基于反演模式的碳排放数据集成管理系统的设计与实现
2017-08-12王娜娜乔英合
王娜娜 乔英合 牟 斌 王 伟
1(中国科学院青岛生物能源与过程研究所 山东 青岛 266101) 2(青岛海防工程局 山东 青岛 266101) 3(中国科学院水利部成都山地灾害与环境研究所 四川 成都 610041)
基于反演模式的碳排放数据集成管理系统的设计与实现
王娜娜1乔英合1牟 斌2王 伟3
1(中国科学院青岛生物能源与过程研究所 山东 青岛 266101)2(青岛海防工程局 山东 青岛 266101)3(中国科学院水利部成都山地灾害与环境研究所 四川 成都 610041)
针对“能源消费与水泥生产的排放”项目中所采集、生产的各类数据,设计并构建基于反演模式的碳排放数据集成管理系统,提供采样数据的预处理、录入导入、分析挖掘及反演预测等功能。着重解析了系统设计开发中的架构设计、数据预处理和反演预测模型等关键模块。实践结果表明,这些模块在碳排放数据集成管理系统中的应用,有利于实现多源数据的统一管理展示,有利于精准确定我国能源消费和水泥生产过程的碳排放系数。
碳排放 数据预处理 数据挖掘 反演 预测
0 引 言
近年来,以温室气体排放为核心的气候变化问题已经成为国际社会、科技界和社会公众关注的焦点,且已深入到国际政治和外交层面[1]。但总体来说,我国在碳排放这方面的研究基础较为薄弱,且零星分散,不能形成合力。在基础数据收集、方法论、关键论断、模型构建等方面都参照甚至照搬国外CO2研究机构或专家的研究成果,缺少创新性成果,导致我国碳排量长期被高估[2],面临着巨大的减排压力[3]。与此同时,我国各领域各行业间测算方法的不同、碳排放系数的标准不统一,使得碳排放测算结果不一致[4],难以为我国进行CO2减排决策提供数据支撑和理论依据。为此,2011年中科院启动了战略性先导科技专项“应对气候变化的碳收支认证及相关问题”(简称“碳专项”)。期望科学系统地研究我国在能源消费、土地利用、自然过程等领域的CO2、CH4和N2O3种主要温室气体排放,建立我国温室气体基础参数及排放数据库[5]。
本文以 “能源消费与水泥生产碳排放”项目为研究背景,探讨碳排放数据集成管理系统的总体流程、架构设计、数据库设计、功能模块设计等。并详细阐述关键技术如数据预处理宏程序、异地容灾技术和反演预测模型等。提出系统具体实现的解决方案,构建能源消费与水泥生产过程碳排放的可视化数据库。
1 系统总体设计
总体设计主要是指在系统分析的基础上,对整个系统的划分(子系统)、机器设备(包括软、硬设备)的配置、数据的存贮规律以及整个系统实现规划等方面进行合理的安排[6],是构建信息系统的基础。本系统采用分布式主从互备架构、MVC三层分离技术,利用Power Design设计数据库E-R图,并根据具体业务需求,将系统划分为六大功能模块。
1.1 系统总体流程
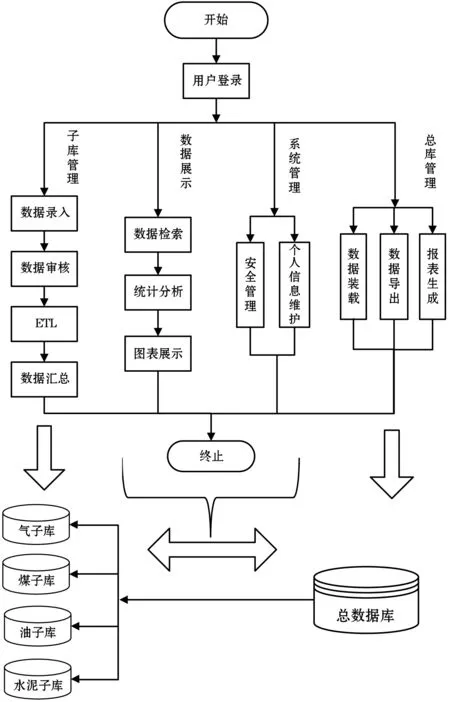
图1 系统总体流程
“能源消费与水泥生产碳排放”项目针对全国范围内“煤”、“油”、“气”、“水泥”等领域的采样数据、历史数据、工厂数据等进行收集、过滤、分析、反演与预测等。因此将系统分为五个模块:一个总数据库和四个子数据库,其中总数据库负责综合各个子数据库信息,用于数据展示、数据挖掘与报表生成。子数据库负责保留原始数据及经过ETL处理后的数据。系统总体流程如图1所示。
1.2 系统架构
系统架构设计是在需求分析的基础上,深入综合地考虑信息系统的目标、技术要求和约束,扩展和细化需求分析阶段的模型。秉承高内聚低耦合的设计原则,实现系统从整体到部分的最高层次划分。本节主要从物理架构、逻辑架构、数据库架构及模块划分四方面进行阐述碳排放数据集成管理系统的架构设计。
1.2.1 物理架构
物理架构明确系统硬件选择、拓扑结构,软硬件映射等。本系统采用“一主两翼”物理架构,设置太原主节点、青岛和上海两个灾备节点。在每个节点系统均采用应用服务器与数据库服务器两层结构设计,数据库服务器提供数据资源与公网隔离,以增加系统安全性,应用服务器应答客户访问请求,具有良好的实时性。系统物理架构如图2所示。
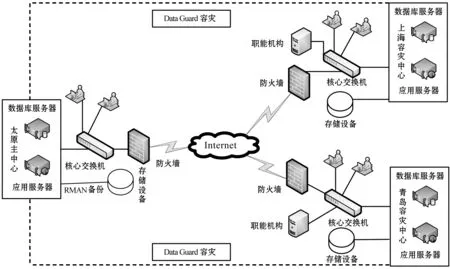
图2 系统物理架构
太原主节点使用的是RMAN实现本地数据每天增量备份和每周全量备份。RMAN是一种用于备份、还原和恢复Oracle 数据库的系统自带工具。可以备份整个数据库或数据库部件,如表空间、数据文件、控制文件、归档日志文件等[7]。主节点Oracle RAC 数据库各节点共享数据文件、控制文件,并存储于存储设备中。数据复制引擎跟踪数据库日志,当应用系统操作数据库时,系统首先把这些信息存储在日志中; 然后数据复制引擎通过对数据库日志的分析,获得本次操作的指令和数据,形成备份目录;最后系统将主节点备份目录通过网络文件系统共享备份数据中心,使备用主机能正常读取RMAN 备份数据。
灾备节点均使用的是Data Guard实现异地人工全库备份。Data Guard主要是通过日志文件的传送、分析和应用来实现数据库复制[8]。在应用事务发生后主数据中心通过数据复制引擎将日志传输到备份数据中心,备份数据中心的数据库对日志中记载的事务执行重演操作,实现对备份数据中心数据库数据的更新。保障太原数据中心同青岛和上海容灾中心间的数据安全、数据同步、高效并发访问等。
1.2.2 逻辑架构
逻辑架构描述系统功能,进而指导系统测试。本系统采用MVC分层架构,由数据层、业务层、展示层组成,如图3所示。各层之间具有较强的独立性,各层采用标准接口为上一层进行服务[9],实现了系统各层间的分离,在一定程度上降低了软件系统的开发周期和维护成本,使系统具有较高的灵活性、伸缩性和可扩展性[10]。
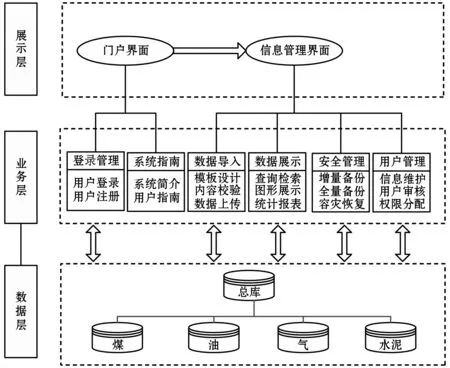
图3 系统逻辑架构
1.3 数据库设计
数据架构指导数据库、实体模型及数据存储的设计。按业务需求,经过详细的需求分析,共设计185个数据库实体,其中主表173个,辅助表11个,统计表1个。某课题E-R图如图4所示。
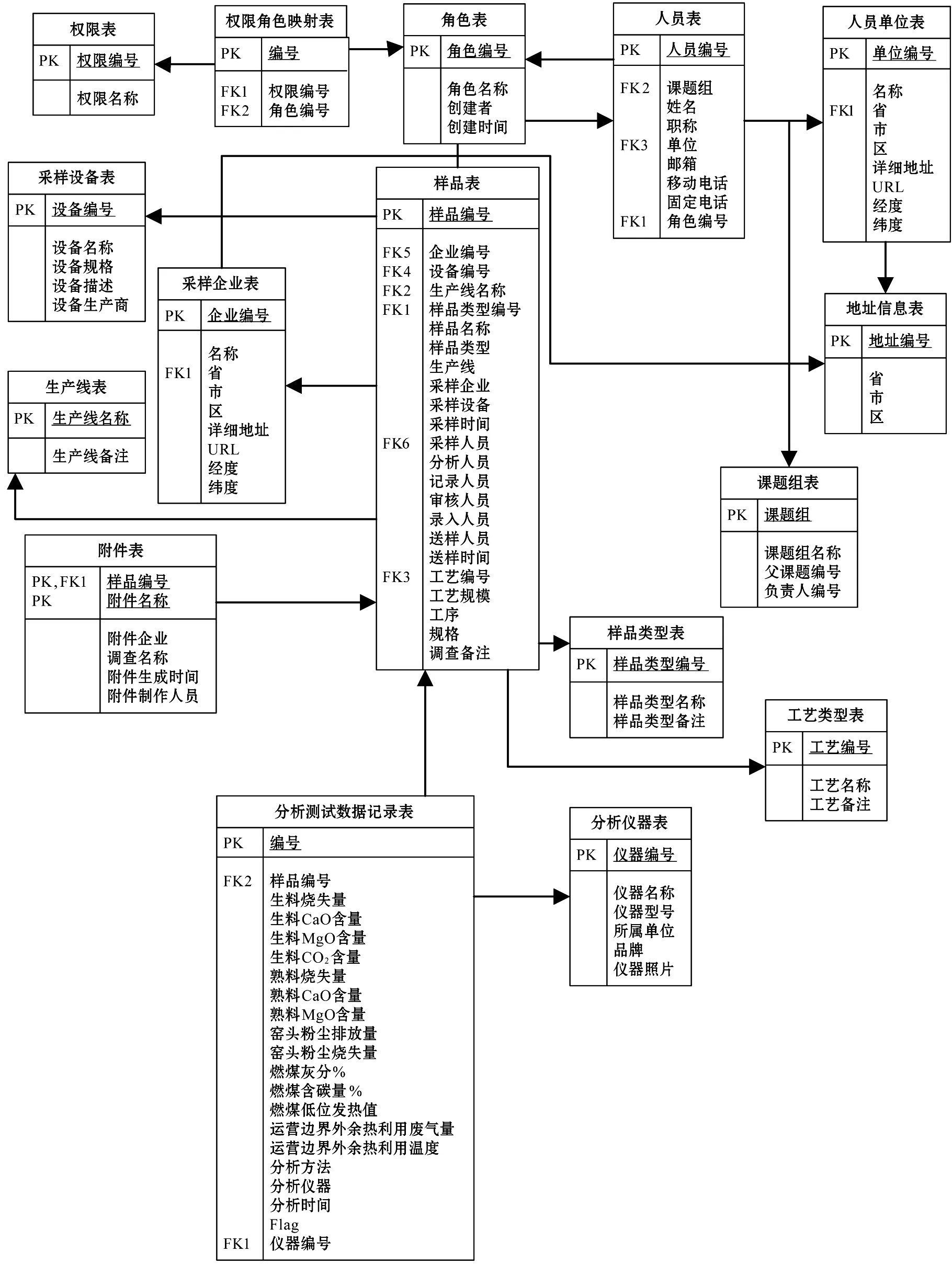
图4 某课题E-R图
1.4 功能设计
根据用户需求,将系统划分为六大功能模块:用户管理、数据预处理、数据录入导入、数据展示、数据反演预测与重要信息监测等功能。
1.4.1 用户管理
根据用户实际需求设计用户管理模型,使用基于角色的访问控制RBAC策略完成了数据库系统的角色管理功能,实现了分层角色,资源权限控制以及动态角色变更等功能。针对用户需求中存在人员兼任多个职务的实际情况,设置了用户多组多角色支持,并实现了权限与用户登录菜单的多级联动功能。对未经授权的用户严格控制其访问。并在系统内部实现了用户的增、删、改、查等功能,支持创建临时用户,及临时用户访问时间控制等功能。
1.4.2 数据预处理
数据预处理欲从大量的数据属性中提取对目标有重要影响的属性来降低数据维数,并甄别错误或不匹配数据,以改善数据质量、提高进一步数据分析的速度[11]。系统针对用户实际需求,设计基于VBA的Excel校核模板,能够实现离线环境中对数据的校验精确到字段。
同时,利用科学的方法,对测量所得的一次数据,进行科学计算,获得碳排放过程核心参数。利用测试所得到的各样品精确的组成、温度、压力、流量等数据,通过公式计算获得标准状况下,各样品的低位发热量和碳含量值。
1.4.3 数据录入导入
系统支持采样数据的单条录入和批量导入功能。为适应表结构变化,实现了数据导入过程中自动解析表结构、自动建表、自动校验等功能。除数据文件外还支持文档数据及图像数据的上传,在数据文件上传过程中提供对数据内容的校验功能,支持重复数据忽略、错误信息提醒等功能。
1.4.4 数据展示
数据入库后自动生成新建表的检索界面,提供统一格式的检索界面。针对每组数据的检索,检索条件中列出了所有的数据字段以供筛选,同时还可以针对每个字段设置检索条件,实现了复杂的数据检索功能。检索结果以表格的形式在同一个页面中展示,实现了检索结果分页。同时对检索得到的结果支持动态生成图形展示等功能,生成的图形包括曲线图、柱状图、饼图、地理信息图等。
1.4.5 数据反演预测
参考IPCC重叠法反演我国二氧化碳排放量。同时,寻找替代变量构建其他反演模型,如多元回归模型,修正我国以往年份能源消费与水泥生产过程的二氧化碳排放量数据。针对历年各省市地区的反演数据存在缺失情况,设计并开发部分碳排放过程的缺失反演数据插值算法,估计并填充缺失的部分反演数据。
同时根据反演数据的统计公式开发由总课题到课题以及由课题到子课题的挖掘功能,逐层递进的展示项目数据以及追踪数据来源。
1.4.6 重要信息监测
使用网络爬虫技术,借助信息抽取、自动分类、自动摘要、文本挖掘等方法,对指定网站的指定新闻模块进行定期跟踪,实现了新闻信息的及时追踪与集中展示功能。由此实现国内及国际碳排放领域相关信息的汇总及展示功能。
2 关键技术研究与实现
根据业务的定义,在系统设计开发过程中采用不同的技术满足用户需求。本系统采用Excel VBA宏程序、IPCC重叠法、ARIMA模型、异地灾备、行级数据管理等技术来实现数据预处理、反演、预测及安全保障。
2.1 数据预处理
由于采样过程不可逆,而采样人员不规范的操作可能会造成采样数据杂乱、无效、缺值等情况,因此需要对采样数据进行实时离线校验,避免人为因素对采样结果造成影响。
项目组基于以上需求,开发了基于EXCEL VBA宏程序的数据模板。实现了数据的范围校验、非空校验、一致性校验等,规范化了数据导入格式,同时备注了各个字段在数据库中的数据类型、数据范围、关键字等必要信息,提升了数据质量,方便了数据采样与导入。系统预处理模板如图5所示。
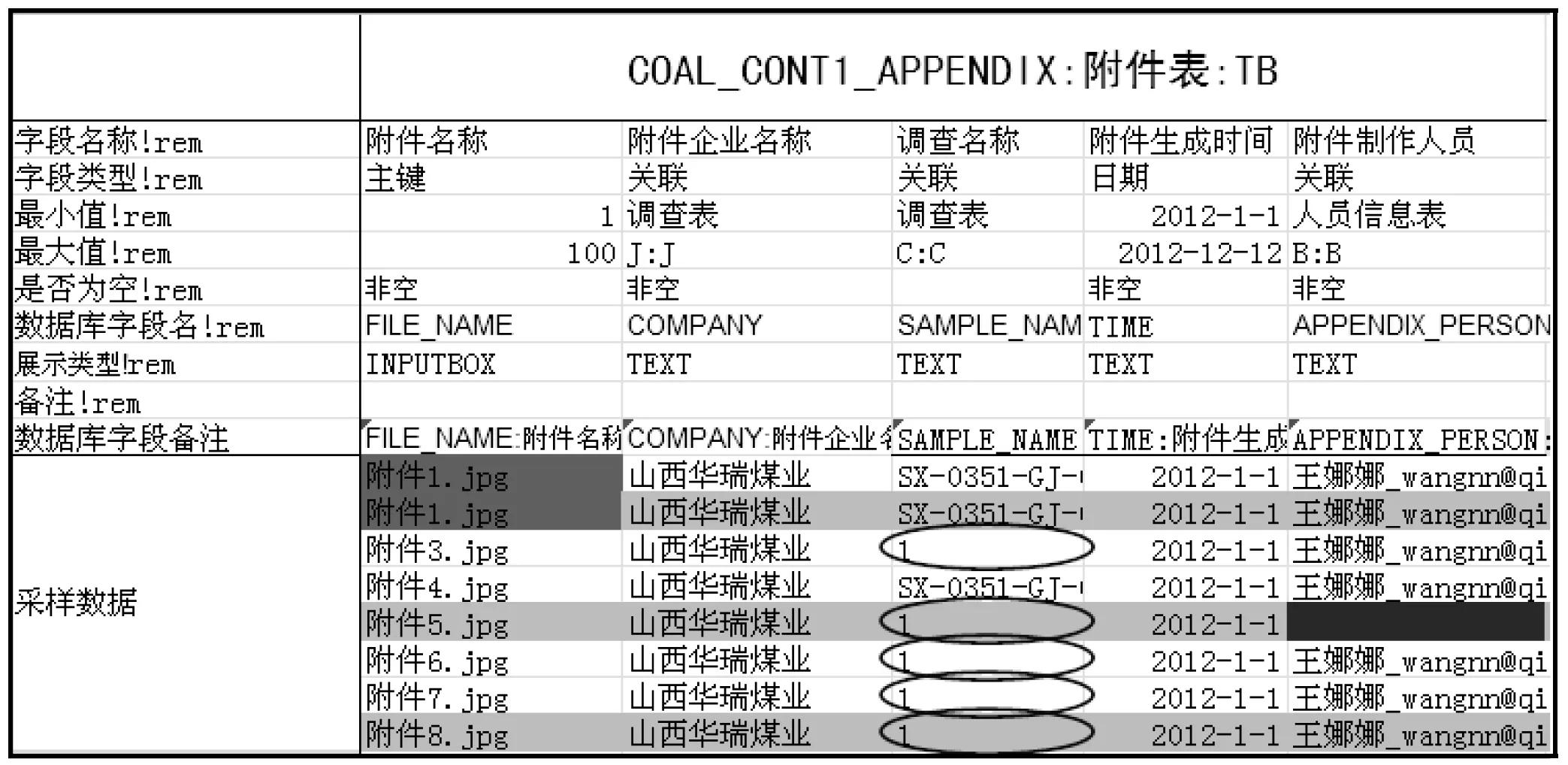
图5 数据预处理模板
数据类型校验:在本系统Excel文件中可支持的数据类型包括整型、小数型、日期型、字符串、关联型,根据实际采样数据的需要预先对记录字段的类型进行设定。数据类型规范如表1所示。
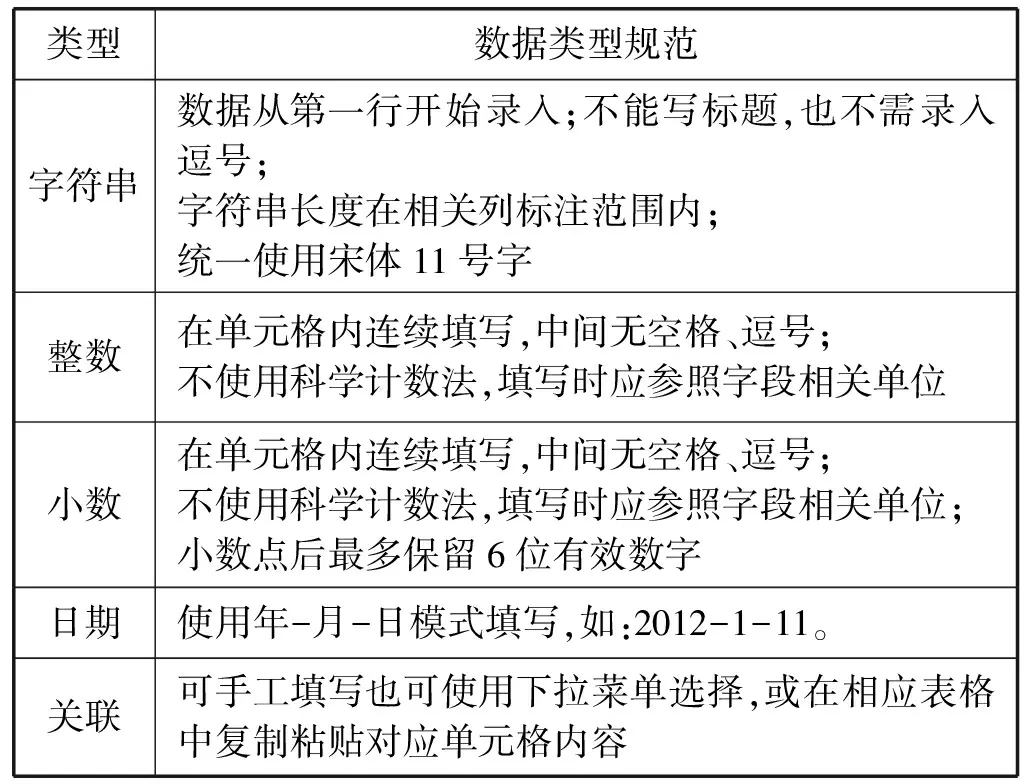
表1 数据类型规范表
对于不符合类型约束或范围约束的情况,填写过程中会自动提示错误。
对于唯一值约束和非空约束,会以特殊颜色标识。对提示框内部数据进行修正后提示色彩会自动消失。
2.2 反演与预测模型
从二氧化碳排放的物理模型出发,基于对IPCC排放因子法的详细研究,选取气体、标准状态及热值作为假设条件,以采样数据为基础,计算碳含量、氧化因子及二氧化碳排放量。在此基础上构建假设检验模型、回归模型、Monte Carlo模型、方差分析模型,确定不同假设组合对检验参数(碳含量、热值及二氧化碳排放量)影响的显著性,根据模型验证结果确定对参数具有显著影响的假设组合,其组合中包含的假设条件即为必要假设条件。
《2006 IPCC国家温室气体清单指南》中介绍的接合技术为数据反演提供理论指导[12],利用重叠法反演我国二氧化碳排放量。同时,寻找替代变量构建其他反演模型,如多元回归模型,将反演结果与利用IPCC缺省值的计算结果进行对比,修正我国以往年份能源消费与水泥生产领域的二氧化碳排放量数据。
在反演模型基础上构建ARIMA时间序列预测模型[13],搜集替代变量,构建与二氧化碳排放的联系模型,并利用各因素的变化反演和预测十年跨度二氧化碳排放量。
2.3 数据集成
由于能源消费与水泥生产过程中涉及到的采样数据、工厂数据、测试数据、设备数据及历史数据等,其数据内容、数据格式和数据质量可能千差万别,需要按照新的数据设计导入到新库中。因此采用开源ETL工具Kettle[14]实现异构数据集成。
由于不同用户提供的数据可能来自不同的途径,根据数据采样测试分析实际需求,对不同途径来源数据进行抽取、过滤,采用事实表—维度表的多维模型构建了星型数据仓库,实现对各主题域维度数据和事实数据的转换与加载,最终形成碳排放数据集成平台。多源数据抽取如图6所示。
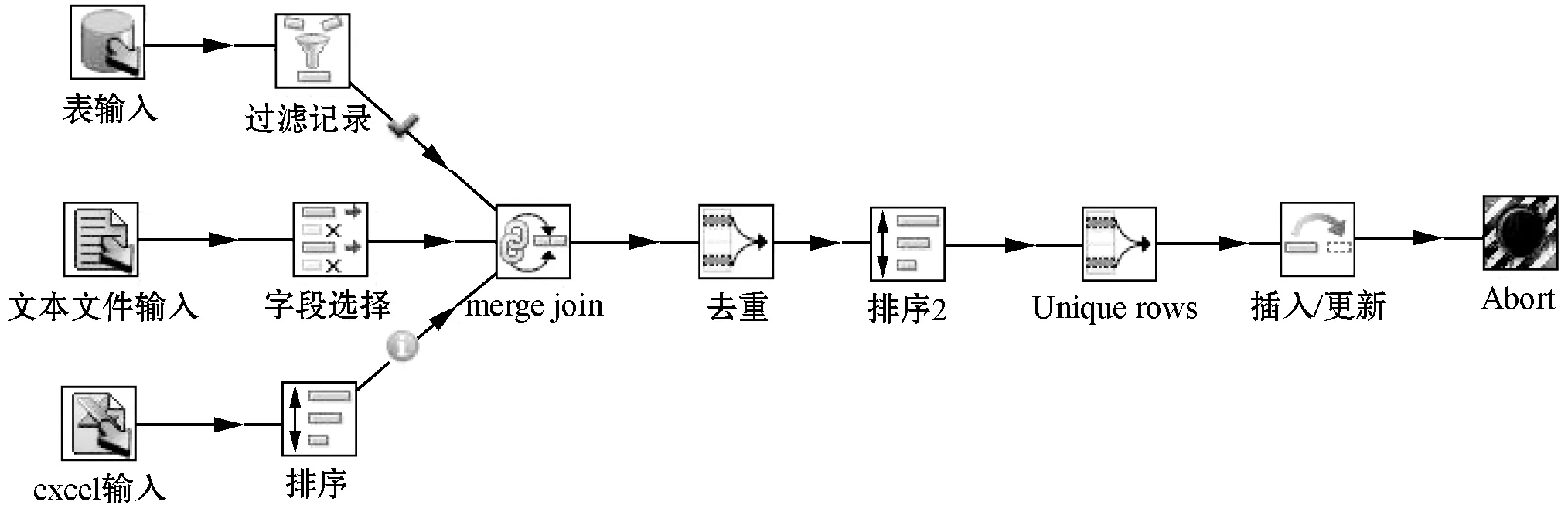
图6 多源数据抽取
2.4 数据安全管理
数据作为信息的重要载体,其安全问题在信息安全中占有非常重要的地位。本系统采用数据备份恢复、权限管理及防SQL注入等策略,保障数据的保密性、可用性、可控性和完整性。
2.4.1 数据备份策略
基于分布式Oracle数据库系统,在现有Data Guard系统上二次开发,实现太原主中心向青岛分中心和上海分中心的数据异地容灾功能。保障两个分中心与主中心数据的一致性,实现主中心的数据灾难恢复功能。同时基于RMAN模块开发各中心内部的数据备份子系统,实现定期数据备份,保障数据安全性。
2.4.2 权限管理策略
采用基于RBAC的权限管理模式。用户可以访问并且只能访问自己被授权的数据资源,有效地保护了敏感数据,提高数据安全性。
采用Shiro框架实现数据级权限管理,细分角色和权限,并将用户、角色、权限和资源均采用数据库存储,实现数据库行列级弹性控制。
2.4.3 防止SQL注入
通过设置系统访问安全控制功能,修订后台访问过滤规则,通过对用户输入的数据进行严格过滤、部署Web应用防火墙、对数据库操作进行监控等策略严防SQL注入和跨站攻击等入侵行为。
3 系统实现
碳排放数据集成管理系统对实地采样数据进行分析测试的基础上,采用Oracle 11g 平台,基于Spring、Struts2、Hibernate框架,使用J2EE 平台进行开发,前端页面采用基于jQuery的easyUI框架。根据项目任务书要求,紧密结合能源消费与水泥生产过程中的数据存取展示需要,建立了以数据采样、预处理、导入建表、反演预测为主线的数据处理流程。并提供良好的用户界面,以期让用户更加方便、高效地使用系统。系统集成展示界面如图7所示。
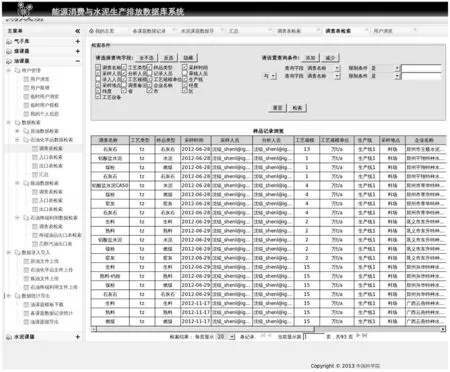
图7 系统集成展示界面
根据历年采样数据,基于IPCC重叠法,构建二氧化碳的反演模型,实现反演数据导入及动态展示功能,某课题反演图片如图8所示。
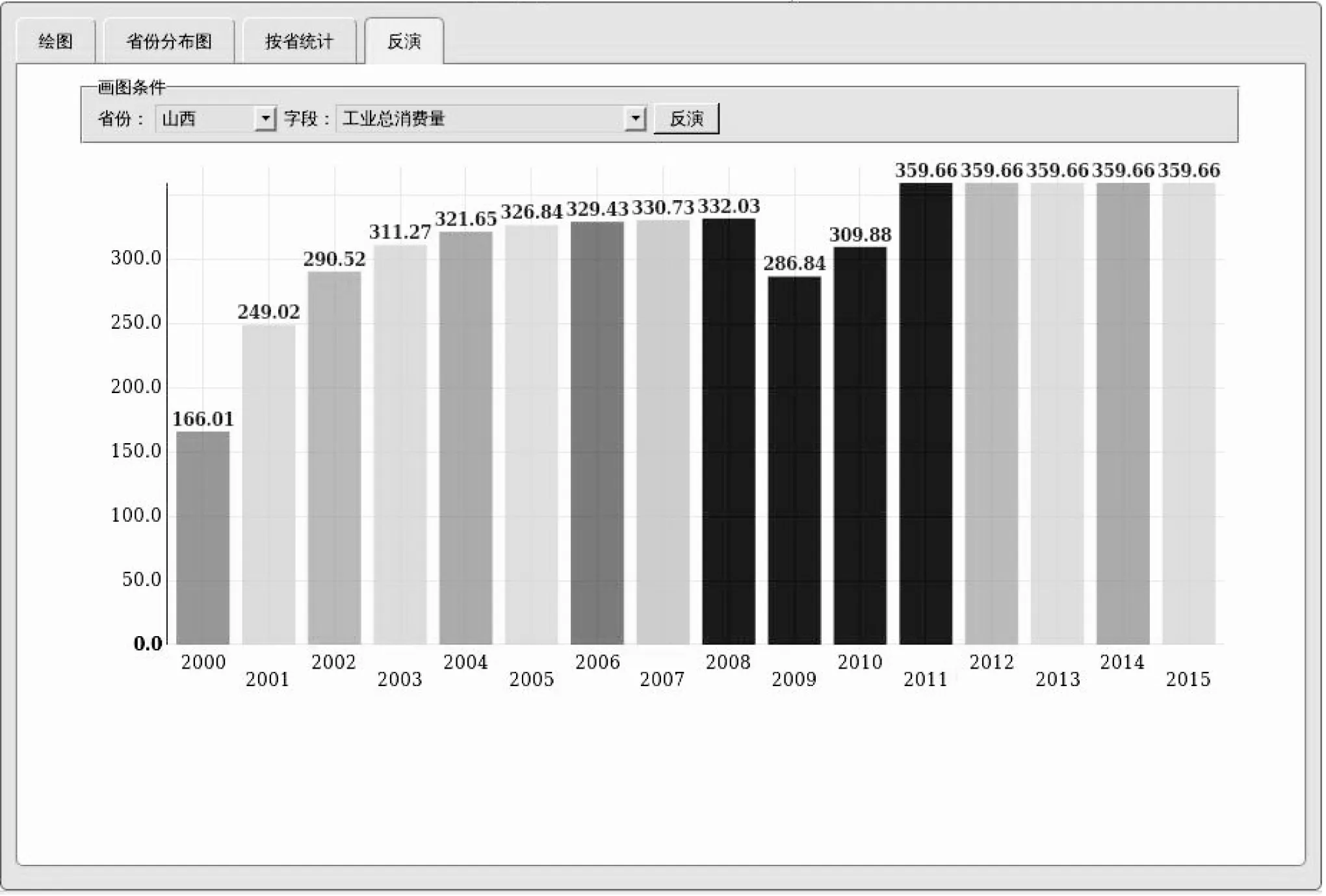
图8 某课题反演图
本系统自2015年在“能源消费与水泥生产的排放”项目组内部投入使用以来,辅助完成调查采样数据共两万余条。在此基础上,构建二氧化碳的反演和预测模型,分析我国10年时间跨度二氧化碳排放趋势,为国家温室气体清单的编制和减排政策的制定提供理论支持。
4 结 语
本系统建设历时五年,构建了集采样数据预处理、录入导入、分析挖掘、领域信息动态监测、信息展示网站于一体的碳排放数据集成管理系统,实现了对全国范围内能源消费与水泥生产的10年时间跨度的二氧化碳的排放量反演与预测的动态模型。目前系统运行状况良好,各功能模块均可正常访问,并已顺利通过专家验收,较好地完成了项目总体目标和预期成果。
[1] 丁仲礼, 傅伯杰, 韩兴国,等. 中国科学院“应对气候变化国际谈判的关键科学问题”项目群简介[J]. 中国科学院院刊, 2009, 24(1):8-17.
[2] Liu Z, Guan D, Wei W, et al. Reduced carbon emission estimates from fossil fuel combustion and cement production in China[J]. Nature, 2015, 524(7565):335-338.
[3] 吕达仁,丁仲礼.应对气候变化的碳收支认证及相关问题[J]. 中国科学院院刊,2012,27(3) :395-401.
[4] 谢守红,王利霞,邵珠龙.国内外碳排放研究综述[J].干旱区地理,2014(4):720-730.
[5] 魏伟, 任小波, 蔡祖聪,等. 中国温室气体排放研究——中国科学院战略性先导科技专项“应对气候变化的碳收支认证及相关问题”之排放清单任务群研究进展[J]. 中国科学院院刊, 2015(6):839-847.
[6] 张海藩,牟永敏.软件工程导论[M]. 6版. 北京: 清华大学出版社,2013.
[7] Oracle. Using RMAN to Back Up and Restore Files [EB/OL]. http://docs.oracle.com/cd/E11882_01/server.112/e25608/rman.htm.
[8] Oracle. Introduction to Oracle Data Guard[EB/OL]. http://docs.oracle.com/cd/E11882_01/server.112/e25608/concepts.htm.
[9] 陈俊宁.海上试验场综合数据集成与管理系统设计与实现[D].山东:中国海洋大学,2015.
[10] 赵伟,王志华,周兵.基于MVC的e-ERP系统的设计与实现[J].计算机应用与软件,2013,30(2):106-109.
[11] 王艺霖,金澈清,王晓玲.公交数据管理系统的设计与实现[J].计算机应用,2016,36(S1):240-242,248.
[12] The Intergovernmental Panel on Climate Change (IPCC).2006 IPCC Guidelines for National Greenhouse Gas Inventories [R/OL].2006. http://www.ipcc-nggip.iges.or.jp/public/2006gl/.
[13] 张利平,于贞杰,张建华,等.六种时间序列组合建模及应用[J].统计与决策,2016(14):71-73.
[14] Matt Casters, Roland Bouman, Jos van Dongen,等. Pentaho Kettle解决方案:使用PD构建开源ETL解决方案[M]. 北京: 电子工业出版社,2014.
DESIGNANDIMPLEMENTATIONOFCARBONEMISSIONDATAINTERGRATIONMANAGEMENTSYSTEMBASEDONINVERSIONMODEL
Wang Nana1Qiao Yinghe1Mu Bin2Wang Wei3
1(QingdaoInstituteofBioenergyandBioprocessTechnology,ChineseAcademyofScience,Qingdao266101,Shandong,China)2(QingdaoCoastalEngineeringBureau,Qingdao266101,Shandong,China)3(InstituteofMountainHazardsandEnvironment,ChineseAcademyofSciences,Chengdu610041,Sichuan,China)
We designed and constructed the integrated management system of carbon emission data based on inversion model, considering the data in the "energy consumption and carbon emissions of cement production" project. The system provides the sample data pre-processing, input, analysis, mining and inversion prediction and other functions. This paper focuses on the analysis of the system design and development of the architecture design, data preprocessing and inversion prediction model and other key modules. The practices show that the adoption of these modules in carbon emissions data integrated management system, is conducive to the unified management of multi-source data display, and to precisely determine the coefficient of carbon emissions of China’s energy consumption and cement production process.
Carbon emission Data preprocessing Data mining Inversion Forecast
2016-08-24。中国科学院战略性先导科技专项(XDA05010000)。王娜娜,工程师,主研领域:科研信息化。乔英合,工程师。牟斌,工程师。王伟,本科。
TP311
A
10.3969/j.issn.1000-386x.2017.08.008
