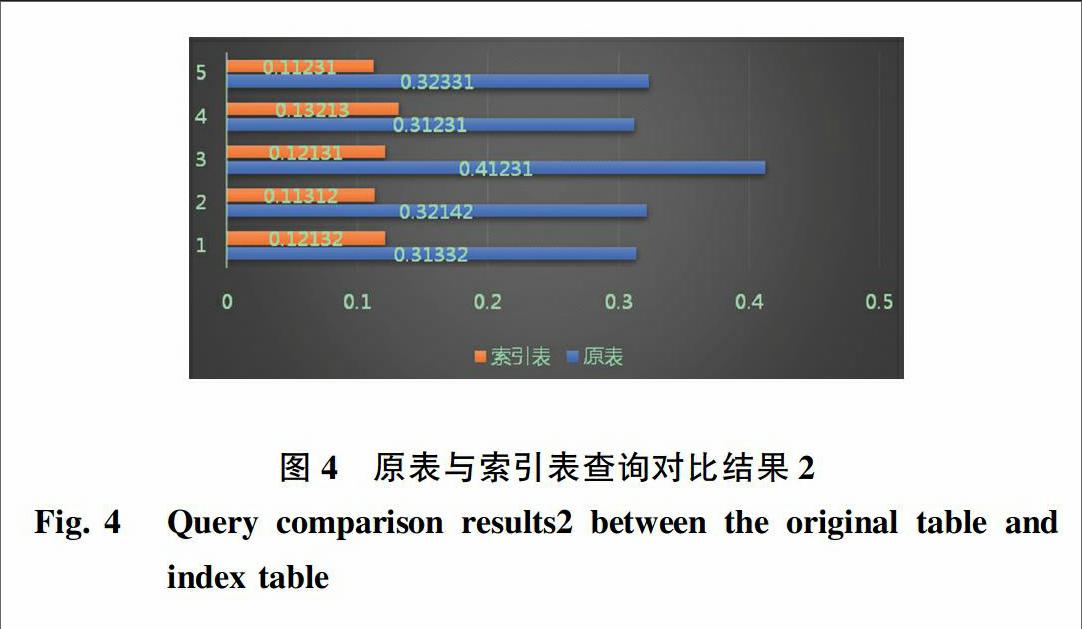
至此,研究通过Hadoop的mapreduce机制将java代码编译组装成jar包写入到HDFS里,得到新的索引表,而对新的索引表就可以进行基于原表的非主键查询,并且对新的索引表的查询将会节约大量的资源。测试中,即以班级系点名册作为数据源,对于建立了二级索引后的数据源的查询和并未建立二级索引的数据源、即原表的实验数据展开了性能对比,可得运行实验结果如图3、图4所示。
[PS朱明3.EPS;S*3;X*3,BP#]
[HJ*3][ST6HZ][WT6HZ][JZ]图3原表与索引表查询对比结果1
Fig. 3[ZK(]Query comparison results1 between the original table and index table[ZK)][HJ]
[PS朱明4.EPS;S*2;X*2,BP#]
[ST6HZ][WT6HZ][JZ]图4原表与索引表查询对比结果2
Fig. 4[ZK(]Query comparison results2 between the original table and index table[ZK)]
[HT5”SS][ST5”BZ][WT5”BZ]
7结束语
基于Hbase的大数据查询中二级索引的创建研究,也就是针对Hbase表的查询优化则使学界对非传统型数据库查询取得了明显突破,通过这种二级索引表,就可以大大降低查询的效率,也可以把nosql的劣势,即只能通过主键rowkey的查询方式,转化为非主键的查询方式等,这是对nosql半结构化数据查询应用的一次研发尝试。也为后续关于更大数据量的非传统型数据库优化提供了重要有益的基础借鉴。
[LL]参考文献:
[WTBZ][ST6BZ][HT6SS][1] [ZK(#〗
张新荣. 基于Hbase的小文件存储系统的研究及实现[D]. 沈阳:东北大学,2012.
[2] 江柳. HDFS下小文件存储优化相关技术研究[D]. 北京:北京邮电大学,2010.
[3] 李颖. 基于分布式文件系统的农业数据云存储研究[D]. 泰安:山东农业大学,2013.
[4] WHITE T. Hadoop: The definitive guide [M]. America: O'Reilly Media, 2009.
[5] 于翔. NoSQL:大数据浪潮中崛起[N]. 网络世界,2012-04-23(40).
[6] 徐小威. 非关系型数据库数据恢复技术研究[D]. 杭州:杭州电子科技大学,2014.
[7] 王映东,匡艺,费江涛. Bigtable系统的负载平衡技术研究[J]. 计算机安全,2009(2):41-43.
[8] 徐达宇. 云计算环境下资源需求预测与优化配置方法研究[D]. 合肥:合肥工業大学,2014.
[9] 毛典辉. 基于MapReduce的CanopyKmeans改进算法[J]. 计算机工程与应用,2012,48(27):22-26,68.
[10]SITTO K, PRESSER M. Field guide to Hadoop:An introduction to Hadoop, its Ecosystem, and aligned technologies[M]. America:O'Reilly Media,2015.endprint
