基于增量支持向量机的入侵检测算法
2017-08-08杜红乐
杜红乐, 张 燕
(商洛学院 数学与计算机应用学院, 商洛 726000)
基于增量支持向量机的入侵检测算法
杜红乐, 张 燕
(商洛学院 数学与计算机应用学院, 商洛 726000)
针对网络入侵检测无法识别新的入侵行为,利用增量学习不断完善分类器,使得分类器可以识别新的入侵行为。提出一种基于相似度的增量支持向量机算法,该算法依据新增样本与支持向量之间的相似度来选择样本(当前分类器缺少该样本的空间信息),然后加入训练集中参加下一次迭代训练。实验结果表明,该算法能够提高最终分类器的分类精度和算法的训练速度。
支持向量机; 入侵检测; 相似度
0 引言
支持向量机(support vector machine,简称SVM)[1]是在统计学习理论基础上发展起来的一种新的机器学习方法,它基于结构风险最小化原则,在解决小样本、非线性及高维模式识别问题中表现出许多特有的优势,近年来,SVM在许多领域都取得广泛的应用。
在实际的应用中往往无法一次性收集到完备的数据集,数据集是在使用的过程中逐渐收集的,例如入侵检测中,入侵行为不断更新,永远无法收集完备的数据集,需要分类器在使用的过程中不断学习新的数据,逐渐完善分类器,增量学习算法应运而生。支持向量机增量学习算法主要算法层面[1-5]和数据层面[6-15]两种,算法层面主要是利用当前分类器的计算信息和新增样本信息获得新的分类器,无需迭代训练;数据层面方法多是针每次迭代中原有样本的筛选及对新增样本的筛选,目的在于保证算法的速度,同时保证分类器的分类精度。对新增样本通过一定方法,选择样本包含的空间信息是分类器缺少的样本加入下一次训练,从而把新增样本中的空间信息逐渐纳入到分类器中。文献[6]充分利用KKT条件,利用最大似然确定边界向量,然后把确定的边界向量加入到训练集中,进行下一次迭代;文献[7]利用KKT条件及时淘汰对后续训练影响不大的样本,同时保留包含重要信息的样本,可以有效提高算法的训练速度;文献[8]依据相似度选择样本,保证所选样本的质量,同时利用误差驱动的原则对原有样本进行删减,可以删除包含空间信息少的以及噪声样本,可以提高算法速度;文献[9]根据加入新增样本后支持向量集的变化,淘汰那些对最终分类无用的样本,提出基于密度法的支持向量机增量学习淘汰算法;文献[10]提出球结构多类SVM 增量学习算法,该算法将新增样本集中根据KKT条件选取部分样本和原始训练集中的支持向量以及分布在球体一定范围内的样本合并作为新的训练集,完成分类器的重构;文献[11]利用新增样本到类中心的距离计算概率密度,依据概率密度选择样本加入下一次迭代,但是该方法每次需要计算到所有样本的距离,会影响算法的速度。基于以上分析,通过计算每个新增样本与正类支持向量及负类支持向量的相似度,然后利用相似度选择加入下次迭代的样本,把该算法叫作基于相似度的增量支持向量机算法,并把该算法应用到入侵检测中,仿真实验结果表明算法的有效性。
1 相似度
SVM为解决线性不可分问题,使用核函数将样本从输入空间映射到某一特征空间中,使得样本在该特征空间中线性可分,设映射函数为:φ:Rk|→F,核函数为K(x,y)=<φ(x),φ(y)>,常采用的核函数有高斯核、多项式核、RBF核等等,SVM的计算过程是在核空间下进行的,因此为了更准确的描述样本与支持向量之间的关系,在核空间下计算样本与支持向量之间的距离,设样本x、y,则两样本之间的距离d(x,y)在核空间下表示,为式(1)。
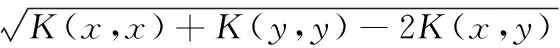
(1)
若采用RBF核函数,即K(x,y)=exp(-g||x-y||2),则两样本之间的距离为式(2)。
(2)
对于增量样本的xi,对正支持向量和负支持向量的相似度用到达正负支持向量的平均距离的倒数表示,计算方法如式(3)。
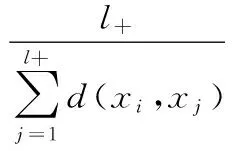

其中l+、l-分别表示正负支持向量数量,d(x,y)在核空间下计算,本文实验中计算相似度的核函数与支持向量机采用相同的核函数,都采用的RBF核函数。
2 增量支持向量机算法
2.1 算法原理
增量学习为了减少每次迭代的训练时间,需要选择对分类器有改变的样本进入训练集,即选择选择的样本所包含空间信息是当前分类器缺少的,例如依据KKT条件[9]、依据概率密度[10]等选择样本进行迭代。
对增量样本集中的每个样本,计算对正负支持向量的相似度,分别依据正负相似度进行排序,选择K个相似度大的样本,对于正相似度,若样本的实际类别为正,则样本不做处理,否则就把该样本放入T中;对于负相似度,若样本实际类别为正,则把该样本放入T中,重新训练得到新的分类器和支持向量。K值是为了控制算法速度,K值越大,每次迭代中的训练集规模就越大,但迭代次数会减少;K值小,则迭代次数增加,迭代中训练集规模减小。
2.2 算法步骤
算法:增量支持向量机算法SISVM
输入:初始训练集集T,增量样本集U,选择样本数K
输出:最终分类器
step1.用SVM对初始训练集T进行训练,得到分类器f和支持向量SV+和SV-;
step2.增量样本选择:
step2.1 判断增量样本集T是否为空,若为空则算法终止;否则,对T中的每个样本,利用计算与正负支持向量的相似度;
step2.2 对正负支持向量相似度进行排序,选择其中K个相似度值大的样本,若S+(xi)≥S-(xi),且样本的实际类别为负,则把该样本放入Temp中;若S+(xi)≤S-(xi),且样本实际类别为正,则把样本放入Temp中,同时从U中删除该样本;
step2.3 判断Temp是否为空,若不为空,则合并Temp和T,重新训练得到新的分类器和支持向量集,返回step2;若为空,则直接返回step2;
step3. 得到最终分类器。
该方法与PISVM相比,PISVM需要计算每个增量样本与当前训练集中每个样本的距离,而本文算法只需计算与支持向量之间的距离,而支持向量数量要小于训练集,因此可以提高算法速度;PISVM算法每次迭代选择1~2个样本,而本文算法通过调控参数K控制每次选择样本的数量,引入S+(xi)≥S-(xi)和S+(xi)≤S-(xi)的判断,确保被选择样本包含有分类器缺少的空间信息,提高准确度。
3 实验及数据分析
本文中所做实验是在Matlab 7.11.0环境下,结合台湾林智仁老师的LIBSVM[16],主机为Intel Core i7 2.3GHz,4G内存,操作系统为Win7的PC机上完成。
3.1 数据集
KDDCUP1999[17]数据集是关于入侵检测的标准数据集,包括训练集和测试集,其中训练集有494022条记录,测试集有311030条记录,训练集中包含24种攻击,而测试集有38种攻击。本文算法是针对二类分类问题,把数据集也看作是两类分类数据,把所有攻击数据看作一类。KDDCUP99数据集的41个数据属性中,有数值型,也有字符型,因此首先对数据集进行数值化和归一化,数值化是对字符类型数据用数字进行简单的替代,归一化采用LIBSVM中的归一化工具进行处理。为了验证算法的有效性,从数据集中取了2组数据集data1和data2,每组实验数据从训练数据中去300条记录作为初始训练集(Train set),从测试数据集中取出1000条记录作为增量样本集,数据集1中的测试集是数据集2的增量样本集,数据集2中的测试集用的是数据集1中的增量样本集,详细的数据集分布情况如表1所示。
3.2 实验结果及分析
对于入侵检测来说,为了更准确的描述算法的有效性,不仅要对比算法的整体准确率,还要综合考虑对样本的查准率和查全率,因此本文主要从准确率、查准率、查全率以及算法时间方面进行对比,验证本文算法的有效性,其中算法PISVM来自于文献[10] 。

表1 实验数据集
从整体、正常行为、攻击行为、已有攻击、未知攻击几方面的分类准确率进行对比,如表2所示。
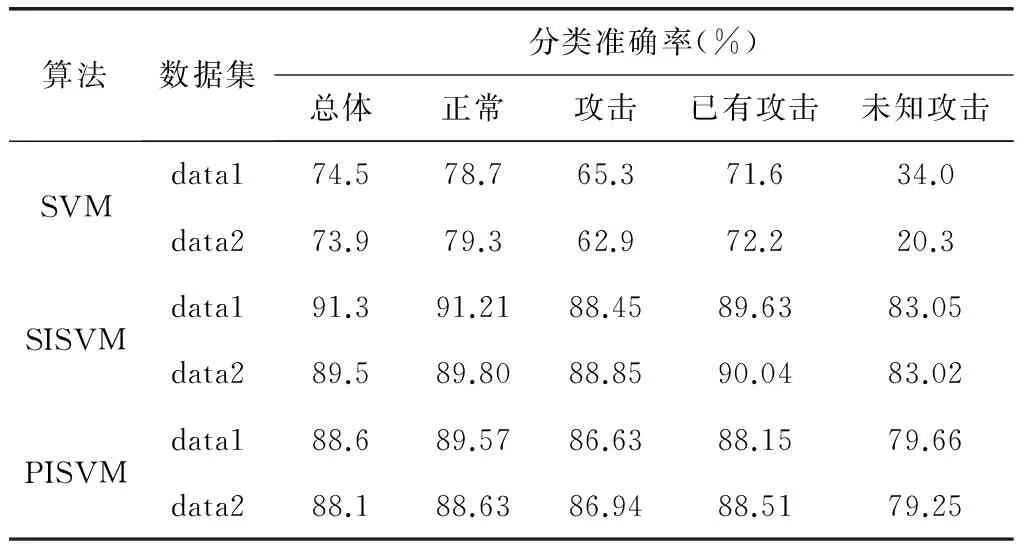
表2 准确率对比
查准率进行对比的结果,如表3所示。

表3 查准率对比
表3中,SVM算法结果是直接对300个样本进行训练,得到分类器对1000个测试样本进行测试的结果,由于未能学到新攻击类型数据的空间信息,导致对未知攻击的分类准确率较低;PISVM算法是根据新增样本到各类中心距离计算概率密度,然后依据概率密度选择加入训练集的样本,用成对标注的直推式支持向量机算法,该算法的前提是两类样本数量相当,而实际的测试集中两类样本不均衡,因此,分类准确率仍不理想,但学习了测试样本及未知攻击类型的空间分布信息,因此分类准确率有了明显的提升;TISVM是本文算法的分类结果,该算法可以尽快获得无标签样本中的空间信息,减少错误的传递和累积,因此对分类准确率及未知攻击的分类准确率都有了明显的提高,实验结果是K=2时候的结果,如表2、表3所示。
从实验结果中可以看到,data1的实验结果要比data2的结果好,无论是准确率海是查准率,分析数据可以看到,data1中的攻击数据数量多于data2中,data1和data2都属于不均衡数据,并且data1中未知攻击数据也多于data2中,因此data1所得的实验结果优于data2的实验结果。
4 总结
入侵检测要不断适应新的攻击行为,需要不断完善分类器,增量学习可以很好解决这样的问题,本文利用新增样本与支持向量的相似度对新增样本进行删除,保留包含丰富空间信息的样本,从而提高算法的速度和精度。然而不均衡数据下同样会导致分类超平面的偏移,会使错误累积和传递,不均衡数据集下的增量学习将是下阶段的主要工作。
[1] 权鑫,顾韵华,郑关胜,等.一种增量式的代价敏感支持向量机[J].中国科学技术大学学报,2016,46(9):727-735.
[2] 王洪波,赵光宙,齐冬莲,等.一类支持向量机的快速增量学习方法[J].浙江大学学报(工学版),2012,46(7):1327-1332.
[3] 郝运河,张浩峰.基于双支持向量回归机的增量学习算法[J].计算机科学,2016,43(2):230-234.
[4] 徐久成,刘洋洋,杜丽娜,等.基于三支决策的支持向量机增量学习方法[J].计算机科学,2016,42(6):82-87.
[5] 刘伟,谢兴生,肖超峰.一种基于支持向量阈值控制的优化增量SVM算法[J].计算机工程与应用,2015,51(3):124-128.
[6] 曹健,孙世宇,段修生,等.基于KKT条件的SVM增量学习算法[J].火力与指挥控制,2014,39(7):139-143.
[7] 马占飞,樊捷杰,张文兴.广义KKT约束的增量支持向量机建模研究[J].机械设计与建造,2015,(11):167-170.
[8] 丰文安,王建东,陈海燕.一种快速SVR增量学习算法[J].小型微型计算机系统,2015,36(1):162-166.
[9] 李娟,王宇平.基于样本密度和分类错误率的增量学习矢量量化算法研究[J].自动化学报,2015,41(6):1187-1200.
[10] 潘世超,王文剑,郭虎升.基于概率密度分布的增量支持向量机算法[J].南京大学学报(自然科学版),2013,49(5):603-610.
[11] 王立梅,李金凤,岳琪.基于k均值聚类的直推式支持向量机学习算法[J].计算机工程与应用,2013,49(14):144-146.
[12] 杨海涛,肖军,王佩瑶,等.基于参数间隔孪生支持向量机的增量学习算法[J].信息与控制,2016,45(4):432-436.
[13] 郭虎升,王文剑, 潘世超.基于组合半监督的增量支持向量机学习算法[J].模式识别与人工智能,2016,29(6):504-510.
[14] 杜红乐,滕少华,张燕.协同标注的直推式支持向量机算法[J].小型微型计算机系统.2016,37(11):2443-2447.
[15] Xie Zhiqiang, Gao Li, Yang Jing. Improved multi-class classification incremental learning algorithm based on sphere structured SVM [J]. Journal of Harbin Engineering University. 2009, 30(9):1041-1046.
[16] Chang C C, Lin C J. LIBSVM: A library for support vector machines. (2014-07-10). [EB/OL]. http://www.csie.ntu.tw/~cjlin/libsvm.
[17] http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html. 1999.
Intrusion Detection Based on Incremental Support Vector Machine
Du Hongle, Zhang Yan
(School of mathematics and computer application, Shangluo University, Shangluo 726000, China)
Because network intrusion detection system cannot identify new intrusion behavior, incremental learning can improve classifier, and classifier can identify the new intrusion behavior. This paper presents an incremental support vector machine algorithm based on similarity. The algorithm selects the sample according to the similarity between the new samples and support vectors. These samples contain the spatial information that the current classifier lacks. Then these samples are added to the training center for the next iteration. This algorithm can improve the training speed and classification accuracy. Finally, the experimental results show that the proposed algorithm can improve the classification accuracy and the training speed.
Support vector machine; Intrusion detection; Similarity
陕西省自然科学基础研究计划资助(2015JM6347)、陕西省教育厅科技计划项目(15JK1218)、商洛学院科学与技术研究项目(15sky010)
杜红乐(1979-),男,硕士,讲师,研究方向:机器学习、数据挖掘。 张燕(1977-),女,硕士,讲师,研究方向:模式识别、机器学习。
1007-757X(2017)07-0015-03
TP301.6
A
2016.10.30)
