基于统计距离和极大极小值的改进K—means算法研究
2017-07-29刘钢李宗辰
刘钢 李宗辰


摘要:该文在通过对传统K-means算法的深入研究后发现,数据集中存在着孤立点和算法的初始聚类中心选取是否合理都将会严重影响算法最终的聚类结果的质量。于是,该文针对K-means算法以上两点问题做出了优化,给出了一种基于统计距离和极大极小值原则的改进K-means算法(KSDM)。KSDM算法首先采用一种基于统计距离的孤立点检测算法对数据集中的数据进行检测,然后再通过基于极大极小值原则的初始聚类中心选取算法来选取初次划分的聚类中心对数据做聚类处理。经过大量实验分析、研究、验证,KSDM算法在孤立点检测方面效果明显,同时在选取初始聚类中心的方面较元算法相比更加的合理。
关键词:聚类;k-means算法;初始聚类中心;孤立点排除
1概述
随着互联网时代的飞速发展,数据的数量呈指数的爆增,在这些数据中存在着很多有价值的信息在等待着我们去发掘,于是,数据挖掘技术成为了互聯网时代信息领域的重点研究方向之一。数据挖掘技术“大家庭”的重要组成成员——聚类分析也是当前互联网时代的研究热点。聚类分析是将一个整体的数据集分解成若干个小的子集,而所得到的这些个子集的内部的数据对象的相似程度相对较高,而不同子集之间的数据对象的它们的差异性相对较大,相似程度也相对较低。其中,基于划分方法的K-means算法是在聚类领域中经典的算法之一,因为该算法操作简捷、运行时间较短以及收敛速度相对较快等多方面的优势,被大量学者应用、优化以及改进。但是,即使是经典的K-means算法中也存在着一些需要优化的不足之处;首先,需要进行聚类处理的数据集中存在着一些孤立点,孤立点就是那些在数据集中与其他数据对象相异度最高、相似度最低并且边缘化的数据点,所以会因为孤立点的存在,导致在算法的运行过程以及最后的聚类结果的质量都造成影响。其次,传统的K-means算法的初次划分的聚类中心是由算法随机选择出来的,由于随机选择的合理性不稳定,所以很容易使算法陷入局部最优;所以,初次划分的聚类中心选择是否合理也将决定着最后的聚类结果的质量的好坏。另外,在随着对传统的K-means算法的深入研究发现,K-means算法在整个聚类的过程中,要对上一次聚类得到的簇求得均值,然后再以求得的均值为聚类中心重新聚类,需要连续不断地重复这一过程直到准则函数收敛给出聚类结果;因此,当初始聚类中心选取的不合理时,会使算法增加的迭代次数,延长算法的运行时间。
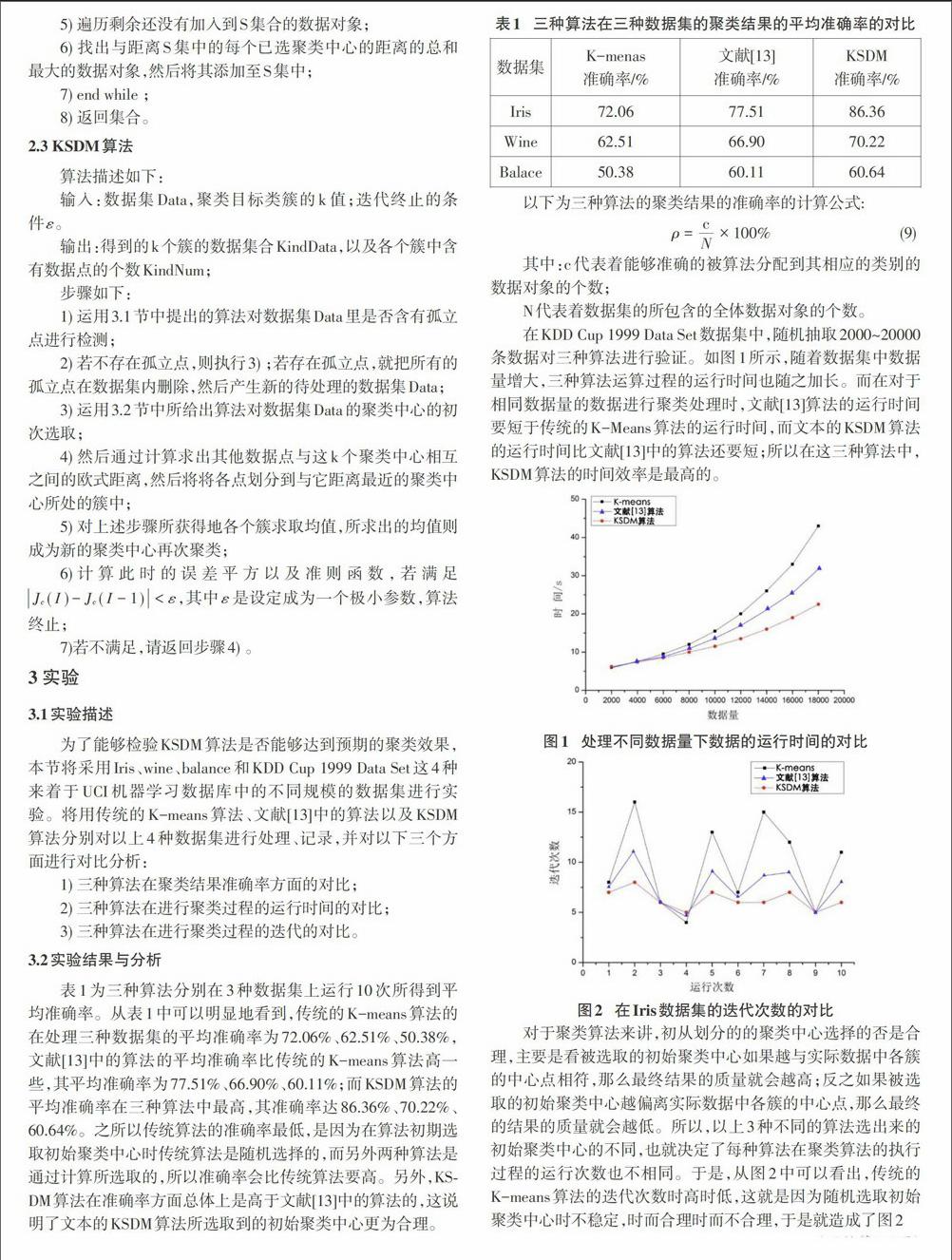
目前,很多研究者对K-means算法进行了改进。文献中的作者提出了一种基于最大最小距离法的初始聚类中心选取方法,该算法够能计算出k值并且能够在数据集中找到k个相对比较合理的初次划分的聚类中心,但是该算法容易将数据集内的边缘数据对象选定成为初次划分的聚类中心,并且需要较大时间消耗。段桂芹采用了一种基于均值与最大距离的乘积的方法选取初始聚类中心,该算法首先选择与距离数据集均值最远的那个数据对象作为聚类中心,并纳入聚类中心的集合,然后依次将与数据集均值和当前聚类中心的乘积最大的数据对象纳入聚类中心的集合,从而提高了准确率。
针对上文所阐述的诸多K-means算法的缺陷,本文给出了基于K-means算法的改进算法KSDM。在KSMD算法中给出了一种基于统计距离的孤立点检测算法和一种基于极大极小值原则的初始聚类中心选取算法。实验结果表明,KSDM算法不仅能够有效的检测和排除孤立点,还能够选取到较为合理的初始聚类中心,从而使算法的迭代次数减少,得到较佳的聚类结果。
2基于K-means算法改进
经过对传统的K-means算法深入研究发现,该算法的初次划分的聚类中心是由算法随机选定出来的,由于数据集中存在着一些与其他数据对象相似度很低。相异度很高,并且严重偏离数据集中心区域的一些数据对象,这里称之为孤立点;这些孤立点的存在会使得K-means算法在选择初次划分的聚类中心时不稳定、不合理,从而会使得聚类过程中迭代次数曾多、运行时间延长、聚类结果质量下降等影响;所以在算法运行之前,将数据集中的孤立点检测出来并删除以及如何选取出更为合理的初始聚类中心是很有必要的。
于是,针对上述的2个问题作者给出了基于K-means算法的改进KSDM算法,KSDM算法很好地优化了K-means算法的缺陷。
2.1算法1:基于统计距离的孤立点排除算法
所谓孤立点,是因为数据集中存在着一些与其他数据对象相似度很低、相异度很高,并且严重偏离数据集中心区域的一些数据对象,所以这种数据对象不属于任何一类的孤立数据对象,也称谓孤立点。由于K-means算法是随机选择初次划分的聚类中心时的,所以有这些孤立点的存在会使得算法在选取初次划分的聚类中心时存在着不稳定性、不合理性,因此,算法最终的聚类效果会因为孤立点的存在而延长运行时间、增加迭代次数以及聚类结果质量较低等隐患。所以,在运行聚类算法之前,将数据集中所存在的孤立点检测出来并删除是必要的。
