深度学习算法在藏文情感分析中的应用研究*
2017-07-31普次仁侯佳林翟东海1
普次仁,侯佳林,刘 月,翟东海1,
1.西藏大学 藏文信息技术研究中心,拉萨 850000
2.西南交通大学 信息科学与技术学院,成都 610031
深度学习算法在藏文情感分析中的应用研究*
普次仁1+,侯佳林2,刘 月2,翟东海1,2
1.西藏大学 藏文信息技术研究中心,拉萨 850000
2.西南交通大学 信息科学与技术学院,成都 610031
+Corresponding author:E-mail:441436418@qq.com
PU Ciren,HOU Jialin,LIU Yue,et al.Deep learning algorithm app lied in Tibetan sentiment analysis.Journalof Frontiersof Com puter Scienceand Technology,2017,11(7):1122-1130.
针对以往进行藏文情感分析时算法忽略藏文语句结构、词序等重要信息而导致结果准确率较低的问题,将深度学习领域内的递归自编码算法引入藏文情感分析中,以更深层次提取语义情感信息。将藏文分词后,用词向量表示词语,则藏文语句变为由词向量组成的矩阵;利用无监督递归自编码算法对该矩阵向量化,此时获得的最佳藏文语句向量编码融合了语义、语序等重要信息;利用藏文语句向量和其对应的情感标签,有监督地训练输出层分类器以预测藏文语句的情感倾向。在实例验证部分,探讨了不同向量维度、重构误差系数及语料库大小对算法准确度的影响,并分析了语料库大小和模型训练时间之间的关系,指出若要快速完成模型的训练,可适当减小数据集语句条数。实例验证表明,在最佳参数组合下,所提算法准确度比传统机器学习算法中性能较好的语义空间模型高约8.6%。
深度学习;情感分析;递归自编码;递归神经网络
1 引言
文本情感分析,即针对“人们关于产品、服务、事件等实体的评论”等文本内容做出的情感分类及预测,在自然语言处理中占有极其重要的地位[1]。藏语作为人类语言的一种,在藏族日常文化交流和信息传递中极其重要,因此针对藏语的文本情感分析,在挖掘藏语文本隐藏信息,了解藏族文化特色及提高国家语言监测力上有较大的作用[2]。而当前的情感分析算法,大多基于传统的机器学习算法,如支持向量机、条件随机场、信息熵等。将这些算法归纳起来可分为3类:有监督、无监督和半监督学习。有监督学习虽然效果不错,但需要大量的人工标注数据集;无监督学习完全依赖算法,虽然减少了人力成本,但效果不太理想;而半监督学习依赖少量人工标注数据集,借助算法,往往可将结果发挥到最佳[3]。许多学者都利用传统的机器学习算法,对文本情感分析进行大量的研究。文献[4]利用文本特征信息分别对朴素贝叶斯、最大熵、支持向量机3种模型进行训练,结果表明,支持向量机在选用一元词作为特征时准确率最高。文献[5]通过分析文本中短语与正向和负向情感词的关联度,并计算正向关联度和负向关联度的差值来判断文本极性,以进行情感分析。文献[6]提出的Dependency-Sentiment-LDA模型,将情感词的话题语境和局部依赖关系加入进去,大大提高了情感分析的精确度,但此模型依赖人工标注数据集,降低了整体性能。在微博情感分析中,文献[7]利用微博中文本的标签、表情符号等特征,训练分类器进行文本情感分析。文献[8]则将藏语句法结构和语义特征向量结合起来构建语义特征空间,进行藏文微博的情感分析。
以上皆是浅层的机器学习算法,然而随着大数据时代的到来[9-10],浅层学习在依靠海量信息做出分析、预测的今天,已经越来越不能满足人们的需求。2006年,Hinton等人[11-12]提出的深度学习,以在海量数据中优异的学习能力,给解决这一问题带来了福音。接着,Mnih和Hinton[13]提出了一种可扩展的分层神经网络语言模型,提高了神经网络语言模型的训练速度和结果精确度。文献[14]提出了一种循环神经网络的深度学习模型,建模时考虑语料的上下文信息,大大降低了模型的出错率。以上模型均忽略了文本语义的结构信息,以致结果仍不太理想。深度学习中的递归自编码模型,因将语义信息融合在树形结构中,在文本特征提取、情感分析中表现优异,受到诸多研究者的青睐。文献[15-17]皆是较好的范例。文献[15]首次用词向量取代词袋模型对词进行编码,以半监督递归自编码的方式训练模型,取得了不错的分析效果。文献[16]在词向量表示词语的基础上,又引入矩阵来记录修改与中心词组合的词表示法,以使预测更加准确。文献[17]针对文献[16]中参数太多的缺点,引入张量进行坐标变换,以降低整体算法的参数数量。
由于藏语是小语种语言,专门针对藏语进行情感分析的研究少之又少,本文在广泛阅读前人资料的基础上将深度学习算法引入藏文情感分析领域,以提高藏语情感分析的准确度。本文所做工作大体可分为以下三部分:首先,将深度学习中的半监督递归自编码模型结合藏语特点引入藏文情感分析领域,以更深层次学习语义结构信息,提高分析精确度;其次,探索了该模型在藏语环境下向量维度、数据集大小及重构误差对情感分析结果的影响,并找出最佳组合以达到最好的分析效果;最后,通过实例验证表明,本文模型比传统的支持向量机、特征融合等情感分析准确度要高。
2 半监督递归自编码模型
本文利用半监督递归自编码模型并结合藏语特点,进行藏文情感分析。首先,对训练集中的藏文语句进行分词处理,然后利用词向量对词语进行编码,这样一条语句可以用一个矩阵来表示;其次,引入半监督递归自编码模型,将藏文语句的矩阵表示转换成向量;再次,将语句向量和其对应的情感标签作为输入,有监督地训练输出层,以预测藏语情感信息;最后,讨论向量维度、数据集大小及重构误差系数对模型的影响。
2.1 用词向量表示藏语词语
首先,采用西藏大学藏文信息技术研究中心研发的藏语分词软件对训练集语料进行分词处理。然后,对词语进行向量编码。如可将词语“བོ བོད་རརིགས(藏族)”表示为[0.1,0.2,0.7,0.5],“སྤུ ན་ཟླ(同胞)”表示为[0.9,0.5,0.6,0.4]。因此,一条分词后的藏语句子可用矩阵表示。抽象来说,若一条语句x含有m个词,则此语句可表示为x[1:m],句子中第k个词可用xk表示。至于xk的向量维度,将在2.4节中讨论,此处假设维度为n,则xk∈Rn,R为实数。若句子中有v个词,则藏文语句可用矩阵L∈Rn×|v|表示。
2.2 无监督贪心迭代
传统的递归自编码算法是如图1所示,将句子中相邻节点组合成新的节点,以层层推进的方式得到最终藏语句子的向量表示。若一条藏文语句x用向量表示为(x1,x2,…,xm),对应的词节点表示为(c1,c2,…,cm),即词c1的向量表示为x1,词c2的向量表示为x2,以此类推。计算c1、c2父节点p1的方法如式(1):

其中,w(1)∈ Rn×2n为系数矩阵;b(1)为偏置项;f采用tanh函数。为了评估p1能否最大限度地表示原始节点c1、c2的信息,算法通过增加重构层(如图1中形如c′1、c′2的矩形节点所示),并计算重构层与原始层的误差来衡量信息前向传输时的损失程度,若误差过大,将迭代调整系数矩阵的权值,直至误差收敛。此处式(2)给出重构层节点c′1、c′2的计算方法,其他节点可以此类推。重构误差的计算方法如式(3)所示。
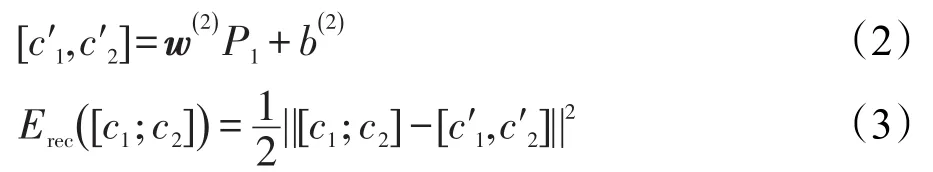
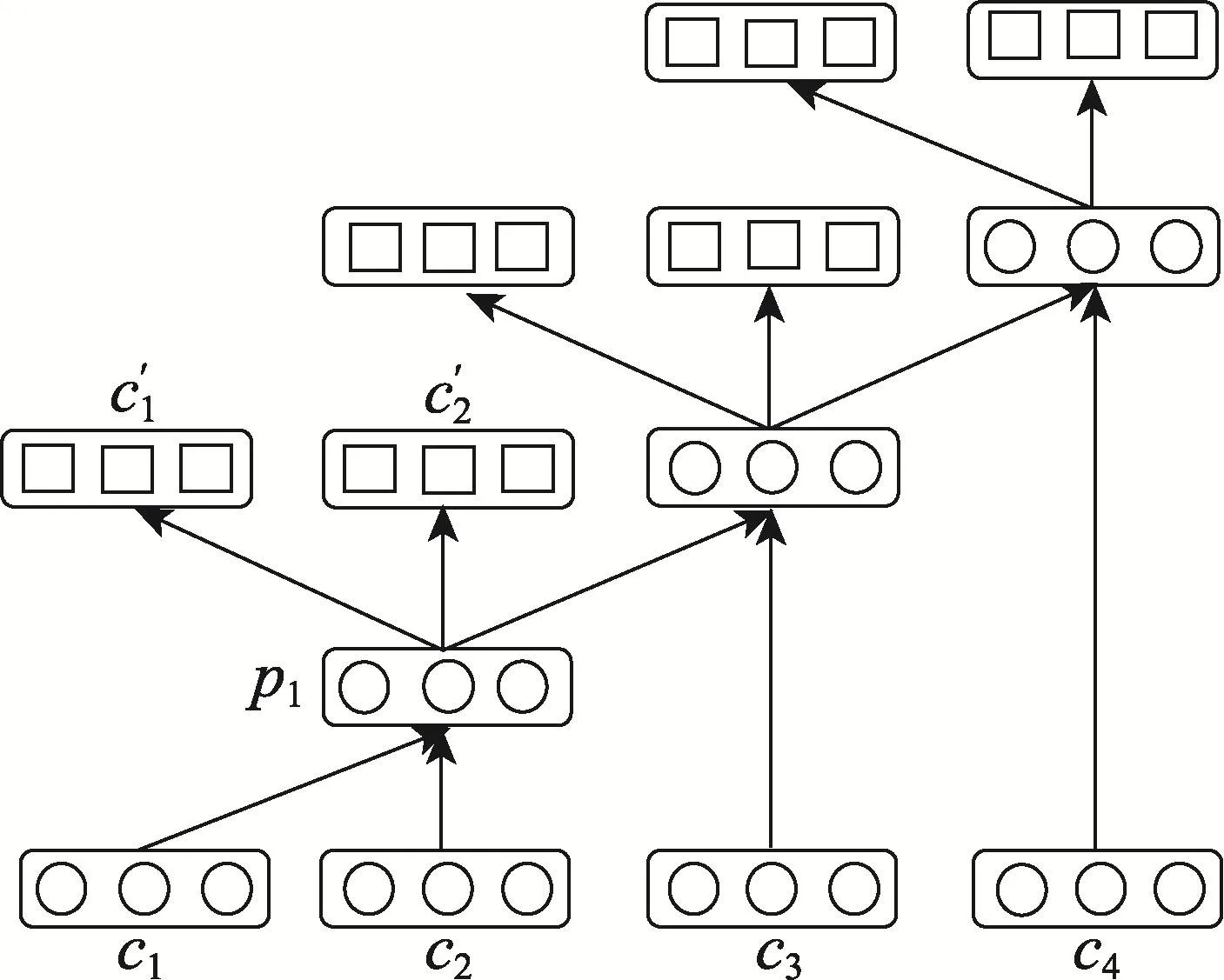
Fig.1 Traditional recursiveauto encoders图1 传统的递归自编码算法
由以上可知,传统的递归自编码算法是在树形结构已经确定的情况下,计算整体误差,然后调整权值,直至误差收敛的。然而,这种固定的树形结构,往往不能很好地表达句子的本意,即此种算法经过参数调整后所得的误差,仍然不是最小的。因此,本文将一种基于最佳树结构的递归自编码算法引入藏语的文本情感分析中。此算法基于贪心迭代的思想,可以很好地将前面生成的藏文语句的矩阵表示转换成向量表示。最佳树的生成算法思想如下:假如一条藏文语句x中有4个词,即x=(c1,c2,c3,c4),首先计算相邻词语间的重构误差,若(c1,c2)重构误差为E1,(c2c3)重构误差为E2,(c3,c4)重构误差为E3,且E2<E1<E3,则在生成树的第一层,将选用(c2,c3)进行组合,其父节点p2将进入第二层节点,此时第二层节点变为(c1,p2,c4);同理,接着计算第二层相邻节点间的重构误差,若(c1,p2)的重构误差小于(p2,c4),则(c1,p2)的父节点p3将进入第三层,此时第三层节点为(p3,c4),此时(p3,c4)的父节点即为该句子的最佳向量表示,整个过程以无监督的方式生成了最佳树结构。
以上建树过程,也是学习藏语句子内部词语间语序关系的过程,学习出的最优树结构,可以将整条语句的误差降低到最小值,即这种最佳的树结构很好地表达了原始语义。同时,为了突出树中不同层内节点间误差对整棵树误差贡献度不一样,在计算重构误差时加入了相应的权值,如式(4):
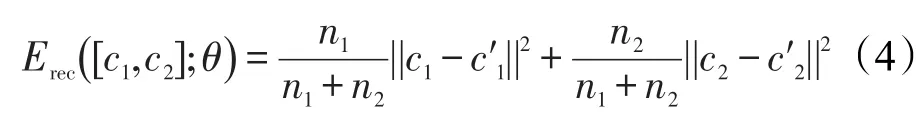
其中,n1、n2为当前节点c1、c2下面的词数。
计算父节点时,可以使用式(5)进行归一化,以方便计算:

2.3 有监督输出藏语情感倾向
当获得藏语句子的最佳向量表示后,需要加入输出层,输出句子的情感倾向。此处输出层是通过有监督的方式训练的,即在句子的向量表示和其相应的情感倾向已知的情况下,通过调整参数权值,以使预测结果最优。设藏文语句的向量表示为p,则输出层情感分类计算方法如式(6):

其中,softmax(·)为输出层分类器函数;wlabel为系数矩阵;label为情感分类数。输出层误差是以交叉熵的方式计算的,如式(7)所示:
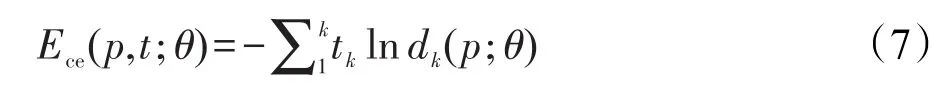
其中,d是一个k维的概率分布向量(此处情感分类数label=k),且d;tk为第k种情感的标签值。
2.4 半监督递归自编码算法
若藏文数据集大小为N,则本次优化的目标函数为式(8):

其中,E(x,t;θ)为一条语句的误差;∑(x,t)E(x,t;θ)则为整个数据集上的误差。计算一条语句的误差,也即遍历整棵树所有非终端节点并计算其误差累加和,计算方法如式(9):
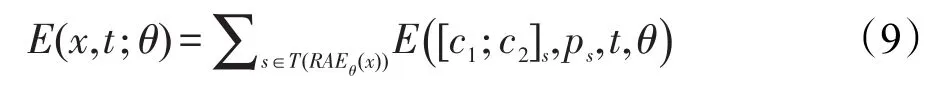
其中,s为一个非终端三元组;T()为遍历函数。为了使结果预测更加准确,在计算一个非终端三元组误差时,将重构误差和交叉熵误差结合起来计算,如图2所示。因为二者所占比重不同,需要加入参数α以调整二者比例,所以一个三元组s的误差计算公式为:
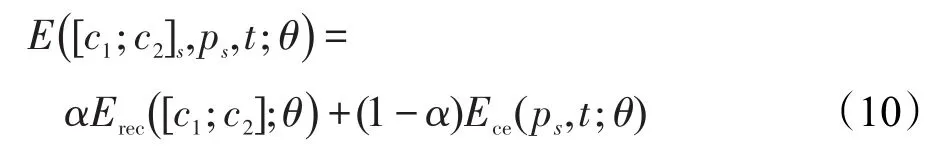
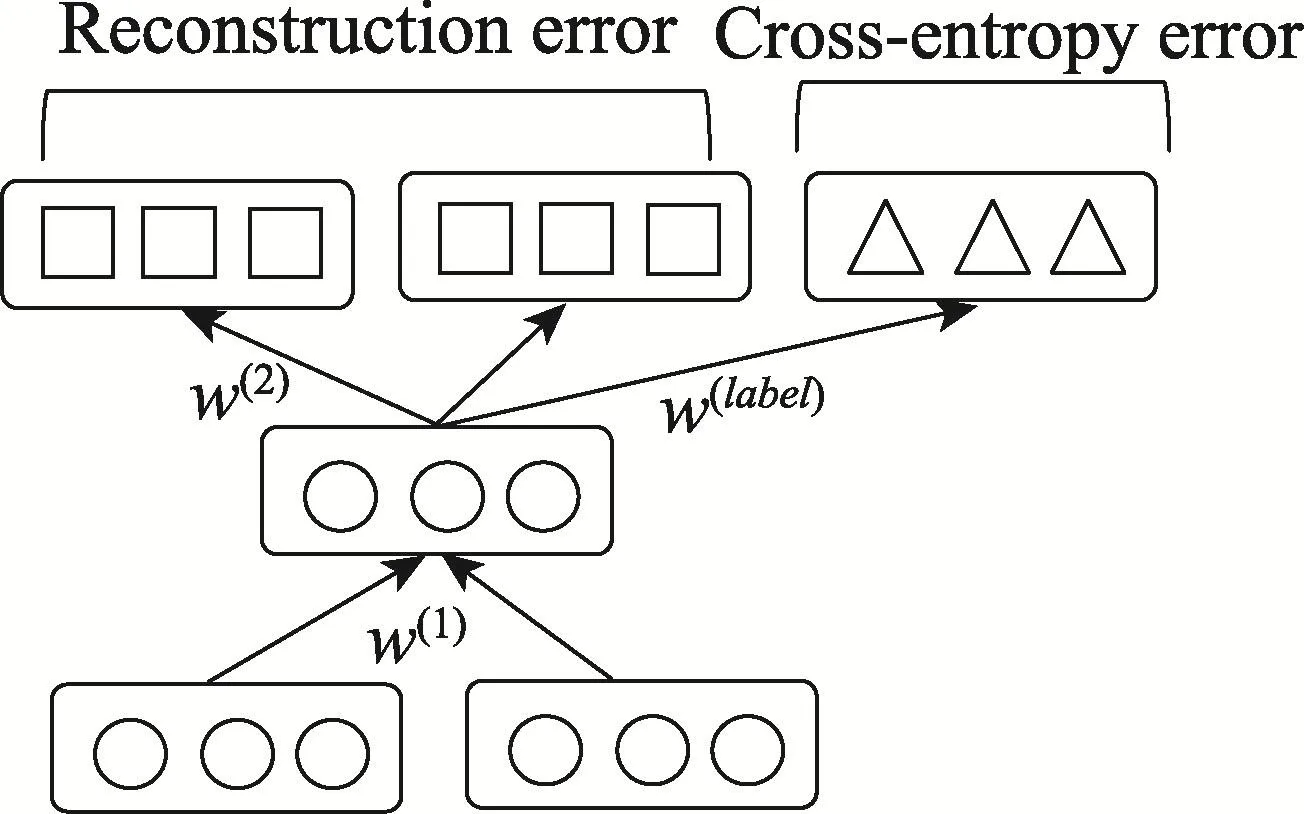
Fig.2 A nonterm inal treenode图2 一个非终端三元组
优化目标函数式(8)时,一般采用L-BFGS(limitedmemory BFGS)算法,可较快速度得出最优解,算法所用梯度为:
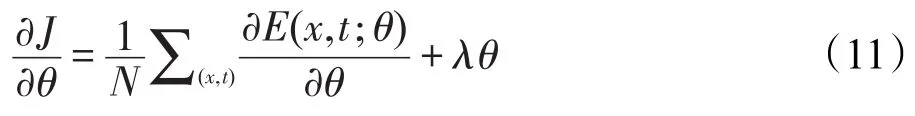
综上,此处给出本文进行藏语情感分析时所用算法。
算法TSSRAE(Tibetan sentiment analysis based on semi-supervised RAE)
参数说明:
TrainingData,训练数据集(带情感标签的藏语语料库);
θ,参数集
J,优化目标函数;
Jsum,训练集误差和;
x,训练集中的一条语句;
BestTreex,句子x的最优结构树
输入:TrainingData
输出:θ
1.Initializeθand usingwordsvector initializeTraining-Data;
2.J←0,Jsum←0;
3.Foreach sentencex∈TrainingData
4. ConstructBestTreexthrough greedy unsupervised RAE;
5.E(x,t;θ)←0;
6. Foreach non-term inalnodes∈BestTreex

12.Repeat2~11 untilJconvergence.
从上述算法训练过程可得,本文算法先以无监督的方式得到最佳树结构,然后整个模型在有监督的方式下得到最优参数集,因此本文算法属于半监督形式。
3 实例验证
此次实例验证分两部分:首先,找出递归自编码算法分析藏语情感倾向时的最佳参数组合;接着,利用这组参数组合初始化本文算法,并和传统算法作对比,以证明本文算法的有效性。
本文语料库由来自西藏大学藏文信息处理中心的多名骨干成员,在新浪微博、腾讯微博精选的44 000条藏文语句组成,情感倾向分积极和消极两类,其中积极情感在语料库中标记为1,消极为-1。语料库分为TibetanCorpus和TibetanCorpusTest两个。Tibetan-Corpus主要用于深度学习模型训练及后期不同算法之间训练时间、结果准确度对比;同时另增加Tibetan-CorpusTest测试语料库,以对比算法间的准确度和F值,增强实验结果的说服力。语料库详情如表1语料库信息表和表2语料库样例表所示。

Table1 Corpus information table表1 语料库信息表

Table 2 Corpusexample table表2 语料库样例表
3.1 参数选择
用本文算法进行藏文情感分析时,词向量的维度和重构误差系数对算法准确度的影响非常大。因此为了将模型训练到最佳状态,必须找出一组最优组合,使算法准确度达到最佳。文献[3,18]分别给出了中文和英文的选择方案,此处将通过大量尝试和多次实验的方式找出藏语下的最佳组合,即分别设置词向量长度为10,20,…,200,重构误差系数为0.1,0.2,…,0.9,采用排列组合的方式将二者的所有组合方案测试一遍,统计出最优组合。实验时,针对语料库TibetanCorpus采用十折交叉法(将语料库TibetanCorpus的4万条语句分成10份,轮流用其中9份做训练集,1份做测试集进行实验,结果准确度取10次实验的均值),以使结果更加准确。实验结果如表3词向量维度和重构误差系数选择表所示,统计相应重构误差系数和词向量维度下算法的准确度(准确度=预测正确条数/总条数)。
从表3中实验结果可得出,当重构误差系数为0.2,词向量维度为110时,本文算法在藏语语料库中准确率最高,可达87.2%。且实验数据表明,当重构误差系数为0.2时,不同向量维度下算法的准确率几乎都为当前维度下的最好值,进一步说明重构误差系数为0.2,是藏语环境下的最好选择。
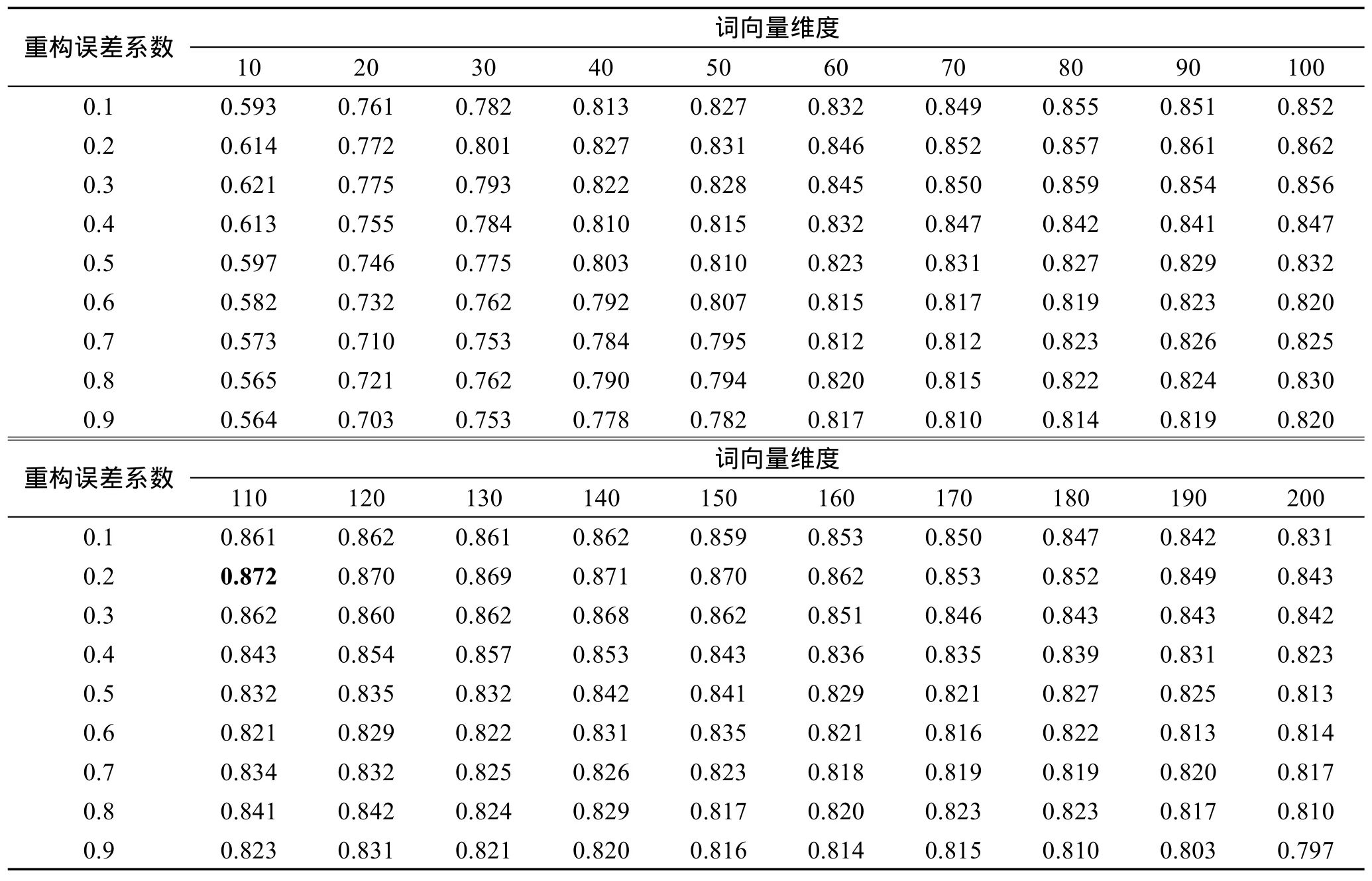
Table3 Selection tableofword vectordimensionsand reconstruction errorweights表3 词向量维度和重构误差系数选择表
接着,本文将验证语料库大小和情感分析准确率及训练时间之间的关系,以便后续研究者在准确率和训练时间之间正确地取舍。本次实验计算机采用AMD双核2.5GHz,内存4GB,采用十折交叉法,数据量大小从1万条语句逐渐增加到4万条,实验结果如图3、图4所示。
从图3实验结果可得出,随着数据量的增大,算法准确度逐渐提高,当语料库大小在1万条语句和2.5万条语句之间时,算法准确度增长较快;从2.5万条增加到4万条,准确度只增加了0.2%,说明一定范围内语料库的大小对算法准确度有较大影响,当语料库足够大时,单纯增加语料库的数据量,很难提高算法准确度。从图4可得出,随着语料库的增大,模型训练时间几乎成倍增长,从1万条语句时的5 h,到4万条语句的65 h,时间翻了13倍,而准确度却只增加了约1%。因此,若需要快速地将模型训练好并以用于情感分析,可适当减小训练集,这样在算法准确度改变不大的情况下,也能达到较好的情感分类效果。
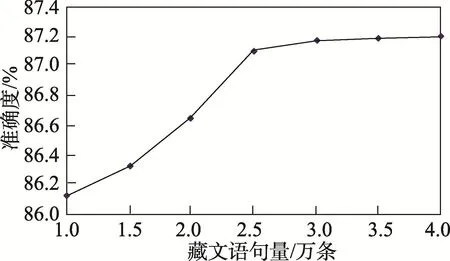
Fig.3 Relation between corpusamountand accuracy图3 语料库大小和准确度关系图
3.2 算法性能对比
3.2.1 准确度和F-measure
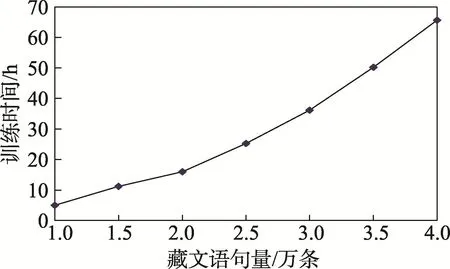
Fig.4 Relation between corpusamountand training time图4 语料库大小和训练时间关系图
为了验证本文算法的有效性,此处将本文所训练的深度学习算法和传统的支持向量机[19]、语义空间模型[8]及特征融合模型[20]进行藏文情感分析对比。此处深度学习模型重构误差系数为0.2,词向量维度为110。实验时,首先选取语料库TibetanCorpus,采用十折交叉法,分别测试语料库大小为0.3、0.6、1.0、4.0万条语句时算法的准确度,结果如图5所示;接着为了增强实验说服力,将以上算法在TibetanCorpus语料库的全部4万条数据下训练后,用TibetanCorpusTest进行测试,实验结果如表4所示。
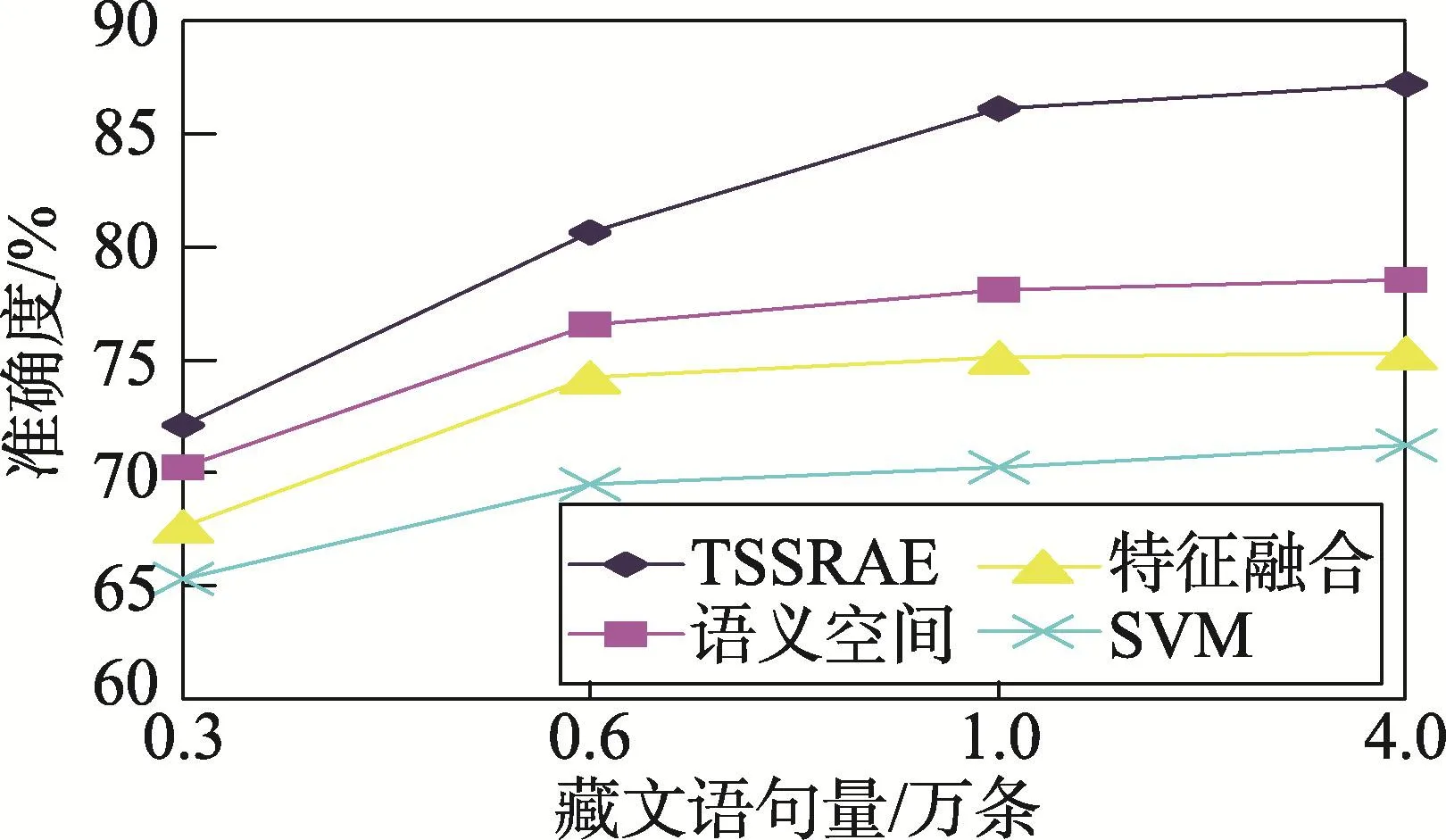
Fig.5 Accuracy comparison of differentalgorithms图5 算法准确度对比图
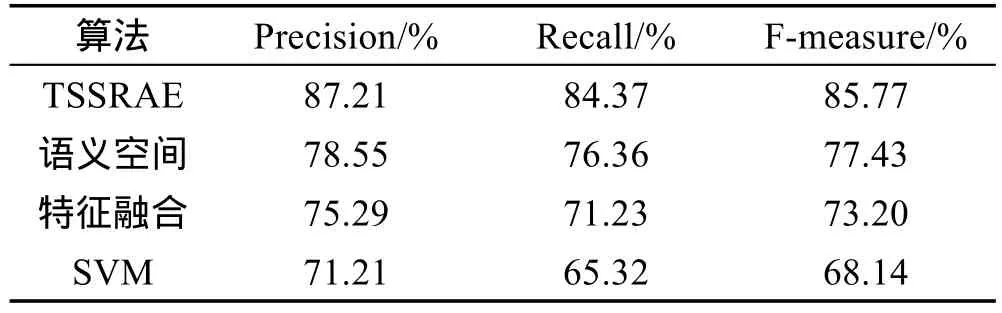
Table4 F-measure comparison of differentalgorithms表4 算法F-measure对比表
从图5结果可得,本文算法TSSRAE藏语情感分析的准确度比上述最好的传统机器学习算法的语义空间模型高约8.6%;从表4可得,在测试语料库TibetanCorpusTest中,TSSRAE模型的F值比语义空间模型高约8.3%。之所以TSSRAE模型表现优异,是因为深度学习模型能够更好地获取传统算法学习不到的文本语义结构信息,并将其保留在树形结构中,最终以向量的形式输出到分类器中进行情感分析,这些信息在语句情感分析中往往非常重要;并且深度学习算法经过层层的特征提取,将句子的矩阵表示映射到向量上,使获得的特征更加精简、充分,更加有利于后期进行情感分析。另外,图5中语料库从0.6万条语句增加到4万条时,传统算法准确度皆变化不大(最高约2.0%),而TSSRAE深度学习算法准确度增加了约6.5%,说明传统算法对语料库学习能力没有深度学习算法强,即深度学习算法能够从更多的语料中挖掘信息,以调整模型参数,使算法达到更佳状态,作出更准确的预测。
3.2.2 算法训练时间
此处研究算法在不同大小数据集下的训练时间,以进一步探讨其优劣。语料库选用TibetanCorpus,实验时分别测试不同算法在数据集为0.3、0.6、1.0、4.0万条语句时的训练时间,结果如表5所示。
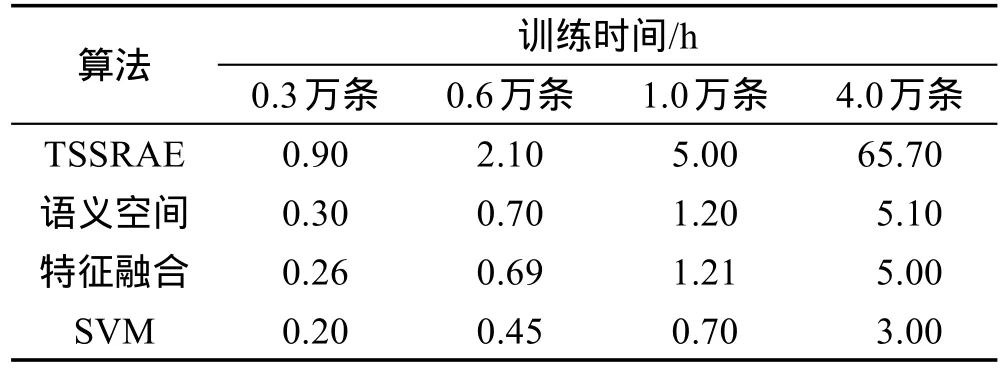
Table5 Time consuming comparison of differentalgorithms表5 算法训练耗费时间对比表
从表5可得,传统的语义空间模型、特征融合和SVM模型在训练时,训练时间约为线性增长,即数据集从0.3万到4万,扩大了约13倍,训练时间则从0.2~0.3 h,涨到了3.0~5.1 h,也增大了13倍左右;而深度学习模型TSSRAE,则从最初的0.9 h增长到了65.7 h,时间扩大了70多倍,说明深度学习算法虽然准确度较高,但是训练耗时太长,特别是在数据量较大情况下,要想获得较好的算法效果,更需要较长的训练时间。究其原因,和传统算法比,深度学习算法内部神经网络的参数调整,算法执行过程中不停地调优迭代,都是十分耗时的工作;数据量越大,每一轮的参数调整,所执行的任务也就越多,这样一轮一轮的任务叠加,使深度学习算法的训练时间几乎成指数级增长。
4 结束语
本文将深度学习算法引入藏语的情感分析中,并对其进行了进一步的融合,如藏语词向量的表示,藏文语句最优结构树的获取等,并通过大量实验找出了适合藏语的重构误差系数和词向量维度,以使算法性能达到最佳;同时本文还探讨了深度学习模型训练时间和语料库大小的关系,指出若要快速建立较好的模型,可适当减少语料库的大小;最后将本文深度学习藏语情感分析算法和传统机器学习算法进行对比实验,表明本文深度学习算法的有效性。当然,本文的研究也存在一定不足,如并未探究语料库大小对深度学习算法性能的影响,以及深度学习中参数较多引起的过拟合现象等,这都将成为本文今后工作的重心。
[1]Liu Bing.Sentiment analysis and opinionmining[M]//Synthesis Lectures on Human Language Technologies.San Rafael,USA:Morgan&Claypool Publishers,2012.
[2]Cao Hui,Dong Xiaofang,Meng Xianghe.Statistical research on Tibetan newspaperwords[J].Journal of Northwest University forNationalities:NaturalScience,2012,33(3):50-54.
[3]Liang Jun,Chai Yumei,Yuan Huibin,et al.Deep learning for Chinesemicro-blog sentimentanalysis[J].Journal of Chinese Information Processing,2014,28(5):155-161.
[4]Pang Bo,Lee L,Vaithyanathan S.Thumbsup?sentimentclassification using machine learning techniques[C]//Proceedingsof the2002Conference on EmpiricalMethods in Natural Language Processing,Pennsylvania,USA,Jul6-7,2002.Stroudsburg,USA:ACL,2002:79-86.
[5]Turney PD.Thumbs up or thumbs down?semantic orientation applied to unsupervised classification of reviews[C]//Proceedings of the 40th AnnualMeeting of the Association for Computational Linguistics,Pennsylvania,USA,Jul 7-12,2002.Stroudsburg,USA:ACL,2002:417-424.
[6]Li Fangtao,Liu Nathan,Jin Hongwei,et al.Incorporating reviewer and product information for review rating prediction[C]//Proceedings of the 22nd International JointConference on Artificial Intelligence,Barcelona,Spain,Jul 16-22,2011.Menlo Park,USA:AAAI,2009:1820-1825.
[7]Davidov D,TsurO,RappoportA.Enhanced sentiment learning using tw itter hashtags and smileys[C]//Proceedings of the 23rd International Conference on Computational Linguistics:Posters,Beijing,Aug 23-27,2010.Stroudsburg,USA:ACL,2010:241-249.
[8]Yuan Bin,Jiang Tao,Yu Hongzhi.Emotional classification method of Tibetan m icro-blog based on semantic space[J].Application Research of Computers,2016,33(3):682-685.
[9]Du Zhijuan,Wang Shuo,Wang Qiuyue,etal.Survey on social media big data analytics[J].Journal of Frontiers of Computer Scienceand Technology,2017,11(1):1-23.
[10]Hou Jialin,Wang Jiajun,Nie Hongyu.MapReduce performance optimization based on anomaly detection model in heterogeneous cloud environment[J].Journal of Computer Applications,2015,35(9):2476-2481.
[11]Hinton G E,Salakhutdinov R R.Reducing the dimensionality of data w ith neural networks[J].Science,2006,313(5786):504-507.
[12]Hinton G E,Osindero S.A fast learning algorithm for deep beliefnets[J].NeuralComputation,2006,18(7):1527-1554.
[13]Mnih A,Hinton G.A scalable hierarchical distributed language model[C]//Proceedings of the 21st International Conference on Neural Information Processing Systems,Vancouver,Canada,Dec 8-10,2008.Red Hook,USA:Curran Associates,2008:1081-1088.
[14]M ikolov T,KarafiátM,Burget L,etal.Recurrent neural network based languagemodel[C]//Proceedings of the 11th Annual Conference of the International Speech Communication Association,Chiba,Japan,Sep 26-30,2010.Red Hook,USA:Curran Associates,2010:1045-1048.
[15]Socher R,Pennington J,Huang EH,etal.Semi-supervised recursive autoencoders for predicting sentimentdistributions[C]//Proceedings of the 2011 Conference on EmpiricalMethods in Natural Language Processing,Edinburgh,UK,Jul 27-31,2011.Stroudsburg,USA:ACL,2011:151-161.
[16]Socher R,Huval B,Manning C D,etal.Semantic compositionality through recursivematrix-vector spaces[C]//Proceedings of the 2012 JointConference on EmpiricalMethods in Natural Language Processing and Computational NaturalLanguage Learning,Jeju Island,Korea,Jul 12-14,2012.Stroudsburg,USA:ACL,2012:1201-1211.
[17]Socher R,Perelygin A,Wu JY,etal.Recursive deepmodels for semantic compositionality over a sentiment treebank[C]//Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing,Seattle,USA,Oct18-21,2013.Stroudsburg,USA:ACL,2013:1631-1642.
[18]Socher R.Recursive deep learning for natural language processing and computer vision[D].Palo A lto:Stanford University,2014.
[19]Han Kaixun.Research on text sentiment analysis based on support vector machine[D].Daqing:Northeast Petroleum University,2014.
[20]Zhu Shaojie.Research on text sentiment classification based on deep learning[D].Harbin:Harbin Institute of Technology,2014.
附中文参考文献:
[2]曹晖,董晓芳,孟祥和.藏文报纸词语统计研究[J].西北民族大学学报:自然科学版,2012,33(3):50-54.
[3]梁军,柴玉梅,原慧斌,等.基于深度学习的微博情感分析[J].中文信息学报,2014,28(5):155-161.
[8]袁斌,江涛,于洪志.基于语义空间的藏文微博情感分析方法[J].计算机应用研究,2016,33(3):682-685.
[9]杜治娟,王硕,王秋月,等.社会媒体大数据分析研究综述[J].计算机科学与探索,2017,11(1):1-23.
[10]侯佳林,王佳君,聂洪玉.基于异常检测模型的异构环境下MapReduce性能优化[J].计算机应用,2015,35(9):2476-2481.
[19]韩开旭.基于支持向量机的文本情感分析研究[D].大庆:东北石油大学,2014.
[20]朱少杰.基于深度学习的文本情感分类研究[D].哈尔滨:哈尔滨工业大学,2014.

普次仁(1970—),男,西藏日喀则人,2008年于西藏大学藏文信息处理专业获得硕士学位,现为西藏大学副教授,主要研究领域为深度学习,数据挖掘,藏语情感分析。主持国家自然科学基金、西藏自治区科技厅软科学计划项目等,发表学术论文10余篇。

HOU Jialin was born in 1990.He is an M.S.candidate at School of Information Science and Technology,Southwest Jiaotong University.His research interests include deep learning and parallel computing.
侯佳林(1990—),男,河南洛阳人,西南交通大学信息科学与技术学院硕士研究生,主要研究领域为深度学习,并行计算。

LIU Yuewas born in 1993.She is an M.S.candidate at School of Information Science and Technology,Southwest Jiaotong University.Her research interest is deep learning.
刘月(1993—),女,四川达州人,西南交通大学信息科学与技术学院硕士研究生,主要研究领域为深度学习。

ZHAIDonghaiwasborn in 1974.He received the Ph.D.degree in traffic information engineering and control from Southwest Jiaotong University in 2003.Now he is an associate professor at School of Information Science and Technology,Southwest Jiaotong University.His research interests include deep learing,datam ining and image inpainting.
翟东海(1974—),男,山西芮城人,2003年于西南交通大学交通信息工程及控制专业获得博士学位,现为西南交通大学信息科学与技术学院副教授,主要研究领域为深度学习,数据挖掘,数字图像处理。主持国家自然科学基金、国家社会科学基金、西藏自治区科技厅科技计划项目等,发表学术论文30余篇。
Deep Learning Algorithm App lied in Tibetan SentimentAnalysis*
PU Ciren1+,HOU Jialin2,LIUYue2,ZHAIDonghai1,2
1.Tibetan Information Technology Research Center,TibetUniversity,Lhasa 850000,China
2.Schoolof Information Science and Technology,Southwest Jiaotong University,Chengdu 610031,China
During Tibetan sentimentanalysis in past,the algorithm always ignores some important information like sentences structure and words order etc,which lead low accuracy of sentiment analysis.To deeply getmore sentimentdetails,this paper proposesa novelapproach of Tibetan sentimentanalysisbased on deep learning.Firstly,one word in Tibetan is represented by aword vectorwhile one sentence is represented by amatrix which is composed by itsword vectors;Secondly,thematrix is turned into a vectorwhich containsmost importantdetails such as sentence meaning and words order etc,through an unsupervised recursive auto encoder algorithm;Finally,the classifier in output layer is trained by supervisedmethod which uses theword vectors and its sentiment tags.In the experiment part,this paper discusses the selection of word vector dimensions and reconstruction errorweights,studies corpus amounthow to affect algorithm accuracy,and analyzes the relation between corpus amount and training time.The experimental results demonstrate that the proposedmethod can improve accuracy up 8.6%compared w ith semantic spacemodelwhich isalmost the best in traditionalmachine learning algorithm.
was born in 1970.He
the M.S.degree in Tibetan information processing from Tibet University in 2008.Now he isan associate professoratTibetUniversity.His research interests include deep learning,datamining and Tibetan sentimentanalysis.
A
:TP391.1
*The National Natural Science Foundation of China under Grant No.61540060(国家自然科学基金);the National Soft Science Research Program of China underGrantNo.2013GXS4D150(国家软科学研究计划项目);the Research Program of Science and Technology Departmentof TibetAutonomousRegion(西藏自治区科技厅科学研究项目).
Received 2016-11,Accepted 2017-01.
CNKI网络优先出版:2017-01-05,http://www.cnki.net/kcms/detail/11.5602.TP.20170105.0828.004.htm l
Keywords:deep learning;sentimentanalysis;recursive auto encoder;recursive neuralnetworks
